Architecture-driven Shift: towards a lightweight selector for capturing the trends of logit shift
Pith reviewed 2026-06-29 19:10 UTC · model grok-4.3
The pith
Architecture-driven Shift (ADS) predicts logit shift trends from architecture properties and few samples in continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We decouple logit shift into architecture dependency and data dependency to establish our framework, which reveals that the combination of two dependency, defined as Architecture-driven Shift (ADS), that can capture the logit shift tendency well computable with few data samples. Specifically, for a well-optimized model on prior tasks, higher ADS is associated with a larger logit shift after training on the current task, which derived based on three mechanistic components: (1) spectral norm scaling of weight matrix gradients with layer width, (2) the optimization path length of the new task, (3) the asymptotic task conflict in wide networks.
What carries the argument
Architecture-driven Shift (ADS), the combination of architecture dependency (from spectral-norm gradient scaling, optimization path length, and asymptotic task conflict) and data dependency.
If this is right
- ADS ranks architectures by expected logit shift without retraining each one on the full sequence.
- ADS supplies a lightweight proxy for expected calibration error when choosing models for continual learning.
- The three mechanistic components together explain why wider or deeper layers produce larger shifts on subsequent tasks.
- ADS remains computable from a small subset of the new-task data.
- The framework applies to real-world networks whose layer widths vary, unlike earlier uniform-width analyses.
Where Pith is reading between the lines
- ADS could be used to guide architecture search toward lower-shift designs before any continual-learning training begins.
- The same decoupling might apply to other shift-sensitive metrics such as feature drift or decision-boundary movement.
- If the three mechanistic components dominate, then controlling layer widths alone could reduce unwanted logit shift even when data order changes.
Load-bearing premise
The logit shift can be cleanly decoupled into an architecture dependency and a data dependency such that their combination captures the tendency of logit shift using only a few data samples, independent of specific optimization details or task ordering.
What would settle it
Observing a collection of new heterogeneous architectures where the Spearman's rank correlation between ADS and measured logit shift falls below 0.7 would falsify the central relation.
Figures

read the original abstract
Continual Learning (CL) is a practical paradigm to utilize power of deep pre-trained neural networks, but which pre-trained model has a better ability to balance ``Plasticity-Stability", deserving to be chosen? The logit shift serves as a natural proxy because it represents the logit shift in CL scenarios. However, obtaining the logit shift requires huge computational cost, which hinders large-scale model selection. Existing theoretical analyses fail to offer an efficient alternative because of the assumption of uniform hidden layer widths, which ignores the structural heterogeneity (variable width and depth) of real-world architectures. This raises a critical question: what theoretically relationship can be identified between heterogeneous architecture and logit shift on prior tasks (that the model has been trained on)? To answer the question, we decouple logit shift into architecture dependency and data dependency to establish our framework, which reveals that the combination of two dependency, defined as Architecture-driven Shift (ADS), that can capture the logit shift tendency well computable with few data samples. Specifically, for a well-optimized model on prior tasks, higher ADS is associated with a larger logit shift after training on the current task, which derived based on three mechanistic components: (1) spectral norm scaling of weight matrix gradients with layer width, (2) the optimization path length of the new task, and (3) the asymptotic task conflict in wide networks. Extensive empirical results across more than 175 diverse architectures demonstrate a strong monotonic correlation (the weakest Spearman's $r_s=0.731$) between ADS and logit shift. Practically, we demonstrate that ADS can serve as a lightweight proxy of the expected calibration error, which is a widely used metric for reliable CL model selection, on three datasets across six scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Architecture-driven Shift (ADS) as a lightweight proxy for logit shift in continual learning (CL) model selection. It decouples logit shift into architecture and data dependencies, with ADS defined as their combination and derived from three components: spectral norm scaling of weight matrix gradients with layer width, optimization path length of the new task, and asymptotic task conflict in wide networks. For well-optimized models, higher ADS is claimed to associate with larger logit shift after new-task training. Empirical results report a minimum Spearman's rs of 0.731 across 175 architectures and utility as a proxy for expected calibration error (ECE) on three datasets across six scenarios.
Significance. If the decoupling and derivation hold without residual optimizer or ordering dependencies, ADS could enable efficient pre-trained model selection for CL by avoiding full logit-shift computation, with the scale of the 175-architecture study providing notable empirical grounding for practical use in architecture search.
major comments (2)
- [Abstract] Abstract / derivation: No explicit formula or combination steps are given for how the three mechanistic components (spectral norm scaling, path length, asymptotic conflict) aggregate into ADS. This leaves open whether residual terms remain that depend on learning-rate schedule, momentum, or task permutation, directly undermining the claimed clean decoupling into architecture vs. data dependencies that is load-bearing for the independence from optimization details.
- [Abstract] Abstract / heterogeneous architectures: The spectral-norm scaling component is invoked for variable widths and depths, yet the original arguments typically assume uniform layers; without the extension shown, it is unclear whether the ADS expression remains valid for the heterogeneous real-world architectures tested, which is central to the generalizability claim across 175 models.
minor comments (2)
- [Abstract] The abstract reports the weakest rs=0.731 but does not identify the dataset/scenario yielding this minimum, reducing clarity on robustness.
- Notation for the final ADS expression should be introduced with an equation number once the derivation is supplied.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed comments on our manuscript. We address each major comment below and have updated the abstract and relevant sections to improve clarity on the derivation and applicability to heterogeneous architectures.
read point-by-point responses
-
Referee: [Abstract] Abstract / derivation: No explicit formula or combination steps are given for how the three mechanistic components (spectral norm scaling, path length, asymptotic conflict) aggregate into ADS. This leaves open whether residual terms remain that depend on learning-rate schedule, momentum, or task permutation, directly undermining the claimed clean decoupling into architecture vs. data dependencies that is load-bearing for the independence from optimization details.
Authors: We agree that the abstract would benefit from an explicit statement of how the components combine into ADS. The full derivation in Section 3 defines ADS as the product of the three terms (spectral norm scaling of gradients, optimization path length, and asymptotic task conflict), which isolates the architecture-dependent factors under fixed optimization settings. We will revise the abstract to include this formula and note the assumptions regarding optimizer independence for the decoupling. revision: yes
-
Referee: [Abstract] Abstract / heterogeneous architectures: The spectral-norm scaling component is invoked for variable widths and depths, yet the original arguments typically assume uniform layers; without the extension shown, it is unclear whether the ADS expression remains valid for the heterogeneous real-world architectures tested, which is central to the generalizability claim across 175 models.
Authors: Our derivation extends the spectral norm scaling to heterogeneous architectures by computing it layer-wise and aggregating across layers of varying widths and depths. This is presented in the theoretical framework and empirically validated with the 175 architectures. To address the concern, we will add a brief mention of this layer-wise extension in the abstract. revision: yes
Circularity Check
No circularity: derivation claims independence via three components without equations reducing ADS to logit shift by construction
full rationale
The abstract decouples logit shift into architecture and data dependencies whose combination is defined as ADS, then states that higher ADS associates with larger logit shift derived from spectral norm scaling, optimization path length, and asymptotic task conflict. No equations are supplied showing that the ADS expression equals or is fitted to the logit shift quantity itself. Empirical correlation (Spearman's r_s >=0.731) is reported separately as validation. No self-citation, ansatz smuggling, or renaming of known results is present in the text. The derivation is therefore treated as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Logit shift factors cleanly into architecture dependency and data dependency
- ad hoc to paper Spectral norm scaling, optimization path length, and asymptotic task conflict together determine the architecture-driven component
invented entities (1)
-
Architecture-driven Shift (ADS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps: //openreview.net/forum?id=SkMwpiR9Y7. Mehdi Abbana Bennani, Thang Doan, and Masashi Sugiyama. Generalisation guarantees for con- tinual learning with orthogonal gradient descent.arXiv preprint arXiv:2006.11942,
-
[2]
Qualitatively characterizing neural network optimization problems
11 Published as a conference paper at ICLR 2026 Ian J Goodfellow, Oriol Vinyals, and Andrew M Saxe. Qualitatively characterizing neural network optimization problems.arXiv preprint arXiv:1412.6544,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Gradient Descent Happens in a Tiny Subspace
Guy Gur-Ari, Daniel A Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace.arXiv preprint arXiv:1812.04754,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Yankun Han. Weight initialization and variance dynamics in deep neural networks and large lan- guage models.arXiv preprint arXiv:2510.09423,
-
[5]
Michael McCloskey and Neal J Cohen
URLhttps: //www.ijcai.org/proceedings/2024/514. Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pp. 109–165. Elsevier,
2024
-
[6]
Sidak Pal Singh, Bobby He, Thomas Hofmann, and Bernhard Sch ¨olkopf. Hallmarks of optimiza- tion trajectories in neural networks: Directional exploration and redundancy.arXiv preprint arXiv:2403.07379,
-
[7]
12 Published as a conference paper at ICLR 2026 Roman Vershynin.High-dimensional probability: An introduction with applications in data science, volume
2026
-
[8]
PathLen(l) ≈C traj ·Disp (l),(23) whereC traj is constant
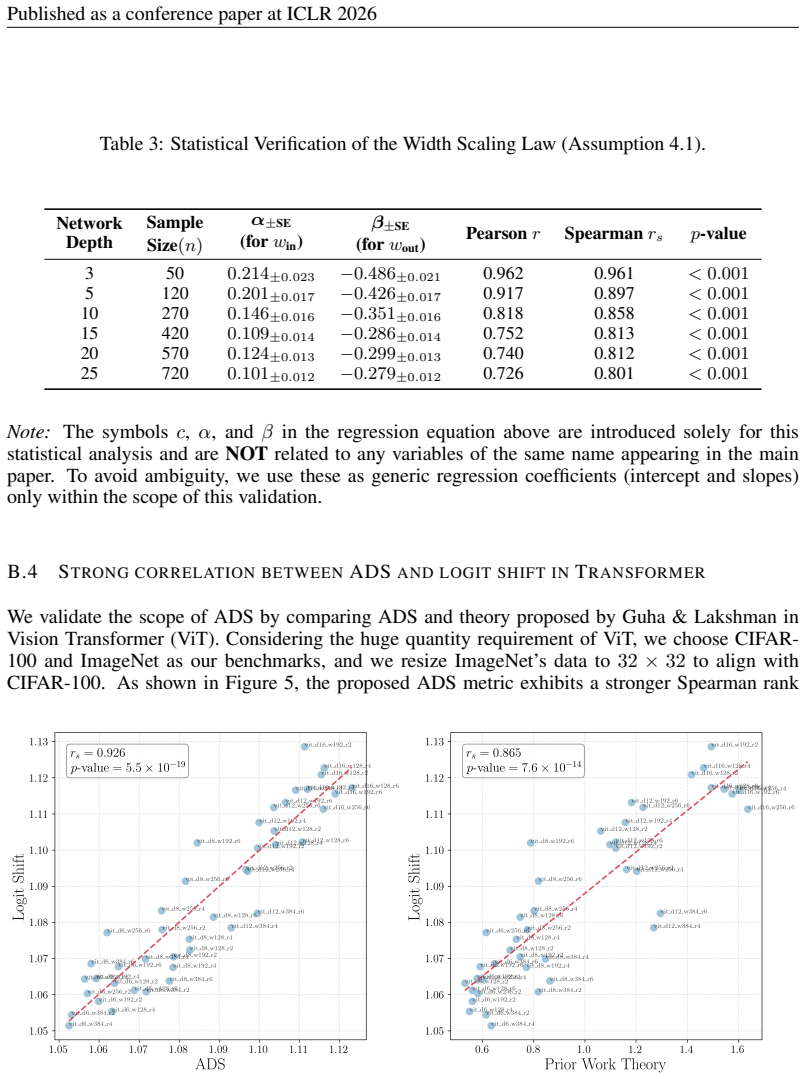
A DETAILEDTHEORETICALFRAMEWORK Assumption A.1(Trajectory Regularity).The optimization trajectory in parameter space is free from sharp directional reversals, implying that the ratio of path length to displacement remains bounded. PathLen(l) ≈C traj ·Disp (l),(23) whereC traj is constant. There are a growing body of theoretical and empirical work supports ...
2021
-
[9]
Global Success
and zero biases. The network is initialized in a trainable regime where gradients do not vanish exponentially with depth. Specifically, the layer-wise weightsΘ (l) follow a non-degenerate distribution with variance satisfying: VarΘ(l) ≫0,∀l= 1, . . . , L⇐ ⇒E[Θ (l)2]≫ E[Θ(l)] 2 .(24) This assumption is both theoretically grounded and standard in practice, ...
2015
-
[10]
width” and “depth
Theorem A.10(Scaling Law of Output Shift).Letf i(x)andf i+1(x)denote the model output before and after learning taski+ 1, respectively. Under the assumption that second-order terms are negligible (dominating<20%of the variation), the shift in the output function for a previous task samplexscales as: ∥fi+1(x)−f i(x)∥2 ∝ LX l=1 (w(l−1))α+ 1 2 (w(l))β · |lbe...
2018
-
[11]
20 Published as a conference paper at ICLR 2026 (a) Validation on fully-connected neural network (FNN)
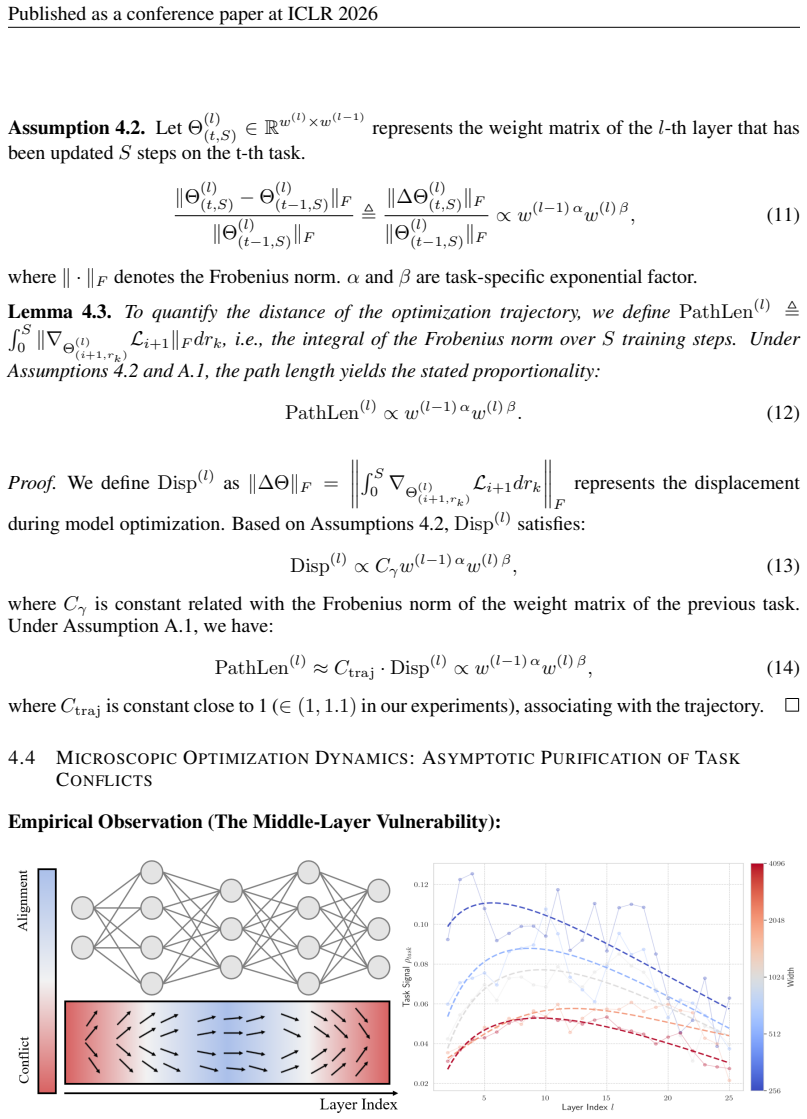
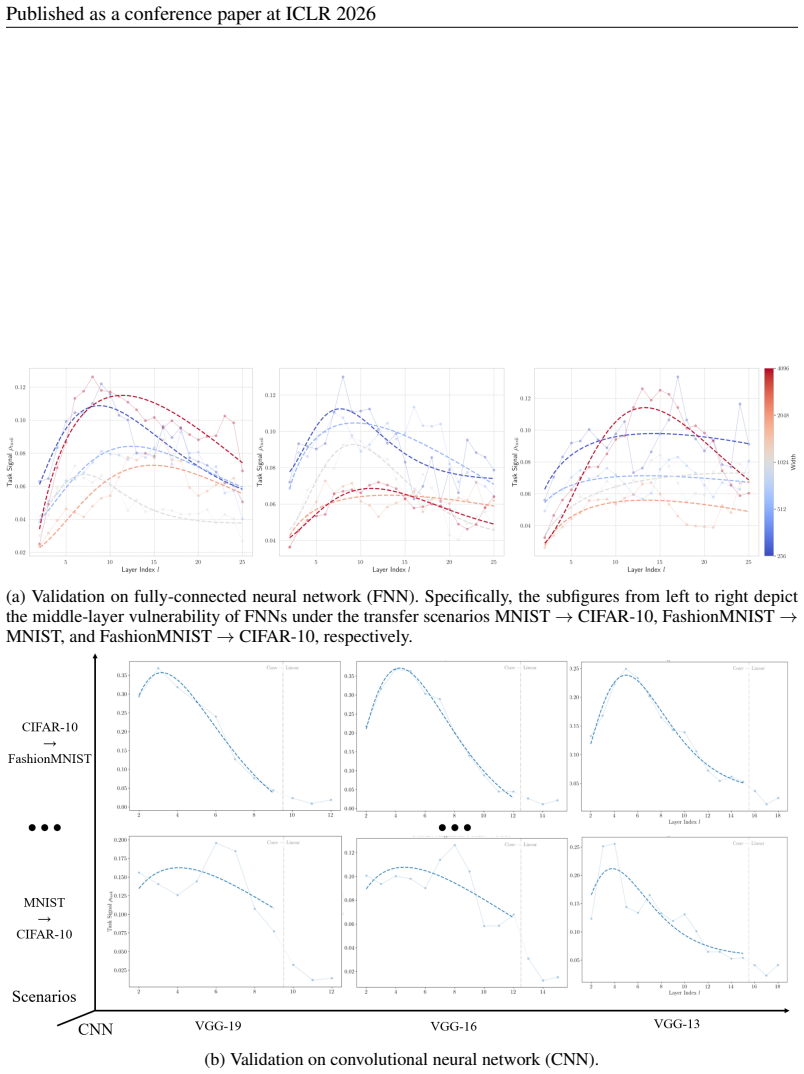
B.3 ADDITIONALEVIDENCE OFMIDDLE-LAYERVULNERABILITY As demonstrated in Figure 4, the middle-layer vulnerability exist across scenarios (different combi- nation of various datasets) and model families (fully-connected neural networks and convolutional neural networks). 20 Published as a conference paper at ICLR 2026 (a) Validation on fully-connected neural ...
2026
-
[12]
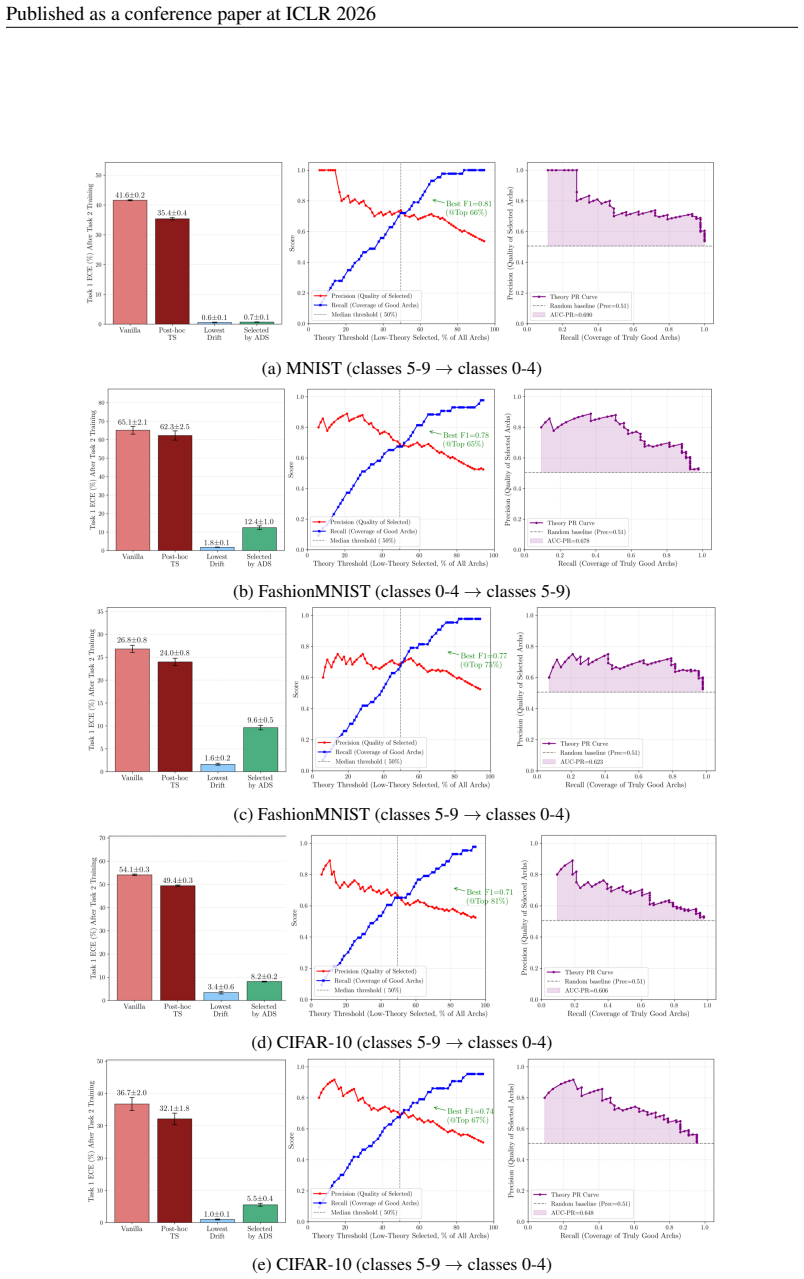
22 Published as a conference paper at ICLR 2026 B.6 EXPERIMENTALRESULTS The empirical validation of the ADS-based selector’s performance in reliable continual learning model selection is shown in Figure
2026
-
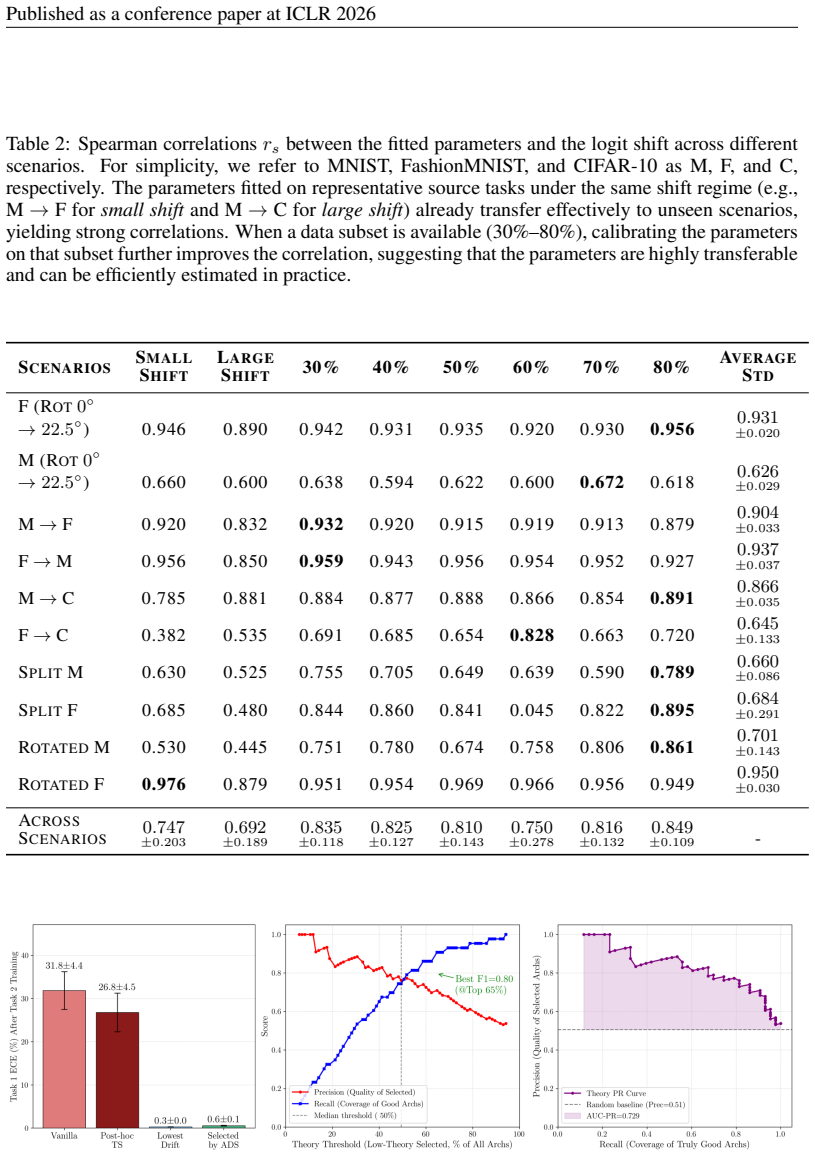
[13]
As illustrated in the mid- dle column of Figure 6, the ADS-based selector serves as an effective coarse-grained selector
Although the selected architectures do not achieve the ideal lowest Expected Calibration Error (ECE), they are more reliable than both the vanilla architecture and those calibrated with a post-hoc temperature scaling mechanism. As illustrated in the mid- dle column of Figure 6, the ADS-based selector serves as an effective coarse-grained selector. It achi...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.