SCALE-COMM: Shared, Contrastively-Aligned Latent Embeddings for MARL Communication
Pith reviewed 2026-06-29 17:09 UTC · model grok-4.3
The pith
SCALE-COMM learns compact latent messages for robot teams by contrastive alignment across agents and time, decoupling them from policy training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
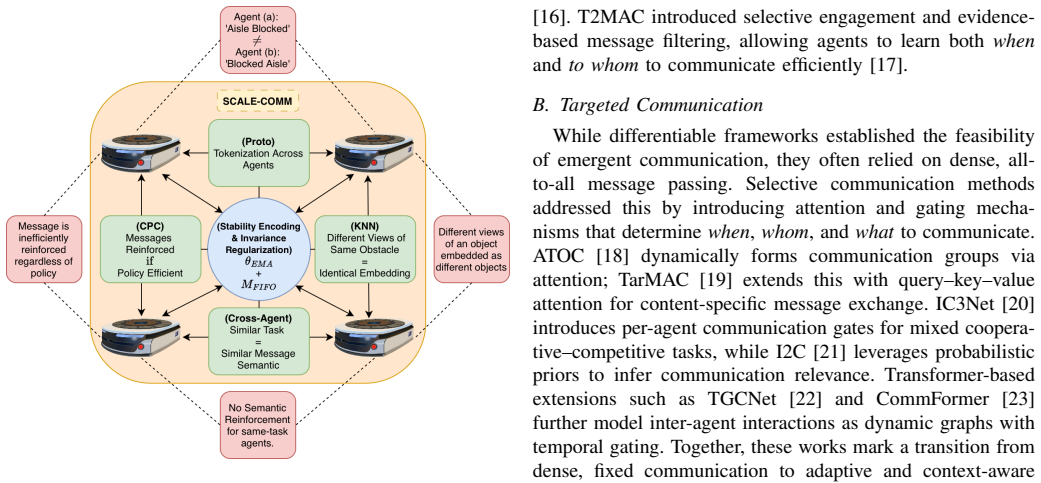
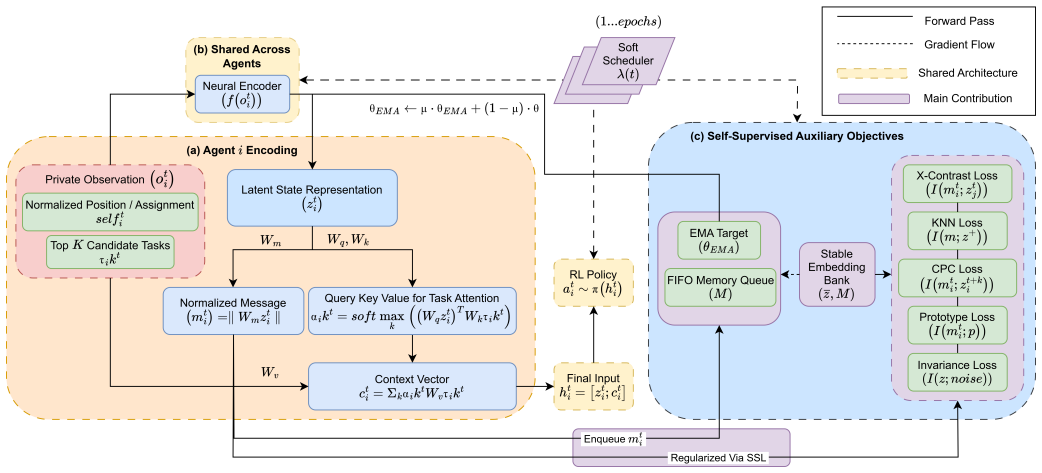
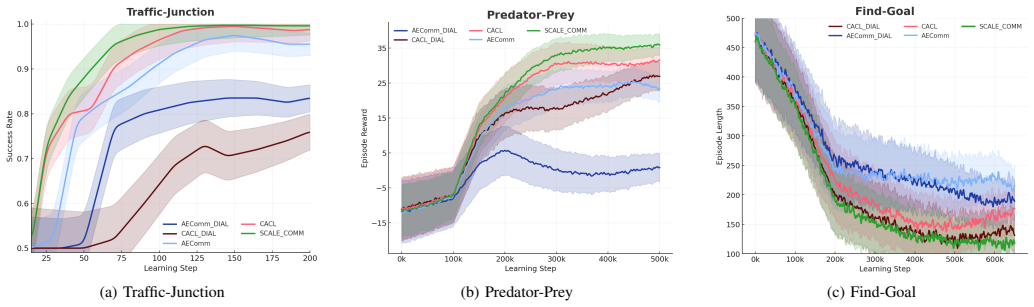
SCALE-COMM is a self-supervised framework that decouples communication learning from policy optimization by training low-dimensional latent messages which capture task-relevant planning and traffic information while enforcing consistency across agents and time, resulting in improved stability, sample efficiency, and throughput compared to prior communication frameworks.
What carries the argument
Shared contrastively-aligned latent embeddings: low-dimensional representations trained to encode planning and traffic information with cross-agent and temporal consistency constraints.
If this is right
- Communication protocols remain stable even as individual agent policies are fine-tuned over time.
- Sample efficiency improves because message learning does not compete with policy gradients.
- Task throughput increases in coordination scenarios that require consistent traffic and planning signals.
- Representation quality metrics rise because embeddings are explicitly aligned rather than emergent from rewards alone.
Where Pith is reading between the lines
- The same alignment approach could be tested in non-robotics MARL domains such as traffic signal control or game playing to check if the stability gains transfer.
- If the low-dimensional embeddings prove interpretable, they might support post-hoc analysis of what information agents are actually sharing.
- Extending the consistency constraints to include predicted future states could further reduce drift in long-horizon tasks.
Load-bearing premise
Contrastive alignment of latent embeddings will produce messages that remain relevant to the evolving policies without creating new interference or needing extra tuning.
What would settle it
On the warehouse coordination task, if SCALE-COMM produces lower throughput or less stable protocols than the best baseline communication method after the same number of training steps, the decoupling benefit would not hold.
Figures

read the original abstract
Emergent communication enables partially observant Autonomous Mobile Robots (AMRs) to coordinate effectively in decentralized multi-agent reinforcement learning (MARL) settings. However, existing approaches often struggle with unstable communication protocols, ungrounded message semantics, and interference between communication learning and policy optimization, leading to degraded coordination over time. We propose SCALE-COMM (Shared, Contrastively-Aligned Latent Embeddings for COMMunication), a self-supervised framework for learning compact, stable, and policy-relevant communication representations. SCALE-COMM decouples communication learning from policy optimization by training low-dimensional latent messages that capture task-relevant planning and traffic information, while enforcing consistency across agents and time. Across standard MARL benchmarks and a realistic warehouse coordination task, SCALE-COMM consistently outperforms existing communication frameworks in both representation quality and task performance. The learned communication space yields improved stability, sample efficiency, and throughput under policy fine-tuning, demonstrating the effectiveness of representation-driven communication for scalable multi-agent coordination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SCALE-COMM, a self-supervised framework that learns compact latent messages for emergent communication in decentralized MARL for AMRs. It decouples communication from policy optimization by training low-dimensional embeddings via contrastive alignment that enforces cross-agent and temporal consistency, with the goal of capturing task-relevant planning and traffic information. The abstract claims consistent outperformance versus prior communication methods on standard MARL benchmarks and a warehouse coordination task, together with gains in stability, sample efficiency, and throughput during policy fine-tuning.
Significance. If the empirical claims and the policy-relevance of the learned embeddings hold, the work would offer a representation-centric alternative to joint optimization approaches in MARL communication, potentially improving scalability and reducing interference in multi-robot coordination settings.
major comments (2)
- [Abstract] Abstract: the central empirical claim of 'consistent outperformance' and 'improved stability, sample efficiency, and throughput' is stated without any metrics, baselines, statistical tests, or experimental protocol, so the data-to-claim link cannot be assessed.
- [Method] Method (contrastive objective): positive pairs are defined exclusively by agent/time identity rather than by policy success, value estimates, or task reward. This leaves open the possibility that the embeddings align on spurious shared observations while remaining uninformative for downstream planning, undermining the decoupling claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'policy-relevant' is used repeatedly but never operationalized; a brief definition or proxy (e.g., correlation with value function) would clarify the intended meaning.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of 'consistent outperformance' and 'improved stability, sample efficiency, and throughput' is stated without any metrics, baselines, statistical tests, or experimental protocol, so the data-to-claim link cannot be assessed.
Authors: We agree the abstract states claims at a high level. The full experimental protocol, baselines, metrics, and statistical tests appear in Sections 4–5. We will revise the abstract to include a small number of key quantitative results (e.g., average return gains and sample-efficiency ratios) while remaining within length limits. revision: yes
-
Referee: [Method] Method (contrastive objective): positive pairs are defined exclusively by agent/time identity rather than by policy success, value estimates, or task reward. This leaves open the possibility that the embeddings align on spurious shared observations while remaining uninformative for downstream planning, undermining the decoupling claim.
Authors: Positive pairs are deliberately defined by agent and time identity to enforce the cross-agent and temporal consistency that underpins the decoupling. Because the resulting embeddings are fed directly into the policy network, downstream task performance serves as an indirect test of relevance. We will add an explicit analysis (correlation of embedding distances with value estimates and reward signals) to the revision to address the spurious-alignment concern. revision: partial
Circularity Check
No circularity detected; derivation chain absent from provided text
full rationale
The abstract and reader's summary contain no equations, derivations, or load-bearing steps that reduce a claimed result to its own inputs by construction. No self-definitional mappings, fitted inputs renamed as predictions, or self-citation chains appear. The method description frames SCALE-COMM as a self-supervised contrastive framework whose outputs are evaluated on external benchmarks, leaving the central claims independent of any internal tautology. This is the expected outcome for a proposal paper whose technical details are not yet inspected.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Decentralized task allocation in multi-robot exploration with position sharing only,
J. Bayer and J. Faigl, “Decentralized task allocation in multi-robot exploration with position sharing only,” inInternational Symposium on Swarm Behavior and Bio-Inspired Robotics (SWARM), 2021
2021
-
[2]
Learning scalable and efficient communication policies for multi-robot collision avoidance,
´A. Serra-G ´omez, H. Zhu, B. Brito, W. B ¨ohmer, and J. Alonso-Mora, “Learning scalable and efficient communication policies for multi-robot collision avoidance,”Autonomous Robots, vol. 47, no. 8, pp. 1275–1297, 2023
2023
-
[3]
Where2comm: Communication-efficient collaborative perception via spatial confidence maps,
Y . Hu, S. Fang, Z. Lei, Y . Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confidence maps,”Advances in neural information processing systems, vol. 35, pp. 4874–4886, 2022
2022
-
[4]
Dmca: Dense multi- agent navigation using attention and communication,
S. H. Arul, A. S. Bedi, and D. Manocha, “Dmca: Dense multi- agent navigation using attention and communication,”arXiv preprint arXiv:2209.06415, 2022
-
[5]
Multi-Agent Reinforcement Learning for Autonomous Driving: A Survey,
R. Zhang, J. Hou, F. Walter, S. Gu, J. Guan, F. R ¨ohrbein, Y . Du, P. Cai, G. Chen, and A. Knoll, “Multi-agent reinforcement learning for autonomous driving: A survey,”arXiv preprint arXiv:2408.09675, 2024
-
[6]
K. Smith, Z. Zhang, H. Ahmad, E. Sabouni, M. Mondal, S. Han, W. Li, and F. Miao, “Robust and safe multi-agent reinforcement learning frame- work with communication for autonomous vehicles,”arXiv preprint arXiv:2506.00982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
On the role of emergent communication for social learning in multi-agent reinforcement learn- ing,
S. Karten, S. Kailas, H. Li, and K. Sycara, “On the role of emergent communication for social learning in multi-agent reinforcement learn- ing,”arXiv preprint arXiv:2302.14276, 2023
-
[9]
Compositionality and generalization in emergent languages,
R. Chaabouni, E. Kharitonov, D. Bouchacourt, E. Dupoux, and M. Ba- roni, “Compositionality and generalization in emergent languages,” arXiv preprint arXiv:2004.09124, 2020
-
[11]
Infobot: Transfer and exploration via the information bottleneck,
A. Goyal, R. Islam, D. Strouse, Z. Ahmed, M. Botvinick, H. Larochelle, Y . Bengio, and S. Levine, “Infobot: Transfer and exploration via the information bottleneck,”arXiv preprint arXiv:1901.10902, 2019
-
[12]
Learning multi-agent communication with contrastive learning,
Y . L. Lo, B. Sengupta, J. Foerster, and M. Noukhovitch, “Learning multi-agent communication with contrastive learning,”arXiv preprint arXiv:2307.01403, 2023
-
[13]
Learning to communicate with deep multi-agent reinforcement learning,
J. Foerster, I. A. Assael, N. De Freitas, and S. Whiteson, “Learning to communicate with deep multi-agent reinforcement learning,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[14]
Learning multiagent communication with backpropagation,
S. Sukhbaatar, R. Ferguset al., “Learning multiagent communication with backpropagation,”Advances in neural information processing sys- tems, vol. 29, 2016
2016
-
[15]
P. Peng, Y . Wen, Y . Yang, Q. Yuan, Z. Tang, H. Long, and J. Wang, “Multiagent bidirectionally-coordinated nets: Emergence of human-level coordination in learning to play starcraft combat games,”arXiv preprint arXiv:1703.10069, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Generalising multi-agent cooperation through task-agnostic communication,
D. Jayalath, S. Morad, and A. Prorok, “Generalising multi-agent cooperation through task-agnostic communication,”arXiv preprint arXiv:2403.06750, 2024
-
[17]
T2mac: Targeted and trusted multi-agent communication through selective en- gagement and evidence-driven integration,
C. Sun, Z. Zang, J. Li, J. Li, X. Xu, R. Wang, and C. Zheng, “T2mac: Targeted and trusted multi-agent communication through selective en- gagement and evidence-driven integration,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 13, 2024, pp. 15 154– 15 163
2024
-
[18]
Learning attentional communication for multi- agent cooperation,
J. Jiang and Z. Lu, “Learning attentional communication for multi- agent cooperation,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[19]
Tarmac: Targeted multi-agent communication,
A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “Tarmac: Targeted multi-agent communication,” inInterna- tional Conference on machine learning. PMLR, 2019, pp. 1538–1546
2019
-
[20]
Learning when to Communicate at Scale in Multiagent Cooperative and Competitive Tasks
A. Singh, T. Jain, and S. Sukhbaatar, “Learning when to communicate at scale in multiagent cooperative and competitive tasks,”arXiv preprint arXiv:1812.09755, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Learning individually inferred commu- nication for multi-agent cooperation,
Z. Ding, T. Huang, and Z. Lu, “Learning individually inferred commu- nication for multi-agent cooperation,”Advances in neural information processing systems, vol. 33, pp. 22 069–22 079, 2020
2020
-
[22]
Bridging training and execution via dynamic directed graph-based communication in cooperative multi- agent systems,
Z. Zhang, B. He, B. Cheng, and G. Li, “Bridging training and execution via dynamic directed graph-based communication in cooperative multi- agent systems,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 22, 2025, pp. 23 395–23 403
2025
-
[23]
Communication learning in multi-agent systems from graph modeling perspective,
S. Hu, L. Shen, Y . Zhang, and D. Tao, “Communication learning in multi-agent systems from graph modeling perspective,”arXiv preprint arXiv:2411.00382, 2024
-
[24]
Emergence of grounded compositional language in multi-agent populations,
I. Mordatch and P. Abbeel, “Emergence of grounded compositional language in multi-agent populations,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
2018
-
[25]
R. M ¨uller, H. Turalic, T. Phan, M. K ¨olle, J. N ¨ußlein, and C. Linnhoff-Popien, “Clustercomm: Discrete communication in decen- tralized marl using internal representation clustering,”arXiv preprint arXiv:2401.03504, 2024
-
[26]
Rgmcomm: Return gap minimization via discrete communications in multi-agent reinforcement learning,
J. Chen, T. Lan, and C. Joe-Wong, “Rgmcomm: Return gap minimization via discrete communications in multi-agent reinforcement learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 327–17 336
2024
-
[27]
Contrastive trajectory learning for multi-agent reinforcement learning policy transfer,
Y . Wang, Q. Liu, H. Chen, K. Fu, L. Liu, B. Gao, X. Ding, and J. Huang, “Contrastive trajectory learning for multi-agent reinforcement learning policy transfer,” in2025 IEEE 26th China Conference on System Simulation Technology and its Applications (CCSSTA). IEEE, 2025, pp. 463–468
2025
-
[28]
Efficient com- munication via self-supervised information aggregation for online and offline multiagent reinforcement learning,
C. Guan, F. Chen, L. Yuan, Z. Zhang, and Y . Yu, “Efficient com- munication via self-supervised information aggregation for online and offline multiagent reinforcement learning,”IEEE Transactions on Neural Networks and Learning Systems, 2024
2024
-
[29]
Ma2cl: masked attentive con- trastive learning for multi-agent reinforcement learning,
H. Song, M. Feng, W. Zhou, and H. Li, “Ma2cl: masked attentive con- trastive learning for multi-agent reinforcement learning,”arXiv preprint arXiv:2306.02006, 2023
-
[30]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738
2020
-
[32]
Bootstrap your own latent-a new approach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altch ´e, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azaret al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in neural information processing systems, vol. 33, pp. 21 271– 21 284, 2020
2020
-
[33]
Unsupervised learning of visual features by contrasting cluster assign- ments,
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assign- ments,”Advances in neural information processing systems, vol. 33, pp. 9912–9924, 2020
2020
-
[34]
Curl: Contrastive unsupervised representations for reinforcement learning,
M. Laskin, A. Srinivas, and P. Abbeel, “Curl: Contrastive unsupervised representations for reinforcement learning,” inInternational conference on machine learning. PMLR, 2020, pp. 5639–5650
2020
-
[35]
M. Schwarzer, A. Anand, R. Goel, R. D. Hjelm, A. Courville, and P. Bachman, “Data-efficient reinforcement learning with self-predictive representations,”arXiv preprint arXiv:2007.05929, 2020
-
[36]
Reinforcement learning via auxiliary task distillation,
A. N. Harish, L. Heck, J. P. Hanna, Z. Kira, and A. Szot, “Reinforcement learning via auxiliary task distillation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 214–230
2024
-
[37]
Reward-independent messaging for decentralized multi-agent reinforcement learning,
N. Yoshida and T. Taniguchi, “Reward-independent messaging for decentralized multi-agent reinforcement learning,”arXiv preprint arXiv:2505.21985, 2025
-
[38]
Learning to ground multi-agent communication with autoencoders,
T. Lin, J. Huh, C. Stauffer, S. N. Lim, and P. Isola, “Learning to ground multi-agent communication with autoencoders,”Advances in Neural Information Processing Systems, vol. 34, pp. 15 230–15 242, 2021
2021
-
[39]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on machine learning. PmLR, 2020, pp. 1597–1607
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.