LaneRoPE: Positional Encoding for Collaborative Parallel Reasoning and Generation
Pith reviewed 2026-06-29 17:17 UTC · model grok-4.3
The pith
LaneRoPE adds an inter-sequence attention mask and RoPE extension so multiple parallel LLM generations can coordinate token positions across sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
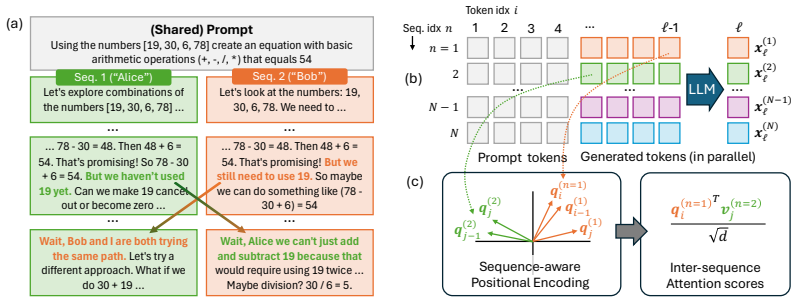
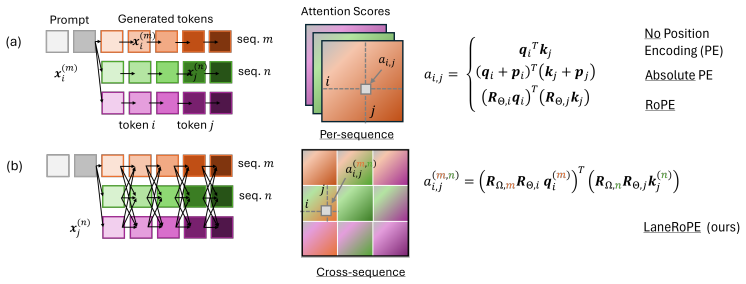
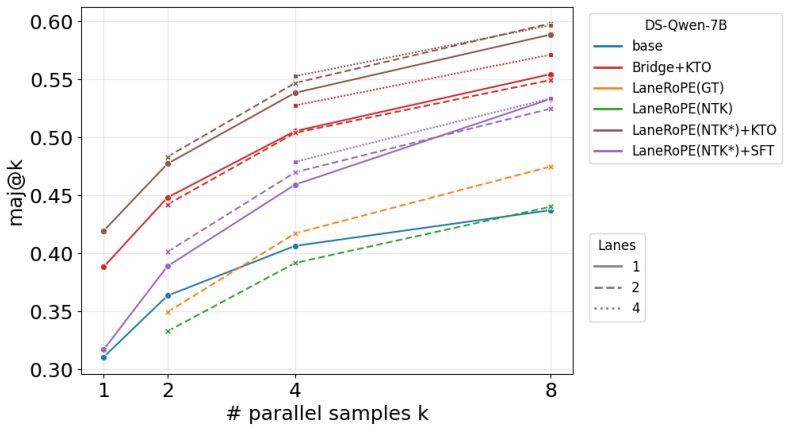
LaneRoPE enables coordination among N>1 sequences at generation time through an inter-sequence attention mask and a RoPE extension that supplies relative positional information for tokens both within and outside any given sequence. When evaluated on mathematical reasoning tasks, this yields additional accuracy improvements under limited generated sequence length while preserving the efficiency of batched inference.
What carries the argument
LaneRoPE: an inter-sequence attention mask paired with a rotary positional encoding extension that records relative token positions across multiple sequences.
If this is right
- Multiple sequences can share intermediate observations during generation instead of running in isolation.
- Accuracy gains appear under fixed output-length budgets where independent sampling plateaus.
- The approach integrates into existing LLM inference pipelines with negligible added latency.
- The same mechanism supports collaborative parallel reasoning on mathematical tasks.
Where Pith is reading between the lines
- The same mask-plus-RoPE pattern could be tested on code generation or multi-step planning where partial outputs from one trajectory inform another.
- If the relative-position signal scales to larger N, best-of-N could be replaced by a single coordinated batch whose members actively correct one another.
- Extending the mask to allow selective rather than full cross-sequence attention might reduce interference while retaining collaboration benefits.
Load-bearing premise
Any accuracy improvement comes from the new cross-sequence dependencies rather than from other incidental effects of the mask or positional change.
What would settle it
Run the same model and prompts with and without the inter-sequence mask at identical total token budgets; if accuracy does not rise when the mask is active, the collaboration claim is false.
Figures
read the original abstract
Parallel LLM test-time scaling techniques (e.g., best-of-$N$) require drawing $N>1$ sequences conditioned on the same input prompt. These methods boost accuracy while exploiting the computational efficiency of batching $N$ generations. However, each sequence in the batch is traditionally generated independently and hence does not reuse intermediate generations, computations, or observations from other sequences. In this paper, we propose LaneRoPE to enable coordination and collaboration among $N>1$ sequences at generation time. LaneRoPE involves two key ideas: (a) an inter-sequence attention mask to make sampling of sequences dependent on one another; and (b) a RoPE extension that injects positional information that captures relative positions between tokens, both within and outside a particular sequence. We evaluate our approach on mathematical reasoning tasks and find promising results: LaneRoPE enables collaboration among sequences, yielding additional accuracy gains under limited generated sequence length. Importantly, since LaneRoPE enables coordination with minimal changes to the underlying LLM architecture and introduces a negligible overhead at inference time, it is appealing to rapidly incorporate parallel reasoning into existing LLM inference pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LaneRoPE to enable collaboration among N>1 parallel generation sequences in LLMs. It combines (a) an inter-sequence attention mask that makes token sampling in one sequence depend on others and (b) an extension of RoPE that encodes relative positions both within and across sequences. The central claim is that this yields additional accuracy gains on mathematical reasoning tasks under limited generated sequence length, with only minimal changes to the underlying LLM and negligible inference overhead.
Significance. If the claimed gains are shown to arise specifically from inter-sequence collaboration (rather than from the RoPE change alone or other factors), the method would offer a lightweight way to improve parallel test-time scaling techniques such as best-of-N without retraining or major architectural modifications.
major comments (2)
- [Abstract] Abstract: the claim that LaneRoPE 'enables collaboration among sequences, yielding additional accuracy gains' is not supported by any reported experimental details, baselines, error bars, or isolating controls. Without these, the support for the central claim cannot be assessed.
- [Experiments (and method description)] No ablation is described that applies the RoPE extension without the inter-sequence attention mask (or vice versa) while holding all other factors fixed. Because the RoPE change encodes global relative positions, it could alter intra-sequence signals independently of any cross-sequence dependency; the absence of this control leaves the causal attribution to the mask unsecured.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our claims and the need for stronger experimental isolation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that LaneRoPE 'enables collaboration among sequences, yielding additional accuracy gains' is not supported by any reported experimental details, baselines, error bars, or isolating controls. Without these, the support for the central claim cannot be assessed.
Authors: The abstract is intentionally concise. The full manuscript contains an experiments section that evaluates LaneRoPE on mathematical reasoning tasks, reports accuracy improvements relative to independent parallel generation baselines under fixed length limits, and includes error bars from repeated runs. To directly address the concern, we will revise the abstract to briefly reference the tasks, the observed gains, and the location of the detailed results and baselines. revision: yes
-
Referee: [Experiments (and method description)] No ablation is described that applies the RoPE extension without the inter-sequence attention mask (or vice versa) while holding all other factors fixed. Because the RoPE change encodes global relative positions, it could alter intra-sequence signals independently of any cross-sequence dependency; the absence of this control leaves the causal attribution to the mask unsecured.
Authors: We agree that an explicit ablation separating the RoPE extension from the inter-sequence mask is necessary to secure attribution to cross-sequence collaboration. The current manuscript does not contain this control. In the revision we will add the requested ablation: we will evaluate the extended RoPE alone (without the mask) while keeping all other factors fixed, and compare it against both the full LaneRoPE configuration and the unmodified baseline. revision: yes
Circularity Check
No circularity: new construction presented without reduction to fitted inputs or self-citations
full rationale
The paper proposes LaneRoPE as an explicit new construction consisting of an inter-sequence attention mask plus a RoPE extension that encodes relative positions both within and across sequences. No derivation chain, first-principles result, or prediction is claimed that reduces by the paper's own equations to quantities already fitted from the target data. The abstract presents the accuracy gains as an empirical outcome of the method rather than a tautological consequence of its definition. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The method is therefore self-contained as a novel engineering proposal whose validity rests on external evaluation rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
2024
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Keyu Chen, Zhifeng Shen, Daohai Yu, Haoqian Wu, Wei Wen, Jianfeng He, Ruizhi Qiao, and Xing Sun. Aspd: Unlocking adaptive serial-parallel decoding by exploring intrinsic parallelism in llms.arXiv preprint arXiv:2508.08895, 2025. doi: 10.48550/arXiv.2508.08895. URL https://arxiv.org/abs/2508.08895
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186, 2019
2019
-
[7]
Generalized parallel scaling with interdependent generations.arXiv preprint arXiv:2510.01143, 2025
Harry Dong et al. Generalized parallel scaling with interdependent generations.arXiv preprint arXiv:2510.01143, 2025. URLhttps://arxiv.org/abs/2510.01143
-
[8]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Stream of search (sos): Learning to search in language.arXiv preprint arXiv:2404.03683, 2024
Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah D Goodman. Stream of search (sos): Learning to search in language.arXiv preprint arXiv:2404.03683, 2024
-
[10]
Lighteval: A lightweight framework for llm evaluation, 2023
Nathan Habib, Clémentine Fourrier, Hynek Kydlí ˇcek, Thomas Wolf, and Lewis Tunstall. Lighteval: A lightweight framework for llm evaluation, 2023. URL https://github.com/ huggingface/lighteval
2023
-
[11]
Group think: Multiple concurrent reasoning agents collaborating at token level granularity.arXiv [cs.AI], 16 May 2025
Chan-Jan Hsu, Davide Buffelli, Jamie McGowan, Feng-Ting Liao, Yi-Chang Chen, Sattar Vakili, and Da-Shan Shiu. Group think: Multiple concurrent reasoning agents collaborating at token level granularity.arXiv [cs.AI], 16 May 2025
2025
-
[12]
Group think: Multiple concurrent reasoning agents collaborating at token level granularity
Chan-Jan Hsu, Davide Buffelli, Jamie McGowan, Feng-Ting Liao, Yi-Chang Chen, Sattar Vakili, and Da-shan Shiu. Group think: Multiple concurrent reasoning agents collaborating at token level granularity. InarXiv preprint arXiv:2505.11107, 2025. doi: 10.48550/arXiv.2505.11107. URLhttps://arxiv.org/abs/2505.11107
-
[13]
Cheng, Zack Ankner, Nikunj Saunshi, Jonathan Ragan-Kelley, Suvinay Subramanian, Blake M
Tian Jin, Ellie Y . Cheng, Zack Ankner, Nikunj Saunshi, Jonathan Ragan-Kelley, Suvinay Subramanian, Blake M. Elias, Amir Yazdanbakhsh, and Michael Carbin. Learning to keep a promise: Scaling language model decoding parallelism with learned asynchronous decoding. In Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025. URL http...
2025
-
[14]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[15]
Long Lian et al. Threadweaver: Adaptive threading for efficient parallel reasoning in language models.arXiv preprint arXiv:2512.07843, 2025. URL https://arxiv.org/abs/2512. 07843. 11
-
[16]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=v8L0pN6EOi
2024
-
[17]
Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. https://huggingface.co/agentica-org/ DeepScaleR-1.5B-Preview, 2025
2025
-
[18]
American mathematics competitions (amc) 10/12 2023,
Mathematical Association of America. American mathematics competitions (amc) 10/12 2023,
2023
-
[19]
American invitational mathematics examination (aime) 2024, 2024
Mathematical Association of America. American invitational mathematics examination (aime) 2024, 2024. URLhttps://maa.org/
2024
-
[20]
American invitational mathematics examination (aime) 2025, 2025
Mathematical Association of America. American invitational mathematics examination (aime) 2025, 2025. URLhttps://maa.org/
2025
-
[21]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, Suzhou, China, November 2025. Association for Comput...
-
[22]
Learning adaptive parallel reasoning with language models
Jiayi Pan, Xiuyu Li, Long Lian, Charlie Snell, Yifei Zhou, Adam Yala, Trevor Darrell, Kurt Keutzer, and Alane Suhr. Learning adaptive parallel reasoning with language models. In Conference on Language Modeling (COLM), 2025. URL https://arxiv.org/abs/2504. 15466
2025
-
[23]
Yarn: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models. InThe Twelfth International Conference on Learning Representations, 2025
2025
-
[24]
Smith, and Mike Lewis
Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[25]
Learning to reason across parallel samples for llm reasoning.arXiv preprint arXiv:2506.09014, 2025
Jianing Qi, Xi Ye, Hao Tang, Zhigang Zhu, and Eunsol Choi. Learning to reason across parallel samples for llm reasoning.arXiv preprint arXiv:2506.09014, 2025. doi: 10.48550/arXiv.2506. 09014. URLhttps://arxiv.org/abs/2506.09014
-
[26]
Qwen-Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Hogwild! inference: Parallel llm generation via concurrent attention
Gleb Rodionov, Roman Garipov, Alina Shutova, George Yakushev, Erik Schultheis, Vage Egiazarian, Anton Sinitsin, Denis Kuznedelev, and Dan Alistarh. Hogwild! inference: Parallel llm generation via concurrent attention. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. URLhttps://arxiv.org/abs/2504.06261
-
[28]
Self-attention with relative position rep- resentations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position rep- resentations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol. 2: Short Papers), pages 464–468, 2018
2018
-
[29]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021. 12
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems (NIPS 2017), pages 6000–6010, 2017
2017
-
[32]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
2022
-
[34]
Parathinker: Native parallel thinking as a new paradigm to scale llm test-time compute
Hao Wen, Yifan Su, Feifei Zhang, Yunxin Liu, Yunhao Liu, Ya-Qin Zhang, and Yuanchun Li. Parathinker: Native parallel thinking as a new paradigm to scale llm test-time compute. arXiv preprint arXiv:2509.04475, 2025. doi: 10.48550/arXiv.2509.04475. URL https: //arxiv.org/abs/2509.04475
-
[35]
Inference scaling laws: An empirical analysis of compute-optimal inference for llm problem-solving
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for llm problem-solving. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[36]
Multiverse: Your language models secretly decide how to parallelize and merge generation
Xinyu Yang, Yuwei An, Hongyi Liu, Tianqi Chen, and Beidi Chen. Multiverse: Your language models secretly decide how to parallelize and merge generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. URL https://arxiv.org/abs/2506. 09991
2025
-
[37]
Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
2023
-
[38]
https://doi.org/10.48550/arXiv.2509
Tong Zheng, Hongming Zhang, Wenhao Yu, Xiaoyang Wang, Runpeng Dai, Rui Liu, Huiwen Bao, Chengsong Huang, Heng Huang, and Dong Yu. Parallel-r1: Towards parallel thinking via reinforcement learning.arXiv preprint arXiv:2509.07980, 2025. doi: 10.48550/arXiv.2509. 07980. URLhttps://arxiv.org/abs/2509.07980. 13 A Background: Self-attention and Positional Encod...
-
[39]
Alice you are wrong
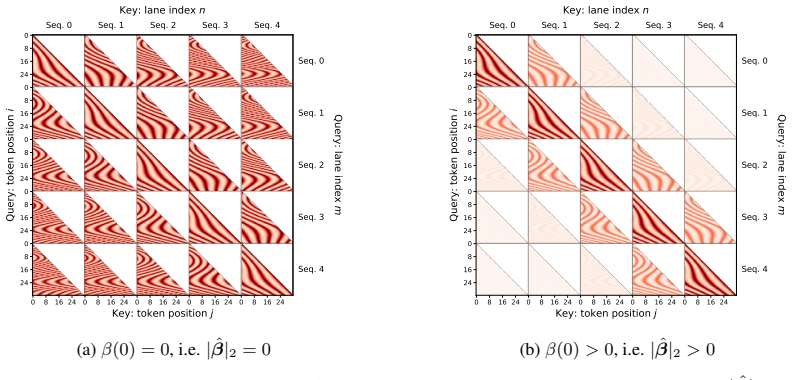
Due to the large initialization norm |β|2 2 = 1000 in the biases of the attention linear layers, we typically use a larger learning rate of 1e-2 only for these parameters. Similarly, we adopt a stronger learning rate of 1e-2 for the LaneRoPE frequency parameters Ω, when tuning these parameters. We also adopt a cosine learning rate scheduler with a warmup ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.