Gradient Transformer: Learning to Generate Updates for LLMs
Pith reviewed 2026-06-29 18:26 UTC · model grok-4.3
The pith
A Gradient Transformer maps TinyLM update vectors to LLM update vectors by learning their correlation on shadow datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
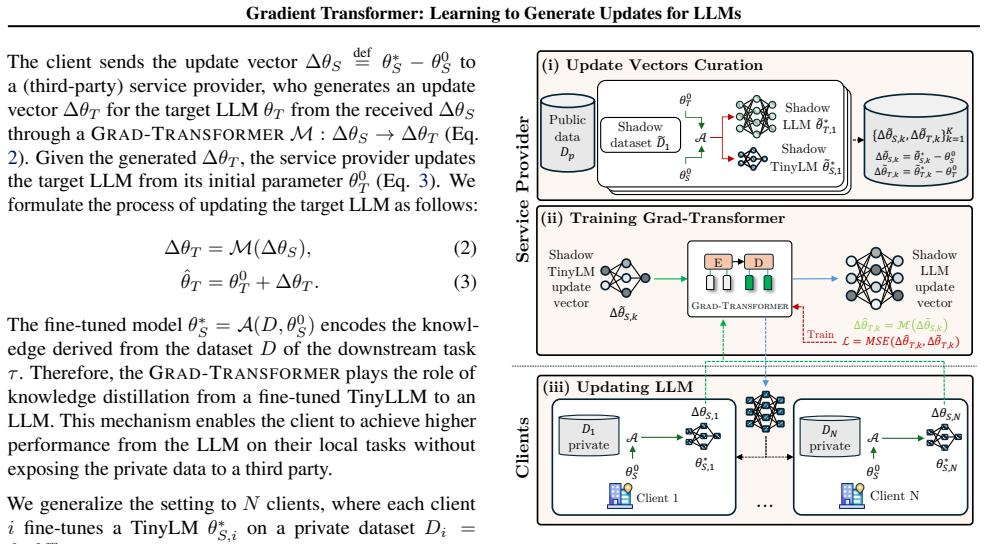
The Gradient Transformer learns a direct mapping from the update vector of a fine-tuned TinyLM to the update vector of the corresponding LLM; once this mapping is fitted on shadow data it can be applied to any new TinyLM update vector produced from private data, thereby producing an effective LLM update without access to the private examples themselves.
What carries the argument
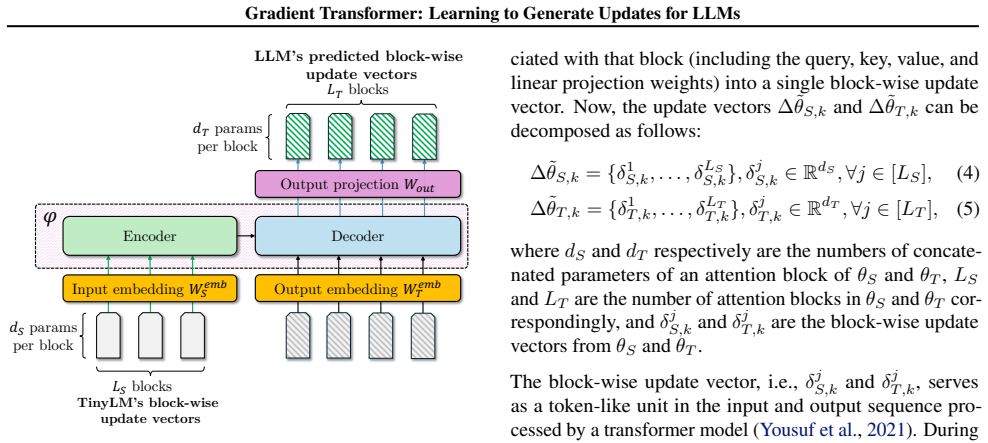
The Gradient Transformer, a model that receives a TinyLM update vector and outputs the corresponding LLM update vector by exploiting the statistical relationship between the two vectors observed on shadow data.
If this is right
- Third parties can generate usable LLM updates from an organization's TinyLM updates without seeing its private data.
- Multiple organizations can combine their TinyLM updates to jointly improve a shared LLM.
- The same pipeline remains effective when differential privacy is enforced on the TinyLM updates.
- The generated LLM updates outperform prior data-free distillation techniques on both language-modeling and reasoning benchmarks.
Where Pith is reading between the lines
- The same vector-mapping idea could be tested on other pairs of model scales or architectures where direct fine-tuning of the larger model is resource-prohibitive.
- If the correlation generalizes across domains, organizations in different sectors could share only their update vectors rather than any raw data.
- The method opens a route for update-based collaboration that avoids both data sharing and full model retraining.
Load-bearing premise
The statistical relationship between TinyLM and LLM update vectors measured on shadow datasets continues to hold for the private data distributions that organizations actually use.
What would settle it
Apply the Gradient-Transformer-generated LLM updates to the target LLM on a held-out private test set; if the resulting performance is no higher than that obtained by simply using the TinyLM updates or by random updates, the mapping does not transfer.
Figures


read the original abstract
Many organizations lack computational resources to fine-tune large language models (LLMs) on private (unshareable) data for better utility, while fine-tuning tiny language models (TinyLMs) alone performs poorly. To address this bottleneck, we propose a data-free knowledge distillation framework that generates LLM update vectors based on TinyLMs fine-tuned on private data. An update vector is a vector of parameter changes from an initial model to its fine-tuned version on a dataset, capturing the effect of cumulative gradient steps during fine-tuning. The key idea of our framework is a novel Gradient Transformer that transforms TinyLM's update vectors into LLM's update vectors. As derived from shadow datasets, Grad-Transformer captures the correlation between TinyLM and LLM update vectors, enabling third-party providers to generate LLM update vectors given the organization's TinyLM update vectors without accessing the organization's private data. The framework supports multi-organization collaboration to jointly update LLMs, improving performance and cost-efficiency. Extensive experiments across language modeling and reasoning tasks show that Grad-Transformer remarkably outperforms state-of-the-art knowledge distillation baselines, even under strict differential privacy protection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Gradient Transformer to learn a mapping from update vectors of fine-tuned TinyLMs to those of LLMs, derived from shadow datasets, to enable generation of LLM updates without access to private data. It claims this supports multi-organization collaboration and outperforms knowledge distillation baselines in experiments on language modeling and reasoning tasks, even under differential privacy.
Significance. Should the learned correlation prove robust to distribution shifts between shadow and private datasets, the approach would offer a novel data-free method for privacy-preserving LLM fine-tuning, with potential impact on collaborative machine learning in regulated domains.
major comments (2)
- Abstract: the central claim that the Gradient Transformer 'captures the correlation between TinyLM and LLM update vectors' as derived from shadow datasets and generalizes to private data is presented without any quantitative evidence, dataset descriptions, performance metrics, or verification of distributional similarity between shadow and private data.
- Abstract: no analysis or experiments are described on how shadow datasets (chosen by the third party) ensure similarity to the organization's private data distribution or on robustness to distribution shift, which is load-bearing for the generalization and multi-organization collaboration claims.
minor comments (1)
- The abstract asserts outperformance 'even under strict differential privacy protection' but supplies no details on the privacy mechanism, its application to update vectors, or empirical impact.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires strengthening with quantitative support and will revise it accordingly. We address the major comments below.
read point-by-point responses
-
Referee: Abstract: the central claim that the Gradient Transformer 'captures the correlation between TinyLM and LLM update vectors' as derived from shadow datasets and generalizes to private data is presented without any quantitative evidence, dataset descriptions, performance metrics, or verification of distributional similarity between shadow and private data.
Authors: We agree the abstract as written states the claim without supporting numbers or details. The body of the manuscript reports concrete results on language modeling and reasoning tasks where Grad-Transformer outperforms the cited knowledge-distillation baselines, together with descriptions of the shadow datasets used to train the transformer. We will revise the abstract to include key performance metrics, dataset references, and a concise statement on the observed generalization from shadow to private data. revision: yes
-
Referee: Abstract: no analysis or experiments are described on how shadow datasets (chosen by the third party) ensure similarity to the organization's private data distribution or on robustness to distribution shift, which is load-bearing for the generalization and multi-organization collaboration claims.
Authors: The observation is correct: the manuscript does not contain dedicated experiments or quantitative analysis measuring distributional similarity or robustness under shift between shadow and private data. The framework description assumes third parties can curate sufficiently aligned shadow data, and the reported experiments demonstrate gains across tasks, but this does not directly test shift robustness. We will add an explicit limitations paragraph discussing the assumption, practical guidance for shadow-data selection, and note robustness to distribution shift as an open question for future work. revision: partial
Circularity Check
No circularity: mapping learned on shadow data then applied to private data is standard supervised transfer, not self-referential
full rationale
The paper trains a Gradient Transformer on shadow datasets (where both TinyLM and LLM update vectors are available) to learn a correlation, then applies the trained model to TinyLM updates from private data. This is an empirical learning setup with no equations or claims showing that the output mapping is defined in terms of itself, that a fitted parameter is renamed as a prediction on the same data, or that any load-bearing step reduces to a self-citation chain. The generalization assumption from shadow to private distributions is an untested empirical claim but does not constitute circularity by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to force the result.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gradient Transformer parameters
axioms (1)
- domain assumption Update vectors from fine-tuning capture the cumulative effect of gradient steps in a transferable way across model sizes
invented entities (1)
-
Gradient Transformer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
B., Mironov, I., Talwar, K., and Zhang, L
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., and Zhang, L. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC conference on computer and communications security, pp. 308–318,
2016
-
[2]
ISBN 9780199535255. 9 Gradient Transformer: Learning to Generate Updates for LLMs doi: 10.1093/acprof:oso/9780199535255.001.0001. URL https://doi.org/10.1093/acprof: oso/9780199535255.001.0001. Bu, Y ., Aminian, G., Toni, L., Wornell, G. W., and Ro- drigues, M. Characterizing and understanding the gener- alization error of transfer learning with gibbs alg...
-
[3]
Generalization bounds for meta-learning: An information-theoretic anal- ysis.Advances in Neural Information Processing Systems, 34:25878–25890, 2021a
Chen, Q., Shui, C., and Marchand, M. Generalization bounds for meta-learning: An information-theoretic anal- ysis.Advances in Neural Information Processing Systems, 34:25878–25890, 2021a. Chen, Y ., Liu, Y ., Chen, L., and Zhang, Y . Dialogsum: A real-life scenario dialogue summarization dataset. In Findings of the Association for Computational Linguis- t...
2021
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dua, D., Wang, Y ., Dasigi, P., Stanovsky, G., Singh, S., and Gardner, M. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378,
2019
-
[6]
A unified framework for quantifying privacy risk in syn- thetic data.Proceedings on Privacy Enhancing Technolo- gies, 2023(2):312–328,
Giomi, M., Boenisch, F., Wehmeyer, C., and Tasn ´adi, B. A unified framework for quantifying privacy risk in syn- thetic data.Proceedings on Privacy Enhancing Technolo- gies, 2023(2):312–328,
2023
-
[7]
Sam- sum corpus: A human-annotated dialogue dataset for abstractive summarization.EMNLP-IJCNLP 2019, pp
Gliwa, B., Mochol, I., Biesek, M., and Wawer, A. Sam- sum corpus: A human-annotated dialogue dataset for abstractive summarization.EMNLP-IJCNLP 2019, pp. 70,
2019
-
[8]
Generating Sequences With Recurrent Neural Networks
Graves, A. Generating sequences with recurrent neural networks.arXiv preprint arXiv:1308.0850,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Guo, J., Chen, H., Wang, C., Han, K., Xu, C., and Wang, Y . Vision superalignment: Weak-to-strong general- ization for vision foundation models.arXiv preprint arXiv:2402.03749,
-
[10]
Scaling Laws for Neural Language Models
Hu, Y ., Wu, F., Li, Q., Long, Y ., Garrido, G. M., Ge, C., Ding, B., Forsyth, D., Li, B., and Song, D. Sok: Privacy- preserving data synthesis. In2024 IEEE Symposium on Security and Privacy (SP), pp. 4696–4713. IEEE, 2024a. Hu, Z., Wei, Y ., Shen, L., Wang, Z., Li, L., Yuan, C., and Tao, D. Sparse model inversion: efficient inversion of vision transforme...
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
Distribution-dependent analysis of gibbs-erm principle
Kuzborskij, I., Cesa-Bianchi, N., and Szepesv ´ari, C. Distribution-dependent analysis of gibbs-erm principle. InConference on Learning Theory, pp. 2028–2054. PMLR,
2028
-
[12]
Data-Free Knowledge Distillation for Deep Neural Networks
Lopes, R. G., Fenu, S., and Starner, T. Data-free knowl- edge distillation for deep neural networks.arXiv preprint arXiv:1710.07535,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Healthcare data security technology: Hipaa compliance
Mbonihankuye, S., Nkunzimana, A., and Ndagijimana, A. Healthcare data security technology: Hipaa compliance. Wireless communications and mobile computing, 2019 (1):1927495,
2019
-
[14]
URL https: //arxiv.org/abs/2412.15115. Raiaan, M. A. K., Mukta, M. S. H., Fatema, K., Fahad, N. M., Sakib, S., Mim, M. M. J., Ahmad, J., Ali, M. E., and Azam, S. A review on large language models: Ar- chitectures, applications, taxonomies, open issues and challenges.IEEE access, 12:26839–26874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Com- monsenseqa: A question answering challenge targeting commonsense knowledge
Talmor, A., Herzig, J., Lourie, N., and Berant, J. Com- monsenseqa: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4149–4158,
2019
-
[16]
Fine tuning llm for enterprise: Practical guidelines and recommendations
VM, K., Warrier, H., Gupta, Y ., et al. Fine tuning llm for enterprise: Practical guidelines and recommendations. arXiv preprint arXiv:2404.10779,
-
[17]
Yao, W., Yang, W., Xu, G., Wang, Z., Lin, Y ., and Liu, Y . The capabilities and limitations of weak-to-strong generalization: Generalization and calibration.arXiv preprint arXiv:2502.01458,
-
[18]
A., and Shaalan, K
11 Gradient Transformer: Learning to Generate Updates for LLMs Yousuf, H., Lahzi, M., Salloum, S. A., and Shaalan, K. A systematic review on sequence-to-sequence learning with neural network and its models.International Journal of Electrical & Computer Engineering (2088-8708), 11(3),
2088
-
[19]
Datasets and Evaluation Metrics A.1
12 Gradient Transformer: Learning to Generate Updates for LLMs A. Datasets and Evaluation Metrics A.1. Dataset descriptions Table 5.Datasets, tasks, and evaluation metrics in experiments. Dataset Task Metric AQuA-RAT Math Reasoning Acc (EM) GSM8K Math Reasoning Acc (EM) CommonsenseQA Commonsense Reasoning Acc (EM) DROP Discrete Reasoning Acc (EM) SAMSum D...
2017
-
[20]
with a measurable functiong, we have: I(w, D p) =D KL(Pw,Dp ∥PwPDp)(19) = sup g n Ew,Dp[g(w, Dp)]−logE ˜w,Dp h eg( ˜w,Dp) io (20) ≥λE w,Dp[RDp(w)]−logE ˜w,Dp[eλRDp( ˜w)],∀λ∈R(21) =λE w,Dp[RDp(w)]−λE ˜w,Dp[RDp( ˜w)]−ψ˜w,Dp(λ).(22) It’s worth noting thatDp is i.i.d sampled from ˜µ, i.e., ∀z∈D p :z∼˜µ , resulting in Dp also follows the distribution ˜µ. We 14...
2013
-
[21]
methods as our baselines. Although these methods do not offer data privacy for clients since they need data sharing between the TinyLM and the LLM, we use them as baselines since they are most applicable to our setting. Previous works in Data-Free Knowledge Distillation are not able to be applied in our experiments since they are only applicable to text c...
2024
-
[22]
Firstly, we provide some basic background on differential privacy (Dwork,
as the client-side training mechanism A to obtain differential privacy protection for client’s unshareable data (Dwork, 2006). Firstly, we provide some basic background on differential privacy (Dwork,
2006
-
[23]
Differential Privacy.Differential privacy (DP) (Dwork,
and the DP-SGD mechanism (Abadi et al., 2016). Differential Privacy.Differential privacy (DP) (Dwork,
2016
-
[24]
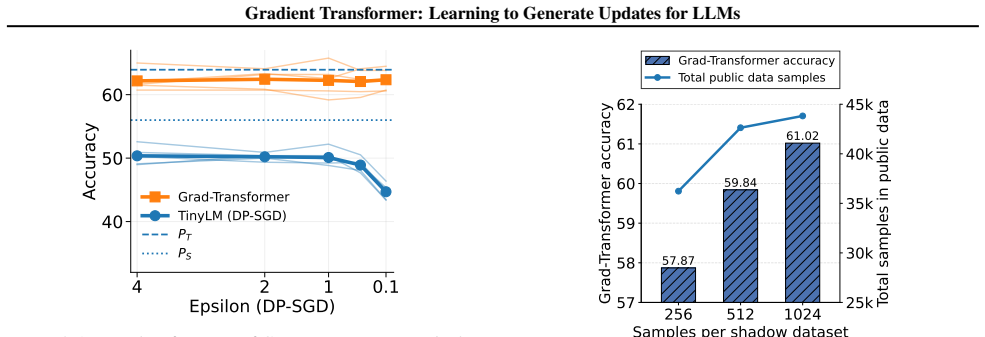
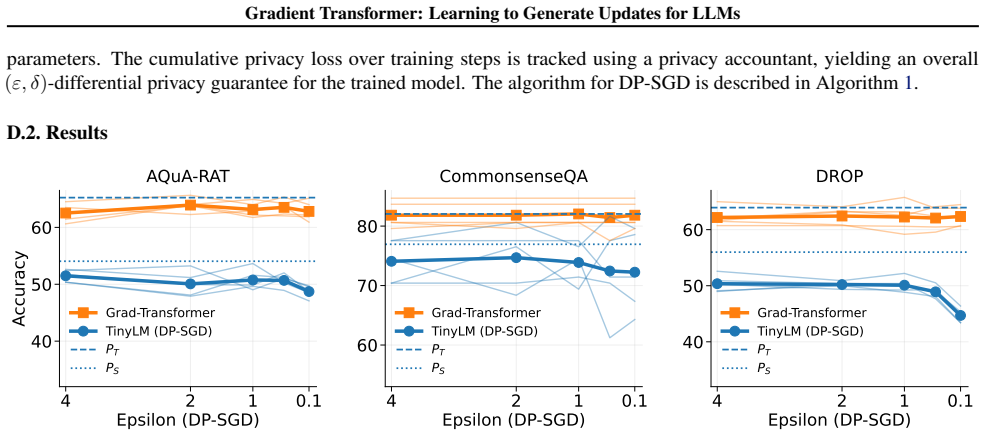
This figure demonstrates that GRAD-TRANSFORMERconsistently perform well using under DP-SGD fine-tuning of the TinyLMs for AQuA-RAT, CommonsenseQA and DROP datasets. E. Additional Experiments and Analysis E.1. Clients with different tasks E.1.1. EACH CLIENT HAVING AN INDEPENDENT TASK Table 7.Results of 3 client setting with different tasks on each client. ...
2000
-
[25]
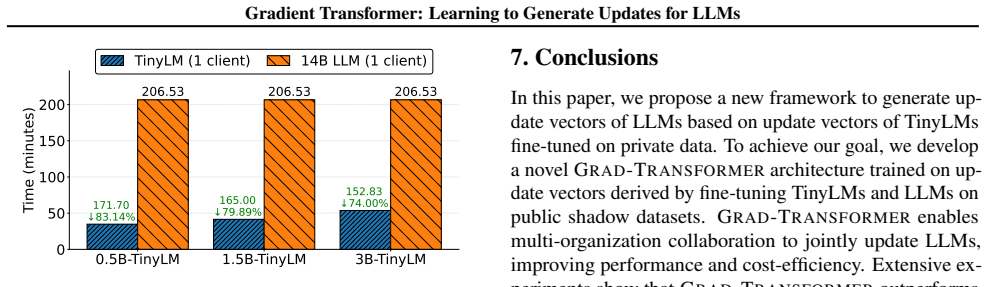
AQR: AQuA-RAT. Stage AQR GSM8K DROP Fine-tune 3B-TinyLM (1 client) 53.70 50.47 101.13 Fine-tune 7B-LLM (1 client) 71.54 56.45 160.43 Time saved using Grad-Transformer 17.84 5.98 59.30 Time reduction in percentage 24.93% 10.59% 36.96% Table 11.GRAD-TRANSFORMERframework time consumption analysis using one NVIDIA A100 80GB GPU. Time consumption is computed w...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.