Learning to Translate from Soft to Hard LLM Prompts
Pith reviewed 2026-06-29 18:17 UTC · model grok-4.3
The pith
A trained translator converts soft LLM prompts into natural language text that outperforms training-free methods and transfers better to large models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Training a dedicated soft-prompt-to-natural-language translation model yields higher quality verbalizations than training-free methods. Soft prompts optimized on small open-source models can thereby be converted into portable text prompts that, when deployed on larger closed-API models, exceed the performance of the original soft prompt and sometimes even few-shot learning.
What carries the argument
A trained translator model that maps soft prompt embeddings to natural language text by learning to verbalize task-relevant information encoded in the soft prompt.
If this is right
- Soft prompts gain interpretability through their natural language equivalents.
- Optimized soft prompts become portable from small open models to large closed models without retraining.
- The translated text prompts can exceed the source soft prompt performance on the target model.
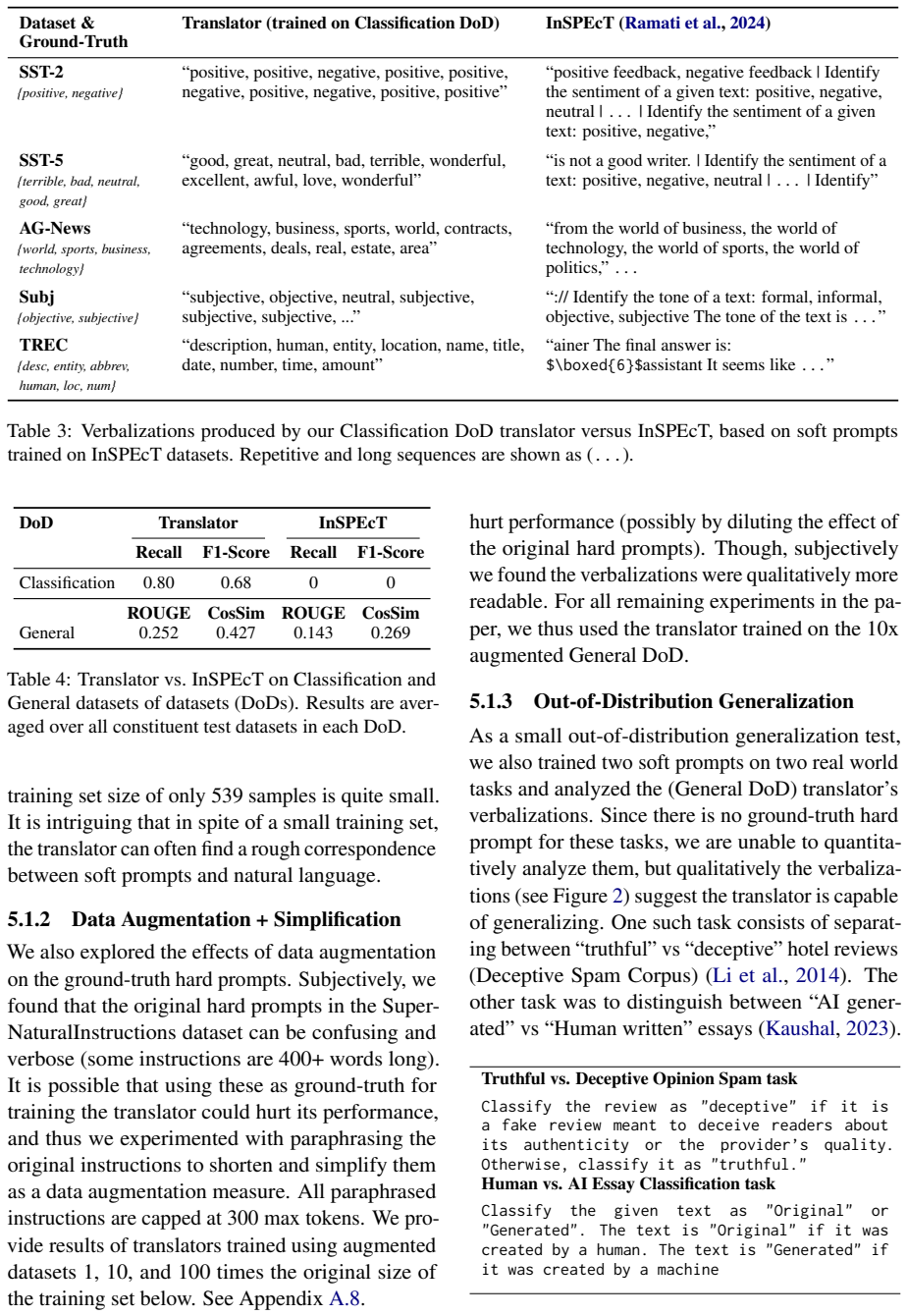
- The approach outperforms InSPEcT on both quantitative and qualitative measures across tested DoDs.
Where Pith is reading between the lines
- Prompt optimization could shift to small accessible models followed by translation for deployment on paid APIs.
- The translation step might reduce the need for manual prompt engineering directly on large models.
- A hybrid workflow becomes feasible where continuous tuning happens on local hardware and discrete text is used in production.
Load-bearing premise
The translator faithfully preserves task-relevant information from the soft prompt when converting it to text without introducing distortions that change how the downstream LLM behaves.
What would settle it
If a soft prompt is translated to text and that text prompt yields lower task accuracy on a large model than the original soft prompt achieves on the same large model, or lower accuracy than few-shot learning on that model.
Figures




read the original abstract
Soft prompt tuning is a parameter-efficient method for adapting LLMs to specific tasks, but suffers from a lack of interpretability. Building on recent work on interpreting soft prompts (Ramati et al., 2024), we explore how training a dedicated soft prompt to natural language translation model can yield higher translation quality. In particular, in both quantitative and qualitative comparisons on multiple Datasets of Datasets (DoDs), we demonstrate that our translator produces fluent, accurate verbalizations that outperforms existing training-free methods like InSPEcT. In addition to advancing interpretability, our work suggests a promising downstream application: soft prompts optimized on small, open-source models can be translated into portable text prompts that, when deployed on larger closed-API models, exceed the performance of the original soft prompt and, in some cases, even few-shot learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes training a dedicated model to translate soft (continuous) prompts into natural-language (hard) prompts. It reports that this translator yields higher-quality verbalizations than training-free baselines such as InSPEcT across multiple Datasets of Datasets (DoDs), both quantitatively and qualitatively. The work further claims a downstream portability benefit: soft prompts tuned on small open-source models can be translated into text prompts that, when applied to larger closed-API models, outperform the original soft prompt and, in some cases, few-shot learning.
Significance. If the portability result holds under properly matched baselines, the approach would provide a practical route to interpretability and cross-model reuse of prompt tuning, allowing efficient optimization on accessible models followed by deployment on proprietary APIs. The explicit comparison to InSPEcT and the use of multiple DoDs are positive elements that could strengthen the interpretability literature.
major comments (2)
- [Abstract] Abstract (and downstream-application paragraph): the central portability claim states that translated prompts 'exceed the performance of the original soft prompt' on larger closed-API models. Because soft prompts are tied to a model's specific embedding space, the baseline is undefined without explicit clarification of whether 'original soft prompt' performance refers to (a) the small-model result, (b) a newly optimized soft prompt on the large model, or (c) some proxy transfer. This comparison is load-bearing for the claimed advantage and must be stated with matching evaluation protocols.
- [Evaluation] Evaluation sections (quantitative comparisons on DoDs): the manuscript asserts quantitative superiority but the provided abstract supplies no dataset cardinalities, number of DoDs, statistical tests, or error bars. If these details are absent or insufficiently reported in the full experimental sections, the superiority claims over InSPEcT cannot be assessed.
minor comments (2)
- [Abstract] Notation: the term 'Datasets of Datasets (DoDs)' is introduced without an explicit definition or citation on first use; a brief parenthetical or footnote would improve clarity.
- [Introduction] Related work: the citation to Ramati et al. (2024) is appropriate but the manuscript should state precisely which components of that prior interpreter are reused versus extended by the new trained translator.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript for improved clarity where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (and downstream-application paragraph): the central portability claim states that translated prompts 'exceed the performance of the original soft prompt' on larger closed-API models. Because soft prompts are tied to a model's specific embedding space, the baseline is undefined without explicit clarification of whether 'original soft prompt' performance refers to (a) the small-model result, (b) a newly optimized soft prompt on the large model, or (c) some proxy transfer. This comparison is load-bearing for the claimed advantage and must be stated with matching evaluation protocols.
Authors: We agree the abstract wording is ambiguous on the baseline. The 'original soft prompt' refers to its performance on the small open-source model where it was optimized. The translated prompt is evaluated on the larger closed-API model, and we demonstrate it exceeds that small-model performance. This is the core portability benefit, as direct soft-prompt application to the large model is not possible. We will revise the abstract and downstream paragraph to explicitly state the models and protocols used for each side of the comparison. revision: yes
-
Referee: [Evaluation] Evaluation sections (quantitative comparisons on DoDs): the manuscript asserts quantitative superiority but the provided abstract supplies no dataset cardinalities, number of DoDs, statistical tests, or error bars. If these details are absent or insufficiently reported in the full experimental sections, the superiority claims over InSPEcT cannot be assessed.
Authors: The full experimental sections report the number of DoDs, dataset cardinalities, error bars on all results, and statistical tests versus InSPEcT (see Section 4 and Appendix B). These details support the quantitative claims. The abstract was kept brief, but we can add a short summary of the setup if the editor prefers. revision: no
Circularity Check
No circularity; empirical method with no load-bearing derivations
full rationale
The paper describes training a dedicated translator model from soft prompts to natural language text prompts, evaluated empirically on Datasets of Datasets against baselines like InSPEcT. No equations, parameter-fitting steps presented as predictions, or self-citation chains are referenced in the provided text that would reduce any claimed result to its own inputs by construction. The downstream portability claim is an empirical observation, not a derived equality. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards a general rule for identifying decep- tive opinion spam. InProceedings of the 52nd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1566– 1576, Baltimore, Maryland. Association for Compu- tational Linguistics. 9 Chin-Yew Lin. 2004. ROUGE: A package for auto- matic evaluation of summaries. InText Summ...
-
[2]
Prompting a pretrained transformer can be a universal approximator.Preprint, arXiv:2402.14753. Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2023. Exploring the limits of transfer learning with a unified text-to-text trans- former.Preprint, arXiv:1910.10683. Dana Ramati, Danie...
-
[3]
To keep at least 90% of the instance data, we picked 400 to- kens as the threshold for this filtration
Filter out any instance sequences (input + out- put) longer than 400 tokens, as we found that there were certain instances where the sequence length was over 200k tokens, with P99 of 1312 and P90 of 337. To keep at least 90% of the instance data, we picked 400 to- kens as the threshold for this filtration
-
[4]
Hence, we decided to use 500 instances as a minimum threshold for selecting tasks for future experiments
Filter out any tasks with less than 500 in- stances, as we found that some tasks had a minimum of 29 instances only, which would not be sufficient for training soft prompts. Hence, we decided to use 500 instances as a minimum threshold for selecting tasks for future experiments
-
[5]
Added a column for total tokens of input + out- put sequences, calculated using tokenizer of meta-llama/Llama-3.1-8B-Instruct lan- guage model, as we dynamically use it later during soft prompt training, for data collation
-
[6]
You are an expert at simplifying and extremely condensing instructions
Created instances of (input, output[ i]) pairs (unwinding), if the output is an array of multi- ple values for a given input, for all values of i in the output array. In the end, we were left with 539 tasks for train- ing split and 96 tasks for testing split. A.8 Data Augmentation on General DoD In order to test our hypothesis of whether the trans- lator ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.