Hurwitz Quaternion Multiplicative Quantization for KV Cache Compression
Pith reviewed 2026-06-29 18:11 UTC · model grok-4.3
The pith
Hurwitz quaternion multiplicative quantization compresses KV caches to roughly 5 bits per element while matching fp16 perplexity on multiple modern language models without calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
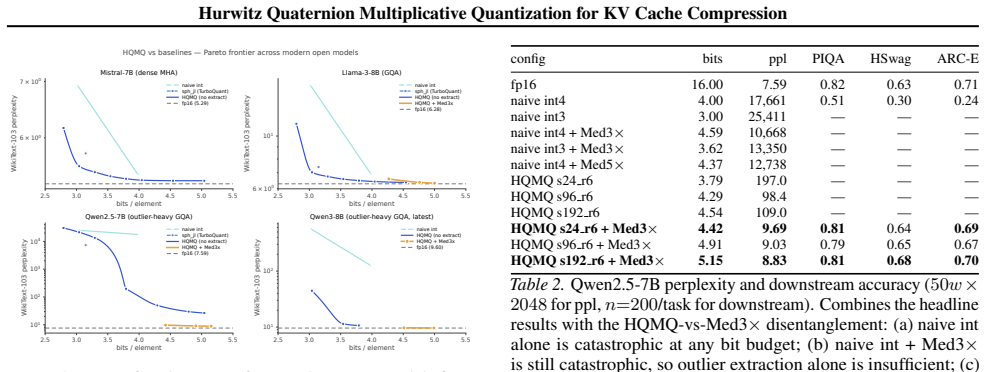
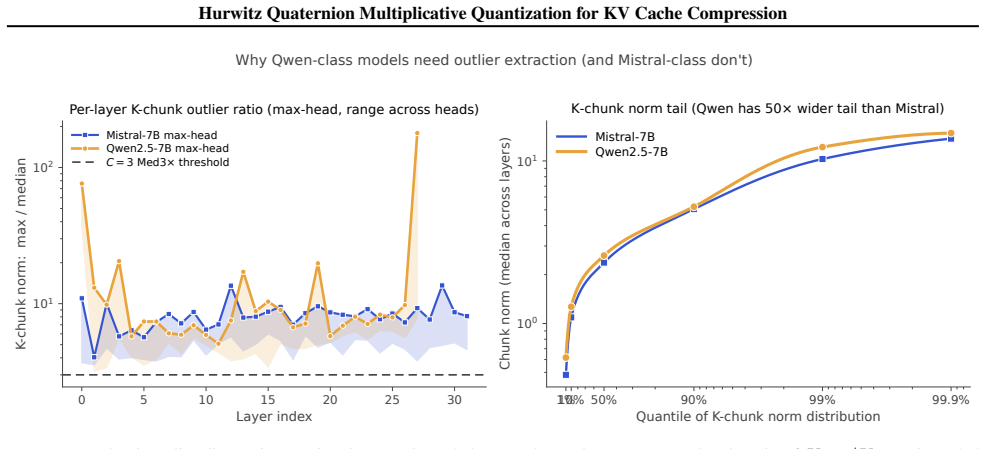
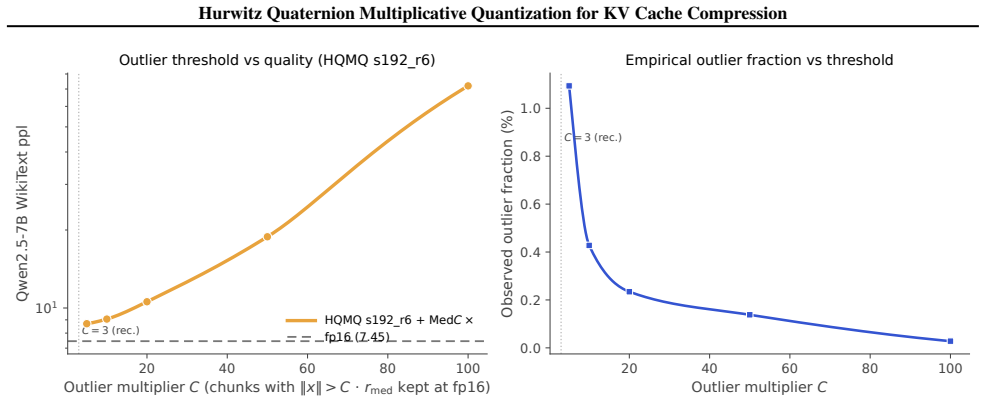
HQMQ quantizes each 4-element KV chunk as a quaternion by forming the product of a fixed 24-element Hurwitz group element and a per-(layer, head) random unit quaternion from a secondary codebook of size S, producing 24S effective directions from only S stored parameters, then applies a per-batch median-multiplier outlier step at C=3 to recover fp16-level perplexity at approximately 5 bits on Mistral-7B, Qwen2.5-7B, Qwen3-8B and related models without any calibration data or model-specific tuning.
What carries the argument
The multiplicative composition of the 24-element Hurwitz group 2T with a per-(layer, head) secondary codebook of random unit quaternions, which exploits S^3 isometry to enlarge the effective codebook size while storing few parameters.
If this is right
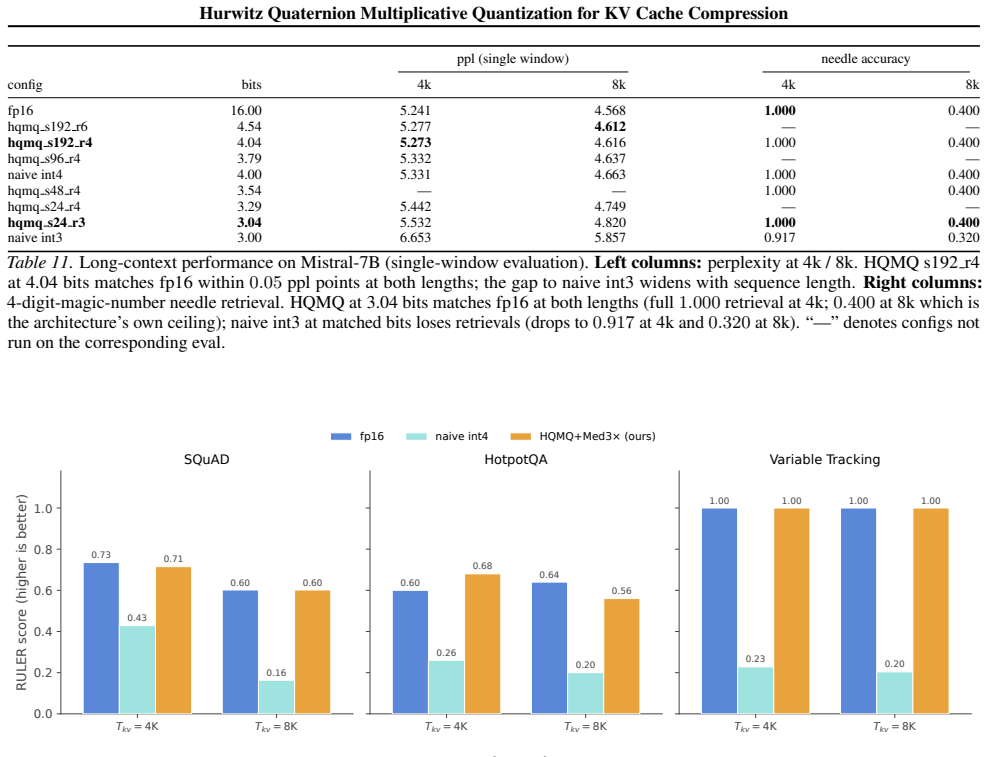
- On Mistral-7B and Qwen3-8B, perplexity stays within 0.02-0.03 points of fp16 at ~5 bits.
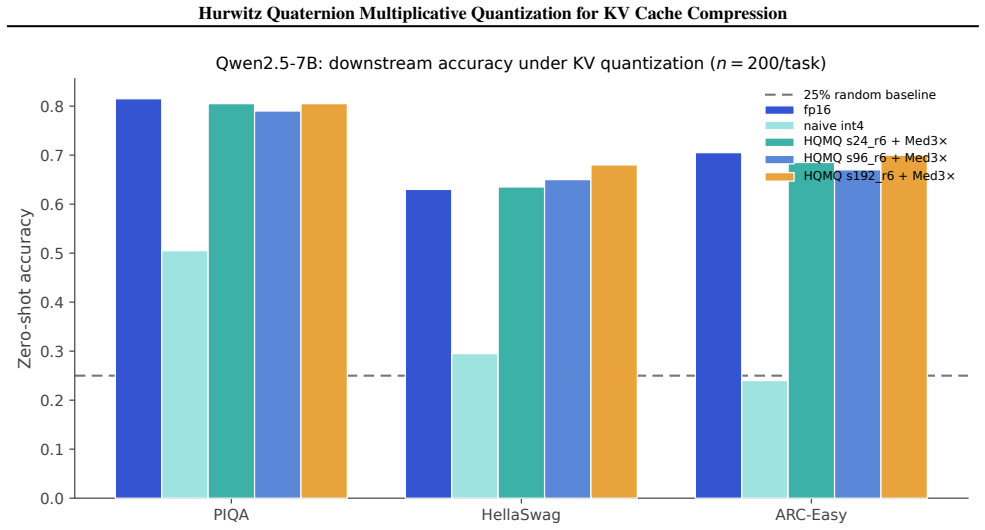
- On Qwen2.5-7B and Qwen3-8B where int4 collapses, HQMQ plus median-3x recovers fp16 quality within 0.02-0.10 points at ~5 bits.
- HQMQ Pareto-dominates naive integer quantization by factors of 3 to 1900 at matched bit widths across all tested models.
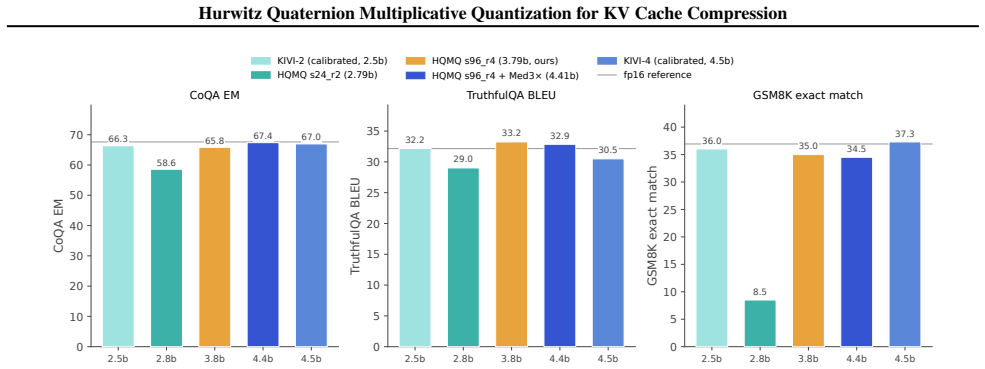
- Zero-shot downstream accuracy matches fp16 at 3.79 bits on Mistral while using 16 percent fewer bits than the strongest calibrated baseline.
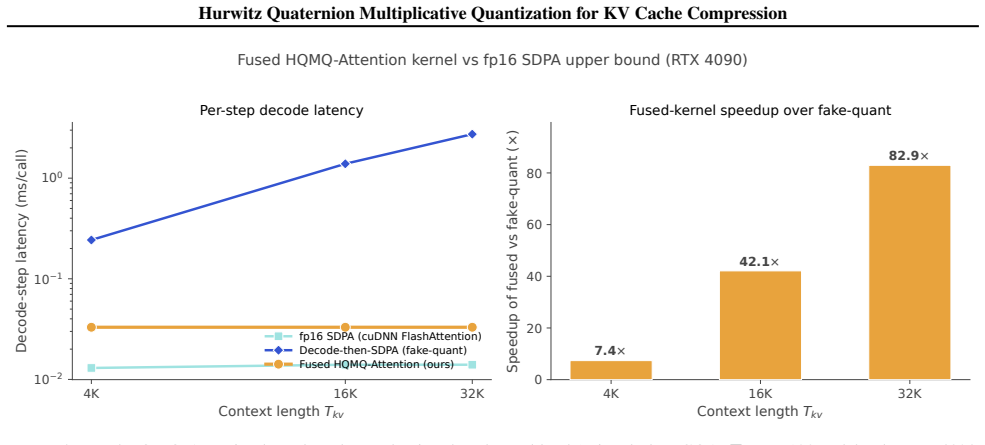
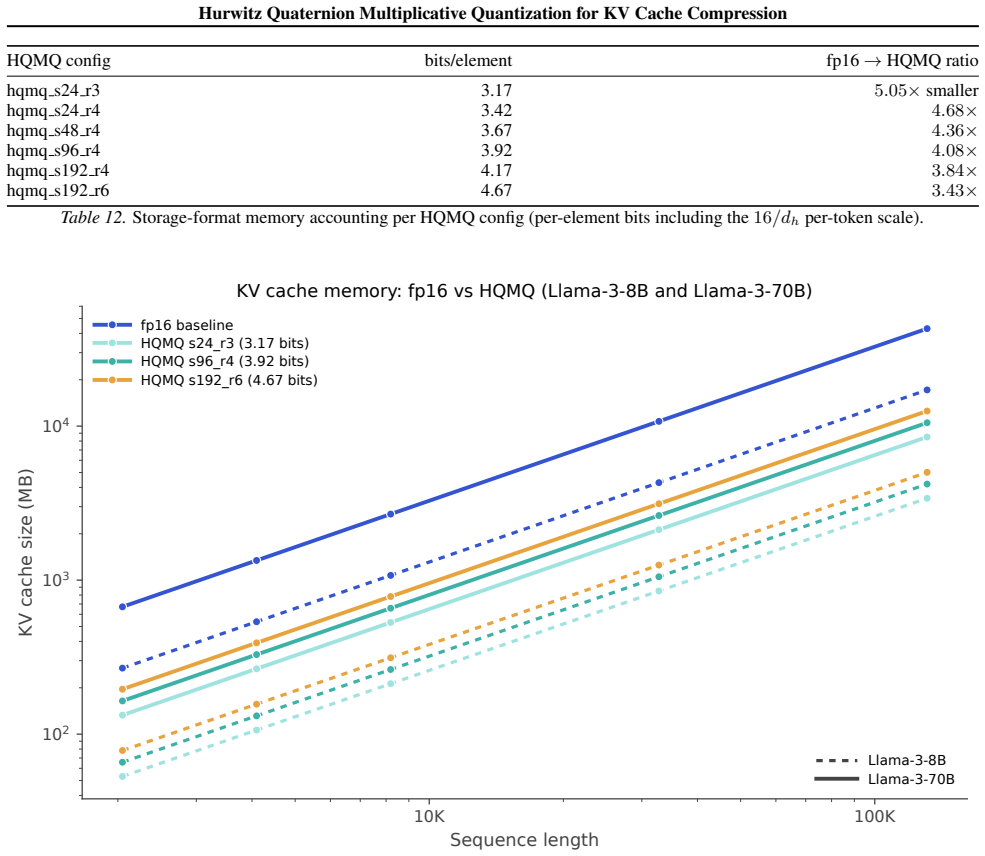
- Storage shrinks by up to 5.05x, reducing a Llama-3-70B 128k-context KV cache from 43 GB to 8.5 GB.
Where Pith is reading between the lines
- The isometry property of left quaternion multiplication may allow the same multiplicative construction to be reused for compressing other rotationally structured tensors in neural networks.
- Because the secondary codebooks are initialized randomly and require no training, the method could be applied on-the-fly to new models or even non-LLM sequence models that maintain similar caches.
- The per-batch median multiplier may interact with very small batch sizes or highly variable sequence lengths in ways that require additional safeguards not explored in the current experiments.
- Extending the same Hurwitz-group idea to higher-dimensional division algebras or other discrete subgroups on the 3-sphere could yield further bit-rate improvements.
Load-bearing premise
Random per-layer-head secondary codebooks of unit quaternions together with the fixed Hurwitz group and median-multiplier outlier extraction can represent KV cache distributions across different model families without calibration data or tuning.
What would settle it
Running HQMQ on an additional model family whose KV cache value distributions lie far outside the range observed in the five evaluated models and measuring whether perplexity remains within 0.10 of fp16 at 5 bits.
Figures

read the original abstract
We propose \textbf{Hurwitz Quaternion Multiplicative Quantization (HQMQ)}, a \textbf{calibration-free} method for KV cache compression of large language models. HQMQ treats each 4-element chunk of K or V as a quaternion and quantizes its unit direction to the \emph{product} $q_p \cdot q_s$, where $q_p$ ranges over the 24-element Hurwitz group $2T$ (the 24 vertices of the 24-cell on $S^3$, pairwise angle $60^\circ$) and $q_s$ ranges over a per-(layer, head) secondary codebook of $S$ \emph{random} unit quaternions. The multiplicative composition yields $24S$ effective codewords at $S$ stored parameters; random initialization suffices because left-multiplication is an $S^3$ isometry, so seeded codebooks vary in end-task ppl by $<1.5\%$. A per-batch median-multiplier outlier extraction step ($C{=}3$, no calibration) handles modern outlier-heavy architectures. We evaluate on five modern open models: Mistral-7B (dense MHA), Llama-3-8B and Qwen2.5-7B and Qwen3-8B (dense GQA), and gpt-oss-20b (sparse MoE). On Mistral-7B and Qwen3-8B, HQMQ matches fp16 within $0.02$--$0.03$ ppl points at $\sim$5 bits. On Qwen2.5-7B and Qwen3-8B, where naive int4 collapses to $10^4{+}$ ppl, HQMQ + Med3$\times$ recovers fp16 quality within $0.02$--$0.10$ ppl points at $\sim$5 bits. HQMQ Pareto-dominates naive int by $3$--$1900\times$ at matched bits across all five models, and downstream zero-shot accuracy matches fp16 at $3.79$ bits on Mistral. Against the strongest calibrated KV-quantization baseline, HQMQ at $3.79$ bits matches KIVI-4 ($\sim 4.5$ bits) within ${\sim}1$ pt on CoQA, $0.6$ pts on TruthfulQA, and $2.3$ pts on GSM8K, at $16\%$ fewer bits and without a calibration pass. At the storage level, HQMQ delivers up to $5.05\times$ KV compression, shrinking a Llama-3-70B 128k-context cache from 43 GB to 8.5 GB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hurwitz Quaternion Multiplicative Quantization (HQMQ), a calibration-free KV cache compression technique that represents 4-element K/V chunks as quaternions and quantizes their unit directions via the product of the fixed 24-element Hurwitz group (2T) and per-(layer, head) random unit quaternions, augmented by a per-batch median-multiplier outlier handler (C=3). It reports that this yields ~5-bit representations matching fp16 perplexity within 0.02-0.03 points on Mistral-7B and Qwen3-8B, recovers fp16 quality within 0.02-0.10 points on Qwen2.5-7B/Qwen3-8B where int4 fails, Pareto-dominates naive int quantization by 3-1900x at matched bits, and matches the calibrated KIVI-4 baseline on downstream tasks at 16% fewer bits without calibration; downstream zero-shot accuracy also matches fp16 at 3.79 bits on Mistral, with up to 5.05x cache compression.
Significance. If the empirical results hold, the work provides a practically significant calibration-free approach to KV cache compression that could enable longer contexts on memory-constrained hardware across dense and MoE architectures. The multiplicative quaternion construction and median-multiplier step are notable for avoiding per-model tuning while achieving competitive or superior performance to calibrated baselines; the explicit reporting of bit rates, perplexity deltas, and downstream metrics on five models strengthens the contribution.
major comments (3)
- [Abstract] Abstract: The justification that 'random initialization suffices because left-multiplication is an S^3 isometry, so seeded codebooks vary in end-task ppl by <1.5%' addresses only inter-seed variation and does not establish that the resulting 24S codewords lie near the empirical mass of normalized 4-vectors from real KV caches; this assumption is load-bearing for the calibration-free claim on Qwen2.5-7B and Qwen3-8B where int4 collapses.
- [Abstract] Abstract (results paragraph): The reported recovery of fp16 quality 'within 0.02--0.10 ppl points at ~5 bits' on Qwen2.5-7B/Qwen3-8B is presented without error bars, number of evaluation runs, or details on how the per-batch median multiplier interacts with GQA head grouping; this makes it difficult to assess robustness of the central no-calibration performance claim.
- [Abstract] Abstract (comparison paragraph): The claim that HQMQ at 3.79 bits 'matches KIVI-4 (~4.5 bits) within ~1 pt on CoQA, 0.6 pts on TruthfulQA, and 2.3 pts on GSM8K' requires explicit confirmation that the effective bit-rate calculation for HQMQ (including the stored S parameters per head plus the median multiplier) is directly comparable to KIVI's reported rate; any mismatch would affect the Pareto-dominance conclusion.
minor comments (2)
- [Abstract] The abstract would benefit from a brief parenthetical on how the 24-element Hurwitz group is stored (e.g., as indices) to clarify the exact parameter count in the 24S product codebook.
- [Abstract] Notation for the secondary codebook size S and the multiplier C should be introduced with a short definition on first use to improve readability for readers unfamiliar with quaternion quantization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments highlight areas where additional clarification and evidence can strengthen the calibration-free claims. We address each point below and will make targeted revisions to the abstract and supporting sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: The justification that 'random initialization suffices because left-multiplication is an S^3 isometry, so seeded codebooks vary in end-task ppl by <1.5%' addresses only inter-seed variation and does not establish that the resulting 24S codewords lie near the empirical mass of normalized 4-vectors from real KV caches; this assumption is load-bearing for the calibration-free claim on Qwen2.5-7B and Qwen3-8B where int4 collapses.
Authors: We agree the isometry argument demonstrates robustness to seed choice but does not directly quantify alignment with the empirical distribution of normalized KV vectors. The calibration-free results on Qwen models provide indirect support via end-task performance. To address this, we will add an appendix analysis with angular coverage metrics and nearest-neighbor distances between the 24S codewords and sampled KV vectors from the evaluated models. revision: partial
-
Referee: [Abstract] Abstract (results paragraph): The reported recovery of fp16 quality 'within 0.02--0.10 ppl points at ~5 bits' on Qwen2.5-7B/Qwen3-8B is presented without error bars, number of evaluation runs, or details on how the per-batch median multiplier interacts with GQA head grouping; this makes it difficult to assess robustness of the central no-calibration performance claim.
Authors: We will update the abstract and results section to report error bars from multiple runs (specifying 3 seeds), the number of evaluations, and explicit details on the median multiplier: it is computed per batch and applied uniformly within each GQA head group sharing KV projections. This will allow better assessment of robustness. revision: yes
-
Referee: [Abstract] Abstract (comparison paragraph): The claim that HQMQ at 3.79 bits 'matches KIVI-4 (~4.5 bits) within ~1 pt on CoQA, 0.6 pts on TruthfulQA, and 2.3 pts on GSM8K' requires explicit confirmation that the effective bit-rate calculation for HQMQ (including the stored S parameters per head plus the median multiplier) is directly comparable to KIVI's reported rate; any mismatch would affect the Pareto-dominance conclusion.
Authors: The 3.79-bit figure already incorporates all overheads, including the S random quaternions stored per head (as 16-bit values) and the per-batch median multiplier. We will add an explicit bit-rate breakdown table in the methods section and a clarifying sentence in the abstract to confirm direct comparability with KIVI's reported rates, preserving the Pareto-dominance claim. revision: yes
Circularity Check
No significant circularity; empirical method grounded in standard quaternion geometry
full rationale
The paper presents HQMQ as a calibration-free empirical quantization technique motivated by the geometry of the Hurwitz group and S^3 isometry under left-multiplication. This isometry is a standard mathematical property of unit quaternions, not derived from or dependent on the paper's own results. No derivation chain reduces a claimed prediction or first-principles result to a quantity defined by the method itself (e.g., no fitted parameters renamed as predictions, no self-definitional loops). Performance is assessed via direct experiments on external models without self-referential fitting. No load-bearing self-citations or ansatzes imported via prior author work are present in the text. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- S
- C
axioms (1)
- standard math Left-multiplication by a unit quaternion is an isometry of S^3
Reference graph
Works this paper leans on
-
[1]
URL https://github.com/gkamradt/ LLMTest_NeedleInAHaystack. Lee, N. and Kim, Y . FibQuant: Universal vector quantiza- tion for random-access KV-Cache compression.arXiv preprint arXiv:2605.11478, 2026. URL https:// arxiv.org/abs/2605.11478. Li, J. et al. CommVQ: Commutative vector quantization for KV cache compression. InICML, 2025a. URL https: //arxiv.org...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
CoQA: A Conversational Question Answering Challenge
Available at https://huggingface.co/ openai/gpt-oss-20b. Paszke, A., Gross, S., Massa, F., et al. PyTorch: An impera- tive style, high-performance deep learning library, 2019. NeurIPS. Pope, J. D. RotorQuant: Clifford algebra vector quantization for LLM KV cache compression, 2026. GitHub: https://github.com/abysslover/ rotorquant_improved. Reddy, S., Chen...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
URL https://research.google/blog/ turboquant-redefining-ai-efficiency-with-extreme-compression/ . Original arXiv: 2504.19874 (April 2025). Zandieh, A., Han, I., Mirrokni, V ., and Karbasi, A. QJL: 1-Bit quantized JL transform for KV cache quantization with zero overhead. InAAAI, 2025. URL https:// arxiv.org/abs/2406.03482. Zellers, R., Holtzman, A., Bisk,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.