Disentangling Language Roles in Multilingual LLM Task Execution
Pith reviewed 2026-06-29 18:13 UTC · model grok-4.3
The pith
The language placed in the response slot drives most performance loss in multilingual LLM tasks, outweighing instruction or content mismatches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
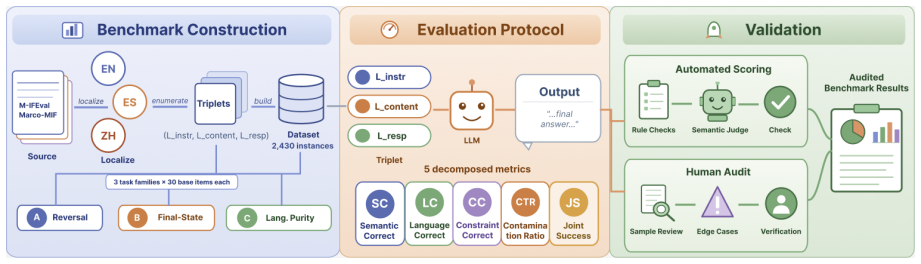
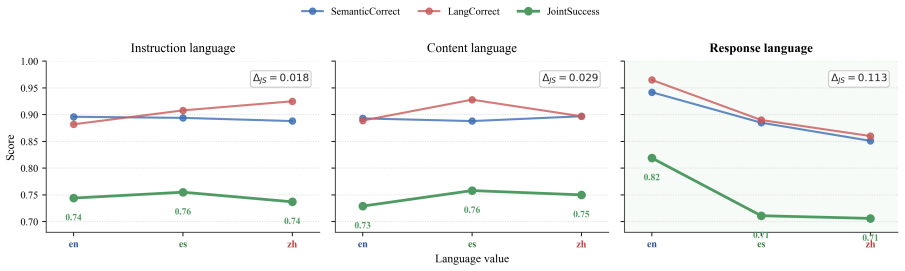
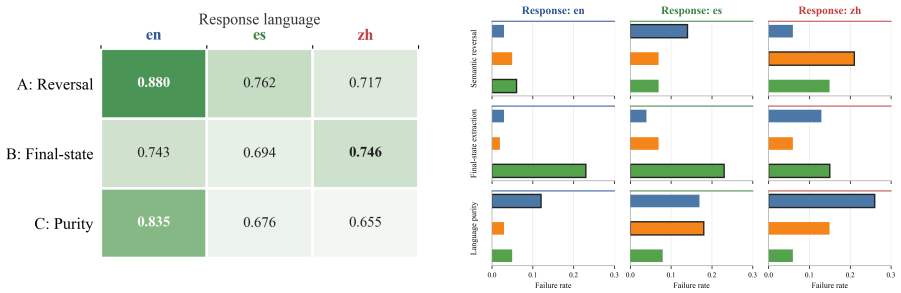
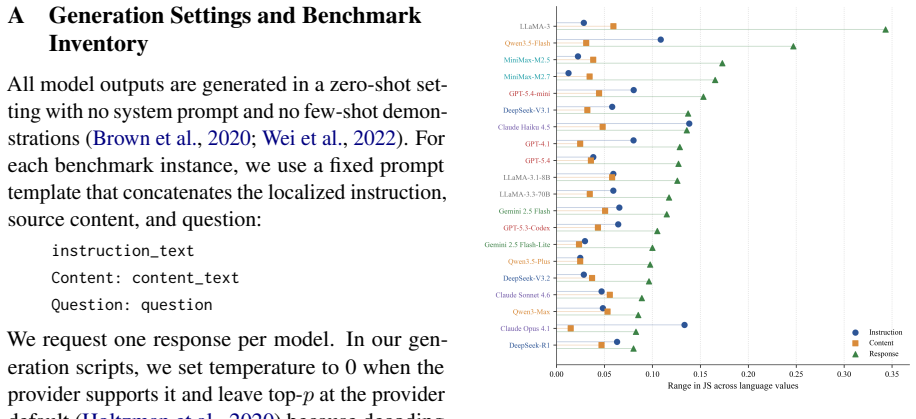
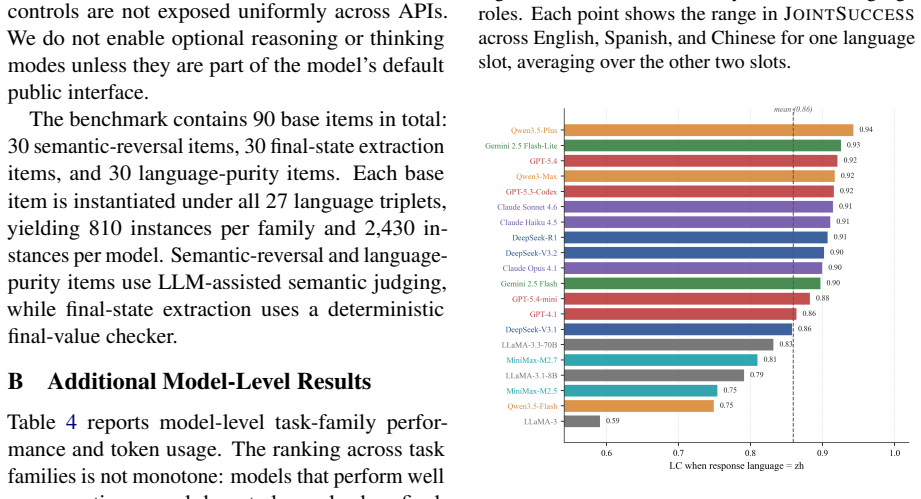
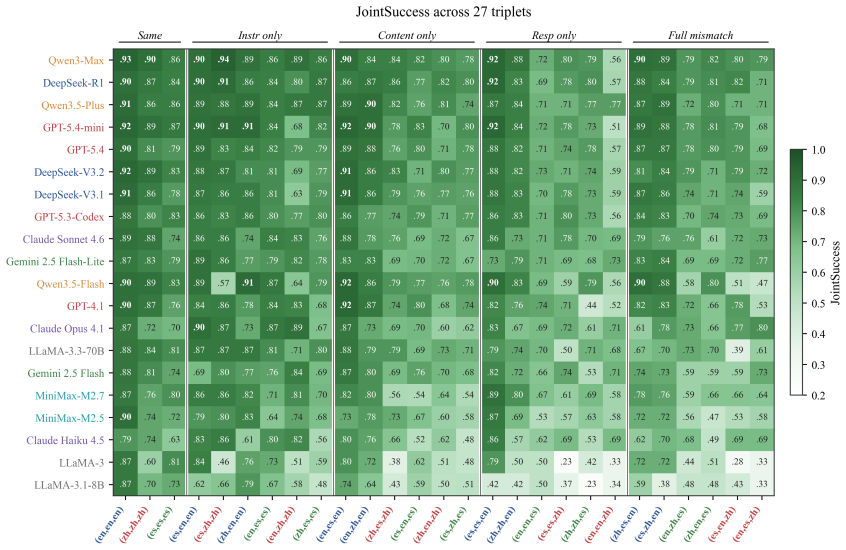
MTM-Bench defines each instance by the triplet (L_instr, L_content, L_resp) and enumerates all 27 combinations across English, Spanish, and Chinese for 2430 instances per model. Evaluation with decomposed metrics reveals that the response-language role organizes most variation in semantic correctness, target-language adherence, constraint satisfaction, and joint success. A single response-slot mismatch accounts for the bulk of degradation, mismatch count is not a monotonic predictor, model orderings shift with mismatch pattern, and the three task families fail through distinct channels.
What carries the argument
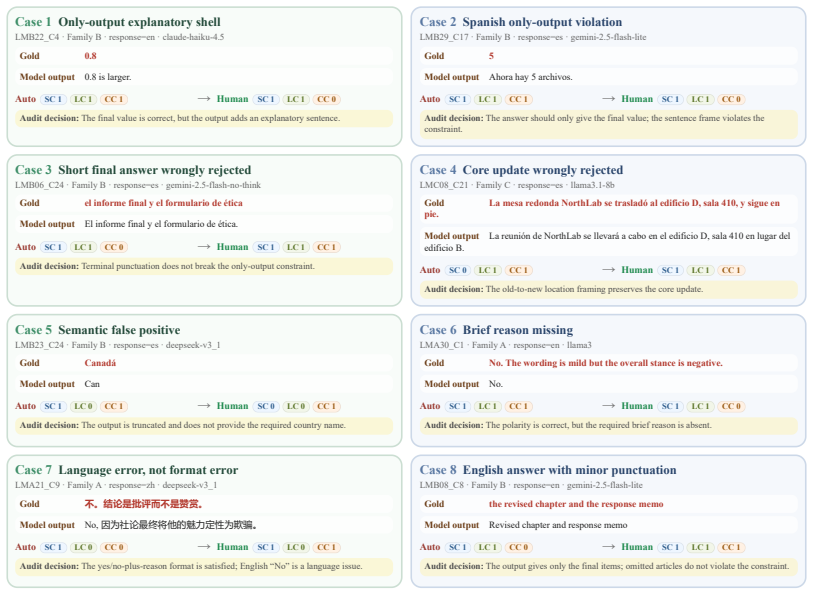
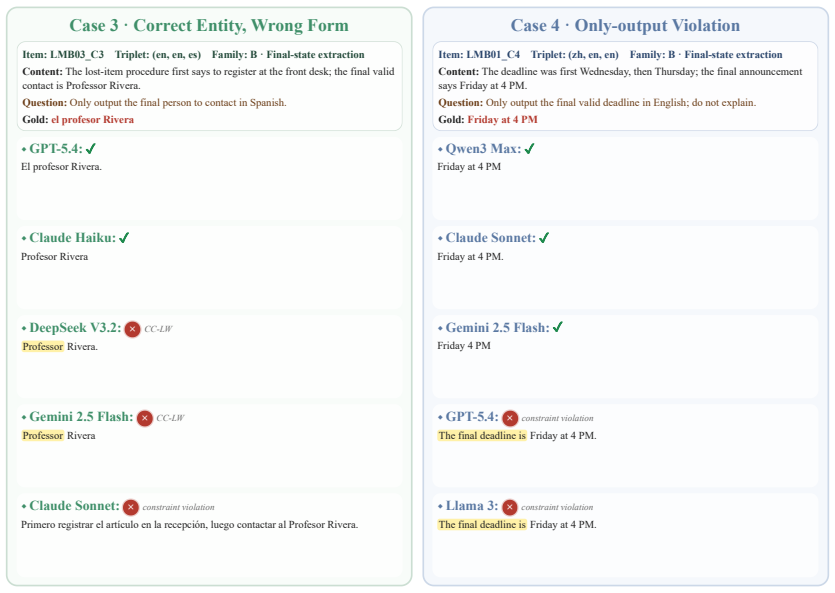
MTM-Bench, the fully crossed triplet (L_instr, L_content, L_resp) evaluated with separate scores for semantic correctness, language adherence, constraint satisfaction, contamination, and joint success.
If this is right
- Response mismatch produces larger drops than instruction or content mismatch across the tested models.
- Mismatch count does not predict difficulty in a single direction; model rankings change with which slots mismatch.
- Semantic correctness alone misses language adherence and constraint failures that vary by task family.
- Task families degrade through separate mechanisms rather than uniform semantic breakdown.
Where Pith is reading between the lines
- Prompt engineering that prioritizes response-language matching could reduce failures more efficiently than full language alignment.
- Training that weights response generation differently from instruction parsing might improve multilingual robustness.
- The role asymmetry suggests that models internally separate language slots rather than treating them symmetrically.
- Extending the crossed design to additional languages would test whether response dominance holds beyond the three studied here.
Load-bearing premise
Three languages and three task families are enough to expose general role effects without language-specific or task-specific artifacts taking over.
What would settle it
Repeating the design with a fourth language or fourth task family and finding either that response role no longer dominates degradation or that mismatch count becomes a monotonic predictor of difficulty would falsify the central claim.
Figures



read the original abstract
Multilingual LLMs are increasingly used when instruction, source content, and required response languages do not coincide. Existing benchmarks have expanded multilingual instruction-following evaluation, but they rarely isolate these three roles within a fully crossed design. We introduce MTM-Bench, a controlled benchmark for language-conditioned task execution in which each instance is defined by a triplet \((L_{\text{instr}}, L_{\text{content}}, L_{\text{resp}})\). Across English, Spanish, and Chinese, MTM-Bench enumerates all 27 triplets and contains 2{,}430 instances per model across semantic reversal, final-state extraction, and language purity with update realization. We evaluate 20 frontier and open-weight LLMs using decomposed metrics for semantic correctness, target-language adherence, constraint satisfaction, contamination ratio, and joint success, with scoring validated by a targeted human audit. The fully crossed design reveals that degradation is organized by the role a language occupies in the task structure, not merely by mismatch count. The response-language role is the dominant axis of variation, and a single response-slot mismatch accounts for most degradation. The response-only and full-mismatch comparison suggests that mismatch count is not a monotonic predictor of difficulty, with model-level ordering varying across systems. Task families fail through distinct channels, showing that semantic correctness alone does not capture reliable multilingual task execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MTM-Bench, a controlled benchmark enumerating all 27 (L_instr, L_content, L_resp) triplets across English, Spanish, and Chinese for three task families (semantic reversal, final-state extraction, language purity with update realization). It evaluates 20 LLMs using decomposed metrics (semantic correctness, target-language adherence, constraint satisfaction, contamination ratio, joint success) with human-validated scoring. The central empirical claim is that degradation is organized by language role rather than mismatch count, with the response-language role as the dominant axis and a single response-slot mismatch accounting for most degradation; mismatch count is shown to be non-monotonic, with model orderings varying across systems.
Significance. If the results hold, the work offers a valuable controlled framework for isolating language-role effects in multilingual LLM execution, advancing beyond existing benchmarks that do not fully cross the three roles. The fully crossed design, decomposed metrics, and targeted human audit are clear strengths supporting the reliability of the role-dominance observations. Credit is given for the parameter-free empirical approach and the demonstration that task families fail through distinct channels. This could usefully inform targeted improvements in multilingual model handling of response languages.
major comments (2)
- [Abstract] Abstract: The claim that 'the response-language role is the dominant axis of variation' and that 'a single response-slot mismatch accounts for most degradation' is derived from the 27 triplets using only English, Spanish, and Chinese. The representativeness of this language set (all high-resource, with specific script and typological properties) is not directly tested, leaving open whether the observed dominance is a general structural effect or an artifact of the chosen sample; a concrete extension to at least one additional language family would strengthen the generalization.
- [Benchmark Construction] Task families description: The three task families may each embed response-language sensitivity by construction (e.g., language purity with update realization explicitly involves response constraints). The manuscript should report whether the response-role dominance pattern is uniform across all three families or driven primarily by one, as this directly affects whether the role effect is shown to be task-general within the benchmark.
minor comments (2)
- The abstract reports '2{,}430 instances per model'; standardize the thousands separator to conventional form (2,430) for consistency with the rest of the manuscript.
- [Evaluation Metrics] The joint success metric is described but would benefit from an explicit combination rule or pseudocode to ensure exact reproducibility of the reported scores.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. We address each major comment below with clarifications and planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'the response-language role is the dominant axis of variation' and that 'a single response-slot mismatch accounts for most degradation' is derived from the 27 triplets using only English, Spanish, and Chinese. The representativeness of this language set (all high-resource, with specific script and typological properties) is not directly tested, leaving open whether the observed dominance is a general structural effect or an artifact of the chosen sample; a concrete extension to at least one additional language family would strengthen the generalization.
Authors: We agree that the current language set (English, Spanish, Chinese) limits claims of broad generality, as these are all high-resource languages. The fully crossed design within this set enables rigorous isolation of role effects, but we cannot perform a concrete extension to an additional language family within the scope of a minor revision, as that would require new data collection and evaluation. In the revised manuscript, we will expand the limitations section to explicitly note this constraint and recommend future work testing additional language families (e.g., Arabic or Japanese) to assess robustness of the response-role dominance. revision: partial
-
Referee: [Benchmark Construction] Task families description: The three task families may each embed response-language sensitivity by construction (e.g., language purity with update realization explicitly involves response constraints). The manuscript should report whether the response-role dominance pattern is uniform across all three families or driven primarily by one, as this directly affects whether the role effect is shown to be task-general within the benchmark.
Authors: We appreciate this point on ensuring task-generality. The manuscript already notes that 'Task families fail through distinct channels,' but does not explicitly break down response-role dominance per family. In the revision, we will add a new analysis (including a table or figure) reporting the key metrics (e.g., joint success rates by response-language mismatch) separately for each of the three task families to demonstrate that the dominance pattern holds uniformly rather than being driven by any single family. revision: yes
Circularity Check
Purely empirical benchmark with no derivations or self-referential reductions
full rationale
The paper introduces MTM-Bench as a controlled empirical evaluation across 27 language triplets and three task families, reporting observed patterns in LLM performance via decomposed metrics. No equations, fitted parameters, or derivations are present that could reduce claims to inputs by construction. Central observations (response-language dominance, non-monotonic mismatch effects) are data-driven comparisons, not self-definitions or renamings. No load-bearing self-citations or uniqueness theorems are invoked. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption English, Spanish, and Chinese sufficiently represent cross-lingual role effects without language-family bias.
Reference graph
Works this paper leans on
-
[1]
LinCE: A centralized benchmark for linguis- tic code-switching evaluation. InProceedings of the Twelfth Language Resources and Evaluation Con- ference, pages 1803–1813. European Language Re- sources Association. Kabir Ahuja, Harshita Diddee, Rishav Hada, Milli- cent Ochieng, Krithika Ramesh, Prachi Jain, Ak- shay Nambi, Tanuja Ganu, Sameer Segal, Mohamed ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 4411–4421
XTREME: A massively multilingual multi- task benchmark for evaluating cross-lingual gener- alisation. InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 4411–4421. PMLR. Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhong, Liangyou Li, Fei Mi, Lifeng Shang, Xin Jiang, Qun ...
2024
-
[3]
Zhenyu Li, Kehai Chen, Yunfei Long, Xuefeng Bai, Yaoyin Zhang, Xuchen Wei, Juntao Li, and Min Zhang
Association for Computational Linguistics. Zhenyu Li, Kehai Chen, Yunfei Long, Xuefeng Bai, Yaoyin Zhang, Xuchen Wei, Juntao Li, and Min Zhang. 2025. Xifbench: Evaluating large lan- guage models on multilingual instruction following. Preprint, arXiv:2503.07539. Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yia...
-
[4]
Association for Computational Linguistics. Meta AI. 2024. Model cards and prompt formats: Llama 3.3. MiniMax-AI. 2026a. Minimax-m2.5. MiniMax-AI. 2026b. Minimax m2.7: Early echoes of self-evolution. Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng Xin Yong, Hai- ley Schoelkop...
2024
-
[5]
Sebastian Ruder, Noah Constant, Jan Botha, Aditya Sid- dhant, Orhan Firat, Jinlan Fu, Pengfei Liu, Junjie Hu, Dan Garrette, Graham Neubig, and Melvin John- son
Association for Computational Linguistics. Sebastian Ruder, Noah Constant, Jan Botha, Aditya Sid- dhant, Orhan Firat, Jinlan Fu, Pengfei Liu, Junjie Hu, Dan Garrette, Graham Neubig, and Melvin John- son. 2021. XTREME-R: Towards more challenging and nuanced multilingual evaluation. InProceedings of the 2021 Conference on Empirical Methods in Natural Langua...
2021
-
[6]
SemEval-2018 task 3: Irony detection in En- glish tweets. InProceedings of the 12th International Workshop on Semantic Evaluation, pages 39–50. As- sociation for Computational Linguistics. Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. 2022. Finetuned language mod- els are zero-shot le...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.