ReverseMath: Answer Inversion for Scalable and Verifiable Mathematical Problem Generation
Pith reviewed 2026-06-29 17:58 UTC · model grok-4.3
The pith
Answer inversion generates scalable verifiable math problems by reversing original input-output relations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
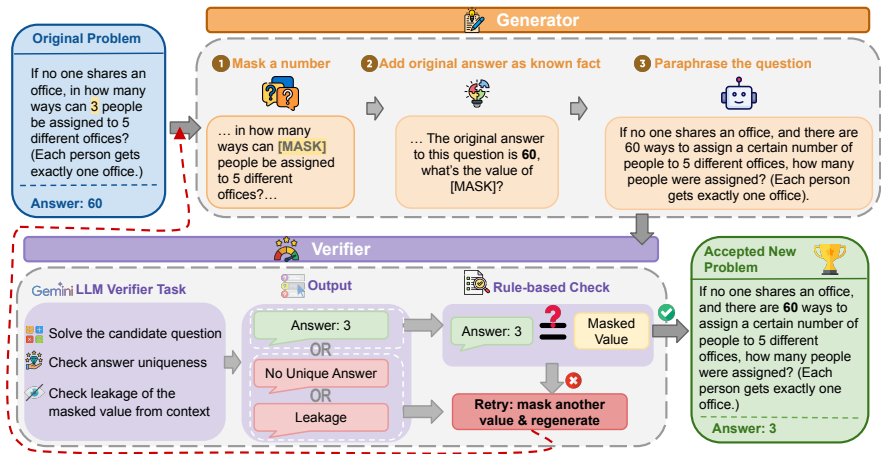
Given a math problem and its answer, ReverseMath masks one numerical value, conditions the rewrite on the original answer, and produces a new problem whose solution is exactly the masked value, thereby creating fresh problems whose correctness is guaranteed by the inversion process itself.
What carries the argument
Answer inversion: the process of masking a numerical value in the original problem and rewriting it via LLM so that the masked value is now the target answer, reversing the original input-output relation.
If this is right
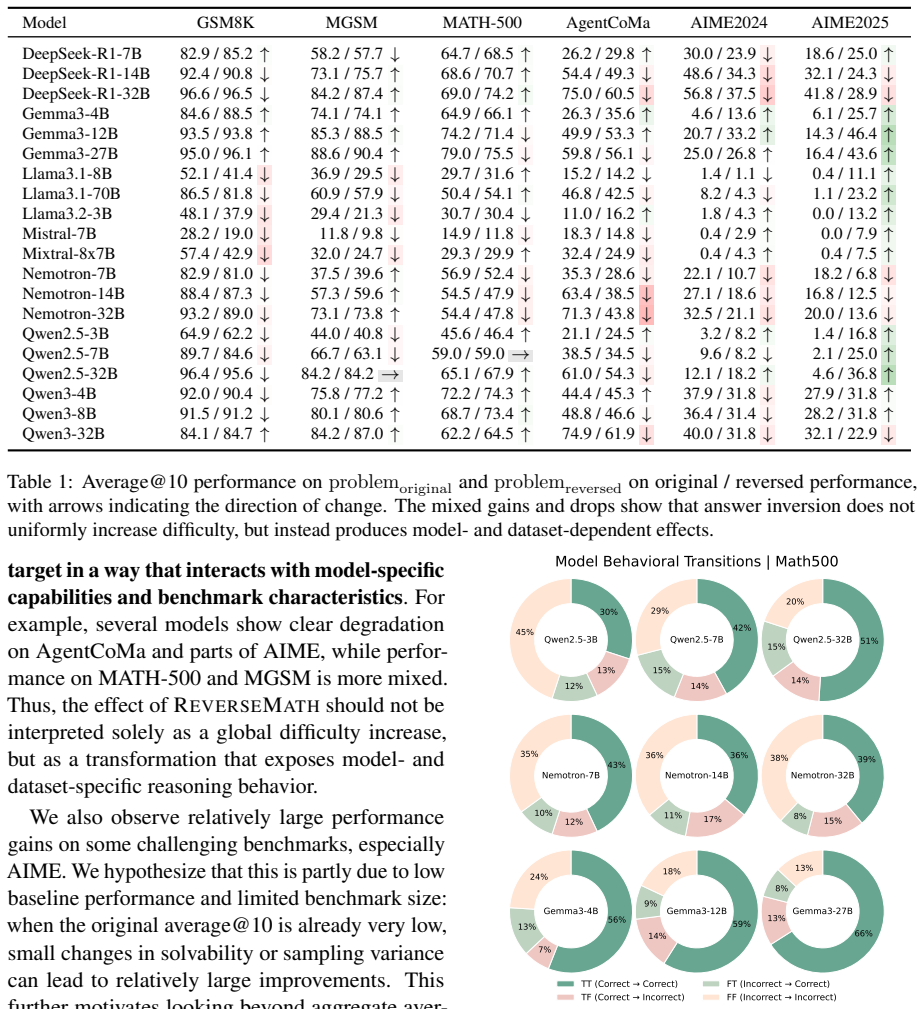
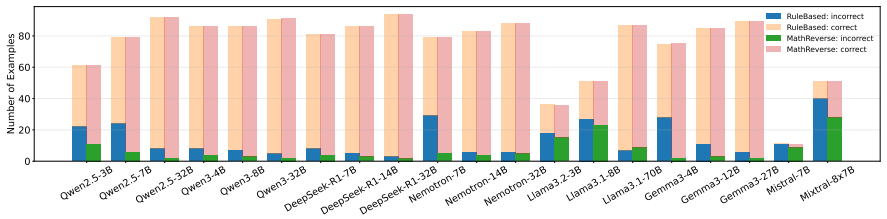
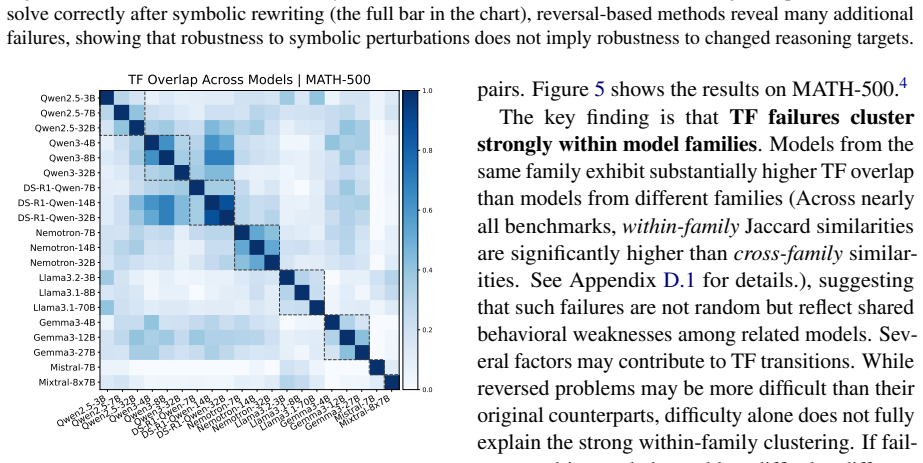
- Paired original and reversed problems produce measurable behavioral shifts, including cases where models output the original answer on the reversed version.
- Augmenting reinforcement learning with the automatically labeled reversed problems raises accuracy on several mathematical reasoning benchmarks.
- The method supplies new problems at low cost while keeping answers known by construction, bypassing manual answer verification.
Where Pith is reading between the lines
- Iterating the inversion on already-reversed problems could produce sequences of related instances for studying how formulation changes affect reasoning.
- The same masking-and-rewrite pattern might extend to non-numerical domains if other verifiable quantities can be isolated and reversed.
- Gains from the added data imply that varying problem wording helps models move beyond surface-level pattern matching.
Load-bearing premise
The LLM rewriting step produces new problems whose difficulty and logical validity match the originals closely enough that observed differences stem mainly from memorization rather than artifacts of the inversion.
What would settle it
Finding that models achieve the same accuracy on original and reversed problem pairs, or that a substantial fraction of reversed problems have inconsistent or incorrect answers upon manual check.
Figures

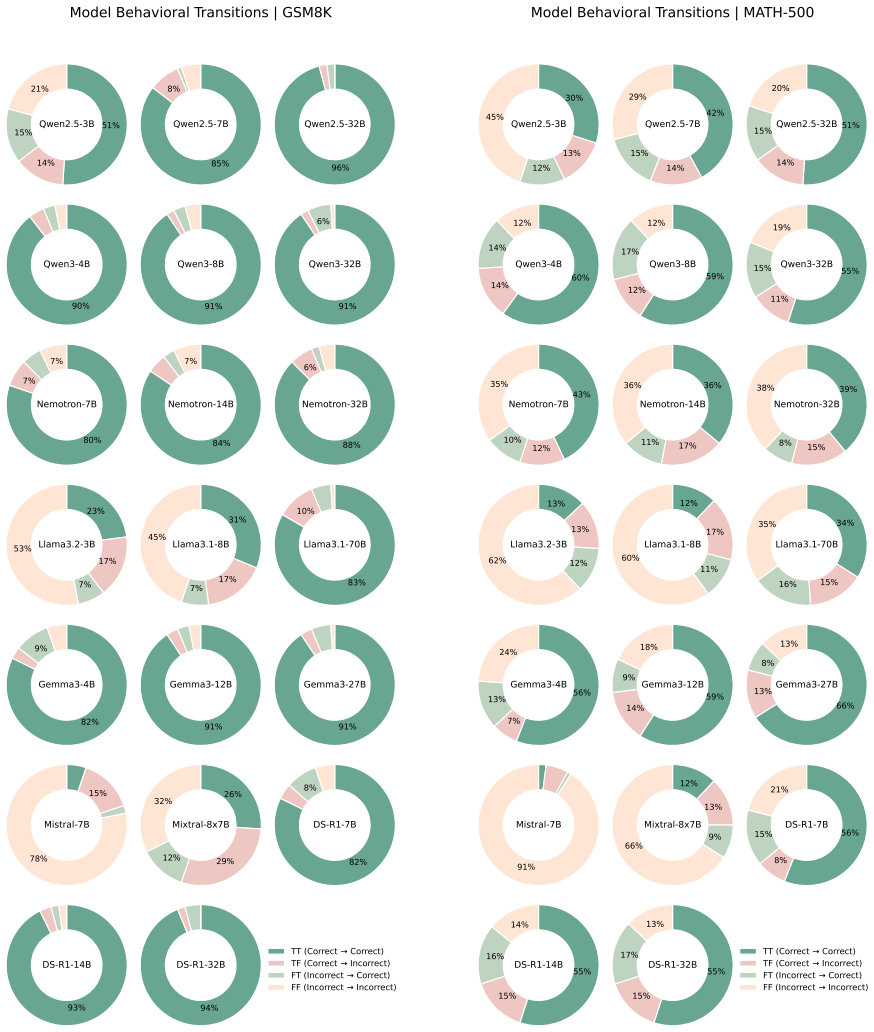
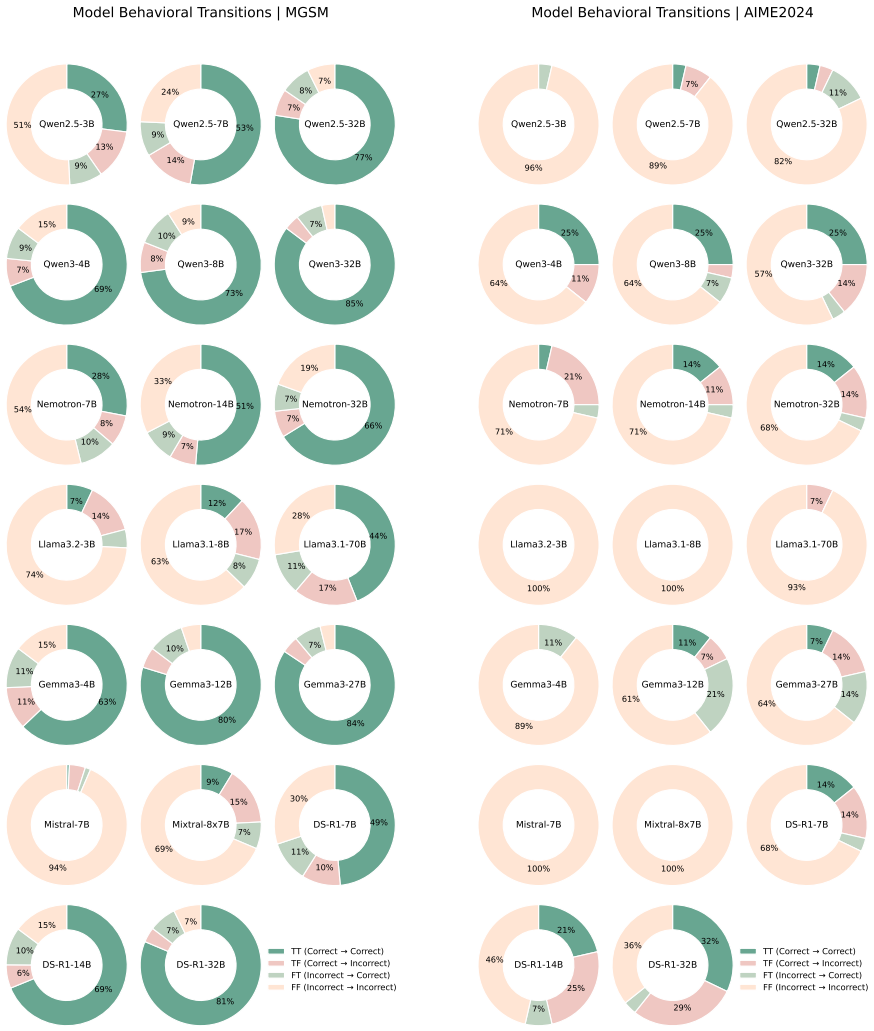
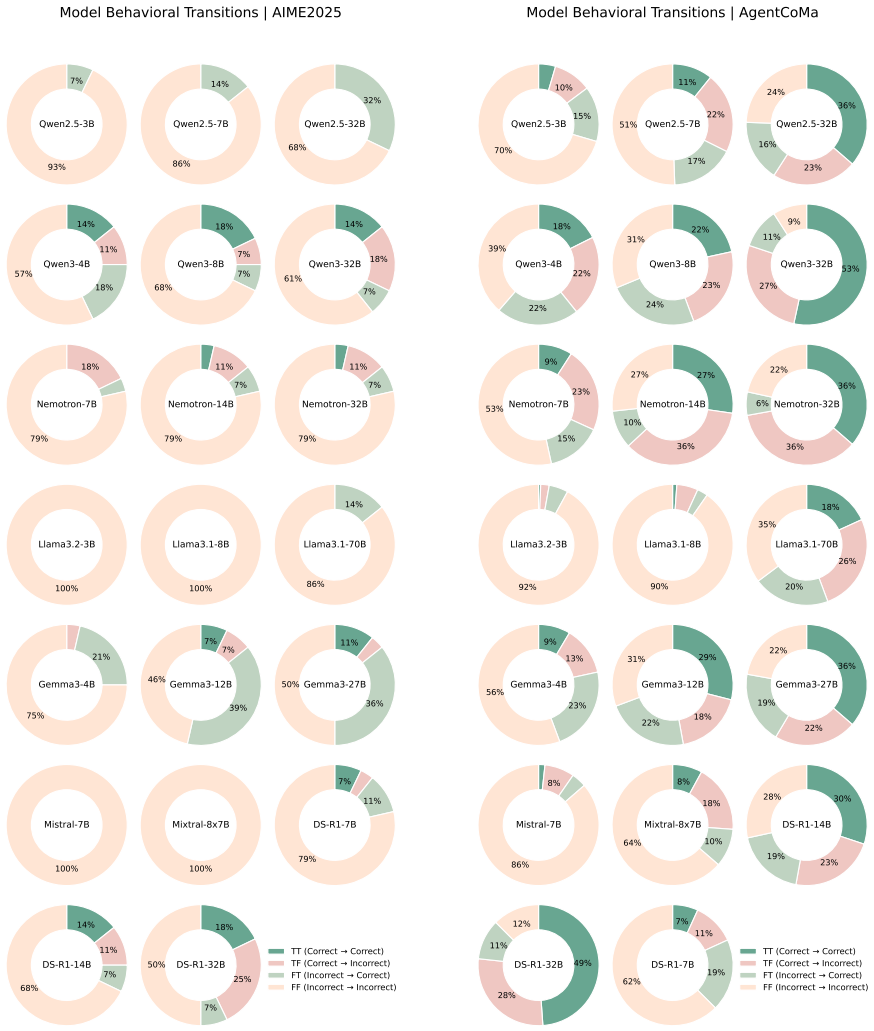
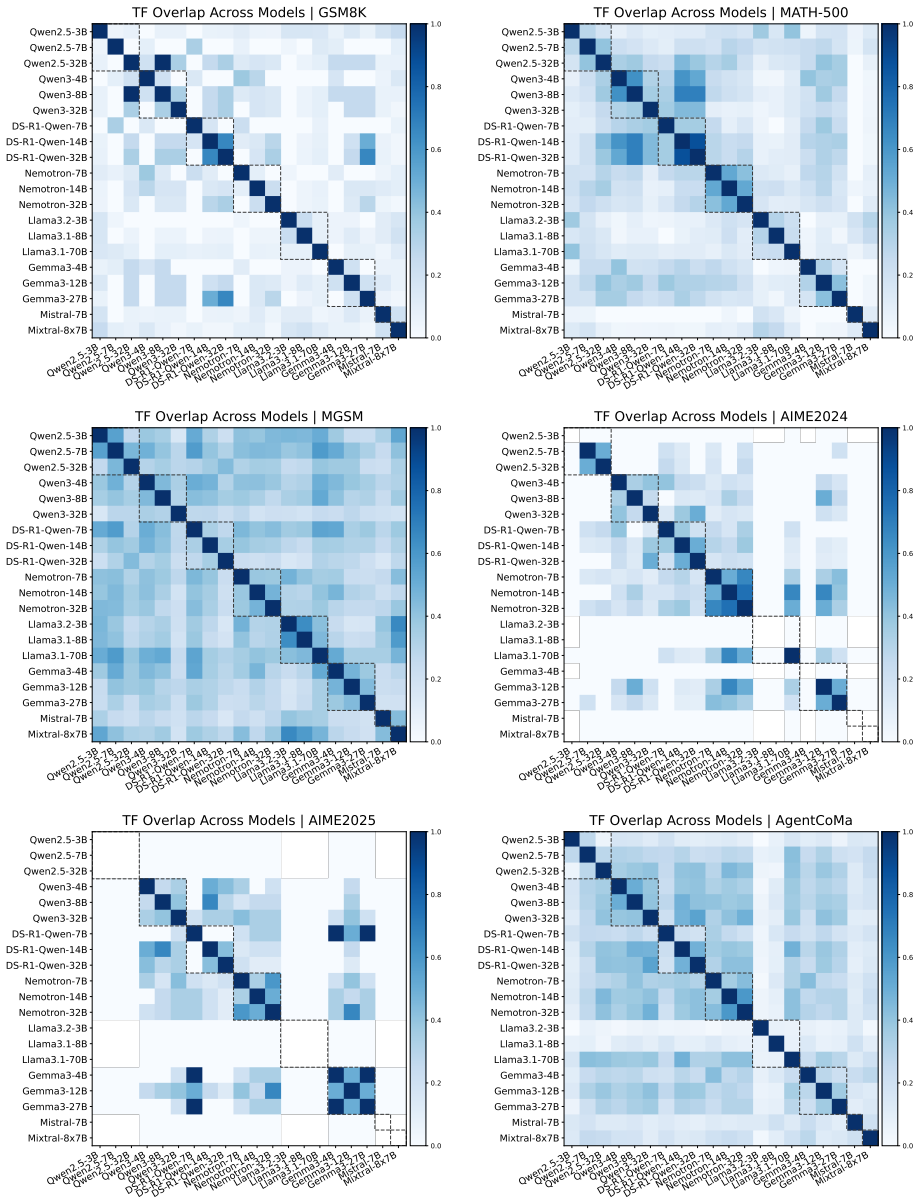
read the original abstract
Mathematical reasoning benchmarks are vital for evaluating large language models (LLMs), but many are static and repeatedly exposed through public evaluation and training pipelines, making it difficult to separate genuine reasoning from memorization. Meanwhile, manually constructing new math problems with reliable answers remains costly. We introduce ReverseMath, a scalable method for generating new math problems through answer inversion. Given a problem and its answer, ReverseMath masks a numerical value in the original problem, treats the original answer as a known condition, and rewrites the problem so that the masked value becomes the new answer. The generated problem reverses the original input-output relation, making its answer known by construction. We study ReverseMath for both evaluation and training. For evaluation, paired original/reversed problems reveal substantial behavioral shifts: models sometimes fail on reversed problems and even incorrectly output the original answer, suggesting memorization-like behavior. For training, ReverseMath provides automatically labeled reversed problems as data augmentation for reinforcement learning (RL). Experiments show that including ReverseMath-generated data improves mathematical reasoning performance across multiple benchmarks, demonstrating its value as both an analysis tool and a scalable source of verifiable training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReverseMath, a method to generate new math problems via answer inversion: mask a numerical value in an original problem, treat the original answer as a condition, and use an LLM to rewrite the statement so the masked value becomes the new answer. This produces automatically verifiable problems that reverse the original input-output mapping. The work evaluates the method for detecting memorization-like behavior through behavioral shifts on paired original/reversed problems and for training by augmenting RL data, reporting improved performance on multiple mathematical reasoning benchmarks.
Significance. If the generated problems maintain validity and comparable reasoning depth, ReverseMath offers a scalable source of verifiable training data and an analysis tool for distinguishing reasoning from memorization on contaminated benchmarks. The automatic labeling by construction is a clear strength, as is the paired-problem design for evaluation.
major comments (2)
- [§3] §3 (Method): The LLM rewriting procedure is described at a high level with no reported controls, prompt templates, or post-generation validation metrics (e.g., human verification of mathematical equivalence or difficulty ratings) to confirm that reversed problems preserve the original reasoning depth and skill distribution. Without this, performance gains in the RL experiments cannot be confidently attributed to the inversion mechanism rather than uncontrolled shifts in problem characteristics.
- [§5] §5 (Experiments): The training results claim that including ReverseMath data improves benchmark performance, yet there are no ablations isolating the inversion from confounding factors such as increased data volume, LLM-induced stylistic artifacts, or changes in problem length/difficulty. This undermines the central training claim.
minor comments (2)
- The abstract and introduction would benefit from a clearer statement of the exact masking criterion and how multiple numerical values are handled when present.
- Figure captions for the behavioral-shift plots should include the exact model sizes and benchmark names for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the method and experiments.
read point-by-point responses
-
Referee: [§3] §3 (Method): The LLM rewriting procedure is described at a high level with no reported controls, prompt templates, or post-generation validation metrics (e.g., human verification of mathematical equivalence or difficulty ratings) to confirm that reversed problems preserve the original reasoning depth and skill distribution. Without this, performance gains in the RL experiments cannot be confidently attributed to the inversion mechanism rather than uncontrolled shifts in problem characteristics.
Authors: We agree that the method section would benefit from greater transparency. In the revised manuscript we will add the complete prompt templates to an appendix. We will also report aggregate statistics comparing original and reversed problems (length, number of numerical values, and answer magnitude distributions) as basic controls. Additionally, we will include results from a small-scale human study on a random sample of 100 reversed problems, with raters assessing mathematical equivalence to the original and relative difficulty; inter-rater agreement will be reported. These additions will allow readers to better evaluate whether gains stem from the inversion itself. revision: yes
-
Referee: [§5] §5 (Experiments): The training results claim that including ReverseMath data improves benchmark performance, yet there are no ablations isolating the inversion from confounding factors such as increased data volume, LLM-induced stylistic artifacts, or changes in problem length/difficulty. This undermines the central training claim.
Authors: The referee correctly notes the absence of targeted ablations. We will add them in the revision: (i) a data-volume control using an equal number of non-inverted problems drawn from the same original sources, (ii) a stylistic-artifact control using problems rewritten by the LLM without the answer-inversion conditioning, and (iii) length- and difficulty-matched subsets. Results will be presented in an expanded experimental section with a new table. These controls should clarify the contribution of the inversion mechanism. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical generation procedure that starts from external source problems, applies LLM-based rewriting to produce reversed problems whose answers are known by construction, and then measures downstream effects on independent external benchmarks. No step reduces a claimed result to a fitted parameter, self-citation chain, or definitional equivalence; the performance gains are reported as measured outcomes rather than derived by construction from the inputs. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. 2024. https://doi.org/10.18653/v1/2024.eacl-srw.17 Large language models for mathematical reasoning: Progresses and challenges . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, pages 225--237, S...
-
[2]
Lisa Alazraki, Lihu Chen, Ana Brassard, Joe Stacey, Hossein A. Rahmani, and Marek Rei. 2026. https://arxiv.org/abs/2508.19988 Agentcoma: A compositional benchmark mixing commonsense and mathematical reasoning in real-world scenarios . Preprint, arXiv:2508.19988
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Simin Chen, Yiming Chen, Zexin Li, Yifan Jiang, Zhongwei Wan, Yixin He, Dezhi Ran, Tianle Gu, Haizhou Li, Tao Xie, and Baishakhi Ray. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.511 Benchmarking large language models under data contamination: A survey from static to dynamic evaluation . In Proceedings of the 2025 Conference on Empirical Methods in N...
-
[4]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. 2024. https://doi.org/10.18653/v1/2024.naacl-long.482 Investigating data contamination in modern benchmarks for large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V...
-
[6]
Yupei Du, Philipp Mondorf, Silvia Casola, Yuekun Yao, Robert Litschko, and Barbara Plank. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.437 Reason to rote: Rethinking memorization in reasoning . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 8659--8679, Suzhou, China. Association for Computational Linguistics
-
[7]
Gemma Team , Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.1978...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. https://doi.org/10.1038/s41586-025-09422-z Deepseek-r1 incentivizes reasoning in llms through reinforcement lear...
-
[10]
Pei Guo, WangJie You, Juntao Li, Yan Bowen, and Min Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.811 Exploring reversal mathematical reasoning ability for large language models . In Findings of the Association for Computational Linguistics: ACL 2024, pages 13671--13685, Bangkok, Thailand. Association for Computational Linguistics
-
[11]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/be83ab3ecd0db773eb2dc1b0a17836a1-Abstract-round2.html Measuring mathematical problem solving with the MATH dataset . In Proceedings of the Neural Information Processin...
2021
-
[12]
Kaixuan Huang, Jiacheng Guo, Zihao Li, Xiang Ji, Jiawei Ge, Wenzhe Li, Yingqing Guo, Tianle Cai, Hui Yuan, Runzhe Wang, Yue Wu, Ming Yin, Shange Tang, Yangsibo Huang, Chi Jin, Xinyun Chen, Chiyuan Zhang, and Mengdi Wang. 2025. https://proceedings.mlr.press/v267/huang25k.html Math-perturb: Benchmarking llms' math reasoning abilities against hard perturbati...
2025
-
[13]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, and 7 others. 2024. ht...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Qintong Li, Leyang Cui, Xueliang Zhao, Lingpeng Kong, and Wei Bi. 2024. https://doi.org/10.18653/v1/2024.acl-long.163 GSM -plus: A comprehensive benchmark for evaluating the robustness of LLM s as mathematical problem solvers . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2961--2...
-
[16]
Inbal Magar and Roy Schwartz. 2022. https://doi.org/10.18653/v1/2022.acl-short.18 Data contamination: From memorization to exploitation . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 157--165, Dublin, Ireland. Association for Computational Linguistics
-
[17]
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. 2025. https://openreview.net/forum?id=AjXkRZIvjB Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025...
2025
-
[18]
Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, and Igor Gitman. 2025. https://arxiv.org/abs/2504.16891 Aimo-2 winning solution: Building state-of-the-art mathematical reasoning models with openmathreasoning dataset . Preprint, arXiv:2504.16891
-
[19]
Qwen Team , An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, and 24 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Oscar Sainz, Jon Campos, Iker Garc \'i a-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.722 NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10776--10787, Singa...
-
[21]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Chi, Nathanael Sch \" a rli, and Denny Zhou
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Sch \" a rli, and Denny Zhou. 2023 a . https://proceedings.mlr.press/v202/shi23a.html Large language models can be easily distracted by irrelevant context . In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , Proceeding...
2023
-
[23]
Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. 2023 b . https://openreview.net/forum?id=fR3wGCk-IXp Language models are multilingual chain-of-thought reasoners . In The Eleventh International Conference on Learning Representations, IC...
2023
-
[24]
Shengkun Tang, Zekun Wang, Bo Zheng, Liangyu Wang, Rui Men, Siqi Zhang, Xiulong Yuan, Zihan Qiu, Zhiqiang Shen, and Dayiheng Liu. 2026. https://arxiv.org/abs/2605.08738 Slimqwen: Exploring the pruning and distillation in large moe model pre-training . Preprint, arXiv:2605.08738
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Peng - Yuan Wang, Tian - Shuo Liu, Chenyang Wang, Ziniu Li, Yidi Wang, Shu Yan, Chengxing Jia, Xu - Hui Liu, Xinwei Chen, Jiacheng Xu, and Yang Yu. 2026. https://doi.org/10.1145/3786333 A survey on large language models for mathematical reasoning . ACM Comput. Surv. , 58(8):209:1--209:35
-
[26]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. http://papers.nips.cc/paper\_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html Chain-of-thought prompting elicits reasoning in large language models . In Advances in Neural Information Processing Systems...
2022
-
[27]
Cheng Xu, Shuhao Guan, Derek Greene, and M-Tahar Kechadi. 2024. https://arxiv.org/abs/2406.04244 Benchmark data contamination of large language models: A survey . Preprint, arXiv:2406.04244
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Tianyi Xu, Kosei Uemura, Alfred Malengo Kondoro, Tadesse Destaw Belay, Catherine Nana Nyaah Essuman, Ifeoma Okoh, Ganiyat Afolabi, Ayodele Awokoya, and David Ifeoluwa Adelani. 2026. https://arxiv.org/abs/2601.21225 Mgsm-pro: A simple strategy for robust multilingual mathematical reasoning evaluation . Preprint, arXiv:2601.21225
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025 a . https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024. https://arxiv.org/abs/2409.12122 Qwen2.5-math technical report: Toward mathematical expert model via self-improvement . Preprint, arXiv:2409.12122
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Yuli Yang, Hiroaki Yamada, and Takenobu Tokunaga. 2025 b . https://doi.org/10.18653/v1/2025.insights-1.16 Evaluating robustness of LLM s to numerical variations in mathematical reasoning . In The Sixth Workshop on Insights from Negative Results in NLP, pages 171--180, Albuquerque, New Mexico. Association for Computational Linguistics
-
[32]
Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2024. https://openreview.net/forum?id=N8N0hgNDRt Metamath: Bootstrap your own mathematical questions for large language models . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria,...
2024
-
[33]
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, William Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, Qin Lyu, Sean Hendryx, Russell Kaplan, Michele Lunati, and Summer Yue. 2024. http://papers.nips.cc/paper\_files/paper/2024/hash/53384f2090c6a5cac952c598fd67992f-Abstract-Datasets\_and\_Benchmarks\_Track.html A careful exami...
2024
-
[34]
Raoyuan Zhao, Abdullatif K \"o ksal, Yihong Liu, Leonie Weissweiler, Anna Korhonen, and Hinrich Schuetze. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.412 S ynth E val: Hybrid behavioral testing of NLP models with synthetic C heck L ists . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7017--7034, Miami, Florida, ...
-
[35]
Hedderich, and Hinrich Schuetze
Raoyuan Zhao, Abdullatif K \"o ksal, Ali Modarressi, Michael A. Hedderich, and Hinrich Schuetze. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1263 Do we know what LLM s don ' t know? a study of consistency in knowledge probing . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23254--23280, Suzhou, China. Associatio...
-
[36]
Evaluating Robustness of Large Language Models Against Multilingual Typographical Errors
Raoyuan Zhao, Yihong Liu, Lena Altinger, Hinrich Schütze, and Michael A. Hedderich. 2026. https://arxiv.org/abs/2510.09536 Evaluating robustness of large language models against multilingual typographical errors . Preprint, arXiv:2510.09536
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Yue Zhou, Yada Zhu, Diego Antognini, Yoon Kim, and Yang Zhang. 2024. https://doi.org/10.18653/v1/2024.naacl-long.153 Paraphrase and solve: Exploring and exploiting the impact of surface form on mathematical reasoning in large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguist...
-
[38]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[39]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.