UserHarness: Harnessing User Minds for Stronger Agent Theory-of-Mind
Pith reviewed 2026-06-29 17:50 UTC · model grok-4.3
The pith
Explicitly decomposing user observations, beliefs, intentions, and actions improves agent theory-of-mind accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
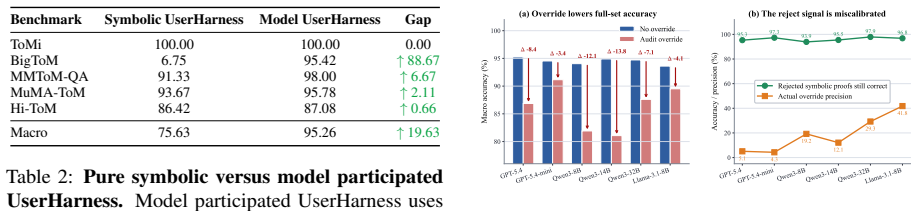
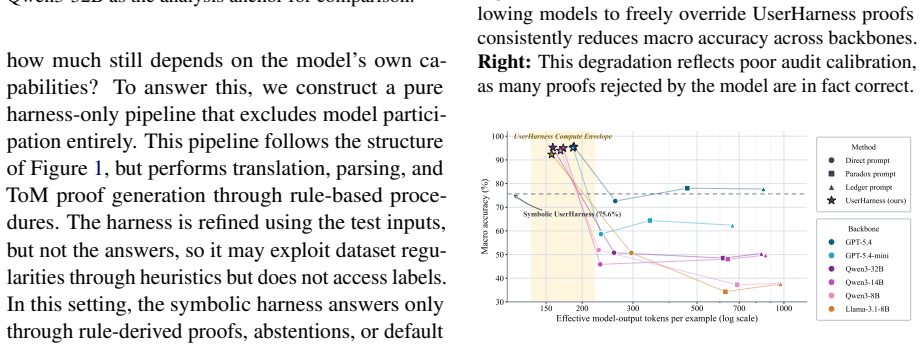
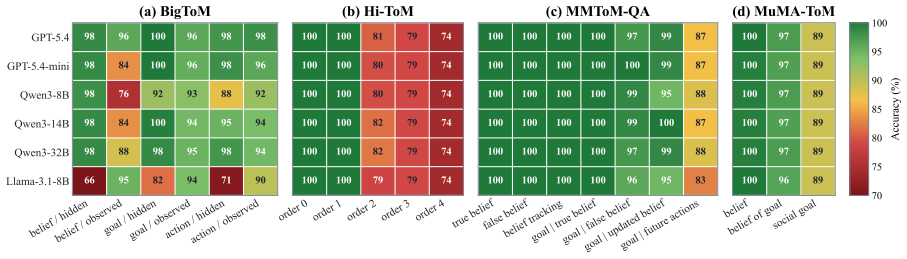
UserHarness reframes ToM reasoning as explicit user-mind reconstruction by decomposing the user's mental state, its relation to the external environment, and the actions that follow from it. This enables agents to track what the user observes, believes, intends, and does. The paper reports that this yields up to 95.94 percent macro accuracy on five benchmarks, with relative improvements of more than 15 percent over existing inference methods and about 20 percent over the strongest prompt-only harness.
What carries the argument
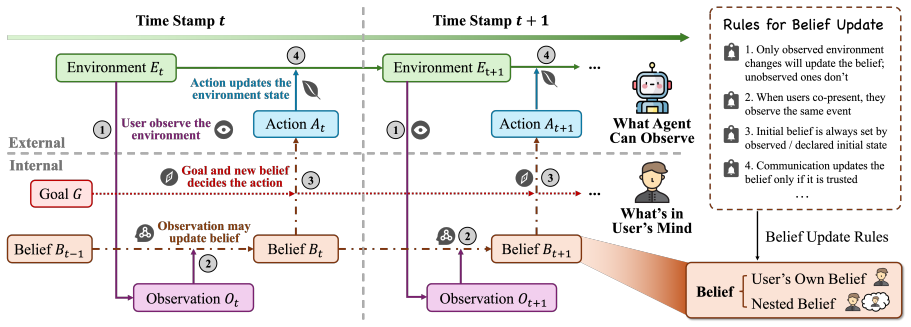
UserHarness, a framework that decomposes the user's mental state into observations, beliefs, intentions, and actions while tracking their links to the environment.
If this is right
- Agents reach up to 95.94 percent macro accuracy on ToM benchmarks through direct mental-state tracking.
- Relative gains exceed 15 percent over existing inference methods and 20 percent over the strongest prompt-only harness.
- Robust user understanding requires reasoning from the roots of the user's mind.
- User harnessing forms a foundation for more adaptive future assistants.
Where Pith is reading between the lines
- The decomposition approach could extend to multi-agent settings where nested beliefs about others' beliefs become central.
- Direct mental-state tracking might reduce dependence on elaborate prompt engineering for agent behavior.
- Integration with real-time interaction logs could test whether the gains hold outside static benchmarks.
Load-bearing premise
Explicitly decomposing and tracking the user's observations, beliefs, intentions, and actions is necessary and sufficient to capture the core structure of ToM reasoning without indirect behavior modeling pipelines.
What would settle it
An indirect behavior-modeling pipeline that reaches or exceeds 95.94 percent macro accuracy on the same five benchmarks without explicit mental-state decomposition would falsify the central claim.
Figures
read the original abstract
Understanding what a user believes and intends is central to building effective agent assistants. This ability is often evaluated through Theory-of-Mind (ToM) tasks, where success requires reasoning from the user's perspective. However, many existing approaches address ToM with complex pipelines that model behavior indirectly, without explicitly reconstructing the user's mental state. This misses the core structure of the problem: users act based on their beliefs, which are updated through observations of the environment; beliefs and intentions jointly determine actions, which in turn change the environment; and social reasoning often requires nested beliefs about what others believe or intend. We propose UserHarness, a simple framework that reframes ToM reasoning as explicit user-mind reconstruction. UserHarness decomposes the user's mental state, its relation to the external environment, and the actions that follow from it, enabling agents to track what the user observes, believes, intends, and does. Across five benchmarks, UserHarness reaches up to 95.94% macro accuracy, improving over existing inference methods by more than 15% relative and over the strongest prompt-only harness by about 20% relative. These results suggest that robust user understanding requires reasoning from the roots of the user's mind, positioning user harnessing as a promising foundation for more adaptive future assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UserHarness, a framework for Theory-of-Mind reasoning in agents that explicitly decomposes the user's mental state into observations, beliefs, intentions, and actions, along with their relations to the environment. It claims that this approach achieves up to 95.94% macro accuracy across five benchmarks, with relative improvements exceeding 15% over existing inference methods and 20% over the strongest prompt-only harness.
Significance. If the empirical results hold under rigorous verification, the explicit decomposition approach could offer a direct and potentially simpler alternative to indirect behavior-modeling pipelines for ToM tasks, with implications for designing more adaptive agent assistants.
major comments (2)
- [Abstract] Abstract: the performance claims (up to 95.94% macro accuracy and 15-20% relative gains) are presented with no description of the five benchmarks, baselines, implementation details, or error analysis, so the central empirical claim cannot be evaluated from the provided text.
- [Abstract] Abstract: no ablation evidence is described to test whether the explicit decomposition and tracking of observations/beliefs/intentions/actions (rather than prompt structure, model scale, or indirect cues) is what produces the reported gains, leaving the necessity of this component unverified.
minor comments (1)
- The abstract refers to 'five benchmarks' without naming them or providing even high-level descriptions, which would help contextualize the evaluation scope.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the specific comments on the abstract. We address each point below and will revise the manuscript to improve the evaluability of the central claims while preserving the abstract's conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (up to 95.94% macro accuracy and 15-20% relative gains) are presented with no description of the five benchmarks, baselines, implementation details, or error analysis, so the central empirical claim cannot be evaluated from the provided text.
Authors: We agree that the abstract, as currently written, is too high-level to allow direct evaluation of the empirical claims. The full manuscript provides these details in Sections 3 (framework and implementation), 4 (benchmarks), and 5 (baselines, results, and error analysis). To address the concern, we will revise the abstract to name the five benchmarks and briefly indicate the main baseline categories (existing inference methods and prompt-only harnesses) while staying within length limits. revision: yes
-
Referee: [Abstract] Abstract: no ablation evidence is described to test whether the explicit decomposition and tracking of observations/beliefs/intentions/actions (rather than prompt structure, model scale, or indirect cues) is what produces the reported gains, leaving the necessity of this component unverified.
Authors: The abstract summarizes the overall results without space for ablation details. The manuscript contains ablation experiments that compare the full decomposition against ablated versions (e.g., prompt-only or indirect-cue variants) while controlling for model scale. These results support that the explicit decomposition drives the gains. We will add one sentence to the abstract noting that ablations confirm the contribution of the decomposition component. revision: yes
Circularity Check
No circularity; empirical benchmark results independent of inputs
full rationale
The paper proposes UserHarness as a framework for explicit decomposition of user mental states (observations, beliefs, intentions, actions) and evaluates it via macro accuracy on five external benchmarks, reporting gains over baselines. No equations, fitted parameters, self-citation load-bearing premises, or ansatzes are present in the provided text. The central claim reduces to an empirical comparison against independent test sets rather than any derivation that collapses to its own inputs by construction. This is the most common honest non-finding for benchmark-driven framework papers.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Users act based on their beliefs, which are updated through observations of the environment
- domain assumption Beliefs and intentions jointly determine actions, which in turn change the environment
- domain assumption Social reasoning often requires nested beliefs about what others believe or intend
Reference graph
Works this paper leans on
-
[1]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Does the autistic child have a “theory of mind”?Cognition, 21(1):37–46. Logan Cross, Violet Xiang, Agam Bhatia, Daniel Yamins, and Nick Haber. 2025. Hypothetical minds: Scaffolding theory of mind for multi-agent tasks with large language models. InInternational Conference on Learning Representations, volume 2025, pages 6507–6546. Alexandre Drouin, Maxime ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Perceptions to beliefs: Exploring precursory inferences for theory of mind in large language mod- els. InProceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, pages 19794–19809. Henry A Kautz, James F Allen, and 1 others. 1986. Generalized plan recognition. InAAAI, volume 86, page 5. Philadelphia, PA. Hyunwoo Kim, Melan...
-
[3]
Revisiting the evaluation of theory of mind through question answering. InProceedings of the 2019 Conference on Empirical Methods in Natu- ral Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5872–5877. Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Au- mayer, Feng Nan, Haoping Bai, Shua...
2019
-
[4]
Userbench: An interactive gym environment for user-centric agents, 2025
Towards a holistic landscape of situated theory of mind in large language models. InFindings of the association for computational linguistics: EMNLP 2023, pages 1011–1031. Josef Perner and Heinz Wimmer. 1985. “john thinks that mary thinks that. . . ” attribution of second-order beliefs by 5-to 10-year-old children.Journal of ex- perimental child psycholog...
-
[5]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. tau-bench: A benchmark for tool- agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045. Zhining Zhang, Chu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
direct observation updates an agent's belief to the observed resulting state
-
[7]
lack of observation preserves the prior belief
-
[8]
agents act from their current beliefs and goals, not hidden truth
-
[9]
if an unchanged belief identifies a specific candidate as satisfying the goal, the agent exploits that candidate (collects, uses, studies, grabs, proceeds with it) instead of searching again
-
[10]
if an observed change resolves a goal precondition, such as an item becoming available, safe, dry, usable, open, or fixed, the agent proceeds under that changed state instead of preserving the old blocked/waiting action
-
[11]
visible causes or visible effects license the stated causal consequence when the story explicitly links them
-
[12]
think from the user’s perspective,
unrelated distractor events do not change target beliefs. Use the story only. User: {question} {options} Derive the answer from the state transition timeline. First identify the prior state, the environment change, whether the target agent observed the change or its visible result, the updated belief, and the action/goal implied by that belief. Then check...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.