Worker Disagreement Reveals Sharp Directions in Local SGD
Pith reviewed 2026-06-29 18:12 UTC · model grok-4.3
The pith
Worker disagreement in Local SGD estimates the dominant Hessian subspace without Hessian computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Standard Local SGD exposes loss geometry through worker disagreement. The worker-average gap covariance is shaped by stochastic-gradient noise and Hessian curvature, causing workers to disagree along sharp, curvature-sensitive directions. Thus, worker-average gaps provide a cheap Hessian-free estimator of the dominant subspace.
What carries the argument
Covariance of worker-average gaps, which the analysis shows is shaped by noise and curvature to preferentially capture the dominant Hessian eigenspace.
If this is right
- The dominant subspace can be tracked throughout training at negligible extra cost.
- Optimizers can use the estimated directions to control movement along sharp versus flat axes.
- The same gaps already present in any Local SGD run become a diagnostic for loss anisotropy.
- The approach applies directly to MLPs, CNNs, and Transformers without architecture changes.
Where Pith is reading between the lines
- The estimator could be combined with existing flat-minima methods to steer updates away from sharp directions on the fly.
- Monitoring gap covariance over time might reveal when the loss geometry changes, such as during phase transitions in training.
- The same signal may appear in other distributed first-order methods that maintain multiple model copies.
Load-bearing premise
Other unmodeled factors do not dominate the worker gaps, so that the gaps remain shaped primarily by stochastic-gradient noise and Hessian curvature.
What would settle it
An experiment in which subspaces formed from worker-average gaps capture only a small fraction of the gradient lying inside the top Hessian eigenspace would falsify the estimator claim.
Figures
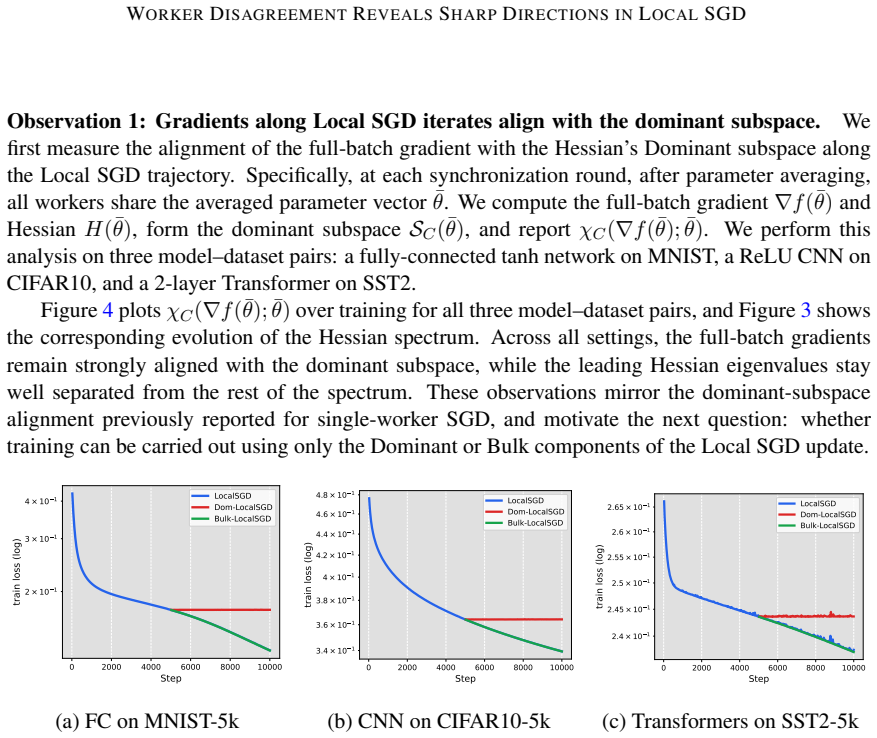
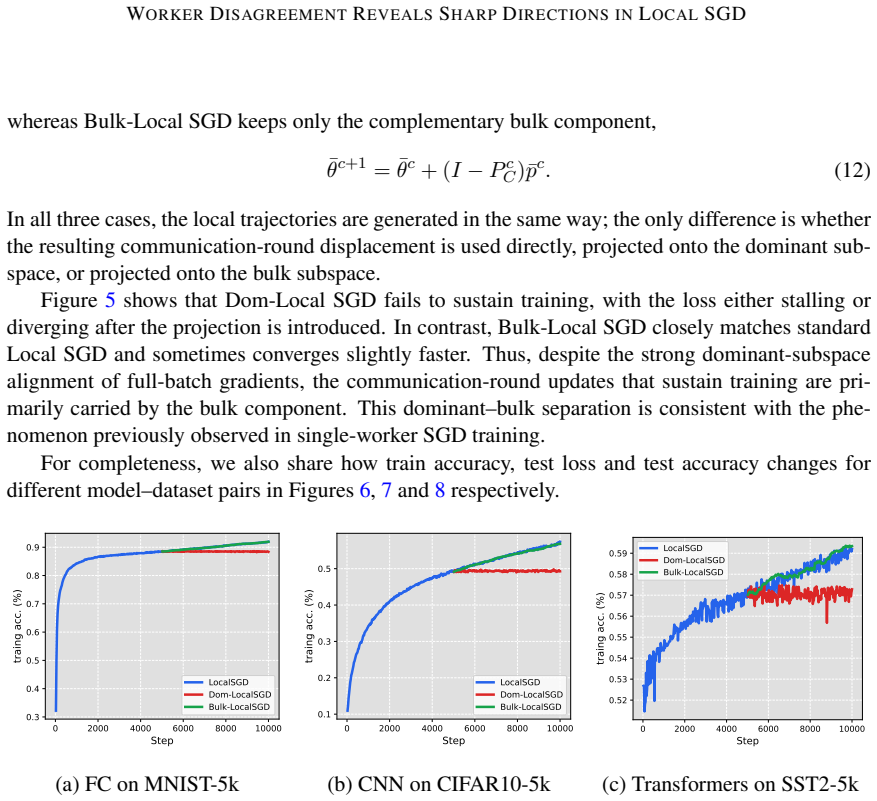
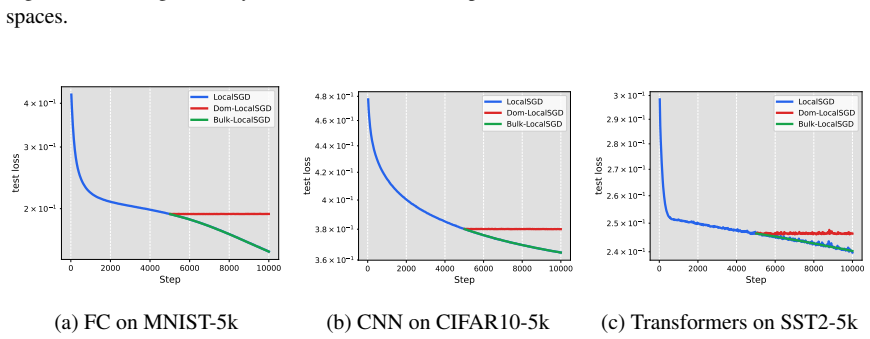
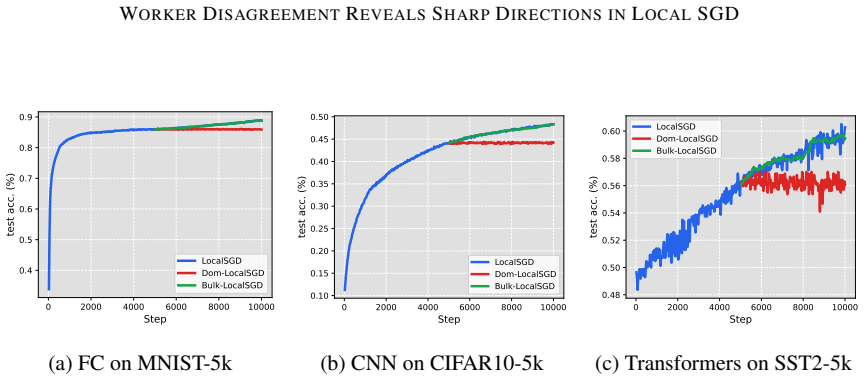
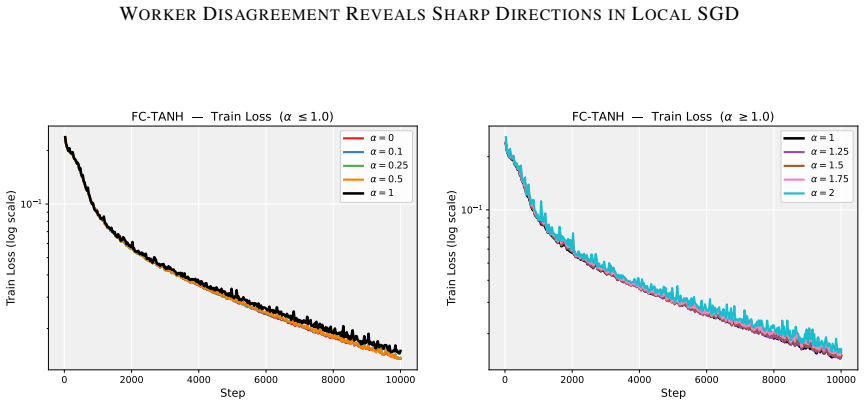
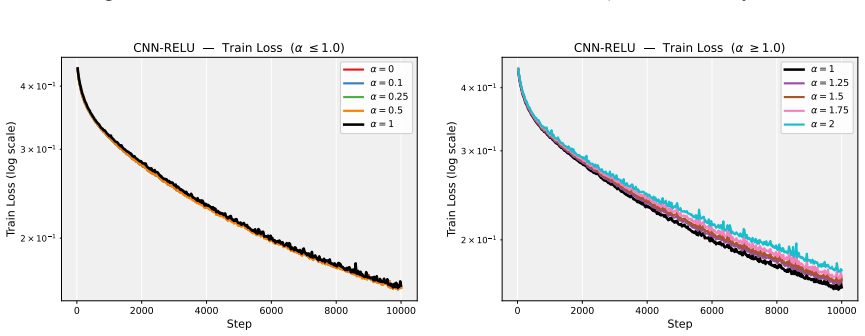
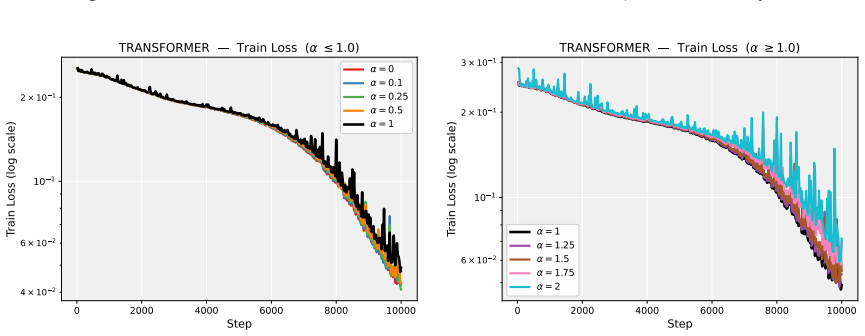
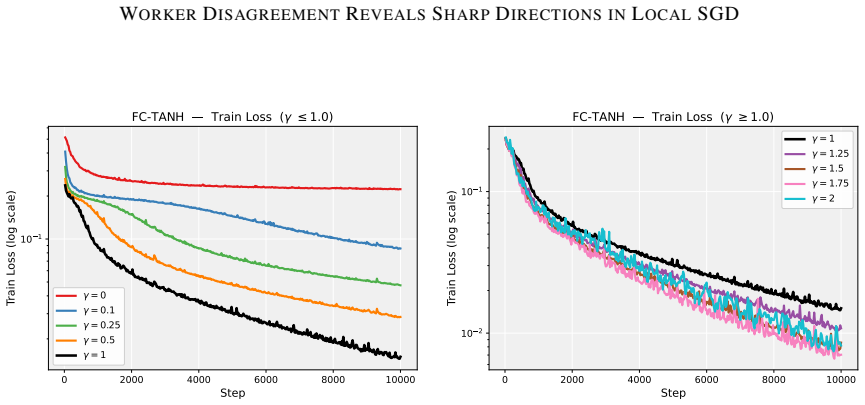
read the original abstract
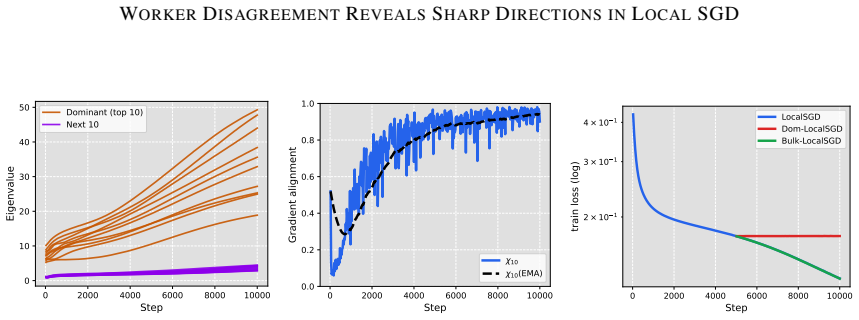
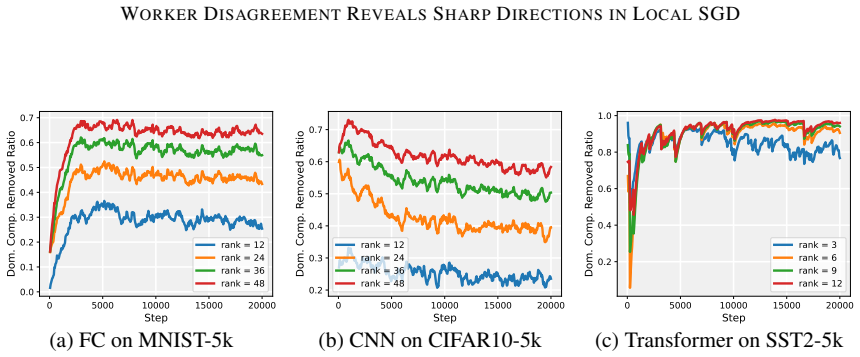
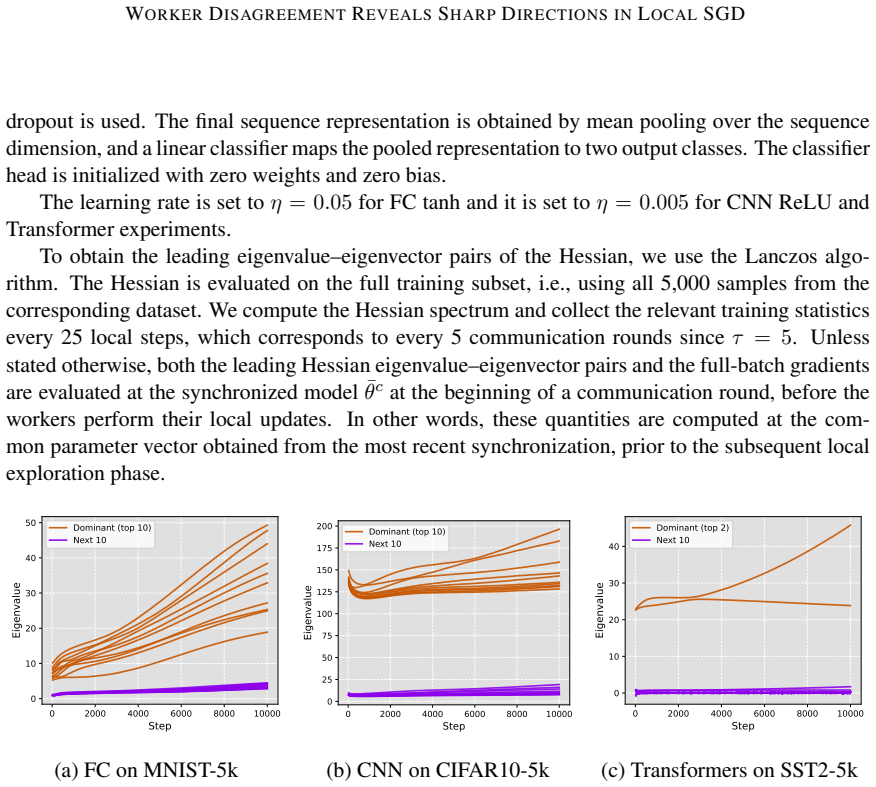
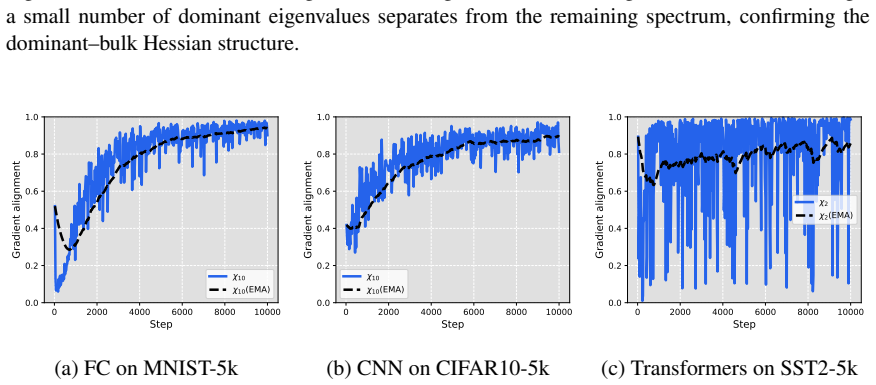
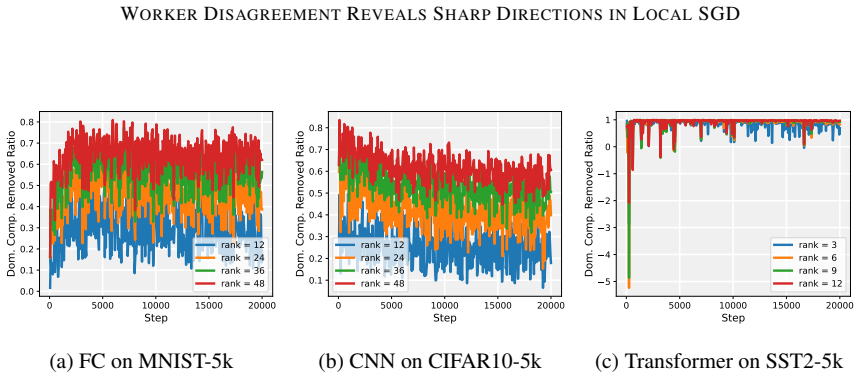
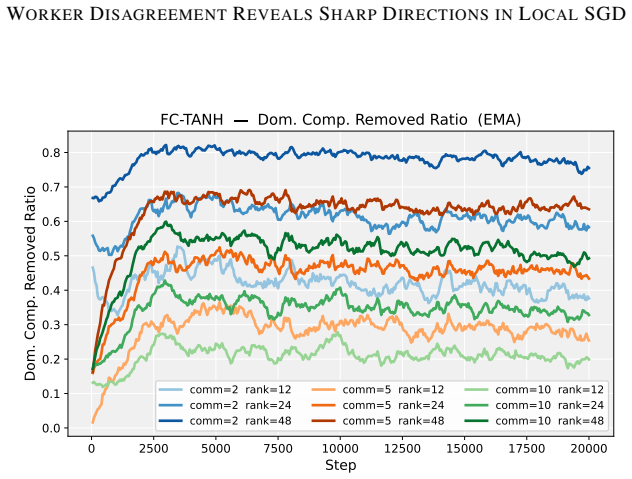
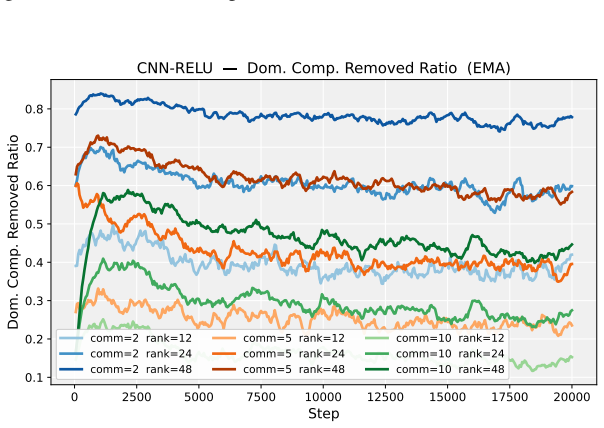
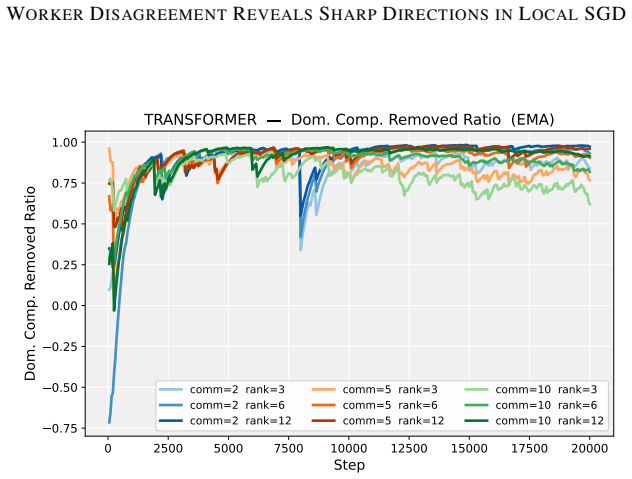
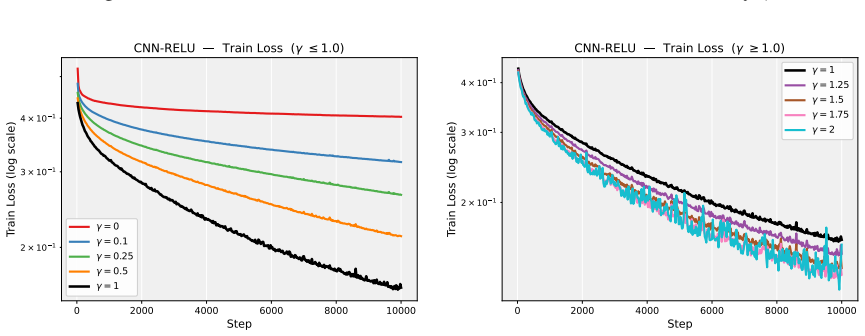
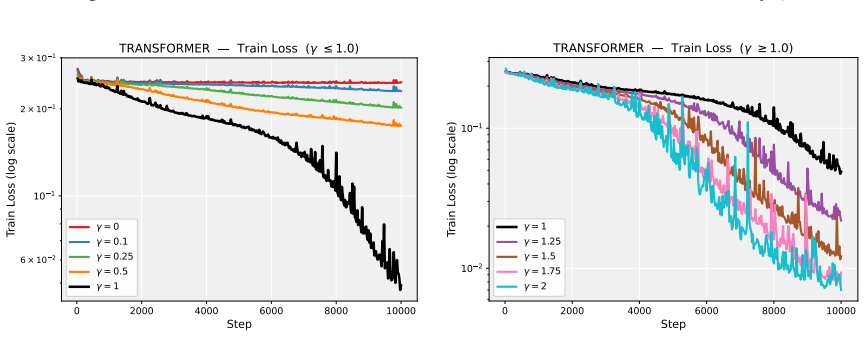
Deep neural network training often exhibits highly anisotropic loss geometry, where a few sharp dominant Hessian directions coexist with a large flatter bulk. Gradients tend to align disproportionately with these dominant directions, although stable progress often requires movement through flatter bulk directions. Estimating the dominant subspace is therefore useful but costly with direct Hessian-based methods. We show that standard Local SGD exposes this geometry through worker disagreement. We theoretically show that the worker-average gap covariance is shaped by stochastic-gradient noise and Hessian curvature, causing workers to disagree along sharp, curvature-sensitive directions. Thus, worker-average gaps provide a cheap Hessian-free estimator of the dominant subspace. Experiments on MLPs, CNNs, and Transformers show that subspaces formed by worker-average gaps capture a substantial fraction of the gradient component lying in the dominant Hessian eigenspace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in Local SGD, the covariance matrix of worker-average gaps is shaped by the interaction of stochastic-gradient noise and Hessian curvature, causing preferential disagreement along sharp directions. This makes the gaps a cheap, Hessian-free estimator of the dominant Hessian eigenspace. A theoretical analysis derives this property under a noise-curvature model, and experiments on MLPs, CNNs, and Transformers show that the resulting subspaces capture a substantial fraction of the gradient component lying in the dominant Hessian eigenspace.
Significance. If the result holds, the work supplies a practical, low-cost alternative to direct Hessian methods for identifying anisotropic loss geometry in deep networks. The experiments across MLPs, CNNs, and Transformers provide concrete evidence that gap-based subspaces align with dominant curvature directions, which could aid both analysis of training dynamics and development of curvature-aware optimizers.
major comments (2)
- [§3] §3 (theoretical derivation of gap covariance): The central claim that worker-average gap covariance is dominated by stochastic-gradient noise interacting with Hessian curvature (producing disagreement along sharp directions) is load-bearing for the estimator property. The derivation should explicitly state the noise model (e.g., isotropic or state-independent) and either derive bounds showing other contributors (finite-batch effects, momentum correlations, trajectory dependence) are negligible or provide a falsifiable condition under which the dominance holds; without this, the subspace estimator conclusion does not follow in general.
- [Experiments] Experiments (Tables/Figures reporting subspace overlap): The reported capture of gradient components in the dominant eigenspace is promising, but the evaluation should include controls that vary the number of local steps or worker count while holding batch size fixed, to test whether the observed alignment scales as predicted by the noise-curvature mechanism rather than by other optimization artifacts.
minor comments (2)
- [§2] Notation for 'worker-average gap' and 'gap covariance' should be defined once with a clear equation early in the paper to avoid ambiguity when comparing to standard Local SGD update rules.
- [Abstract] The abstract states the result holds for 'standard Local SGD' but does not specify whether momentum or other common modifications are included; a brief clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify opportunities to strengthen the clarity of the theoretical assumptions and the experimental validation of the proposed mechanism. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (theoretical derivation of gap covariance): The central claim that worker-average gap covariance is dominated by stochastic-gradient noise interacting with Hessian curvature (producing disagreement along sharp directions) is load-bearing for the estimator property. The derivation should explicitly state the noise model (e.g., isotropic or state-independent) and either derive bounds showing other contributors (finite-batch effects, momentum correlations, trajectory dependence) are negligible or provide a falsifiable condition under which the dominance holds; without this, the subspace estimator conclusion does not follow in general.
Authors: We agree that the noise model must be stated explicitly for the derivation to be self-contained. The analysis in §3 is performed under the standard isotropic, state-independent Gaussian noise model (i.e., each worker’s stochastic gradient is the true gradient plus independent isotropic noise whose variance is independent of the current parameters). In the revised manuscript we will open §3 with a clear statement of this assumption together with the precise noise-curvature model. We will also add a short paragraph providing a falsifiable condition: the gap covariance is dominated by the noise-curvature term whenever the per-coordinate noise variance exceeds the contribution of finite-batch sampling by a factor of at least two (a threshold that can be verified by comparing gap matrices obtained at two different batch sizes while keeping all other hyperparameters fixed). Under the local-SGD regime with modest numbers of local steps, momentum correlations and trajectory dependence remain second-order effects because the workers start from the same point and the local updates are short; we will briefly note this and cite the relevant supporting calculation. revision: yes
-
Referee: [Experiments] Experiments (Tables/Figures reporting subspace overlap): The reported capture of gradient components in the dominant eigenspace is promising, but the evaluation should include controls that vary the number of local steps or worker count while holding batch size fixed, to test whether the observed alignment scales as predicted by the noise-curvature mechanism rather than by other optimization artifacts.
Authors: We appreciate the suggestion for targeted controls. While the existing experiments already span MLPs, CNNs and Transformers and include multiple worker counts, they do not systematically vary the number of local steps at fixed per-worker batch size. In the revised version we will add a new set of controlled runs on the MLP and CNN tasks that sweep the number of local steps (1, 5, 10) while keeping the per-worker batch size constant, and a parallel sweep over worker count (2, 4, 8) at fixed local steps. The resulting subspace-overlap metrics will be reported in an additional figure that directly tests the predicted scaling with the noise-curvature interaction. revision: yes
Circularity Check
No circularity: derivation from Local SGD update and noise model is independent
full rationale
The provided abstract and context describe a first-principles theoretical derivation of the gap covariance from the Local SGD dynamics, stochastic gradient noise, and Hessian curvature. No equations, fitted parameters renamed as predictions, or self-citations are shown that would make the claimed alignment equivalent to the inputs by construction. The result is presented as a consequence of the model assumptions rather than a tautology or load-bearing self-reference. This is the expected non-finding for a modeling paper whose central step is an explicit derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Deep neural network loss landscapes exhibit highly anisotropic geometry with a few sharp dominant Hessian directions coexisting with a large flatter bulk.
- domain assumption The covariance of worker-average gaps is shaped by stochastic-gradient noise and Hessian curvature.
Reference graph
Works this paper leans on
-
[1]
High- dimensional sgd aligns with emerging outlier eigenspaces
Gerard Ben Arous, Reza Gheissari, Jiaoyang Huang, and Aukosh Jagannath. High- dimensional sgd aligns with emerging outlier eigenspaces. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Confer- ence on Learning Representations, volume 2024, pages 47732–47778, 2024. URL https://proceedings.iclr.cc/paper_files/pap...
2024
-
[2]
An investigation into neural net opti- mization via hessian eigenvalue density
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net opti- mization via hessian eigenvalue density. InInternational Conference on Machine Learning, pages 2232–2241. PMLR, 2019
2019
-
[3]
Gradient Descent Happens in a Tiny Subspace
Guy Gur-Ari, Daniel A Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace. arXiv preprint arXiv:1812.04754, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Farzin Haddadpour, Mohammad Mahdi Kamani, Mehrdad Mahdavi, and Viveck R. Cadambe. Local sgd with periodic averaging: Tighter analysis and adaptive synchronization. InAdvances in Neural Information Processing Systems, pages 11082–11094, 2019
2019
-
[5]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[6]
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791
-
[7]
Tao Li, Lei Tan, Zhehao Huang, Qinghua Tao, Yipeng Liu, and Xiaolin Huang. Low dimensional trajectory hypothesis is true: Dnns can be trained in tiny subspaces.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3411–3420, 2023. doi: 10.1109/TPAMI.2022.3178101
-
[8]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Ar- cas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. PMLR, 2017
2017
-
[9]
The Full Spectrum of Deepnet Hessians at Scale: Dynamics with SGD Training and Sample Size
Vardan Papyan. The full spectrum of deepnet hessians at scale: Dynamics with sgd training and sample size.arXiv preprint arXiv:1811.07062, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
Levent Sagun, Leon Bottou, and Yann LeCun. Eigenvalues of the hessian in deep learning: Singularity and beyond.arXiv preprint arXiv:1611.07476, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Levent Sagun, Utku Evci, V Ugur Guney, Yann Dauphin, and Leon Bottou. Empirical analysis of the hessian of over-parametrized neural networks.arXiv preprint arXiv:1706.04454, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Recursive deep models for semantic compositionality over a sen- timent treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sen- timent treebank. InProceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642, 2013. 6 WORKERDISAGREEMENTREVEALSSHARPDIRECTIONS INLOCALSGD
2013
-
[13]
Does sgd really happen in tiny subspaces? InInternational Conference on Learning Representations, volume 2025, pages 8086–8120, 2025
Minhak Song, Kwangjun Ahn, and Chulhee Yun. Does sgd really happen in tiny subspaces? InInternational Conference on Learning Representations, volume 2025, pages 8086–8120, 2025
2025
-
[14]
Local sgd converges fast and communicates little
Sebastian Urban Stich. Local sgd converges fast and communicates little. InICLR 2019- International Conference on Learning Representations, 2019
2019
-
[15]
Investigating the overlooked hessian structure: From CNNs to LLMs
Qian-Yuan Tang, Yufei Gu, Yunfeng Cai, Mingming Sun, Ping Li, zhou Xun, and Zeke Xie. Investigating the overlooked hessian structure: From CNNs to LLMs. InForty-second In- ternational Conference on Machine Learning, 2025. URLhttps://openreview.net/ forum?id=o62ZzfCEwZ
2025
-
[16]
On the overlooked struc- ture of stochastic gradients
Zeke Xie, Qian-Yuan Tang, Mingming Sun, and Ping Li. On the overlooked struc- ture of stochastic gradients. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 66257–66276. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023...
2023
-
[17]
Compressible dynamics in deep overpa- rameterized low-rank learning and adaptation
Can Yaras, Peng Wang, Laura Balzano, and Qing Qu. Compressible dynamics in deep overpa- rameterized low-rank learning and adaptation. In Ruslan Salakhutdinov, Zico Kolter, Kather- ine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning, volume 235 ofPro...
2024
-
[18]
On the Superlinear Relationship between SGD Noise Covariance and Loss Landscape Curvature
Yikuan Zhang, Ning Yang, and Yuhai Tu. On the superlinear relationship between sgd noise covariance and loss landscape curvature.arXiv preprint arXiv:2602.05600, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
BSFA: Leveraging the sub- space dichotomy to accelerate neural network training
WenJie Zhou, Bohan Wang, Wei Chen, and Xueqi Cheng. BSFA: Leveraging the sub- space dichotomy to accelerate neural network training. In Christos Christodoulopoulos, Tan- moy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, pages 18834–18849, Suzhou, China, Novembe...
-
[20]
Zhanxing Zhu, Jingfeng Wu, Bing Yu, Lei Wu, and Jinwen Ma. The anisotropic noise in stochastic gradient descent: Its behavior of escaping from sharp minima and regularization effects.arXiv preprint arXiv:1803.00195, 2018. 7 WORKERDISAGREEMENTREVEALSSHARPDIRECTIONS INLOCALSGD Appendix A. Experiment Details and More Results Here, we provide more details of ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.