A Policy-Driven Runtime Layer for Agentic LLM Serving
Pith reviewed 2026-06-29 16:51 UTC · model grok-4.3
The pith
An agent runtime layer with observe, score, predict, and act primitives coordinates policies across agent frameworks and serving engines using agent identity as the shared coordinate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
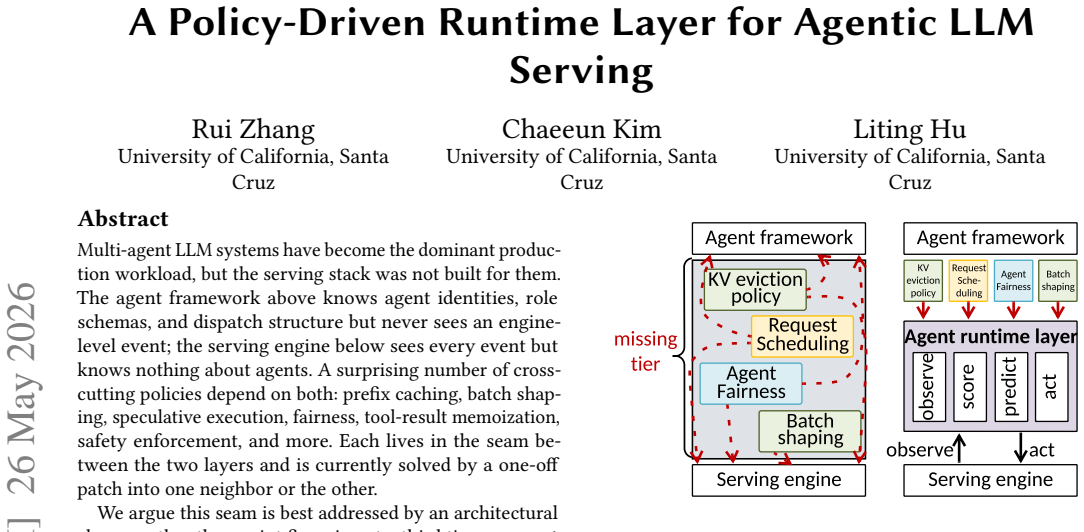
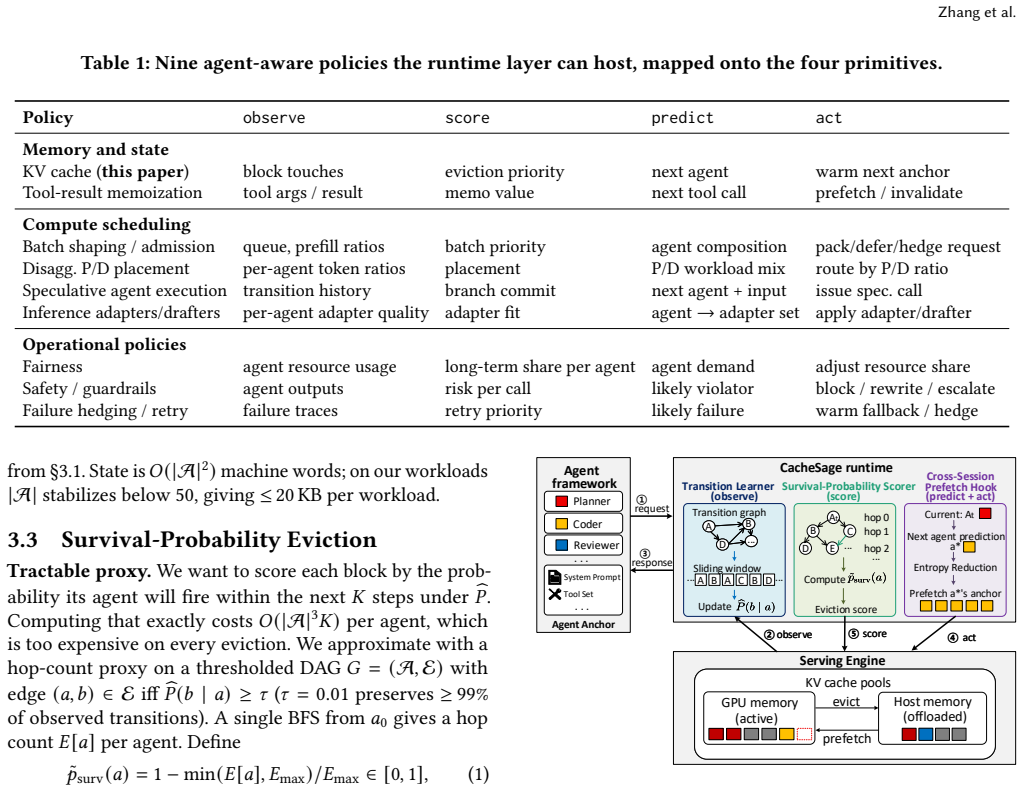
Inserting an agent runtime layer between the framework and the engine, exposing four primitives (observe, score, predict, act) into which any agent-aware policy plugs, with agent identity as the shared coordinate, allows cross-cutting policies to be expressed uniformly instead of through separate patches into either neighbor; the claim is instantiated and measured on KV caching via CacheSage, which learns the agent transition matrix online for survival-based eviction and between-step prefetch.
What carries the argument
The agent runtime layer, which sits between the agent framework and serving engine and coordinates policies through the four primitives observe, score, predict, act using agent identity as the shared coordinate.
If this is right
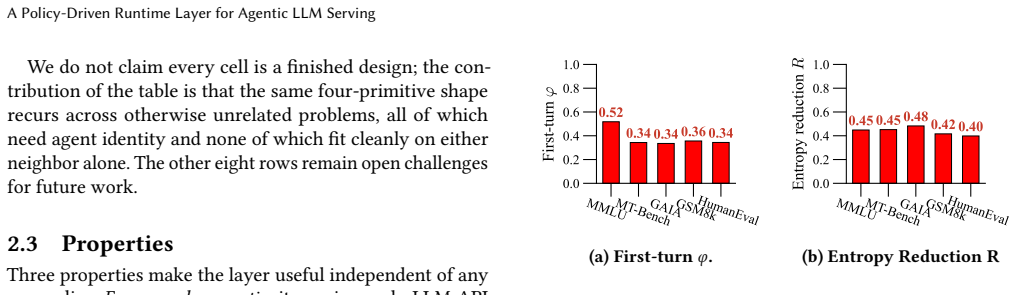
- Nine cross-cutting policies including prefix caching, batch shaping, speculative execution, fairness, tool-result memoization, and safety enforcement can be expressed once inside the runtime layer.
- KV caching across sessions can use an online-learned per-workload agent transition matrix to perform survival-based eviction and between-step prefetching.
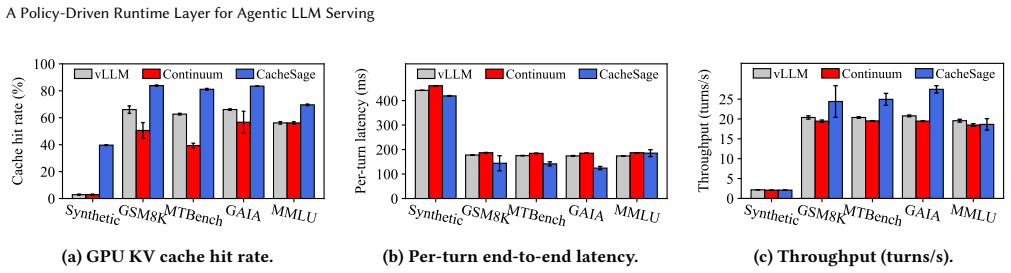
- Mean time-to-first-token can drop 12 to 29 percent and throughput can rise 6 to 14 percent on multi-agent workloads.
- Cache hit rates can increase 13 to 37 percentage points over an unmodified serving stack.
Where Pith is reading between the lines
- The four primitives could serve as a stable interface that lets new policies be developed and tested without touching either the framework or engine code.
- Agent identity as a first-class coordinate might allow the same runtime layer to support dynamic policy composition when workloads mix different agent types.
- The separation of concerns could simplify auditing or rolling back individual policies in production without engine restarts.
Load-bearing premise
Cross-cutting policies that depend on both agent frameworks and serving engines are best solved by adding a new architectural layer rather than by continued point fixes in the existing layers.
What would settle it
A controlled experiment that reimplements the nine policies and CacheSage logic directly inside the framework or engine and measures whether it matches the reported cache hit-rate, TTFT, and throughput gains on the same five workloads.
Figures
read the original abstract
Multi-agent LLM systems have become the dominant production workload, but the serving stack was not built for them. The agent framework above knows agent identities, role, schemas, and dispatch structure but never sees an engine-level event; the serving engine below sees every event but knows nothing about agents. A surprising number of cross-cutting policies depend on both: prefix caching, batch shaping, speculative execution, fairness, tool-result memoization, safety enforcement, and more. Each lives in the seam between the two layers and is currently solved by a one-off patch into one neighbor or the other. We argue this seam is best addressed by an architectural change rather than point fixes: insert a third tier, an agent runtime layer, between the framework and the engine, exposing four primitives (observe, score, predict, act) into which any agent-aware policy plugs, with agent identity as the shared coordinate. We map nine concrete policies onto the layer and validate the abstraction in depth on the one with the largest immediate serving-cost lever: KV caching across sessions, instantiated as CacheSage, which learns the per-workload agent transition matrix online and uses it for survival-based eviction and between-step prefetch. Preliminary results on five real multi-agent workloads show +13 to +37 pp cache hit-rate lift, 12% to 29% lower mean TTFT, and 6% to 14% higher throughput over an unmodified serving stack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-agent LLM serving suffers from a seam between agent frameworks (which know identities and structure) and engines (which see events but lack agent context), leading to ad-hoc point fixes for cross-cutting policies like KV caching and batch shaping. It argues this is best solved by inserting a new agent runtime layer exposing observe/score/predict/act primitives with agent identity as the coordinate, maps nine policies onto it, and validates the abstraction via CacheSage (an online-learned agent transition matrix for survival-based KV eviction and prefetch) on five workloads, reporting +13 to +37 pp hit-rate gains, 12-29% lower TTFT, and 6-14% higher throughput versus an unmodified stack.
Significance. If the architectural argument holds, the layer could reduce fragmentation in policy implementation for agentic workloads. The mapping of nine policies and the concrete, online CacheSage instantiation provide a useful existence proof for the primitives; the reported gains on real workloads are a positive signal, though the evaluation remains preliminary.
major comments (1)
- [Abstract] Abstract: the central claim that the seam 'is best addressed by an architectural change rather than point fixes' is load-bearing for the recommendation yet unsupported by direct evidence. The only quantitative comparison is CacheSage versus an unmodified baseline; no equivalent policy implemented as a minimal patch into the engine (or framework) that could exploit agent identity is evaluated, leaving open whether the reported gains require the new layer or could be matched at lower integration cost.
minor comments (2)
- [Abstract] Abstract: workload descriptions, baseline engine/framework versions, error bars, and statistical tests are absent from the reported results, making it difficult to assess the reliability of the +13 to +37 pp hit-rate and throughput numbers.
- [Abstract] Abstract: the transition matrix is described as 'learned online' but no detail is given on its parameterization, update rule, or free parameters, which would clarify the scope of the 'parameter-free' aspects of the policy.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the focus on the load-bearing claim in the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the seam 'is best addressed by an architectural change rather than point fixes' is load-bearing for the recommendation yet unsupported by direct evidence. The only quantitative comparison is CacheSage versus an unmodified baseline; no equivalent policy implemented as a minimal patch into the engine (or framework) that could exploit agent identity is evaluated, leaving open whether the reported gains require the new layer or could be matched at lower integration cost.
Authors: We agree that the manuscript provides no direct head-to-head evaluation of an equivalent policy implemented as a minimal patch. The central argument is conceptual: agent identity, roles, and dispatch structure exist only in the framework, while engine events lack this coordinate, so any agent-aware policy must bridge the seam. A patch into the engine would require either (a) extending the framework-engine interface to carry agent context on every event (which recreates the runtime layer's role) or (b) ad-hoc duplication of agent logic inside the engine for each policy. The paper maps nine distinct policies (KV caching, batch shaping, speculative execution, fairness, tool-result memoization, safety, etc.) onto the same four primitives to illustrate that a single layer can host them without repeated interface changes. The CacheSage evaluation demonstrates that one such policy can be realized cleanly via the primitives and yields measurable gains, but we did not implement or benchmark the corresponding point-fix versions. Adding those comparisons would require substantial additional engineering outside the paper's scope and is not planned for revision. revision: no
Circularity Check
No circularity: architectural argument validated empirically on external workloads
full rationale
The paper's central claim is an architectural recommendation (insert runtime layer exposing observe/score/predict/act with agent identity as coordinate) rather than a mathematical derivation. Validation uses CacheSage, which learns the agent transition matrix online from real multi-agent workloads (external data). No equations, fitted predictions, or self-citations are shown that reduce any result to its own inputs by construction. The transition matrix and performance deltas (+13-37pp hit-rate, etc.) are measured against unmodified baselines on five workloads, satisfying the self-contained-against-external-benchmarks criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- agent transition matrix
axioms (1)
- domain assumption Many cross-cutting policies depend on both agent identities/roles and engine-level events.
invented entities (1)
-
agent runtime layer
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Zhuohang Bian, Feiyang Wu, Teng Ma, and Youwei Zhuo. 2025. Token- cake: A KV-Cache-centric Serving Framework for LLM-based Multi- Agent Applications.arXiv preprint arXiv:2510.18586(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Hee- woo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Datadog. 2026. State of AI Engineering 2026. Industry report, https: //www.datadoghq.com/state-of-ai-engineering/
2026
-
[6]
Yixin Dong, Charlie F Ruan, Yaxing Cai, Ziyi Xu, Yilong Zhao, Ruihang Lai, and Tianqi Chen. 2025. Xgrammar: Flexible and efficient structured generation engine for large language models.Proceedings of Machine Learning and Systems7 (2025)
2025
- [7]
-
[8]
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandel- wal, and Lin Zhong. 2024. Prompt cache: Modular attention reuse for low-latency inference.Proceedings of Machine Learning and Systems6 (2024), 325–338
2024
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al. 2024. MetaGPT: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Rep- resentations, Vol. 2024. 23247–23275
2024
-
[12]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[13]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[14]
LangChain. 2026. State of Agent Engineering 2026. Industry survey, https://www.langchain.com/state-of-agent-engineering
2026
-
[15]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. {InfiniGen}: Efficient generative inference of large language models with dynamic{KV}cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 155–172
2024
-
[16]
Hanchen Li, Runyuan He, Qiuyang Mang, Qizheng Zhang, Huanzhi Mao, Xiaokun Chen, Hangrui Zhou, Alvin Cheung, Joseph Gonza- lez, and Ion Stoica. 2025. Continuum: Efficient and robust multi- turn llm agent scheduling with kv cache time-to-live.arXiv preprint arXiv:2511.02230(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. 2024. Parrot: Efficient serving of {LLM-based} applications with semantic variable. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 929–945
2024
-
[18]
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaot- ing Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, et al
- [19]
-
[20]
Yuhan Liu, Yuyang Huang, Jiayi Yao, Shaoting Feng, Zhuohan Gu, Kuntai Du, Hanchen Li, Yihua Cheng, Junchen Jiang, Shan Lu, et al
- [21]
- [22]
-
[23]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. Gaia: a benchmark for general ai assistants. In International Conference on Learning Representations, Vol. 2024. 9025– 9049
2024
-
[24]
OpenAI. 2024. Swarm: Educational framework exploring ergonomic, lightweight multi-agent orchestration. https://github.com/openai/ swarm
2024
-
[25]
Zaifeng Pan, AJJKUMAR DAHYALAL PATEL, Yipeng Shen, Zhengding Hu, Yue Guan, Wan-Lu Li, Lianhui Qin, Yida Wang, and Yufei Ding. 2026. KVFlow: Efficient prefix caching for accelerating LLM-based multi-agent workflows.Advances in Neural Information Processing Systems38 (2026), 126246–126265
2026
- [26]
-
[27]
Rana Shahout, Cong Liang, Shiji Xin, Qianru Lao, Yong Cui, Minlan Yu, and Michael Mitzenmacher. 2026. Fast inference for augmented large language models.Advances in Neural Information Processing Systems38 (2026), 71562–71591
2026
-
[28]
Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dongming Li, and Yiying Zhang. 2025. Preble: Efficient distributed prompt scheduling for llm serving. InInternational conference on learning representations, Vol. 2025. 37057–37082
2025
-
[29]
Yifan Sui, Han Zhao, Rui Ma, Zhiyuan He, Hao Wang, Jianxun Li, and Yuqing Yang. 2026. Act while thinking: Accelerating llm agents via pattern-aware speculative tool execution.arXiv preprint arXiv:2603.18897(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Dezhan Tu, Danylo Vashchilenko, Yuzhe Lu, and Panpan Xu. 2025. VL- cache: Sparsity and modality-aware KV cache compression for vision- language model inference acceleration. InInternational Conference on Learning Representations, Vol. 2025. 219–239
2025
- [31]
-
[32]
Brandon T Willard and Rémi Louf. 2023. Efficient guided generation for large language models.arXiv preprint arXiv:2307.09702(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. 2024. Autogen: Enabling next-gen LLM applications via multi-agent conver- sations. InFirst conference on language modeling
2024
-
[34]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. Cacheblend: 6 A Policy-Driven Runtime Layer for Agentic LLM Serving Fast large language model serving for rag with cached knowledge fusion. InProceedings of the twentieth European conference on computer systems. 94–109
2025
-
[35]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Hancheng Ye, Zhengqi Gao, Mingyuan Ma, Qinsi Wang, Yuzhe Fu, Ming-Yu Chung, Yueqian Lin, Zhijian Liu, Jianyi Zhang, Danyang Zhuo, et al. 2026. Kvcomm: Online cross-context kv-cache communi- cation for efficient llm-based multi-agent systems.Advances in Neural Information Processing Systems38 (2026), 17882–17928
2026
-
[37]
Rui Zhang and Liting Hu. 2025. Enabling Fairness Across Multi-modal and Multi-agent Applications. In2025 IEEE International Conference on Edge Computing and Communications (EDGE). IEEE, 90–92
2025
-
[38]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhang- hao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems36 (2023), 46595– 46623
2023
-
[39]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured lan- guage model programs.Advances in neural information processing systems37 (2024), 62557–62583. 7
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.