Can Segmentation Models Understand the World? Towards Proactive Affordance Reasoning via Visual Chain-of-Thought
Pith reviewed 2026-06-29 17:45 UTC · model grok-4.3
The pith
Segmentation models improve on intent-level instructions by first proactively reasoning about scenes via visual chain-of-thought.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
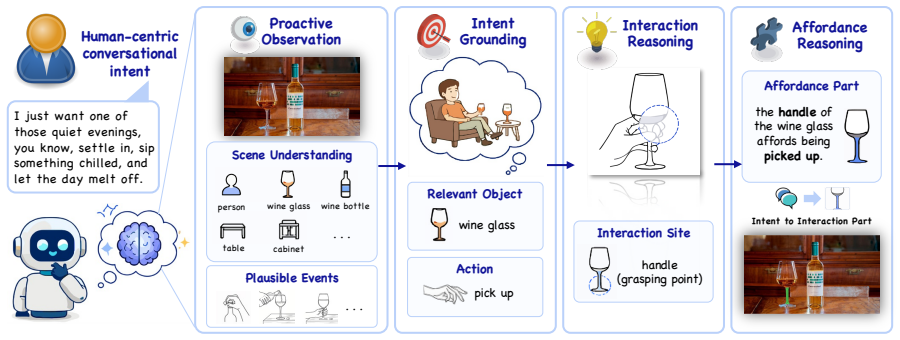
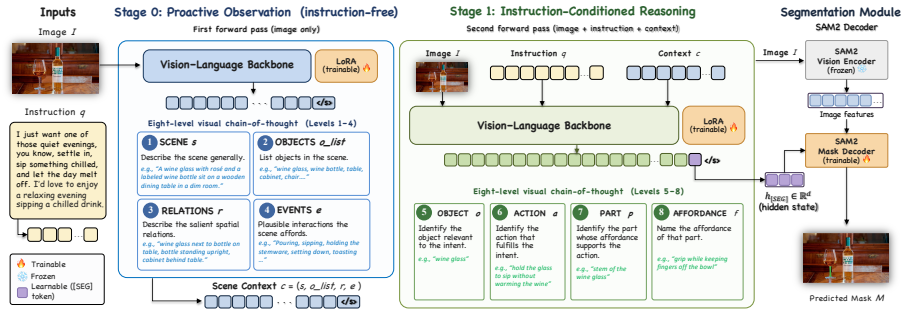
SegWorld reasons about the scene through a multi-level visual chain-of-thought before committing to a mask. Before receiving any instructions, it proactively observes the scene, describing visible objects and inferring plausible events they may support. Given an instruction, it continues the chain: from the object relevant to the intent, through the action that satisfies it, to the physical interaction site, the object part that affords the action. The approach is formalized as probabilistic inference in which proactive observation supplies a linguistic scene context that improves mask prediction when instructions are given at the level of intent.
What carries the argument
Multi-level visual chain-of-thought that begins with proactive scene observation and proceeds through object, action, interaction site, and affording part to produce the final mask.
If this is right
- Matches instruction-driven baselines on target-referential instructions
- Substantially improves performance on intent-level instructions
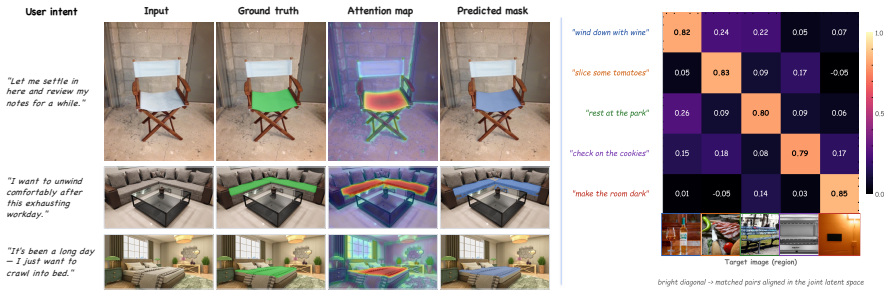
- Supports evaluation through a constructed intent-to-part benchmark for affordance-bearing part segmentation
Where Pith is reading between the lines
- The same proactive chain could be tested on downstream embodied tasks such as robotic grasping to check whether the inferred parts lead to successful actions.
- Early scene context might reduce ambiguity in instructions that refer to multiple possible regions.
- The method might generalize to other vision-language grounding problems that currently assume all context arrives with the query.
- If the chain-of-thought steps can be made explicit and editable, users could inspect or correct intermediate inferences before mask output.
Load-bearing premise
Proactive observation of the scene before any instruction supplies a linguistic context that reliably improves mask prediction for intent-level instructions.
What would settle it
An experiment on the intent-to-part benchmark in which SegWorld shows no substantial improvement over instruction-driven baselines on intent-level instructions would falsify the benefit of the proactive chain-of-thought.
Figures


read the original abstract
Recent segmentation models couple large language models (LLMs) with mask decoders to ground complex language expressions into masks, yet their instructions remain target-referential: they describe, constrain, or imply the region to be segmented. However, in real-world embodied interaction, human instructions are often at the intent-level, which includes the desired outcome without naming the region that enables it. To bridge this gap, we introduce SegWorld, where the model reasons about the scene through a multi-level visual chain-of-thought (CoT) before committing to a mask. Before receiving any instructions, it proactively observes the scene, describing visible objects and inferring plausible events they may support. Given an instruction, it continues the chain: from the object relevant to the intent, through the action that satisfies it, to the physical interaction site, the object part that affords the action. We formalize SegWorld as probabilistic inference, in which proactive observation supplies a linguistic scene context that improves mask prediction when instructions are given at the level of intent. We construct an intent-to-part benchmark for evaluating affordance-bearing part segmentation from high-level goals. Experiments show SegWorld matches instruction-driven baselines on target-referential instructions and improves substantially on intent-level ones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SegWorld, a model that augments LLM-based segmentation with a multi-level visual chain-of-thought. Before any instruction, the model proactively observes the scene to describe objects and infer plausible events. Given an intent-level instruction, it continues the chain from relevant object through action to the affordance-bearing part. The approach is formalized as probabilistic inference in which the proactive stage supplies linguistic scene context that improves mask prediction. A new intent-to-part benchmark is introduced; experiments claim that SegWorld matches instruction-driven baselines on target-referential instructions and substantially outperforms them on intent-level instructions.
Significance. If the performance gains are shown to be driven by the proactive observation component, the work would meaningfully extend segmentation models toward embodied, intent-driven settings by demonstrating that pre-instruction scene reasoning can supply useful context for affordance-based part segmentation. The construction of the intent-to-part benchmark itself provides a concrete evaluation resource for future affordance reasoning research.
major comments (1)
- [Experiments] Experiments section: the reported gains on the intent-to-part benchmark are obtained by comparing the full SegWorld pipeline (proactive observation + multi-level CoT) against instruction-driven baselines. No ablation is described that runs the same multi-level CoT reasoning without the proactive pre-instruction observation stage. This control is load-bearing for the central claim (abstract and formalization paragraph) that proactive observation supplies the linguistic scene context responsible for improved mask prediction on intent-level instructions; without it, the gains could be attributable to the CoT structure alone.
minor comments (1)
- [Formalization] The probabilistic formalization paragraph would benefit from an explicit statement of the joint distribution or inference procedure (e.g., how the proactive context is incorporated into the mask prediction posterior) to make the claimed improvement mechanism fully verifiable.
Simulated Author's Rebuttal
We thank the referee for this constructive comment highlighting the importance of isolating the contribution of proactive observation. We agree that the requested ablation is necessary to strengthen the central claim and will incorporate it in the revision.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported gains on the intent-to-part benchmark are obtained by comparing the full SegWorld pipeline (proactive observation + multi-level CoT) against instruction-driven baselines. No ablation is described that runs the same multi-level CoT reasoning without the proactive pre-instruction observation stage. This control is load-bearing for the central claim (abstract and formalization paragraph) that proactive observation supplies the linguistic scene context responsible for improved mask prediction on intent-level instructions; without it, the gains could be attributable to the CoT structure alone.
Authors: We agree that the current comparison does not fully isolate the proactive stage. The instruction-driven baselines use neither proactive observation nor the multi-level CoT structure. To address the referee's point, we will add a new ablation that applies the identical multi-level CoT reasoning but omits the pre-instruction proactive observation phase, starting the chain directly from the intent-level instruction. This will quantify the marginal benefit of the proactive linguistic scene context. The revised manuscript will report these results alongside the existing experiments. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces SegWorld via a modeling choice to formalize proactive pre-instruction observation as supplying linguistic scene context within probabilistic inference for intent-level mask prediction. This is an external assumption, not a derived quantity. No equations, fitted parameters, or self-citations are present that reduce the reported gains or central claim to inputs by construction. Experiments compare the full pipeline to instruction-driven baselines on target-referential and intent-level tasks without indicating statistical forcing. The derivation remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chai- tanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, and 1 others. 2025. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719. Hengshuo Chu, Xiang Deng, Qi Lv, Xiaoyang C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Stage 0 is always supervised with its language- modeling loss. Baseline training.Trainable baselines are fine- tuned on the same Intent2Part training split with the same instruction pool, optimizer, batch size, train- ing budget, and mask loss as SegWorld whenever their released implementations support supervised fine-tuning. Off-the-shelf Sa2V A is evalu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.