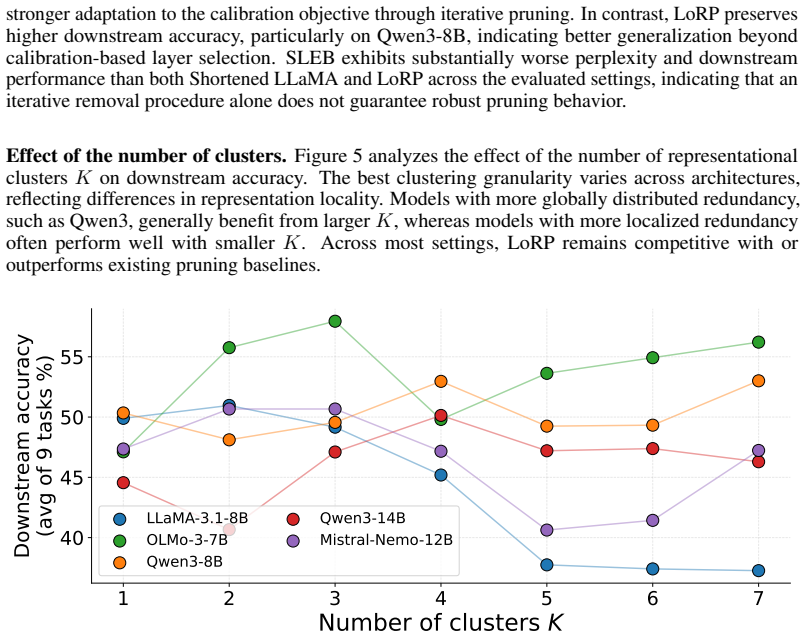
Locality-Aware Redundancy Pruning for LLM Depth Compression
Pith reviewed 2026-06-29 13:50 UTC · model grok-4.3
The pith
LoRP prunes LLM layers by clustering them according to global hidden-state similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
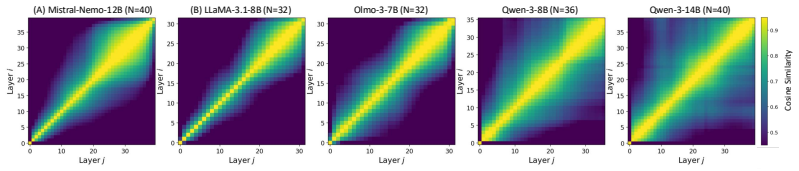
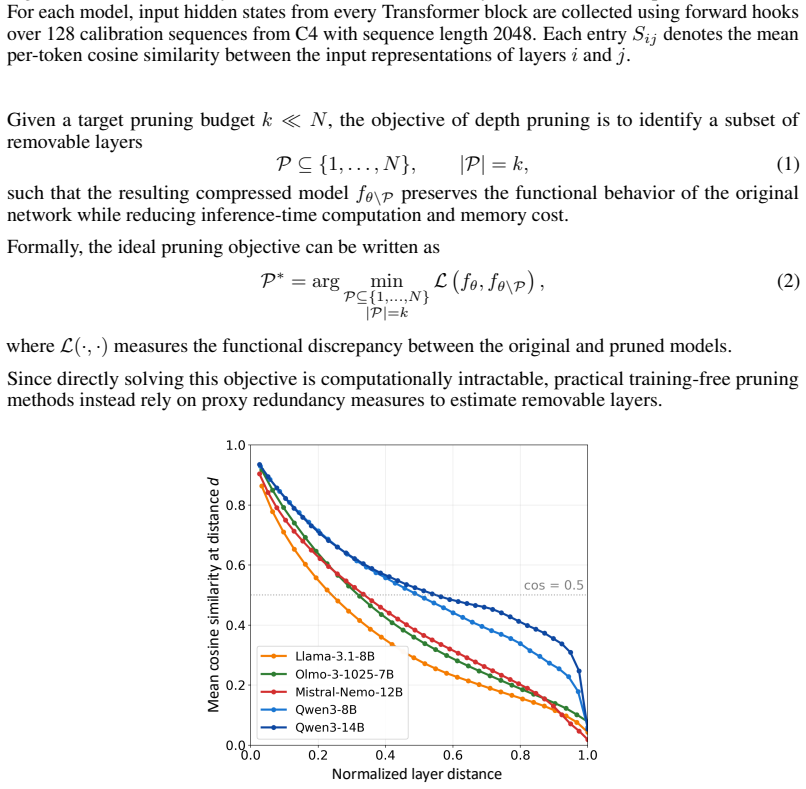
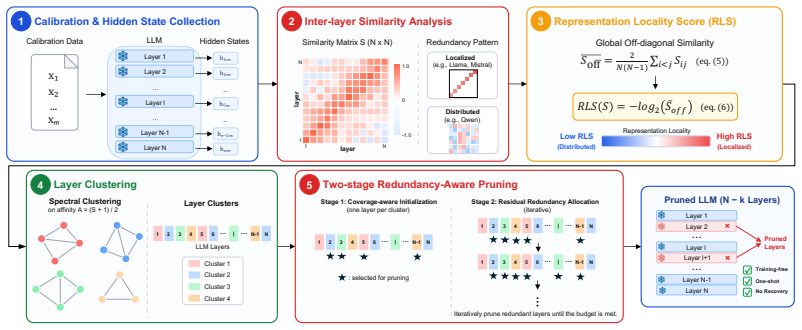
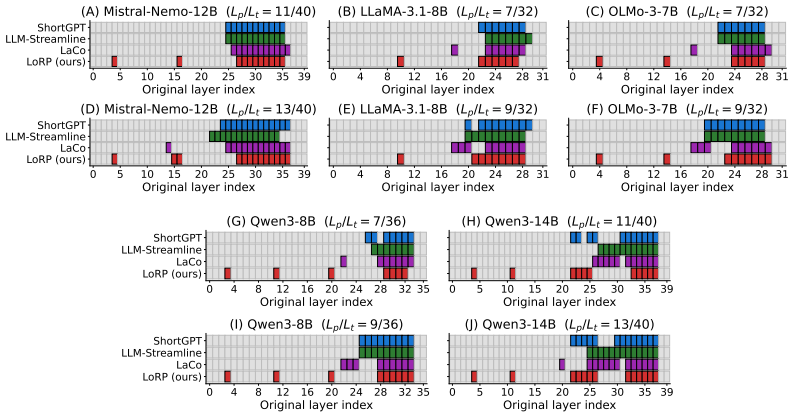
LoRP computes pairwise similarities between hidden states across layers on a calibration set, derives a Representation Locality Score that distinguishes localized from globally distributed redundancy, clusters layers by representational similarity, and allocates the number of layers to prune according to the residual redundancy inside each cluster.
What carries the argument
Representation Locality Score (RLS), computed from global inter-layer hidden-state similarity, which both characterizes redundancy distribution and determines how many layers to remove from each similarity cluster.
If this is right
- Pruning can be adapted automatically to whether an architecture shows localized or distributed redundancy.
- One-shot depth compression becomes viable across families without architecture-specific tuning.
- A small calibration set suffices to decide layer removals that preserve both perplexity and task accuracy.
- Models whose redundancy is globally distributed benefit more from the clustering step than from per-layer scoring.
Where Pith is reading between the lines
- The same similarity clustering could be tested as a diagnostic tool to decide how many layers an architecture should have before training.
- If the calibration set is expanded or chosen differently, the identified clusters might shift and change the pruning outcome.
- Extending the method to prune non-consecutive layers within a cluster could be checked against the current consecutive-removal rule.
Load-bearing premise
Pairwise hidden-state similarity measured on a small calibration set is enough to identify which layers inside a cluster can be removed without harming overall model capability more than local baselines.
What would settle it
Running LoRP and a local-importance baseline on the same new LLM family and calibration set, then finding that the local baseline yields lower perplexity or higher downstream accuracy, would falsify the central claim.
Figures
read the original abstract
Large language models are known to contain representational redundancy across network depth, making depth pruning an effective approach for improving inference efficiency. Existing one-shot pruning methods rely on local layer importance or fixed redundancy assumptions across architectures. We propose Locality-Aware Redundancy Pruning (LoRP), a training-free one-shot depth pruning framework guided by representation locality. We show that inter-layer redundancy can be either localized or globally distributed depending on the LLM architecture. To characterize this phenomenon, we introduce Representation Locality Score (RLS), derived from global inter-layer hidden-state similarity. Using a small calibration set, LoRP computes pairwise layer similarity, clusters layers by representational similarity, and allocates pruning according to residual intra-cluster redundancy. Experiments across diverse LLM families show improvements in both perplexity and downstream task accuracy. Official github repository: https://github.com/daniel-eai/LoRP-Locality-Aware-Redundancy-Pruning/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Locality-Aware Redundancy Pruning (LoRP), a training-free one-shot depth pruning framework for LLMs. It introduces the Representation Locality Score (RLS) computed from pairwise inter-layer hidden-state similarities on a small calibration set, clusters layers according to representational similarity, and allocates pruning to exploit residual intra-cluster redundancy. The central claim is that this locality-aware allocation yields better perplexity and downstream-task accuracy than local-importance baselines across multiple LLM families.
Significance. If the empirical gains are robust, the work offers a practical, architecture-sensitive alternative to uniform or locally greedy depth pruning. Distinguishing localized versus globally distributed redundancy via RLS is a useful conceptual contribution, and the public GitHub repository supports reproducibility. The training-free, one-shot nature aligns with common deployment constraints.
major comments (2)
- [Method] Method section (RLS and clustering description): the central claim that pre-pruning pairwise similarities on a calibration set correctly identify removable intra-cluster redundancy is load-bearing, yet the manuscript provides no analysis of how layer removal changes the input distribution to downstream layers. Because depth pruning is sequential, similarities measured on the intact model need not predict post-pruning behavior; an ablation or sensitivity study on calibration-set size, prompt distribution, or similarity metric is required to substantiate the allocation rule.
- [Experiments] Experiments section (results tables): the reported improvements in perplexity and accuracy lack error bars, multiple random seeds, or explicit variation over calibration-set size and similarity metric. Without these, it is impossible to determine whether the gains over local-importance baselines are statistically reliable or sensitive to the narrow calibration distribution.
minor comments (1)
- [Abstract / Method] The abstract states that RLS is 'derived from global inter-layer hidden-state similarity' but does not specify the exact similarity function or normalization; this notation should be clarified in the main text with an equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and commit to revisions that will strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Method] Method section (RLS and clustering description): the central claim that pre-pruning pairwise similarities on a calibration set correctly identify removable intra-cluster redundancy is load-bearing, yet the manuscript provides no analysis of how layer removal changes the input distribution to downstream layers. Because depth pruning is sequential, similarities measured on the intact model need not predict post-pruning behavior; an ablation or sensitivity study on calibration-set size, prompt distribution, or similarity metric is required to substantiate the allocation rule.
Authors: We acknowledge that sequential layer removal can induce distribution shifts to downstream layers, and that pre-pruning similarities on the intact model do not automatically guarantee post-pruning behavior. Our design choice rests on the empirical finding that RLS-derived clusters identify redundancies whose removal improves perplexity and accuracy across architectures; however, to directly address the concern we will add a sensitivity analysis on calibration-set size, prompt distribution, and similarity metric in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section (results tables): the reported improvements in perplexity and accuracy lack error bars, multiple random seeds, or explicit variation over calibration-set size and similarity metric. Without these, it is impossible to determine whether the gains over local-importance baselines are statistically reliable or sensitive to the narrow calibration distribution.
Authors: The gains are observed consistently across multiple LLM families and tasks. To establish statistical reliability we will report error bars from multiple random seeds and include explicit ablations over calibration-set size and similarity metric in the revised experiments. revision: yes
Circularity Check
No circularity: RLS and pruning allocation derived from observable calibration-set similarities without self-referential reduction.
full rationale
The paper computes pairwise layer similarities on a small calibration set, derives RLS from global inter-layer hidden-state similarity, clusters layers, and allocates pruning by residual intra-cluster redundancy. No quoted equations or steps show the allocation reducing to a fitted parameter renamed as prediction, a self-citation load-bearing premise, or an ansatz smuggled via prior work; the central procedure remains an explicit computation from data rather than a definitional loop or imported uniqueness claim. Experimental results are presented as empirical outcomes, not forced by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs contain representational redundancy across network depth that can be measured via hidden-state similarity
invented entities (2)
-
Representation Locality Score (RLS)
no independent evidence
-
LoRP framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fluctuation-based adaptive structured pruning for large language models
Yongqi An, Xu Zhao, Tao Yu, Ming Tang, and Jinqiao Wang. Fluctuation-based adaptive structured pruning for large language models. InAAAI Conference on Artificial Intelligence, 2024
2024
-
[2]
Croci, Marcelo Gennari Nascimento, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Maximilian L. Croci, Marcelo Gennari Nascimento, Torsten Hoefler, and James Hensman. SliceGPT: Compress large language models by deleting rows and columns. In International Conference on Learning Representations (ICLR), 2024
2024
-
[3]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[4]
Stream- lining redundant layers to compress large language models
Xiaodong Chen, Yuxuan Hu, Jing Zhang, Yanling Wang, Cuiping Li, and Hong Chen. Stream- lining redundant layers to compress large language models. InInternational Conference on Learning Representations, volume 2025, pages 30362–30383, 2025
2025
-
[5]
BoolQ: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers),...
2019
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
The PASCAL recognising textual entailment challenge
Ido Dagan, Oren Glickman, and Bernardo Magnini. The PASCAL recognising textual entailment challenge. InMachine Learning Challenges Workshop, pages 177–190. Springer, 2005
2005
-
[8]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
SparseGPT: Massive language models can be accurately pruned in one-shot
Elias Frantar and Dan Alistarh. SparseGPT: Massive language models can be accurately pruned in one-shot. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[10]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[11]
The unreasonable ineffectiveness of the deeper layers
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Daniel A Roberts. The unreasonable ineffectiveness of the deeper layers. InInternational Conference on Learning Representations, volume 2025, pages 81906–81920, 2025
2025
-
[12]
Shortened LLaMA: A simple depth pruning for large language models
Bo-Kyeong Kim, Geonmin Kim, Tae-Ho Kim, Thibault Castells, Shinkook Choi, Junho Shin, and Hyoung-Kyu Song. Shortened LLaMA: A simple depth pruning for large language models. arXiv preprint arXiv:2402.02834, 2024
-
[13]
Minkyu Kim, Vincent-Daniel Yun, Youngrae Kim, Youngjin Heo, Suin Cho, Seong-hun Kim, Woosang Lim, and Gaeul Kwon. Rethinking layer redundancy in large language models: Calibration objectives and search for depth pruning.arXiv preprint arXiv:2604.24938, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
RACE: Large-scale ReAding comprehension dataset from examinations
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785–794, 2017
2017
-
[15]
Reddi, Ke Ye, Felix Chern, Felix Yu, Ruiqi Guo, and Sanjiv Kumar
Zonglin Li, Chong You, Srinadh Bhojanapalli, Daliang Li, Ankit Singh Rawat, Sashank J. Reddi, Ke Ye, Felix Chern, Felix Yu, Ruiqi Guo, and Sanjiv Kumar. The lazy neuron phenomenon: On emergence of activation sparsity in transformers. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[16]
LLM-pruner: On the structural pruning of large language models
Xinyin Ma, Gongfan Fang, and Xinchao Wang. LLM-pruner: On the structural pruning of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[17]
Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz
Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of English: The Penn Treebank.Computational Linguistics, 19(2):313–330, 1993
1993
-
[18]
Shortgpt: Layers in large language models are more redundant than you expect
Xin Men, Mingyu Xu, Qingyu Zhang, Qianhao Yuan, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. Shortgpt: Layers in large language models are more redundant than you expect. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20192–20204, 2025
2025
-
[19]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[20]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, 2018
2018
-
[21]
Mistral NeMo
Mistral AI. Mistral NeMo. https://mistral.ai/news/mistral-nemo, 2024. Accessed: 2026-05-21
2024
-
[22]
Compact language models via pruning and knowledge distillation
Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, and Pavlo Molchanov. Compact language models via pruning and knowledge distillation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[23]
Ng, Michael I
Andrew Y . Ng, Michael I. Jordan, and Yair Weiss. On spectral clustering: Analysis and an algorithm. InAdvances in Neural Information Processing Systems (NeurIPS), 2001
2001
-
[24]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, et al. 2 OLMo 2 furious.arXiv preprint arXiv:2501.00656, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(1), 2020
2020
-
[26]
Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S. Gordon. Choice of plausible alternatives: An evaluation of commonsense causal reasoning. InAAAI Spring Symposium: Logical Formalizations of Commonsense Reasoning, 2011
2011
-
[27]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.arXiv preprint arXiv:1907.10641, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[28]
SLEB: Streamlining LLMs through redundancy verification and elimination of transformer blocks
Jiwon Song, Kyungseok Oh, Taesu Kim, Hyungjun Kim, Yulhwa Kim, and Jae-Joon Kim. SLEB: Streamlining LLMs through redundancy verification and elimination of transformer blocks. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[29]
Zico Kolter
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. A simple and effective pruning approach for large language models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[30]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2017
2017
-
[32]
A tutorial on spectral clustering.Statistics and Computing, 17(4):395–416, 2007
Ulrike von Luxburg. A tutorial on spectral clustering.Statistics and Computing, 17(4):395–416, 2007. 12
2007
-
[33]
Sheared LLaMA: Accelerating language model pre-training via structured pruning
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. Sheared LLaMA: Accelerating language model pre-training via structured pruning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
LaCo: Large language model pruning via layer collapse
Yifei Yang, Zouying Cao, and Hai Zhao. LaCo: Large language model pruning via layer collapse. InFindings of the Association for Computational Linguistics: EMNLP, 2024
2024
-
[36]
Robust neural pruning with gradient sampling optimization for residual neural networks
Juyoung Yun. Robust neural pruning with gradient sampling optimization for residual neural networks. In2024 International Joint Conference on Neural Networks (IJCNN), pages 1–10, 2024
2024
-
[37]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
2019
-
[38]
A survey on model compression for large language models.Transactions of the Association for Computational Linguistics (TACL), 2024
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. A survey on model compression for large language models.Transactions of the Association for Computational Linguistics (TACL), 2024. 13 Appendix A Inference Efficiency of Pruned LLMs We complement the language modeling and downstream evaluation results with an inference- efficiency analysis on Qwen3-1...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.