A Fixed-Budget, Cluster-Aware Standard for LLM-as-a-Judge Evaluation: A Multi-Hop RAG Stress Test
Pith reviewed 2026-06-29 13:18 UTC · model grok-4.3
The pith
A fixed-budget cluster-aware standard for LLM-as-a-judge RAG evaluation reduces four apparently significant semantic baseline wins to only one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
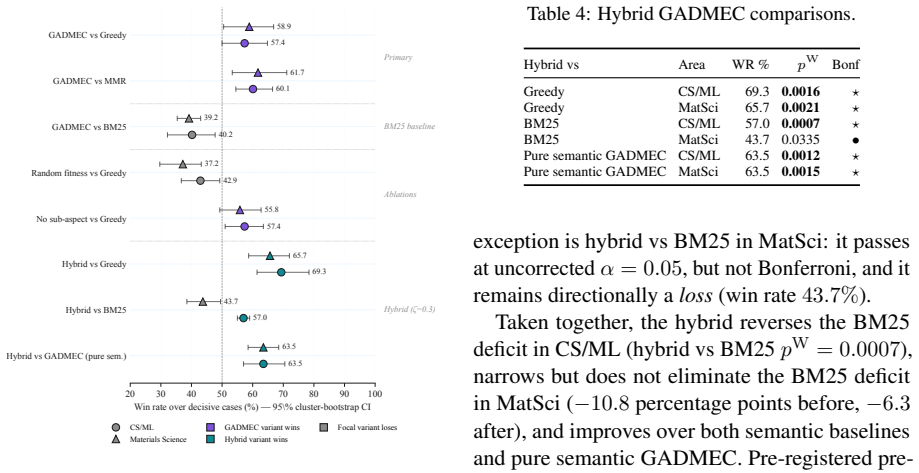
The authors claim that adopting the fixed-budget, cluster-aware standard changes the empirical story in multi-hop RAG: a binomial test makes all four semantic-baseline comparisons look significant, but cluster-aware inference leaves only one Bonferroni-significant result. Under the same controls, BM25 beats pure semantic GADMEC while a lexical-semantic hybrid recovers performance in CS/ML and narrows the gap in Materials Science.
What carries the argument
The cluster-aware inference protocol (with exact cluster sign-flip check when feasible) applied to fixed top-100 pools, evidence budgets, answer caps, generators, and prompts, which isolates retrieval quality from confounds in LLM-as-a-judge scoring.
If this is right
- Cluster-aware inference with Bonferroni correction reduces the number of significant semantic-baseline comparisons from four to one.
- BM25 outperforms pure semantic GADMEC under identical evidence budgets.
- A lexical-semantic hybrid recovers performance in CS/ML and narrows the Materials Science gap.
- The standard requires pre-registered hypotheses, second-judge replication, and cluster sign-flip checks when feasible.
Where Pith is reading between the lines
- Existing multi-hop RAG papers that rely on unclustered binomial tests may have overstated retrieval improvements.
- The fixed-budget approach could be extended to other LLM-judge tasks such as summarization or open-ended question answering to check for similar overstatement.
- Requiring cluster-aware tests might slow the rate of reported progress but raise the reliability of claims about new evidence selectors.
Load-bearing premise
Fixing the top-100 candidate pool, evidence budget, answer cap, generator, and prompt is sufficient to isolate retrieval quality from other confounds in LLM-as-a-judge scoring.
What would settle it
Running the same 400-question comparisons with the proposed fixed parameters but finding that cluster-aware inference still yields more than one Bonferroni-significant result, or that different fixed budgets produce a different pattern of significance, would falsify the claim that the protocol changes the empirical story.
Figures
read the original abstract
Retrieval-augmented generation (RAG) systems are often compared by asking a large language model (LLM) judge which answer is better. For multi-hop RAG, this has become a measurement problem as much as a modeling problem: the same score can reflect retrieval quality, answer length, lexical overlap, or a statistical test that ignores clustered data. We ask what happens when these choices are made explicit. We propose a minimum measurement standard for LLM-as-a-judge comparisons in RAG. The standard fixes the top-100 candidate pool, evidence budget, answer cap, generator, and prompt; it also requires pre-registered hypotheses, cluster-aware inference, an exact cluster sign-flip check when feasible, and second-judge replication. Clustered benchmarks can overstate progress; the field should adopt this standard. We stress-test it with Genetic Algorithm Decoder for Multi-hop Evidence Composition (GADMEC), an evolutionary evidence selector, on 400 multi-hop questions in computer science/machine learning (CS/ML) and Materials Science. The protocol changes the empirical story. A binomial test makes all four semantic-baseline comparisons look significant; cluster-aware inference leaves only one Bonferroni-significant result. BM25 beats pure semantic GADMEC under the same budget, while a lexical-semantic hybrid recovers in CS/ML and narrows the Materials Science gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a minimum measurement standard for LLM-as-a-judge evaluation in multi-hop RAG. The standard fixes the top-100 candidate pool, evidence budget, answer cap, generator, and prompt; it also requires pre-registered hypotheses, cluster-aware inference, an exact cluster sign-flip check, and second-judge replication. In a stress test with the GADMEC evolutionary evidence selector on 400 multi-hop questions (CS/ML and Materials Science domains), the protocol changes the empirical story: a binomial test finds all four semantic-baseline comparisons significant, while cluster-aware inference with Bonferroni correction leaves only one significant result. BM25 outperforms pure semantic GADMEC under the fixed budget, while a lexical-semantic hybrid recovers performance in CS/ML and narrows the gap in Materials Science.
Significance. If the central empirical result holds under the proposed controls, the work is significant because it supplies a concrete, replicable protocol that directly addresses overstatement of progress due to clustered data and unaccounted confounds in LLM-as-a-judge scoring. The stress-test demonstration that statistical correction alters which baselines appear superior provides a falsifiable illustration of the measurement problem. Adoption of the fixed-pool/budget/generator/prompt plus cluster-aware requirements would improve comparability across RAG papers.
major comments (2)
- [Abstract] Abstract, paragraph 2: the claim that fixing the top-100 pool, evidence budget, generator, and prompt isolates retrieval quality from residual LLM-judge confounds rests on an untested assumption; no ablation is reported that holds retrieval method constant while varying evidence presentation order, concatenation format, or surface-form cues to test whether judge rankings remain stable.
- [Abstract] Abstract, final paragraph: the reported shift from four binomial-significant results to one Bonferroni-significant result under cluster-aware inference is load-bearing for the central claim, yet the manuscript provides no table of raw counts, exact cluster definitions, or per-cluster sign-flip statistics, making it impossible to verify that the change is not driven by post-hoc cluster construction or data exclusions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 2: the claim that fixing the top-100 pool, evidence budget, generator, and prompt isolates retrieval quality from residual LLM-judge confounds rests on an untested assumption; no ablation is reported that holds retrieval method constant while varying evidence presentation order, concatenation format, or surface-form cues to test whether judge rankings remain stable.
Authors: We agree that the manuscript presents the fixed controls as isolating retrieval quality but does not report an ablation that holds the retrieval method fixed while varying evidence order, concatenation, or surface cues. The claim therefore rests on an assumption rather than direct evidence from the current experiments. In the revised manuscript we will revise the abstract language to describe the fixed pool/budget/generator/prompt as a methodological control intended to reduce (rather than fully eliminate) residual confounds, and we will add an explicit limitations paragraph noting the absence of this ablation and suggesting it as a direction for follow-up validation. revision: yes
-
Referee: [Abstract] Abstract, final paragraph: the reported shift from four binomial-significant results to one Bonferroni-significant result under cluster-aware inference is load-bearing for the central claim, yet the manuscript provides no table of raw counts, exact cluster definitions, or per-cluster sign-flip statistics, making it impossible to verify that the change is not driven by post-hoc cluster construction or data exclusions.
Authors: The referee correctly identifies that the manuscript omits the raw data and cluster-level statistics needed to verify the reported change in significance. The revised version will add a supplementary table (or appendix section) containing: (1) raw win/loss counts for each baseline comparison, (2) the exact pre-registered cluster definitions (by domain and question source), and (3) the per-cluster sign-flip counts and test results. We will also state in the methods that clusters were defined prior to any significance testing. revision: yes
Circularity Check
No circularity: empirical protocol with no derivations or fitted predictions
full rationale
The paper proposes a fixed-budget measurement standard and reports results from an empirical stress test on 400 multi-hop questions using GADMEC. No equations, parameter fittings, or first-principles derivations appear in the abstract or described protocol; claims rest on direct experimental comparisons (binomial vs. cluster-aware inference) under explicitly fixed conditions. These are externally verifiable and do not reduce to self-definition or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clustered data in RAG benchmarks requires cluster-aware statistical inference to avoid overstated significance
Reference graph
Works this paper leans on
-
[1]
Review of Economics and Statistics, 90(3):414–427
Bootstrap-based improvements for in- ference with clustered errors. Review of Economics and Statistics, 90(3):414–427. doi:10.1162/rest. 90.3.414. Jaime Carbonell and Jade Goldstein
-
[2]
The use of MMR, diversity-based reranking for reordering doc- uments and producing summaries. In Proceedings of the 21st Annual International ACM SIGIR Confer- ence on Research and Development in Information Retrieval, pages 335–336. doi:10.1145/290941. 291025. Sukmin Cho, Soyeong Jeong, Jeongyeon Seo, Taeho Hwang, and Jong C. Park
-
[3]
In Findings of the Association for 8 Computational Linguistics: EMNLP 2024
Typos that broke the RAG’s back: Genetic attack on RAG pipeline by simulating documents in the wild via low-level perturbations. In Findings of the Association for 8 Computational Linguistics: EMNLP 2024 . doi:10. 18653/v1/2024.findings-emnlp.161. Yann Dubois, Balázs Galambosi, Percy Liang, and Tat- sunori B. Hashimoto
2024
-
[4]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Length-controlled Al- pacaEval: A simple way to debias automatic eval- uators. In Proceedings of the Conference on Lan- guage Modeling (COLM) . doi:10.48550/arXiv. 2404.04475. Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[5]
RAGAs: Automated eval- uation of retrieval augmented generation. In Pro- ceedings of the 18th Conference of the European Chapter of the Association for Computational Lin- guistics: System Demonstrations , pages 150–158. Association for Computational Linguistics. doi: 10.18653/v1/2024.eacl-demo.16. José Fernando Gonçalves and Mauricio G. C. Re- sende
-
[6]
F oundations and Trends in Machine Learning , 5(2–3):123–286
Determinantal point processes for machine learning. F oundations and Trends in Machine Learning , 5(2–3):123–286. doi:10.1561/2200000044. J. Richard Landis and Gary G. Koch
-
[7]
In Findings of the Association for Computational Lin- guistics: EMNLP 2025
GRADE: Generating multi-hop QA and fine- gRAined difficulty matrix for RAG evaluation. In Findings of the Association for Computational Lin- guistics: EMNLP 2025 . doi:10.18653/v1/2025. findings-emnlp.236. Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhat- tacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai ...
-
[8]
From gen- eration to judgment: Opportunities and challenges of LLM-as-a-judge. In Proceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP) . doi:10.18653/v1/ 2025.emnlp-main.138. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Z...
-
[9]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
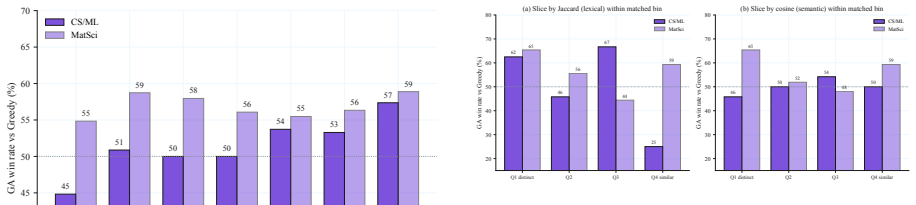
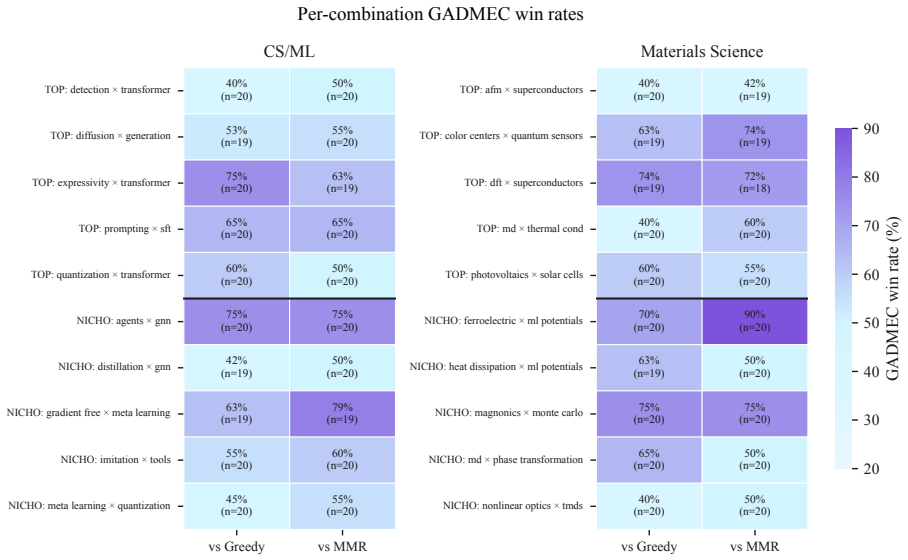
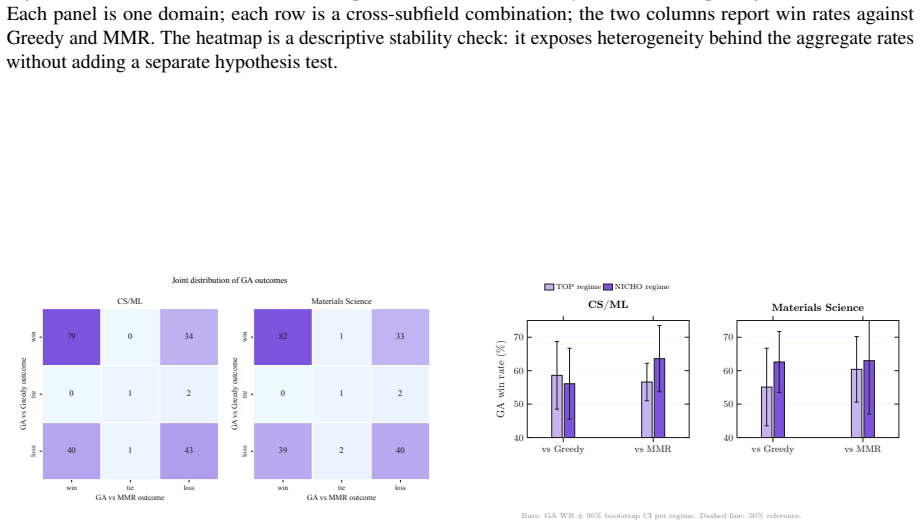
doi:10.48550/ arXiv.2306.05685. 9 A Supplementary Diagnostics The appendix is descriptive. It does not introduce new primary claims; instead, it makes the aggregate results easier to audit. Figure 5, Figure 6, and Fig- ure 7 answer three diagnostic questions: whether the aggregate win rates are driven by a few combi- nations, whether wins against Greedy a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.