Density-aware Sample-specific Attack
Pith reviewed 2026-06-29 13:40 UTC · model grok-4.3
The pith
Placing backdoor triggers in low-density regions optimizes both success rate and resistance to post-training defenses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
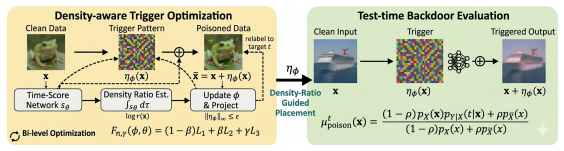
Both attack success and clean-accuracy preservation are simultaneously optimized when triggered samples are steered into low-density regions of the clean data distribution, a distributional condition that controls all moments of the poisoned distribution at once rather than a handful of input-space summary statistics. We introduce a bilevel optimization framework that estimates density ratios via conditional time-score matching and optimizes a mixture-model objective to place triggered samples in these sparse regions.
What carries the argument
bilevel optimization framework that estimates density ratios via conditional time-score matching and optimizes a mixture-model objective to place triggered samples in sparse regions
If this is right
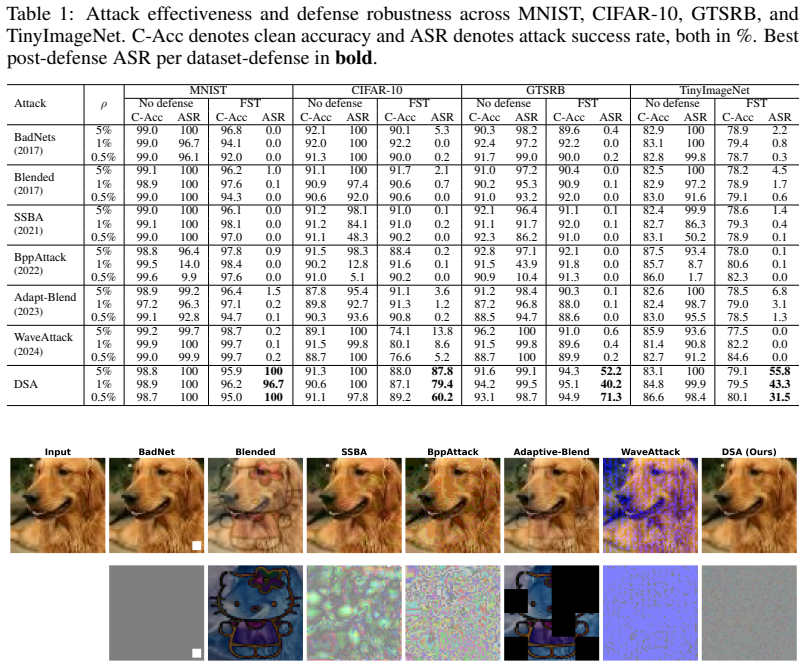
- The method achieves above 99% attack success rate before defense.
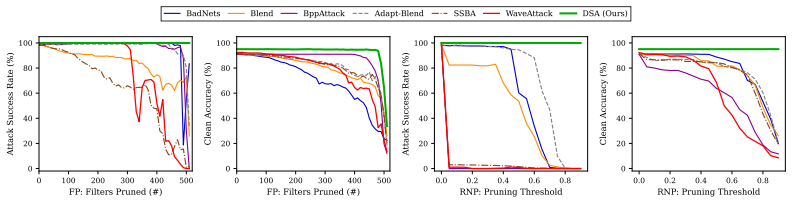
- It retains 50--85 percentage points higher post-defense ASR than the strongest baselines under fine-tuning defenses.
- The attack exhibits complete immunity to neuron-pruning defenses, with zero neurons identified for removal across all pruning thresholds.
- These results indicate that current defenses fail when triggers lie outside the support of the clean distribution.
Where Pith is reading between the lines
- Defenses operating only on the support of the clean distribution are likely to be bypassed by such density-aware attacks.
- The approach could be extended to other types of data poisoning by targeting low-density areas.
- Testing the method on additional model architectures or non-image domains would reveal its broader applicability.
Load-bearing premise
The victim's training process follows a Bayes-optimal model, which is used to derive the criteria for optimal trigger construction.
What would settle it
Finding that an attack with triggers not steered to low-density regions achieves similar post-defense performance on the same datasets would falsify the central claim.
Figures

read the original abstract
Despite recent progress in backdoor attacks, existing methods remain susceptible to post-training defenses that erase the backdoor through fine-tuning or pruning. We revisit the core objectives of backdoor attacks and derive principled criteria characterizing optimal sample-specific trigger construction under a Bayes-optimal model of the victim's training. Our analysis reveals that both attack success and clean-accuracy preservation are simultaneously optimized when triggered samples are steered into low-density regions of the clean data distribution, a distributional condition that controls all moments of the poisoned distribution at once rather than a handful of input-space summary statistics. We introduce a bilevel optimization framework that estimates density ratios via conditional time-score matching and optimizes a mixture-model objective to place triggered samples in these sparse regions. Extensive evaluations on MNIST, CIFAR-10, GTSRB, and TinyImageNet demonstrate that our method achieves above 99\% attack success rate before defense and retains 50--85 percentage points higher post-defense ASR than the strongest baselines under fine-tuning defenses. Against neuron-pruning defenses, the method exhibits complete immunity, with zero neurons identified for removal across all pruning thresholds. These results expose a fundamental gap in current defense paradigms and underscore the need for defenses that operate beyond the support of the clean distribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives principled criteria for optimal sample-specific backdoor triggers under a Bayes-optimal victim model, showing that steering triggers into low-density regions of the clean distribution simultaneously maximizes attack success rate (ASR) and preserves clean accuracy by controlling all moments of the poisoned distribution. It introduces a bilevel optimization that estimates density ratios via conditional time-score matching and optimizes a mixture-model objective, reporting >99% pre-defense ASR and 50-85pp higher post-fine-tuning ASR than baselines on MNIST/CIFAR-10/GTSRB/TinyImageNet, plus complete immunity to neuron pruning.
Significance. If the transfer from the Bayes-optimal derivation to practical SGD training holds and the density-ratio estimates are shown independent of the reported ASR numbers, the result would identify a structural limitation in current post-training defenses that rely on support or moment-matching assumptions, motivating new defense paradigms that explicitly address low-density poisoning.
major comments (3)
- [Abstract, §3] Abstract (first paragraph) and §3 (Bayes-optimal derivation): the optimality criteria are obtained by analyzing the effect of low-density placement on a Bayes-optimal classifier; no section demonstrates that the same distributional condition remains optimal under the non-convex SGD dynamics used in the MNIST/CIFAR experiments, leaving the central claim dependent on an unverified modeling assumption.
- [§4, experimental results] §4 (bilevel optimization) and experimental section: the density-ratio estimator is learned via conditional time-score matching and appears inside the mixture-model objective, yet no ablation or sensitivity analysis shows that the final ASR numbers are independent of the estimator's hyperparameters or training data; the reported 99% ASR and defense immunity therefore rest on unquantified estimation error.
- [Table 2, Figure 4] Table 2 / Figure 4 (post-defense ASR): the method claims 50-85pp gains over baselines under fine-tuning, but the abstract and results provide neither error bars across random seeds nor verification that the Bayes-optimal derivation was checked on the actual trained models, so the cross-method comparison cannot be assessed for statistical reliability.
minor comments (2)
- [§4.1] Notation for the conditional time-score matching loss is introduced without an explicit equation reference in the main text; adding the precise objective (currently only in appendix) would improve readability.
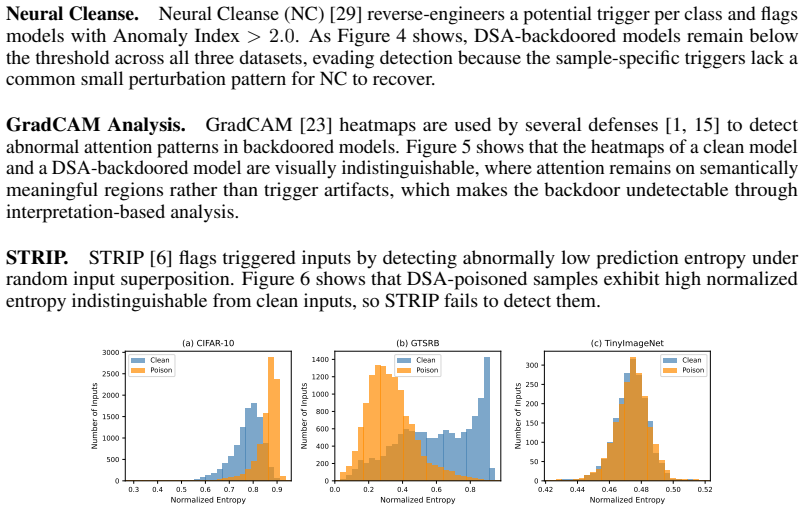
- [experimental results] The claim of 'complete immunity' to neuron pruning (zero neurons identified) should be accompanied by the exact pruning thresholds and identification criterion used, rather than a single summary sentence.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major comments, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract (first paragraph) and §3 (Bayes-optimal derivation): the optimality criteria are obtained by analyzing the effect of low-density placement on a Bayes-optimal classifier; no section demonstrates that the same distributional condition remains optimal under the non-convex SGD dynamics used in the MNIST/CIFAR experiments, leaving the central claim dependent on an unverified modeling assumption.
Authors: The Bayes-optimal derivation is presented as a theoretical motivation that identifies low-density placement as simultaneously controlling attack success and all moments of the poisoned distribution. We do not claim a formal optimality guarantee under SGD; the manuscript relies on this condition as a guiding principle whose practical utility is validated empirically. In revision we will add an explicit discussion paragraph in §3 clarifying the modeling assumption and noting that transfer to SGD-trained models is supported by the reported results rather than proven. revision: partial
-
Referee: [§4, experimental results] §4 (bilevel optimization) and experimental section: the density-ratio estimator is learned via conditional time-score matching and appears inside the mixture-model objective, yet no ablation or sensitivity analysis shows that the final ASR numbers are independent of the estimator's hyperparameters or training data; the reported 99% ASR and defense immunity therefore rest on unquantified estimation error.
Authors: We agree that additional sensitivity analysis would increase confidence in the results. In the revised version we will add an ablation subsection reporting ASR under varied hyperparameters of the conditional time-score matching estimator and under different subsets of training data used for density-ratio estimation. revision: yes
-
Referee: [Table 2, Figure 4] Table 2 / Figure 4 (post-defense ASR): the method claims 50-85pp gains over baselines under fine-tuning, but the abstract and results provide neither error bars across random seeds nor verification that the Bayes-optimal derivation was checked on the actual trained models, so the cross-method comparison cannot be assessed for statistical reliability.
Authors: We acknowledge the lack of error bars. In revision we will rerun all experiments with at least five random seeds and report means and standard deviations in Table 2 and Figure 4. Verification that the Bayes-optimal condition holds exactly on the trained (non-Bayes-optimal) models was not performed; we will add a short paragraph in the discussion section explaining that such verification lies outside the current scope and is left for future work. revision: partial
Circularity Check
No circularity: derivation rests on explicit external Bayes-optimal assumption
full rationale
The paper states its core criteria are derived under a Bayes-optimal model of the victim's training (abstract). This is presented as an external modeling choice used to analyze the effect of low-density placement on the poisoned distribution. No equations or steps in the provided text reduce the claimed optimality condition to a fitted parameter, self-citation, or input by construction. The subsequent bilevel optimization (density-ratio estimation via time-score matching) is a separate implementation step whose outputs are not shown to be tautological with the final ASR metrics. The derivation chain is therefore self-contained; the transferability concern to SGD training is a question of assumption validity, not circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- density ratio estimator parameters
axioms (1)
- domain assumption Victim's training follows a Bayes-optimal model
Reference graph
Works this paper leans on
-
[1]
H. Chen, C. Fu, J. Zhao, and F. Koushanfar. DeepInspect: A black-box trojan detection and mitigation framework for deep neural networks. InIJCAI, volume 2, page 8, 2019
2019
-
[2]
X. Chen, C. Liu, B. Li, K. Lu, and D. Song. Targeted backdoor attacks on deep learning systems using data poisoning.arXiv preprint arXiv:1712.05526, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[4]
K. Doan, Y . Lao, W. Zhao, and P. Li. Lira: Learnable, imperceptible and robust backdoor attacks. InProceedings of the IEEE/CVF international conference on computer vision, pages 11966–11976, 2021
2021
-
[5]
Franceschi, P
L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil. Bilevel programming for hyperparameter optimization and meta-learning. InInternational conference on machine learning, pages 1568–1577. PMLR, 2018
2018
-
[6]
Y . Gao, C. Xu, D. Wang, S. Chen, D. C. Ranasinghe, and S. Nepal. STRIP: A defence against trojan attacks on deep neural networks. InProceedings of the 35th annual computer security applications conference, pages 113–125, 2019
2019
-
[7]
T. Gu, B. Dolan-Gavitt, and S. Garg. BadNets: Identifying vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016
2016
-
[9]
Jiang, H
W. Jiang, H. Li, G. Xu, and T. Zhang. Color backdoor: A robust poisoning attack in color space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8133–8142, 2023
2023
-
[10]
Krizhevsky, G
A. Krizhevsky, G. Hinton, et al. Learning multiple layers of features from tiny images, 2009
2009
-
[11]
LeCun, L
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[12]
Y . Li, Y . Li, B. Wu, L. Li, R. He, and S. Lyu. Invisible backdoor attack with sample-specific triggers. InProceedings of the IEEE/CVF international conference on computer vision, pages 16463–16472, 2021
2021
-
[13]
Y . Li, X. Lyu, X. Ma, N. Koren, L. Lyu, B. Li, and Y .-G. Jiang. Reconstructive neuron pruning for backdoor defense. InInternational Conference on Machine Learning, pages 19837–19854. PMLR, 2023
2023
-
[14]
K. Liu, B. Dolan-Gavitt, and S. Garg. Fine-pruning: Defending against backdooring attacks on deep neural networks. InInternational symposium on research in attacks, intrusions, and defenses, pages 273–294. Springer, 2018
2018
-
[15]
Liu, W.-C
Y . Liu, W.-C. Lee, G. Tao, S. Ma, Y . Aafer, and X. Zhang. Abs: Scanning neural networks for back-doors by artificial brain stimulation. InProceedings of the 2019 ACM SIGSAC conference on computer and communications security, pages 1265–1282, 2019
2019
-
[16]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 10
2021
-
[17]
Lorraine, P
J. Lorraine, P. Vicol, and D. Duvenaud. Optimizing millions of hyperparameters by implicit differentiation. InInternational conference on artificial intelligence and statistics, pages 1540–1552. PMLR, 2020
2020
-
[18]
R. Min, Z. Qin, L. Shen, and M. Cheng. Towards stable backdoor purification through feature shift tuning.Advances in Neural Information Processing Systems, 36:75286–75306, 2023
2023
-
[19]
A. Nguyen and A. Tran. Wanet–imperceptible warping-based backdoor attack.arXiv preprint arXiv:2102.10369, 2021
-
[20]
T. A. Nguyen and A. Tran. Input-aware dynamic backdoor attack.Advances in Neural Information Processing Systems, 33:3454–3464, 2020
2020
-
[21]
B. A. Pearlmutter. Fast exact multiplication by the hessian.Neural computation, 6(1):147–160, 1994
1994
-
[22]
X. Qi, T. Xie, Y . Li, S. Mahloujifar, and P. Mittal. Revisiting the assumption of latent separability for backdoor defenses. InThe eleventh international conference on learning representations, 2023
2023
-
[23]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-CAM: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE international conference on computer vision, pages 618–626, 2017
2017
-
[24]
J. R. Shewchuk et al. An introduction to the conjugate gradient method without the agonizing pain, 1994
1994
-
[25]
Stallkamp, M
J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel. The german traffic sign recognition benchmark: a multi-class classification competition. InThe 2011 international joint conference on neural networks, pages 1453–1460. IEEE, 2011
2011
-
[26]
B. Tran, J. Li, and A. Madry. Spectral signatures in backdoor attacks.Advances in neural information processing systems, 31, 2018
2018
- [27]
-
[28]
P. Vincent. A connection between score matching and denoising autoencoders.Neural compu- tation, 23(7):1661–1674, 2011
2011
-
[29]
B. Wang, Y . Yao, S. Shan, H. Li, B. Viswanath, H. Zheng, and B. Y . Zhao. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In2019 IEEE symposium on security and privacy (SP), pages 707–723. IEEE, 2019
2019
-
[30]
T. Wang, Y . Yao, F. Xu, S. An, H. Tong, and T. Wang. An invisible black-box backdoor attack through frequency domain. InEuropean Conference on Computer Vision, pages 396–413. Springer, 2022
2022
-
[31]
Z. Wang, J. Zhai, and S. Ma. BppAttack: Stealthy and efficient trojan attacks against deep neural networks via image quantization and contrastive adversarial learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15074–15084, 2022
2022
-
[32]
Wu and Y
D. Wu and Y . Wang. Adversarial neuron pruning purifies backdoored deep models. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 16913–16925. Curran Associates, Inc., 2021
2021
-
[33]
J. Xia, Z. Yue, Y . Zhou, Z. Ling, Y . Shi, X. Wei, and M. Chen. WaveAttack: Asymmetric frequency obfuscation-based backdoor attacks against deep neural networks.Advances in Neural Information Processing Systems, 37:43549–43570, 2024
2024
-
[34]
Y . Yang, C. Jia, D. Yan, M. Hu, T. Li, X. Xie, X. Wei, and M. Chen. SampDetox: Black-box backdoor defense via perturbation-based sample detoxification.Advances in Neural Information Processing Systems, 37:121236–121264, 2024. 11
2024
-
[35]
H. Yu, A. Klami, A. Hyvärinen, A. Korba, and O. Chehab. Density ratio estimation with conditional probability paths. InForty-second International Conference on Machine Learning, 2025
2025
- [36]
-
[37]
M. Zhu, S. Wei, L. Shen, Y . Fan, and B. Wu. Enhancing fine-tuning based backdoor defense with sharpness-aware minimization. InProceedings of the IEEE/CVF international conference on computer vision, pages 4466–4477, 2023. 12 A Implementation Details A.1 Our Algorithm Algorithm 1 presents the bi-level optimization pipeline of our trigger generating proced...
2023
-
[38]
to just 12.87% (Level 5), and FST similarly reduces ASR from 87.12% to 43.92%. This suggests that when the trigger optimization relies on a weaker clean classifier, the resulting backdoor becomes more entangled with limited feature representations, hence is easier to disrupt through fine-tuning. In contrast, FT-init defense remains ineffective across all ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.