ReSAE: Residualized Sparse Autoencoders for Multi-Layer Transformer Interventions
Pith reviewed 2026-06-29 14:50 UTC · model grok-4.3
The pith
ReSAEs train sparse autoencoders on layer residuals after removing linearly predictable cross-layer information to enable better multi-layer interventions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
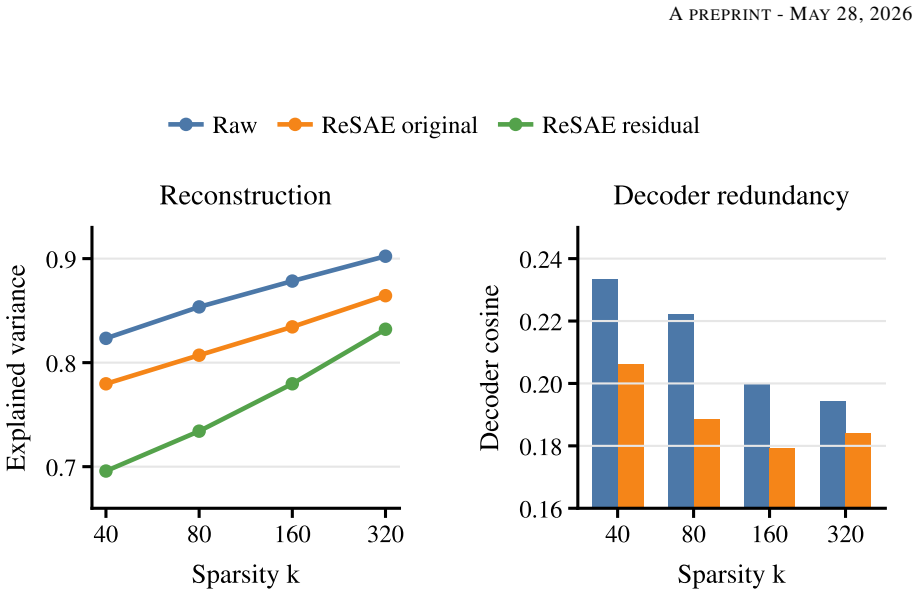
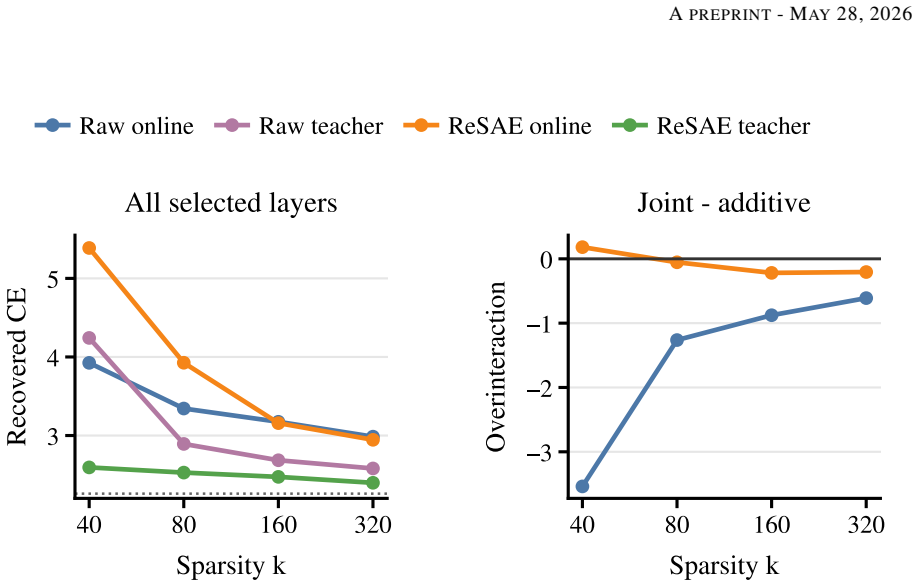
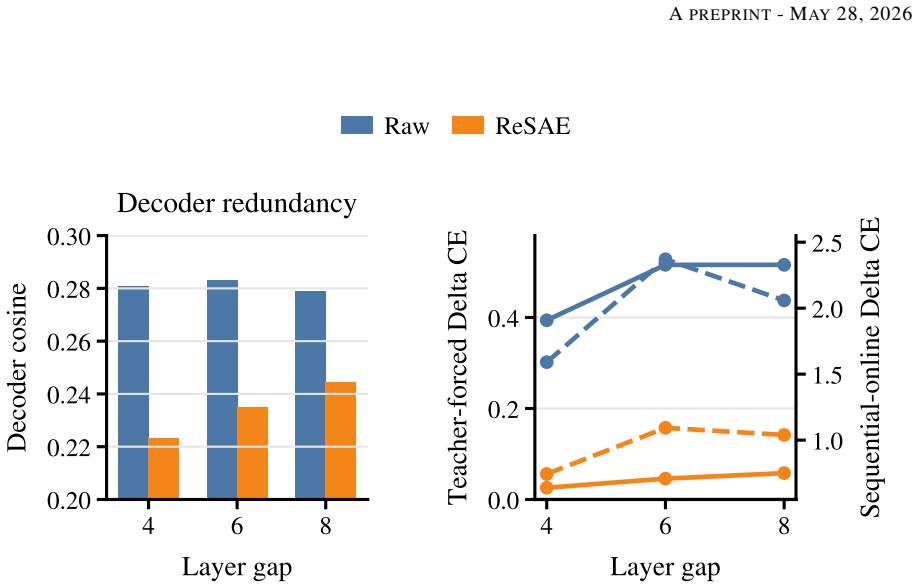
The central discovery is that training SAEs on residuals after affine residualization between layers produces dictionaries that, when used for multi-layer interventions, recover more of the transformer's original cross-entropy loss than unresidualized SAEs, even though they explain less activation variance. This holds on Pythia-1.4B and Gemma-2-9B models, with gains clearest under teacher-forcing and adequate sparsity.
What carries the argument
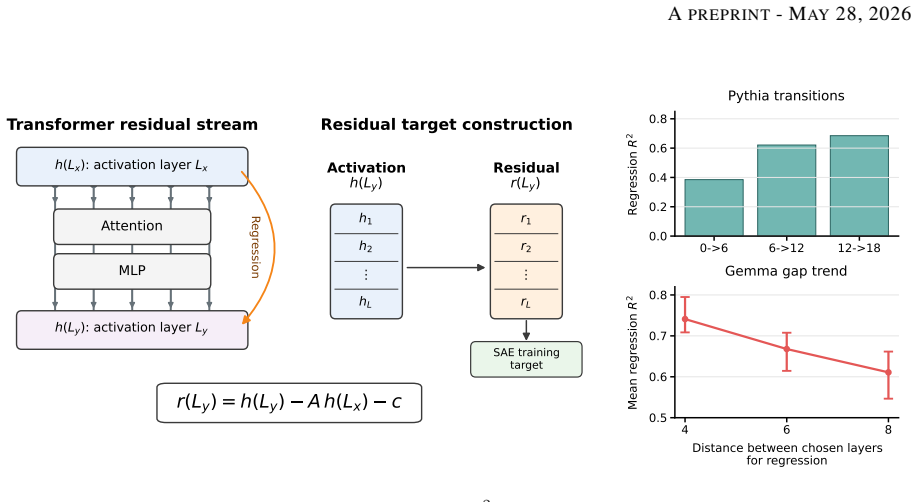
The ReSAE mechanism, consisting of an affine map fitted between selected layers whose output is subtracted to produce the residual input to the SAE, with the SAE output added back through the inverse affine chain.
Load-bearing premise
The linearly predictable carried-forward information between layers can be removed without losing features essential to the model's downstream behavior.
What would settle it
A controlled test where multi-layer ReSAE interventions recover less cross-entropy than standard SAE interventions on a specific task would falsify the claim of superior preservation of computation-relevant components.
Figures
read the original abstract
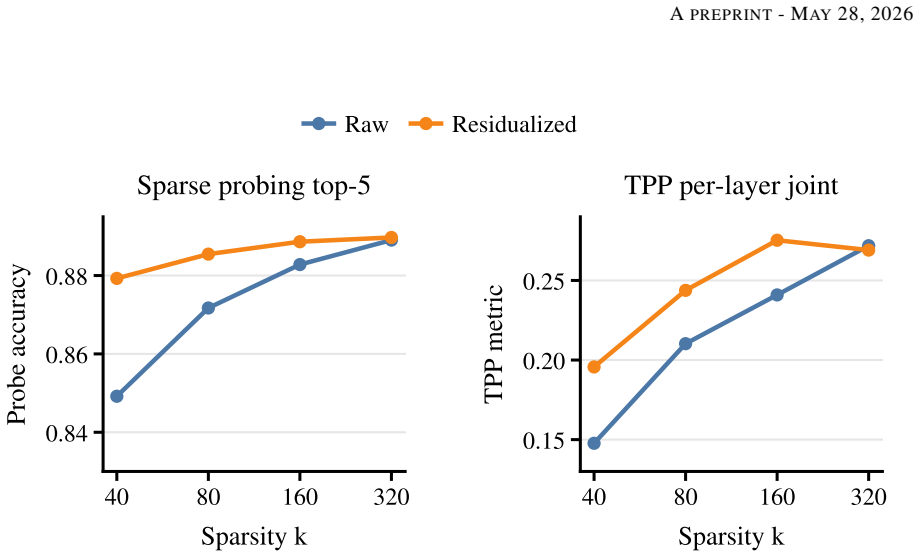
Sparse autoencoders are usually trained one layer at a time, even though transformer residual stream activations are strongly coupled across depth. This creates a practical problem for multi-layer interventions: different layerwise dictionaries can spend capacity representing the same carried-forward information, and replacing several layers at once can produce interactions that are not predicted by single-layer behavior. We introduce Residualized Sparse Autoencoders (ReSAEs), which fit an affine map between selected layers and train each later-layer SAE on the unexplained residual rather than on the full activation. Reconstructions are mapped back into the original activation space through the fitted affine chain, so ReSAEs can be evaluated with the same intervention protocols as ordinary SAEs. On Pythia-1.4B and Gemma-2-9B, residualization reduces decoder redundancy and improves sparse probing and targeted perturbation in most tested settings. Despite reconstructing less of the raw activation variance, ReSAEs recover more transformer cross entropy under multi-layer replacement. This gain is clearest under teacher-forcing and at sufficient sparsity online, indicating that ReSAEs preserve the components of the activation most relevant to the model's downstream computation. These results suggest that removing linearly predictable cross-layer structure is a useful default for multi-layer SAE interventions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Residualized Sparse Autoencoders (ReSAEs), which fit an affine map between selected transformer layers and train each subsequent SAE on the residual activation after subtracting the carried-forward linear component. Reconstructions are mapped back via the affine chain for compatibility with standard intervention protocols. On Pythia-1.4B and Gemma-2-9B, the method is reported to reduce decoder redundancy, improve sparse probing and targeted perturbation in most settings, and recover more model cross-entropy under multi-layer replacement despite reconstructing less raw activation variance; the gain is stated to be clearest at sufficient sparsity and under teacher-forcing.
Significance. If the central empirical claim holds after addressing the control issue, residualization would provide a useful default preprocessing step for multi-layer SAE interventions, directly tackling the problem of redundant capacity spent on cross-layer carry-forward. The evaluation on two distinct model families supplies a reasonable starting point for the observation.
major comments (2)
- [Abstract / §4] Abstract and §4 (results on multi-layer replacement): the claim that ReSAEs 'preserve the components of the activation most relevant to the model's downstream computation' because they recover more CE despite lower variance reconstruction is load-bearing for the headline result. This interpretation requires evidence that the removed affine component does not itself carry functionally relevant features. No control experiment is described that intervenes by replacing activations with the affine prediction alone (or measures CE degradation attributable to the linear part), leaving the functional importance of the residual under-determined.
- [§3] §3 (method) and evaluation protocol: the affine map coefficients are fit on the same data used for SAE training and downstream evaluation. While this is not a derivation that reduces to the fit by construction, the absence of a held-out layer or model for the affine fit introduces a moderate risk that reported gains partly reflect reduced training variance or back-mapping artifacts rather than isolation of computation-relevant structure. A cross-model or cross-dataset validation of the affine map would strengthen the result.
minor comments (2)
- [Abstract] The abstract states gains occur 'in most tested settings' and 'at sufficient sparsity'; the main text should include a table or figure that explicitly lists all settings tested and the fraction in which improvement was observed, to avoid selective reporting.
- [§3] Notation for the affine map (e.g., how the chain of maps is composed for multi-layer replacement) should be defined once in §3 with a clear equation, then used consistently in the intervention description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, providing clarifications and committing to revisions where the concerns identify gaps in the current evidence.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (results on multi-layer replacement): the claim that ReSAEs 'preserve the components of the activation most relevant to the model's downstream computation' because they recover more CE despite lower variance reconstruction is load-bearing for the headline result. This interpretation requires evidence that the removed affine component does not itself carry functionally relevant features. No control experiment is described that intervenes by replacing activations with the affine prediction alone (or measures CE degradation attributable to the linear part), leaving the functional importance of the residual under-determined.
Authors: We agree that the headline interpretation would be strengthened by a direct control that replaces activations using only the fitted affine prediction and measures the resulting CE change. Our existing results show that ReSAEs (which discard the affine component) recover more CE than standard SAEs (which retain it) under multi-layer replacement, providing indirect evidence that the residual carries more intervention-relevant structure. However, this does not fully rule out functional content in the affine part. We will add the suggested control experiment (affine-only replacement) to §4 in the revised manuscript. revision: yes
-
Referee: [§3] §3 (method) and evaluation protocol: the affine map coefficients are fit on the same data used for SAE training and downstream evaluation. While this is not a derivation that reduces to the fit by construction, the absence of a held-out layer or model for the affine fit introduces a moderate risk that reported gains partly reflect reduced training variance or back-mapping artifacts rather than isolation of computation-relevant structure. A cross-model or cross-dataset validation of the affine map would strengthen the result.
Authors: The affine map is a low-parameter linear fit whose purpose is to remove cross-layer linear dependence before SAE training; the subsequent SAE optimization and all reported metrics (probing, perturbation, CE) are performed on the residual. While we acknowledge that fitting and evaluating on the same data introduces a risk of optimistic bias, the consistency of gains across two architecturally distinct models (Pythia-1.4B and Gemma-2-9B) and multiple tasks reduces the likelihood that results are artifacts of a single data split. We will add a brief discussion of this limitation to §3 and include a cross-dataset check (holding out a separate corpus for the affine fit) in the revision. revision: partial
Circularity Check
No significant circularity; empirical method with independent evaluation.
full rationale
The paper defines ReSAE as fitting an affine map between layers and training SAEs on the residual activation, then maps reconstructions back via the chain. Central claims are empirical: reduced decoder redundancy and higher cross-entropy recovery under multi-layer interventions on Pythia-1.4B and Gemma-2-9B, despite lower raw variance reconstruction. These are measured outcomes on held-out model behavior, not quantities forced by the affine fit itself. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the method. No step reduces a claimed result to the fitted parameters by construction; the evaluation uses standard intervention protocols on the same models but reports observable differences in probing and perturbation metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- affine map coefficients
axioms (1)
- domain assumption Transformer residual stream activations are strongly coupled across depth
Reference graph
Works this paper leans on
-
[1]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
NeurIPS 2025 oral. Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Zhengfu He, Wentao Shu, Xuyang Ge, Lingjie Chen, Junxuan Wang, Yunhua Zhou, Frances Liu, Qipeng Guo, Xuanjing Huang, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. Llama Scope: Extracting millions of features from Llama-3.1-8b with sparse autoencoders.arXiv preprint arXiv:2410.20526,
-
[4]
Evaluating sparse autoencoders on targeted concept erasure tasks
Adam Karvonen, Can Rager, Samuel Marks, and Neel Nanda. Evaluating sparse autoencoders on targeted concept erasure tasks. arXiv preprint arXiv:2411.18895, 2024a. Adam Karvonen, Benjamin Wright, Can Rager, Rico Angell, Jannik Brinkmann, Logan Smith, Claudio Mayrink Verdun, David Bau, and Samuel Marks. Measuring progress in dictionary learning for language ...
-
[5]
Gemma Scope: Open sparse autoencoders everywhere all at once on Gemma
11 APREPRINT- MAY28, 2026 Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma Scope: Open sparse autoencoders everywhere all at once on Gemma
2026
-
[6]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with JumpReLU sparse autoencoders.arXiv preprint arXiv:2407.14435,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophancy in language models.arXiv prepri...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.