TCP-MCP: Landscape-Guided Co-Evolution of Prompts and Communication Topologies for Multi-Agent Systems
Pith reviewed 2026-06-29 12:52 UTC · model grok-4.3
The pith
Jointly evolving prompts and communication topologies provides a route to cost-aware multi-agent system design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
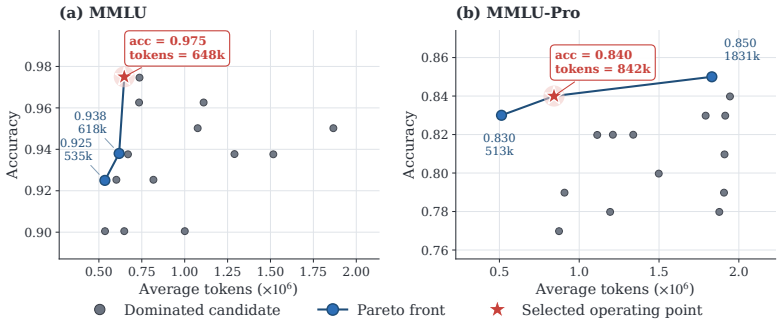
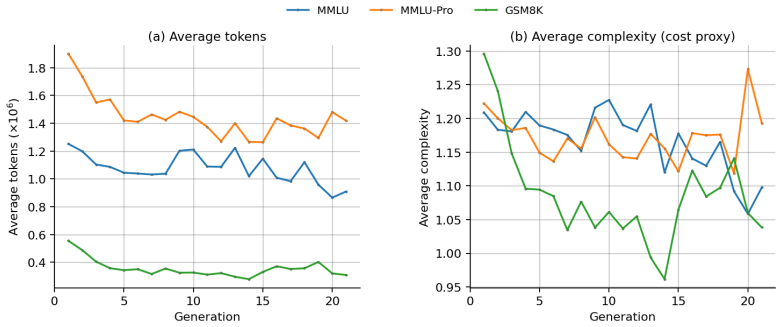
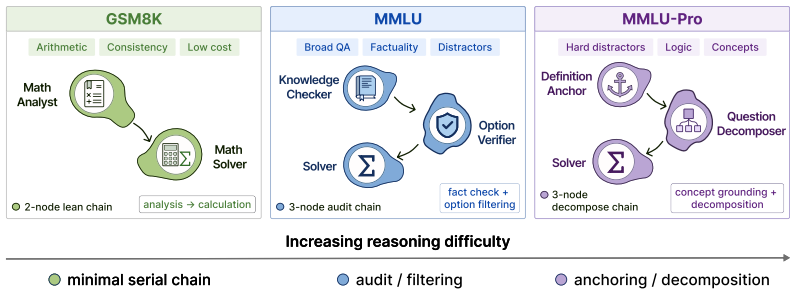
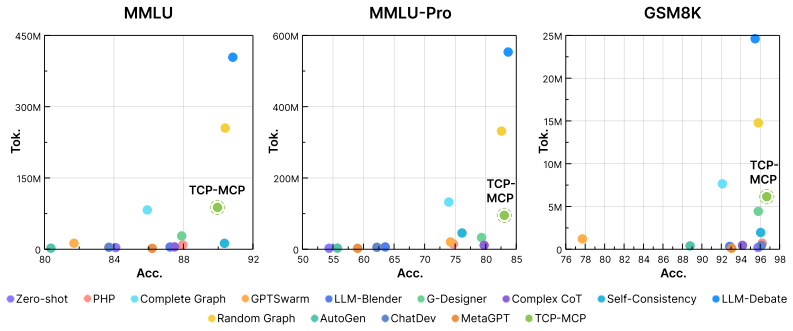
TCP-MCP searches agent prompts and communication topologies as a single genome. It begins with an initialization-time landscape probe to calibrate early behavior, then uses Pareto-front diagnostics to balance three objectives during evolution. The resulting systems reach 82.66 percent accuracy on MMLU-Pro, 89.96 percent on MMLU, and 96.61 percent on GSM8K while using up to 5.69 times fewer tokens than debate-style systems at the reported points and outperforming automated graph-generation baselines.
What carries the argument
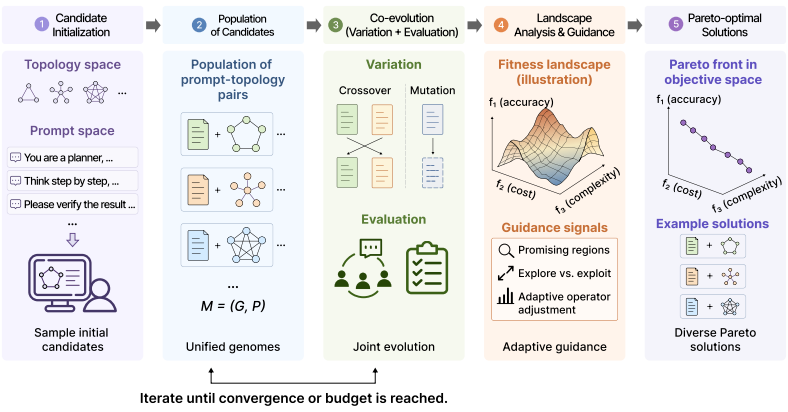
The unified genome that represents both prompts and communication topologies together, evolved with an initialization-time landscape probe and Pareto-front adaptation under performance, cost, and complexity objectives.
If this is right
- Communication topologies become task-specific rather than fixed in advance.
- Token budgets can be treated as an explicit, optimizable objective alongside accuracy.
- Manual tuning of either prompts or graphs in isolation is expected to be suboptimal.
- The same backbone model can support multiple operating points on the performance-cost frontier.
Where Pith is reading between the lines
- The approach suggests that existing single-agent prompt libraries could be extended by jointly searching over small communication graphs.
- If the landscape probe generalizes, similar calibration steps might reduce the number of generations needed in other evolutionary prompt methods.
- The three-objective Pareto framing could be tested on domains where communication cost is measured in latency rather than tokens.
Load-bearing premise
The landscape probe at initialization and the Pareto-front diagnostics guide the search without introducing post-hoc bias or overfitting to the chosen benchmarks.
What would settle it
Apply the same co-evolution procedure to a fourth benchmark outside the three used in the evaluations and check whether the reported accuracy and token-cost advantages are preserved.
Figures
read the original abstract
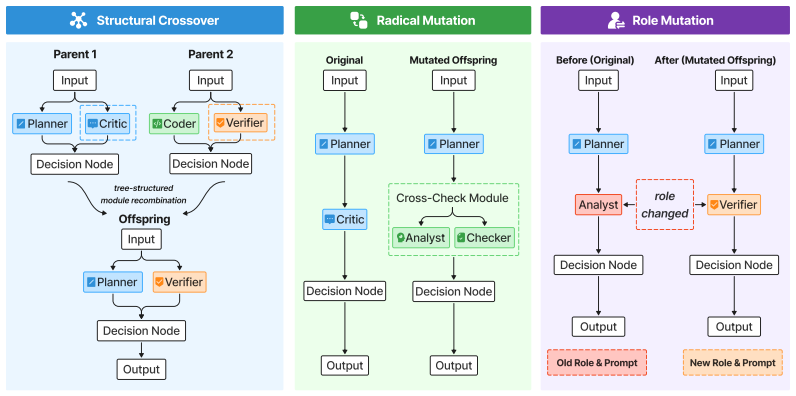
Effective multi-agent systems cannot be designed by selecting prompts or communication graphs in isolation. Agent behavior depends on the information an agent receives, while the usefulness of a communication edge depends on how the receiving agent interprets and uses that information. We propose \textbf{TCP-MCP} (Topology-Coupled Prompting for Multi-Agent Collaborative Problem-Solving), a co-evolution framework that searches agent prompts and communication topologies as a unified genome. TCP-MCP uses an initialization-time landscape probe to calibrate early search behavior, and then relies on Pareto-front diagnostics to adapt exploration under three objectives: task performance, token cost, and structural complexity. Using the same DeepSeek-V3.2 backbone across all methods, TCP-MCP achieves 82.66\%, 89.96\%, and 96.61\% accuracy on MMLU-Pro, MMLU, and GSM8K, respectively. Across the three benchmarks, it consistently outperforms automated graph-generation baselines and achieves competitive accuracy relative to debate-style systems, while using up to 5.69$\times$ fewer tokens than those systems at the reported operating points. These results show that jointly evolving prompts and communication structure provides a practical route to cost-aware and task-adaptive multi-agent system design in controlled evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TCP-MCP, a co-evolution framework that jointly searches agent prompts and communication topologies as a unified genome. It employs an initialization-time landscape probe to calibrate search and Pareto-front diagnostics to balance three objectives (task performance, token cost, structural complexity). Using a fixed DeepSeek-V3.2 backbone, the method reports 82.66% accuracy on MMLU-Pro, 89.96% on MMLU, and 96.61% on GSM8K, outperforming automated graph-generation baselines while using up to 5.69× fewer tokens than debate-style systems at the reported points.
Significance. If the empirical results prove reproducible, the work demonstrates a practical route to cost-aware multi-agent design by treating prompts and topologies as coupled variables rather than independent choices. The consistent backbone across comparisons and the explicit multi-objective Pareto handling are positive features that support fair evaluation of the joint-evolution claim.
major comments (2)
- [Abstract] Abstract: the reported accuracy figures (82.66%, 89.96%, 96.61%) and token-reduction claims are presented without error bars, statistical tests, baseline implementation details, data-exclusion rules, or the full experimental protocol, leaving the central empirical claims without verifiable support from the provided text.
- [Framework] Framework description (implied in §3): the initialization-time landscape probe and Pareto-front diagnostics are positioned as the mechanisms that prevent post-hoc bias and overfitting to the three benchmarks, yet no concrete implementation parameters, pseudocode, or cross-benchmark validation procedure is supplied, so it is impossible to assess whether these components reliably calibrate the search as claimed.
minor comments (1)
- [Abstract] Abstract: the phrase 'up to 5.69× fewer tokens than those systems at the reported operating points' should explicitly name the comparison systems and the exact operating points for each benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in our empirical claims and framework details. We address each point below and will revise the manuscript to improve reproducibility while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported accuracy figures (82.66%, 89.96%, 96.61%) and token-reduction claims are presented without error bars, statistical tests, baseline implementation details, data-exclusion rules, or the full experimental protocol, leaving the central empirical claims without verifiable support from the provided text.
Authors: We agree the abstract is too terse to support the claims on its own. In revision we will expand it to note that accuracies are means over 5 independent runs, with standard deviations and full protocol (including identical DeepSeek-V3.2 backbone, no data exclusion beyond benchmark defaults, and token counting procedure) provided in Section 4 and Appendix B. Baseline implementation details will be cross-referenced to the same section. This addresses the verifiability concern without altering the reported operating points. revision: yes
-
Referee: [Framework] Framework description (implied in §3): the initialization-time landscape probe and Pareto-front diagnostics are positioned as the mechanisms that prevent post-hoc bias and overfitting to the three benchmarks, yet no concrete implementation parameters, pseudocode, or cross-benchmark validation procedure is supplied, so it is impossible to assess whether these components reliably calibrate the search as claimed.
Authors: Section 3 currently gives a high-level description. We will add (i) explicit parameter values (probe size = 50 genomes, Pareto selection threshold = 0.15 hypervolume improvement), (ii) pseudocode for both the landscape probe and the diagnostic update rule, and (iii) a new cross-benchmark validation subsection in Section 4.3 that reports probe calibration statistics and Pareto stability across all three tasks. These additions will allow direct assessment of the claimed bias-prevention behavior. revision: yes
Circularity Check
No significant circularity in claimed derivation chain
full rationale
The paper describes an empirical co-evolution framework (TCP-MCP) that jointly searches prompts and communication topologies using an initialization-time landscape probe and Pareto-front diagnostics under three objectives. Results are presented as direct empirical measurements (accuracies and token reductions on MMLU-Pro, MMLU, GSM8K) against baselines, with no equations, derivations, or self-referential definitions that reduce outputs to fitted inputs by construction. The central claims rest on controlled evaluations rather than load-bearing mathematical steps or self-citation chains that collapse to the target result. This is the expected non-finding for an applied empirical methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent behavior depends on received information while communication edge usefulness depends on how the receiving agent interprets that information
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/ abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
John Wiley & Sons, Chichester, UK, 2001
Kalyanmoy Deb.Multi-Objective Optimization Using Evolutionary Algorithms. John Wiley & Sons, Chichester, UK, 2001. ISBN 9780471873396
2001
-
[3]
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and T. Meyarivan. A fast and elitist multiob- jective genetic algorithm: NSGA-II.IEEE Transactions on Evolutionary Computation, 6(2): 182–197, 2002. doi: 10.1109/4235.996017
-
[4]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 11733–11763. PMLR, 2024. URL https://proceedings.mlr. press/v235...
2024
-
[5]
Complexity-based prompting for multi-step reasoning
Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. Complexity-based prompting for multi-step reasoning. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=yf1icZHC-l9
2023
-
[6]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=d7KBjmI3GmQ
2021
-
[7]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework. InThe Twelfth International Conference on Learning Representations,
-
[8]
URLhttps://openreview.net/forum?id=VtmBAGCN7o
-
[9]
LLM-blender: Ensembling large language models with pairwise ranking and generative fusion
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. LLM-blender: Ensembling large language models with pairwise ranking and generative fusion. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14165–14178, Toronto, Canada, 2023. Association for Computational Linguistics. doi: 10.18653/v1/202...
-
[10]
Fitness distance correlation as a measure of problem difficulty for genetic algorithms
Terry Jones and Stephanie Forrest. Fitness distance correlation as a measure of problem difficulty for genetic algorithms. InProceedings of the Sixth International Conference on Genetic Algorithms, pages 184–192. Morgan Kaufmann, 1995
1995
-
[11]
Michael D. McKay, Richard J. Beckman, and William J. Conover. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics, 21(2):239–245, 1979. doi: 10.1080/00401706.1979.10489755
-
[12]
ImageInWords: Unlocking hyper-detailed image descriptions
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15174–15186, Ba...
-
[13]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=1PL1NIMMrw
2023
-
[14]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems, 2024. UR...
2024
-
[15]
Autogen: Enabling next-gen LLM applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen LLM applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024. URL https://openreview.net/forum? id=BAakY1hNKS
2024
-
[16]
G-designer: Architecting multi-agent communication topologies via graph neural networks
Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. G-designer: Architecting multi-agent communication topologies via graph neural networks. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=LpE54NUnmO
2025
-
[17]
Progressive-hint prompt- ing improves reasoning in large language models
Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, and Yu Li. Progressive-hint prompt- ing improves reasoning in large language models. InAI for Math Workshop @ ICML 2024,
2024
-
[18]
URLhttps://openreview.net/forum?id=UkFEs3ciz8
-
[19]
GPTSwarm: Language agents as optimizable graphs
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. GPTSwarm: Language agents as optimizable graphs. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/ forum?id=uTC9AFXIhg
2024
-
[20]
Comparison of multiobjective evolutionary algorithms: Empirical results.Evolutionary Computation, 8(2):173–195, 2000
Eckart Zitzler, Kalyanmoy Deb, and Lothar Thiele. Comparison of multiobjective evolutionary algorithms: Empirical results.Evolutionary Computation, 8(2):173–195, 2000. doi: 10.1162/ 106365600568202. A Related Work A.1 Single-Agent Reasoning Single-agent reasoning methods improve the inference process of a single LLM without introducing explicit inter-agen...
2000
-
[21]
Fact Check: Check whether each option is factually true
-
[22]
Defer to MathSolver
Relevance: Check whether each option answers the question. ## CRITICAL RULE - If this is a math question, output: "Defer to MathSolver." - Do not copy other agents’ analyses. Check the facts independently. ## OUTPUT - Option [X]: [Correct/Incorrect] - [Brief Reason] For GSM8K, solver prompts are more calculation-oriented. The math solver receives hints fr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.