SIGMA: Bridging Structural and Distributional Gaps for Vision Foundation Model Adaptation
Pith reviewed 2026-06-29 13:41 UTC · model grok-4.3
The pith
SIGMA adapts vision foundation models to dense tasks by bridging structural and distributional gaps with a two-module adapter using 1.72 percent trainable parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SIGMA consists of a scale-adaptive fusion module that enhances extraction of multi-granularity visual information to bridge structural gaps and a semantic modulation module that performs global feature alignment on the fused features to eliminate distributional gaps, enabling effective unified spatial and distributional adaptation for dense tasks.
What carries the argument
The Scale-Integrated Global Modulation Adapter (SIGMA) formed by combining scale-adaptive fusion and semantic modulation modules.
If this is right
- SIGMA delivers consistent performance gains over state-of-the-art PEFT methods on multiple downstream dense tasks.
- The method maintains its advantages when applied to different vision foundation model backbones.
- Only 1.72 percent of the backbone parameters need training to achieve the reported adaptation.
- The design produces unified handling of spatial and distributional shifts during adaptation.
Where Pith is reading between the lines
- The modular separation of fusion and modulation steps could be reused to adapt models to other spatially structured outputs beyond the tested dense tasks.
- If the gap-bridging pattern holds, similar lightweight additions might lower the barrier for adapting foundation models in settings with limited labeled data for dense outputs.
- The low parameter count suggests the approach could support rapid task switching on hardware where storing full fine-tuned copies is impractical.
Load-bearing premise
That structural and distributional gaps are the primary obstacles limiting PEFT performance on dense tasks and that the two proposed modules close those gaps without introducing new accuracy or stability problems.
What would settle it
An experiment on standard dense prediction benchmarks where SIGMA fails to match or exceed the accuracy of leading PEFT baselines while keeping trainable parameters at or below 1.72 percent of the backbone.
Figures
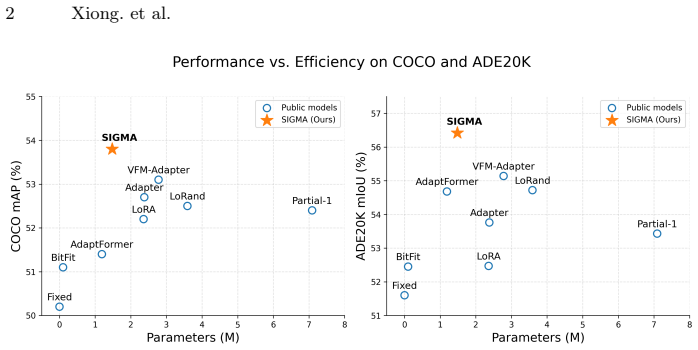
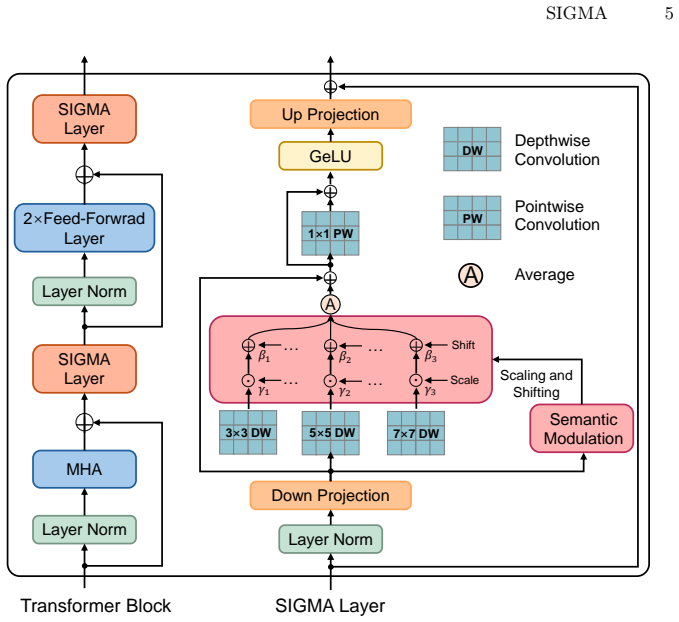
read the original abstract
Vision Foundation Models (VFMs) have demonstrated impressive representational capabilities. However, adapting them to downstream tasks via full fine-tuning incurs prohibitive computational and storage overhead. Parameter-Efficient Fine-Tuning (PEFT) has emerged as a compelling alternative, aiming to achieve performance parity with full fine-tuning at minimal training costs. Nonetheless, applying PEFT to VFMs for dense prediction tasks remains challenging due to the structural and distributional gaps. To bridge these gaps, we propose \textbf{S}cale-\textbf{I}ntegrated \textbf{G}lobal \textbf{M}odulation \textbf{A}dapter (\textbf{SIGMA}), a novel lightweight PEFT method, which consists of two modules: scale-adaptive fusion and semantic modulation. Specifically, the scale-adaptive fusion module is utilized to bridge structural gaps by enhancing the extraction of multi-granularity visual information. Furthermore, SIGMA introduces semantic modulation on the fusion features to perform global feature alignment to further eliminate the distribution gap. This design facilitates unified spatial and distributional adaptation, requiring only 1.72\% trainable parameters relative to the VFM backbone. Comprehensive experiments across various downstream dense tasks and multiple VFM backbones demonstrate that SIGMA achieves consistent and superior performance over state-of-the-art PEFT methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SIGMA, a lightweight PEFT adapter for vision foundation models on dense prediction tasks. It introduces two modules—scale-adaptive fusion to extract multi-granularity features and close structural gaps, plus semantic modulation for global feature alignment to close distributional gaps—claiming this unified adaptation requires only 1.72% trainable parameters relative to the backbone and yields consistent superiority over prior PEFT methods across multiple downstream tasks and VFM backbones.
Significance. If the performance claims hold under rigorous evaluation, the work would offer a practical, low-overhead route for adapting large VFMs to dense tasks without full fine-tuning, which is relevant given the computational costs of such models. The explicit focus on structural and distributional gaps is a clear framing, though its impact depends on the strength of the supporting experiments.
major comments (1)
- [Abstract] Abstract: The central claim of 'consistent and superior performance over state-of-the-art PEFT methods' is asserted without any reported metrics, baselines, task-specific results, ablation studies, or quantitative comparisons. This absence is load-bearing because the manuscript's value rests entirely on the empirical outcome; without these details it is impossible to evaluate whether the data support the stated superiority or the 1.72% parameter figure.
Simulated Author's Rebuttal
We thank the referee for their comment. We address the point on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'consistent and superior performance over state-of-the-art PEFT methods' is asserted without any reported metrics, baselines, task-specific results, ablation studies, or quantitative comparisons. This absence is load-bearing because the manuscript's value rests entirely on the empirical outcome; without these details it is impossible to evaluate whether the data support the stated superiority or the 1.72% parameter figure.
Authors: We agree that the abstract asserts the superiority claim without embedding specific numerical results, which limits immediate assessment from the abstract alone. The manuscript body contains the full supporting evidence, including quantitative comparisons against multiple PEFT baselines across tasks (semantic segmentation, instance segmentation, depth estimation), datasets, and backbones, along with ablations and the 1.72% parameter count (detailed in Tables 1-4 and Section 4). To address the concern directly, we will revise the abstract to include concise key metrics (e.g., average mIoU gains and parameter ratio) while preserving brevity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces SIGMA as an empirical PEFT design with two modules (scale-adaptive fusion for multi-granularity features and semantic modulation for global alignment) whose value is asserted via experiments on downstream dense tasks and multiple backbones. No equations, uniqueness theorems, or derivation steps are present that reduce any claimed prediction or performance gain to a fitted parameter or self-citation by construction. The central claims rest on external validation through comparative results rather than internal self-definition or renaming of inputs, satisfying the criteria for a self-contained non-circular contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
BEiT: BERT Pre-Training of Image Transformers
Bao, H., Dong, L., Piao, S., Wei, F.: Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
2020
-
[4]
Advances in Neural Information Processing Systems35, 16664–16678 (2022)
Chen, S., Ge, C., Tong, Z., Wang, J., Song, Y., Wang, J., Luo, P.: Adaptformer: Adapting vision transformers for scalable visual recognition. Advances in Neural Information Processing Systems35, 16664–16678 (2022)
2022
-
[5]
On Self Modulation for Generative Adversarial Networks
Chen, T., Lucic, M., Houlsby, N., Gelly, S.: On self modulation for generative adversarial networks. arXiv preprint arXiv:1810.01365 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Zeng, Y., Chen, Z., Gao, H., Chen, L., Liu, J., Zhao, F.: Vfm-adapter: Adapting visual foundation models for dense prediction with dynamic hybrid oper- ation mapping. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2385–2393 (2025)
2025
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1290–1299 (2022)
2022
-
[8]
Contributors, M.: MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark.https://github.com/open-mmlab/mmsegmentation(2020)
2020
-
[9]
Vision Transformers Need Registers
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need reg- isters. arXiv preprint arXiv:2309.16588 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Advances in neural information processing systems30(2017)
De Vries, H., Strub, F., Mary, J., Larochelle, H., Pietquin, O., Courville, A.C.: Modulating early visual processing by language. Advances in neural information processing systems30(2017)
2017
-
[11]
Advances in Neural Information Processing Sys- tems36, 52548–52567 (2023)
Dong, W., Yan, D., Lin, Z., Wang, P.: Efficient adaptation of large vision trans- former via adapter re-composing. Advances in Neural Information Processing Sys- tems36, 52548–52567 (2023)
2023
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020) 16 Xiong. et al
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
In: Proceedings of the IEEE/CVF international conference on computer vision
Fan, H., Xiong, B., Mangalam, K., Li, Y., Yan, Z., Malik, J., Feichtenhofer, C.: Multiscale vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6824–6835 (2021)
2021
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[15]
In: Proceedings of the IEEE international conference on computer vision
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 2961–2969 (2017)
2017
-
[16]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[17]
In: International conference on machine learning
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: International conference on machine learning. pp. 2790–2799. PMLR (2019)
2019
-
[18]
International Confer- ence on Learning Representations1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. International Confer- ence on Learning Representations1(2), 3 (2022)
2022
-
[19]
In: Proceedings of the computer vision and pattern recognition conference
Huang, S., Lu, Z., Cun, X., Yu, Y., Zhou, X., Shen, X.: Deim: Detr with improved matching for fast convergence. In: Proceedings of the computer vision and pattern recognition conference. pp. 15162–15171 (2025)
2025
-
[20]
In: Proceedings of the IEEE international conference on computer vision
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE international conference on computer vision. pp. 1501–1510 (2017)
2017
-
[21]
In: International conference on machine learning
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: International conference on machine learning. pp. 448–456. pmlr (2015)
2015
-
[22]
Advances in neural information processing systems28(2015)
Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. Advances in neural information processing systems28(2015)
2015
-
[23]
In: European conference on computer vision
Jia, M., Tang, L., Chen, B.C., Cardie, C., Belongie, S., Hariharan, B., Lim, S.N.: Visual prompt tuning. In: European conference on computer vision. pp. 709–727. Springer (2022)
2022
-
[24]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[25]
Advances in neural information processing systems25 (2012)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep con- volutional neural networks. Advances in neural information processing systems25 (2012)
2012
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Y., Fan, H., Hu, R., Feichtenhofer, C., He, K.: Scaling language-image pre- training via masking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 23390–23400 (2023)
2023
-
[27]
Advances in Neural Information Processing Systems35, 109–123 (2022)
Lian, D., Zhou, D., Feng, J., Wang, X.: Scaling & shifting your features: A new baseline for efficient model tuning. Advances in Neural Information Processing Systems35, 109–123 (2022)
2022
-
[28]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[29]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lin, Y., Yuan, Y., Zhang, Z., Li, C., Zheng, N., Hu, H.: Detr does not need multi- scale or locality design. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6545–6554 (2023) SIGMA 17
2023
-
[30]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[31]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3431–3440 (2015)
2015
-
[32]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
In: Proceedings of the AAAI conference on artificial intelligence
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: Film: Visual rea- soning with a general conditioning layer. In: Proceedings of the AAAI conference on artificial intelligence. vol. 32 (2018)
2018
-
[34]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[36]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12179–12188 (2021)
2021
-
[37]
IEEE transactions on pattern analysis and machine intelligence44(3), 1623–1637 (2020)
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE transactions on pattern analysis and machine intelligence44(3), 1623–1637 (2020)
2020
-
[38]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 779–788 (2016)
2016
-
[40]
In: European conference on computer vision
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: European conference on computer vision. pp. 746–
-
[41]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Sun, Q., Fang, Y., Wu, L., Wang, X., Cao, Y.: Eva-clip: Improved training tech- niques for clip at scale. arXiv preprint arXiv:2303.15389 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Tan,M.,Pang,R.,Le,Q.V.:Efficientdet:Scalableandefficientobjectdetection.In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 10781–10790 (2020)
2020
-
[43]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Vasu, P.K.A., Pouransari, H., Faghri, F., Vemulapalli, R., Tuzel, O.: Mobileclip: Fast image-text models through multi-modal reinforced training. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15963–15974 (2024)
2024
-
[45]
In: Proceedings of the European conference on computer vision (ECCV)
Wu, Y., He, K.: Group normalization. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018) 18 Xiong. et al
2018
-
[46]
In: Proceedings of the European conference on computer vision (ECCV)
Xiao, T., Liu, Y., Zhou, B., Jiang, Y., Sun, J.: Unified perceptual parsing for scene understanding. In: Proceedings of the European conference on computer vision (ECCV). pp. 418–434 (2018)
2018
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Un- leashing the power of large-scale unlabeled data. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10371–10381 (2024)
2024
-
[48]
Advances in Neural Information Processing Systems37, 21875–21911 (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024)
2024
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yin, D., Yang, Y., Wang, Z., Yu, H., Wei, K., Sun, X.: 1% vs 100%: Parameter- efficient low rank adapter for dense predictions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20116–20126 (2023)
2023
-
[50]
Yosinski, J., Clune, J., Bengio, Y., Lipson, H.: How transferable are features in deep neural networks? Advances in neural information processing systems27(2014)
2014
-
[51]
In: Proceedings of the European conference on computer vision (ECCV)
Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., Sang, N.: Bisenet: Bilateral segmenta- tion network for real-time semantic segmentation. In: Proceedings of the European conference on computer vision (ECCV). pp. 325–341 (2018)
2018
-
[52]
In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Zaken, E.B., Goldberg, Y., Ravfogel, S.: Bitfit: Simple parameter-efficient fine- tuning for transformer-based masked language-models. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). pp. 1–9 (2022)
2022
-
[53]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023)
2023
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: Detrs beat yolos on real-time object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16965–16974 (2024)
2024
-
[55]
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Scene parsing throughade20kdataset.In:ProceedingsoftheIEEEconferenceoncomputervision and pattern recognition. pp. 633–641 (2017)
2017
-
[56]
iBOT: Image BERT Pre-Training with Online Tokenizer
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: ibot: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.