GeneralThinker: Domain-General Reasoning through Likelihood-Guided Answer-Conditioned Optimization
Pith reviewed 2026-06-29 12:47 UTC · model grok-4.3
The pith
GeneralThinker uses likelihood of ground-truth answers to enable dense token-level optimization for domain-general reasoning without verifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
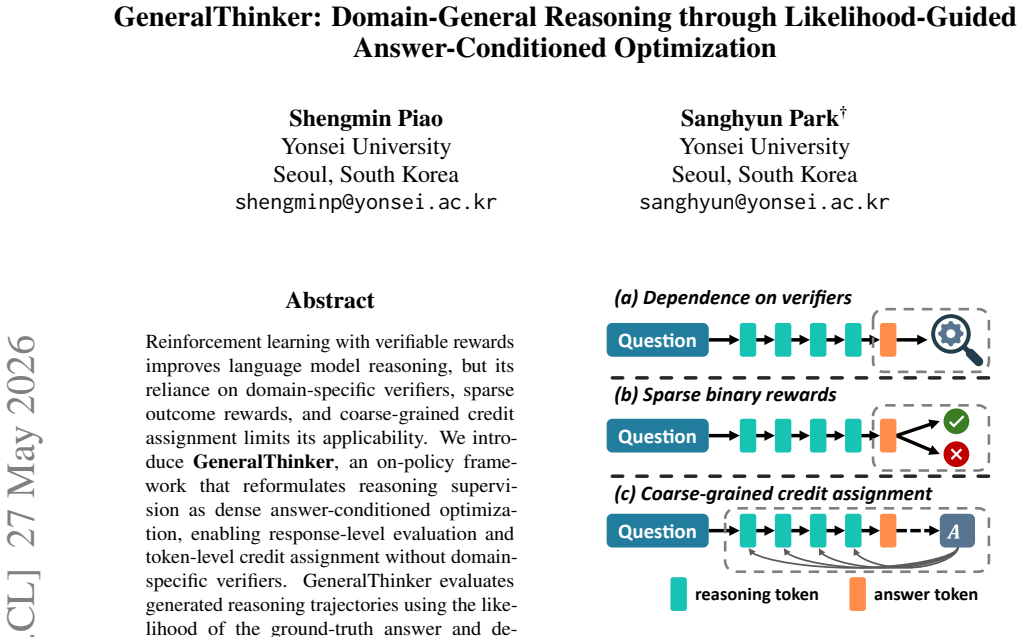
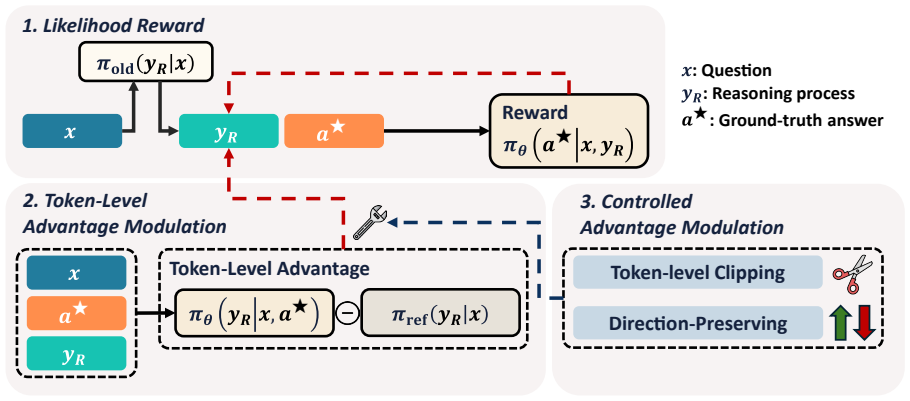
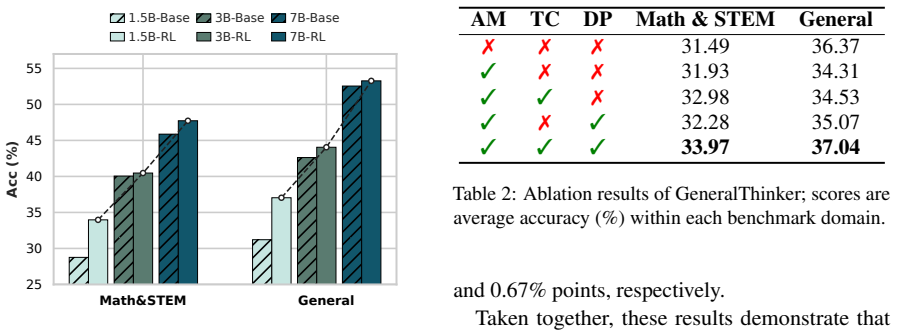
GeneralThinker reformulates reasoning supervision as dense answer-conditioned optimization. It evaluates reasoning trajectories by the likelihood of the ground-truth answer under the model and computes token-wise compatibility signals. Clipping and direction-preserving modulation constrain the updates to maintain stability. This yields the best average performance on eleven benchmarks covering mathematics, STEM, and general reasoning without any domain-specific verifiers.
What carries the argument
Likelihood-guided answer-conditioned optimization that turns the probability of the ground-truth answer into dense token-wise reward signals for on-policy updates.
If this is right
- It enables reasoning training without domain-specific verifiers.
- It supplies dense response evaluation and token-level credit assignment.
- It attains the best average performance across 11 benchmarks in multiple domains.
- Controlled modulation ensures token-level updates remain stable rather than destabilizing training.
- The framework applies to on-policy optimization for general reasoning tasks.
Where Pith is reading between the lines
- The same likelihood signal could be tested in non-reasoning generation tasks.
- Lowering the verifier requirement might allow faster iteration on new reasoning domains.
- The clipping technique may prove useful in other fine-grained RL settings for language models.
- If unbiased, this could complement or replace sparse rewards in existing RLHF pipelines.
Load-bearing premise
The likelihood of the ground-truth answer under the current policy provides an unbiased and stable dense reward signal that can replace domain-specific verifiers without introducing systematic bias in credit assignment.
What would settle it
Finding that models trained with this method show degraded performance or biased token assignments on benchmarks where answer likelihood does not align with reasoning quality would disprove the central claim.
Figures
read the original abstract
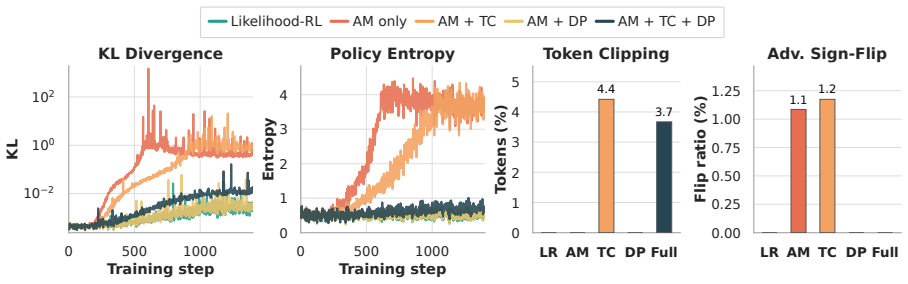
Reinforcement learning with verifiable rewards improves language model reasoning, but its reliance on domain-specific verifiers, sparse outcome rewards, and coarse-grained credit assignment limits its applicability. We introduce GeneralThinker, an on-policy framework that reformulates reasoning supervision as dense answer-conditioned optimization, enabling response-level evaluation and token-level credit assignment without domain-specific verifiers. GeneralThinker evaluates generated reasoning trajectories using the likelihood of the ground-truth answer and derives token-wise compatibility signals for fine-grained credit assignment. To stabilize optimization, it constrains token-level updates through clipping and direction-preserving modulation. Across 11 benchmarks spanning mathematics, STEM, and general reasoning, GeneralThinker achieves the best average performance. Further analyses show that uncontrolled token-level modulation can destabilize training, whereas controlled modulation makes fine-grained credit assignment consistently effective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GeneralThinker, an on-policy RL framework for domain-general reasoning in language models. It reformulates supervision as dense answer-conditioned optimization, using the likelihood of the ground-truth answer under the current policy as the reward signal for response-level evaluation and token-level credit assignment. Clipping and direction-preserving modulation stabilize the updates. The central claim is that this yields the best average performance across 11 benchmarks spanning mathematics, STEM, and general reasoning, without requiring domain-specific verifiers.
Significance. If the empirical results survive proper controls and ablations, the approach could meaningfully broaden the applicability of RL-based reasoning improvement by removing the need for task-specific verifiers and enabling finer-grained credit assignment. The explicit analysis of modulation stability is a positive technical element. The significance remains provisional because the central claim rests on an unverified empirical assertion whose validity depends on whether the likelihood signal isolates reasoning quality.
major comments (2)
- [Abstract] Abstract: the claim of best average performance on 11 benchmarks is presented without reported details on experimental controls, baseline comparisons, statistical significance, or whether gains survive ablation of the modulation components; this is load-bearing for the central empirical assertion.
- [Method (reward definition)] Method (reward definition, as described in the abstract): the reward is the likelihood of the ground-truth answer under the current policy, creating a self-referential loop; without an ablation that replaces the true answer with a random or permuted target while holding all other components fixed, it is unclear whether improvements reflect reasoning gains or answer leakage/memorization bias.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below with clarifications from the manuscript and commitments to revisions where they strengthen the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of best average performance on 11 benchmarks is presented without reported details on experimental controls, baseline comparisons, statistical significance, or whether gains survive ablation of the modulation components; this is load-bearing for the central empirical assertion.
Authors: The manuscript reports these details in Section 4 (Experiments), including baseline comparisons to verifier-based RL methods and other on-policy approaches, statistical significance via means and standard deviations over multiple random seeds, and controls for experimental setup. Section 5.3 presents ablations on the modulation components showing that performance gains persist under controlled modulation. The abstract follows standard length constraints by summarizing the primary result. To make the robustness more visible upfront, we will revise the abstract to briefly note that results hold under the reported controls and ablations. revision: partial
-
Referee: [Method (reward definition)] Method (reward definition, as described in the abstract): the reward is the likelihood of the ground-truth answer under the current policy, creating a self-referential loop; without an ablation that replaces the true answer with a random or permuted target while holding all other components fixed, it is unclear whether improvements reflect reasoning gains or answer leakage/memorization bias.
Authors: The reward is the log-likelihood of the ground-truth answer conditioned on the question plus the model's generated reasoning trajectory, evaluated under the current policy. This provides a dense, trajectory-dependent signal that rewards reasoning steps increasing the probability of the correct answer. The on-policy update and explicit conditioning on the trajectory are intended to tie the signal to reasoning quality rather than direct answer recall. To directly test for leakage or memorization effects as suggested, we will add the ablation replacing the ground-truth target with a random or permuted answer (holding all other components fixed) and report comparative results in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks
full rationale
The paper's central claim is superior average performance across 11 external benchmarks. The method defines a reward from the likelihood of dataset ground-truth answers under the current policy and uses it for on-policy optimization with clipping. No equations, self-citations, or uniqueness theorems are quoted that reduce any derived result or prediction to the inputs by construction. The optimization target is an external data signal, and benchmark scores are measured independently. This satisfies the default expectation of a self-contained empirical method without load-bearing self-reference.
Axiom & Free-Parameter Ledger
free parameters (1)
- clipping threshold and modulation strength
axioms (1)
- domain assumption Likelihood of the ground-truth answer under the current policy is a reliable proxy for reasoning quality across domains.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Are we done with mmlu? InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (V olume 1: Long Papers), pages 5069–5096. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, and 1 others. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Ja- cob Steinhardt. 2021. Measuring mathematical prob- lem solving with the math dataset.arXiv preprint arXiv:2103.03874. Edward J Hu, yelong shen, Phillip Wallis, Zeyuan A...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Wei Liu, Siya Qi, Xinyu Wang, Chen Qian, Yali Du, and Yulan He. 2025. NOVER: Incentive training for language models via verifier-free reinforcement learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7439–7...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.