Quantum principal component analysis without eigenvector recovery
Pith reviewed 2026-06-29 11:58 UTC · model grok-4.3
The pith
A calibrated quantum measurement with an entropy-regularized Fermi-Dirac filter performs soft principal component analysis without eigenvector recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
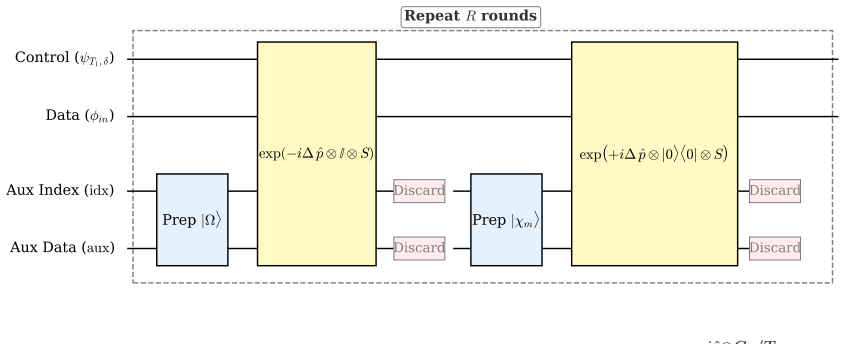
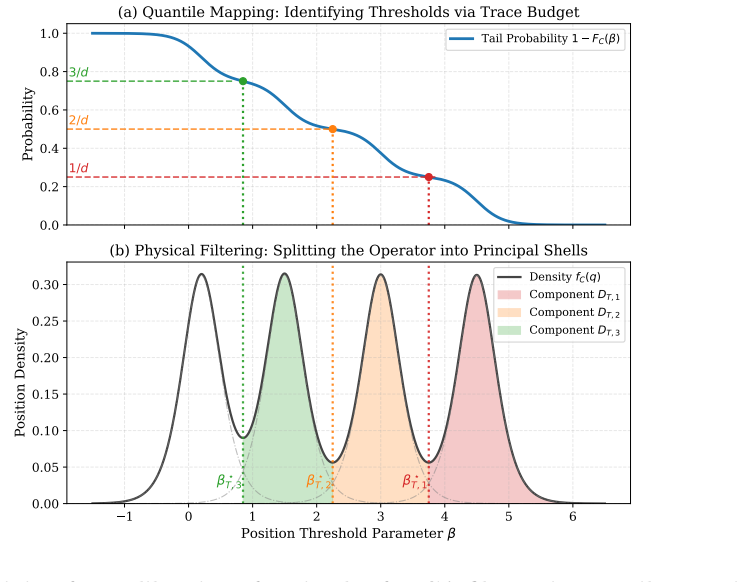
The entropy-regularized Fermi--Dirac filter is the unique optimizer of an entropy-regularized variational formulation of PCA and converges to the classical PCA projector in the zero-temperature limit. For centered covariance operators represented by quantum feature states, a single fixed circuit, together with threshold calibration, accesses all optimal filters for different rank budgets or retained-variance levels without rank-dependent circuit updates or eigenvector recovery. For new inputs, the same calibrated quantum circuit yields soft principal subspace scores, spectral energy profiles, and postselected filtered states. The required centering of both training and test data is performed
What carries the argument
The entropy-regularized Fermi--Dirac filter, the unique optimizer of an entropy-regularized variational formulation of PCA that replaces the hard top-k projector and functions directly as a quantum measurement.
If this is right
- All optimal filters for different rank budgets or retained-variance levels are obtained from one fixed circuit plus threshold calibration
- Sample complexity stays O(η^{-2}) and independent of dimension for scoring accuracy η
- Coherent centering inside the protocol enables use on quantum data without classical feature vectors
- The same circuit supplies spectral energy profiles and postselected filtered states in addition to scores
- The filter recovers the classical hard PCA projector exactly in the zero-temperature limit
Where Pith is reading between the lines
- The measurement framing could extend to other kernel spectral tasks that currently rely on explicit eigendecomposition
- Soft scoring may simplify real-time postselection pipelines in quantum sensing or anomaly detection
- The variational entropy-regularized objective might suggest classical sampling algorithms that avoid full matrix diagonalization
- Near-term hardware tests could check whether the coherent centering overhead scales as predicted for moderate qubit counts
Load-bearing premise
Centered covariance operators can be represented by quantum feature states and coherent centering of both training and test data can be performed inside the quantum protocol when no classical feature vectors or centered Gram matrix are available.
What would settle it
An experiment or simulation in which the sample complexity required to reach additive accuracy η in normalized fractional-rank or retained-variance scoring exceeds O(η^{-2}) or in which the soft scores deviate from classical PCA results by more than the zero-temperature limit predicts.
Figures
read the original abstract
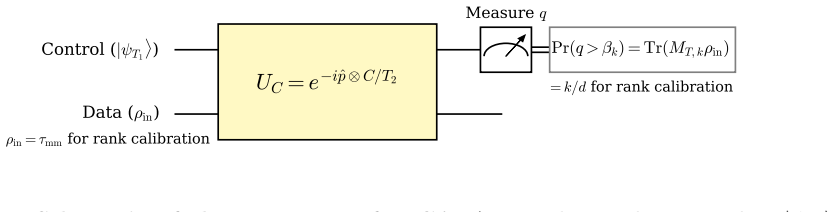
Principal component analysis (PCA) is traditionally implemented through a covariance or kernel matrix, leading-eigenvector extraction, and hard rank-$k$ projection. These steps can be computationally costly in high-dimensional and quantum-data settings, sensitive to small eigengaps, and unnecessary when downstream tasks only require principal-subspace scores. Such score-based objectives are important in applications such as anomaly detection, spectral-energy profiling, and other postselection tasks. To address these needs, we introduce a measurement-based soft PCA framework replacing the hard top-$k$ projector with an entropy-regularized Fermi--Dirac filter. This filter is the unique optimizer of an entropy-regularized variational formulation of PCA and converges to the classical PCA projector in the zero-temperature limit. This filter has a direct interpretation as a quantum measurement, which naturally suggests a quantum approach. For centered covariance operators represented by quantum feature states, a single fixed circuit, together with threshold calibration, accesses all optimal filters for different rank budgets or retained-variance levels without rank-dependent circuit updates or eigenvector recovery. For new inputs, the same calibrated quantum circuit yields soft principal subspace scores, spectral energy profiles, and postselected filtered states. The required centering of both training and test data is performed coherently inside the quantum protocol, which is particularly important for quantum data where no classical feature vectors or centered Gram matrix are directly available. By reframing PCA as a calibrated measurement task, this framework bypasses the need for iterative eigenvector extraction and achieves a dimension-independent sample complexity $O(\eta^{-2})$ for normalized fractional-rank or retained variance scoring at additive accuracy $\eta$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a measurement-based soft PCA framework that replaces hard top-k projection with an entropy-regularized Fermi-Dirac filter, which is the unique optimizer of an entropy-regularized variational formulation of PCA and converges to the classical projector at zero temperature. For centered covariance operators represented by quantum feature states, a single fixed circuit with threshold calibration is claimed to access all optimal filters without rank-dependent updates or eigenvector recovery. Coherent centering of training and test data is performed inside the quantum protocol. The central claim is a dimension-independent sample complexity O(η^{-2}) for normalized fractional-rank or retained-variance scoring at additive accuracy η, particularly advantageous for quantum data where no classical feature vectors or Gram matrix are available.
Significance. If the claims hold with the required resource accounting, the work would provide a useful reframing of PCA as a calibrated quantum measurement task, bypassing iterative eigenvector methods and enabling direct soft scores and filtered states. The variational characterization of the filter and its zero-temperature limit are conceptually clean; the emphasis on quantum-native centering for data without classical representations is a relevant strength for quantum ML settings. The dimension-independent complexity would be a notable result if the centering subroutine does not introduce hidden dimension dependence.
major comments (2)
- [Abstract] Abstract (final paragraph): The dimension-independent O(η^{-2}) sample complexity for additive accuracy η on normalized fractional-rank scores is load-bearing for the central claim, yet the manuscript provides no explicit circuit depth, copy count, or measurement overhead for the coherent centering of training and test quantum feature states. If this subroutine scales with feature dimension or requires additional copies linear in 1/η, the stated complexity bound no longer holds independently of dimension.
- [Abstract] Abstract (final paragraph) and any section deriving the sample complexity: The claim that a single fixed circuit plus threshold calibration suffices for all rank budgets relies on the centering being performed coherently without classical Gram matrix access. No resource analysis or pseudocode for this centering operation is referenced, leaving the dimension-independence assertion dependent on an unverified subroutine whose cost must be shown to be O(1) or absorbed into the O(η^{-2}) bound.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for explicit resource accounting on the coherent centering subroutine. We address each major comment below and will revise the manuscript to include the requested analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): The dimension-independent O(η^{-2}) sample complexity for additive accuracy η on normalized fractional-rank scores is load-bearing for the central claim, yet the manuscript provides no explicit circuit depth, copy count, or measurement overhead for the coherent centering of training and test quantum feature states. If this subroutine scales with feature dimension or requires additional copies linear in 1/η, the stated complexity bound no longer holds independently of dimension.
Authors: We agree that the current manuscript lacks an explicit resource analysis for coherent centering. The centering protocol operates directly on quantum feature states with a fixed circuit that uses a constant number of copies independent of dimension and η. We will add a dedicated subsection with circuit depth, copy count, and measurement overhead to confirm that these costs are absorbed into the stated O(η^{-2}) bound without introducing dimension dependence. revision: yes
-
Referee: [Abstract] Abstract (final paragraph) and any section deriving the sample complexity: The claim that a single fixed circuit plus threshold calibration suffices for all rank budgets relies on the centering being performed coherently without classical Gram matrix access. No resource analysis or pseudocode for this centering operation is referenced, leaving the dimension-independence assertion dependent on an unverified subroutine whose cost must be shown to be O(1) or absorbed into the O(η^{-2}) bound.
Authors: The referee is correct that no resource analysis or pseudocode for centering is currently referenced. In revision we will supply both a resource count demonstrating O(1) overhead in dimension and η, and pseudocode for the coherent centering step, thereby verifying that the subroutine cost does not compromise the dimension-independent sample complexity. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces an entropy-regularized Fermi-Dirac filter as the unique optimizer of a variational PCA formulation and reframes the task as calibrated quantum measurement to obtain O(η^{-2}) sample complexity. No quoted step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or definitional tautology. The centering subroutine is described as internal to the protocol but is not shown to be constructed from the target complexity bound. This matches the default expectation of an independent proposal with no load-bearing self-reference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The entropy-regularized variational formulation of PCA admits the Fermi-Dirac filter as its unique optimizer.
- domain assumption Centered covariance operators can be represented by quantum feature states allowing coherent centering inside the quantum protocol.
Reference graph
Works this paper leans on
-
[1]
Jolliffe.Principal Component Analysis
Ian T. Jolliffe.Principal Component Analysis. Springer Series in Statistics. Springer, second edition, 2002.doi:10.1007/b98835
-
[2]
Ian T. Jolliffe and Jorge Cadima. Principal component analysis: A review and recent developments.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2065):20150202, 2016.doi:10.1098/rsta.2015.0202
-
[3]
J. Edward Jackson and Govind S. Mudholkar. Control procedures for residuals associated with principal component analysis.Technometrics, 21(3):341–349, 1979.doi:10.1080/ 00401706.1979.10489779
-
[4]
Diagnosing network-wide traffic anomalies
Anukool Lakhina, Mark Crovella, and Christophe Diot. Diagnosing network-wide traffic anomalies. InProceedings of ACM SIGCOMM 2004, pages 219–230, 2004.doi:10.1145/ 1030194.1015492
-
[5]
Qi Ding and Eric D. Kolaczyk. A compressed PCA subspace method for anomaly detection in high-dimensional data.IEEE Transactions on Information Theory, 59(11):7419–7433, 2013.doi:10.1109/TIT.2013.2278017. 34
-
[6]
Subspace method of pattern recognition
Satosi Watanabe and Nikhil Pakvasa. Subspace method of pattern recognition. InProceed- ings of the 1st International Joint Conference on Pattern Recognition, pages 25–32, 1973. URL:https://www.haralick.org/ML/subspace_watanabe.pdf
1973
-
[7]
Matthew Turk and Alex Pentland. Eigenfaces for recognition.Journal of Cognitive Neu- roscience, 3(1):71–86, 1991.doi:10.1162/jocn.1991.3.1.71
-
[8]
Kazuhiro Fukui. Subspace methods. In Katsushi Ikeuchi, editor,Computer Vision: A Reference Guide. Springer, 2020.doi:10.1007/978-3-030-03243-2_708-1
-
[9]
Manabu Kano, Shinji Hasebe, Iori Hashimoto, and Hiromu Ohno. A new multivariate statistical process monitoring method using principal component analysis.Computers & Chemical Engineering, 25(7–8):1103–1113, 2001.doi:10.1016/S0098-1354(01)00683-4
-
[10]
Elia Marin, Davide Redolfi Bristol, Alfredo Rondinella, Alex Lanzutti, and Pietro Riello. Statistical approaches to Raman imaging: Principal component score mapping.Analytical Methods, 16:2707–2720, 2024.doi:10.1039/D4AY00171K
-
[11]
Thomas P. Minka. Automatic choice of dimensionality for PCA. In Todd K. Leen, Thomas G. Dietterich, and Volker Tresp, editors,Advances in Neural Information Process- ing Systems 13, pages 598–604. MIT Press, 2000. URL:https://proceedings.neurips. cc/paper_files/paper/2000/file/7503cfacd12053d309b6bed5c89de212-Paper.pdf
2000
-
[12]
Ronan Perry, Snigdha Panigrahi, Jacob Bien, and Daniela Witten. Inference on the pro- portion of variance explained in principal component analysis.Journal of the American Statistical Association, 2025.doi:10.1080/01621459.2025.2538895
-
[13]
The approximation of one matrix by another of lower rank
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank. Psychometrika, 1(3):211–218, 1936.doi:10.1007/BF02288367
-
[14]
Ky Fan. Maximum properties and inequalities for the eigenvalues of completely continuous operators.Proceedings of the National Academy of Sciences of the United States of America, 37(11):760–766, 1951.doi:10.1073/pnas.37.11.760
-
[15]
Bhatia , Matrix Analysis , vol
Rajendra Bhatia.Matrix Analysis, volume 169 ofGraduate Texts in Mathematics. Springer, 1997.doi:10.1007/978-1-4612-0653-8
-
[16]
Alexandre d’Aspremont, Laurent El Ghaoui, Michael I. Jordan, and Gert R. G. Lanck- riet. A direct formulation for sparse PCA using semidefinite programming.SIAM Review, 49(3):434–448, 2007.doi:10.1137/050645506
-
[17]
Vu, Juhee Cho, Jing Lei, and Karl Rohe
Vincent Q. Vu, Juhee Cho, Jing Lei, and Karl Rohe. Fantope projection and selection: A near-optimal convex relaxation of sparse PCA. InAdvances in Neural Information Processing Systems 26, pages 2670–2678, 2013. URL:https://proceedings.neurips. cc/paper_files/paper/2013/file/81e5f81db77c596492e6f1a5a792ed53-Paper.pdf
2013
-
[18]
Quantum principal component analysis.Nature Physics, 10(9):631–633, 2014.doi:10.1038/nphys3029
Seth Lloyd, Masoud Mohseni, and Patrick Rebentrost. Quantum principal component analysis.Nature Physics, 10(9):631–633, 2014.doi:10.1038/nphys3029
-
[19]
Cerezo, Lukasz Cincio, and Patrick J
Max Hunter Gordon, M. Cerezo, Lukasz Cincio, and Patrick J. Coles. Covariance matrix preparation for quantum principal component analysis.PRX Quantum, 3(3):030334, 2022. doi:10.1103/PRXQuantum.3.030334
-
[20]
Fast randomized entropically regularized semidefinite programming, 2023
Michael Lindsey. Fast randomized entropically regularized semidefinite programming, 2023. arXiv:2303.12133,doi:10.48550/arXiv.2303.12133. 35
-
[21]
Nana Liu and Mark M. Wilde. Fermi–Dirac thermal measurements: A framework for quantum hypothesis testing and semidefinite optimization, 2026.arXiv:2603.04061,doi: 10.48550/arXiv.2603.04061
-
[22]
Bernhard Sch¨ olkopf, Alexander Smola, and Klaus-Robert M¨ uller. Nonlinear component analysis as a kernel eigenvalue problem.Neural Computation, 10(5):1299–1319, 1998.doi: 10.1162/089976698300017467
-
[23]
Andrew M. Childs and Nathan Wiebe. Hamiltonian simulation using linear combinations of unitary operations.Quantum Information and Computation, 12(11–12):901–924, 2012. doi:10.26421/QIC12.11-12-1
-
[24]
Dominic W. Berry, Andrew M. Childs, Richard Cleve, Robin Kothari, and Rolando D. Somma. Simulating Hamiltonian dynamics with a truncated Taylor series.Physical Review Letters, 114:090502, 2015.doi:10.1103/PhysRevLett.114.090502
-
[25]
Hale F. Trotter. On the product of semi-groups of operators.Proceedings of the American Mathematical Society, 10(4):545–551, 1959.doi:10.1090/S0002-9939-1959-0108732-6
-
[26]
Masuo Suzuki. Fractal decomposition of exponential operators with applications to many- body theories and Monte Carlo simulations.Physics Letters A, 146(6):319–323, 1990. doi:10.1016/0375-9601(90)90962-N
-
[27]
Aryeh Dvoretzky, Jack Kiefer, and Jacob Wolfowitz. Asymptotic minimax character of the sample distribution function and of the classical multinomial estimator.The Annals of Mathematical Statistics, 27(3):642–669, 1956.doi:10.1214/aoms/1177728174
-
[28]
Pascal Massart. The tight constant in the Dvoretzky–Kiefer–Wolfowitz inequality.The Annals of Probability, 18(3):1269–1283, 1990.doi:10.1214/aop/1176990746
-
[29]
Nana Liu, Jayne Thompson, Christian Weedbrook, Seth Lloyd, Vlatko Vedral, Mile Gu, and Kavan Modi. Power of one qumode for quantum computation.Physical Review A, 93(5):052304, 2016.doi:10.1103/PhysRevA.93.052304
-
[30]
St´ ephane Boucheron, G´ abor Lugosi, and Pascal Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013.doi:10.1093/ acprof:oso/9780199535255.001.0001
-
[31]
Gene H. Golub and Charles F. Van Loan.Matrix Computations. Johns Hopkins Univer- sity Press, fourth edition, 2013. URL:https://epubs.siam.org/doi/book/10.1137/1. 9781421407944
work page doi:10.1137/1 2013
-
[32]
SIAM, 2011.doi:10.1137/1.9781611970739
Yousef Saad.Numerical Methods for Large Eigenvalue Problems: Revised Edition. SIAM, 2011.doi:10.1137/1.9781611970739
-
[33]
Nathan Halko, Per-Gunnar Martinsson, and Joel A. Tropp. Finding structure with ran- domness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM Review, 53(2):217–288, 2011.doi:10.1137/090771806
-
[34]
Fast Stochastic Algorithms for SVD and PCA: Convergence Properties and Convexity
Ohad Shamir. Fast stochastic algorithms for SVD and PCA: Convergence properties and convexity. InProceedings of the 33rd International Conference on Machine Learning (ICML), pages 248–256, 2016. URL:https://proceedings.mlr.press/v48/shamira16. html,arXiv:1507.08788
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Prateek Jain, Chi Jin, Sham M. Kakade, Praneeth Netrapalli, and Aaron Sidford. Stream- ing PCA: Matching matrix Bernstein and near-optimal finite sample guarantees for Oja’s al- gorithm. InProceedings of the 29th Annual Conference on Learning Theory (COLT), pages 36 1147–1164, 2016. URL:https://proceedings.mlr.press/v49/jain16.html,arXiv: 1602.06929
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[36]
Andr´ as Gily´ en, Yuan Su, Guang Hao Low, and Nathan Wiebe. Quantum singular value transformation and beyond: Exponential improvements for quantum matrix arithmetics. InProceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, STOC 2019, pages 193–204, 2019.doi:10.1145/3313276.3316366
-
[37]
Ryan LaRose, Arkin Tikku, ´Etude O’Neel-Judy, Lukasz Cincio, and Patrick J. Coles. Variational quantum state diagonalization.npj Quantum Information, 5:57, 2019.doi: 10.1038/s41534-019-0167-6
-
[38]
A quantum-inspired classical algorithm for recommendation systems
Ewin Tang. A quantum-inspired classical algorithm for recommendation systems. InPro- ceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, pages 217–228, 2019.doi:10.1145/3313276.3316310
-
[39]
Ewin Tang. Quantum principal component analysis only achieves an exponential speedup because of its state preparation assumptions.Physical Review Letters, 127(6):060503, 2021. doi:10.1103/PhysRevLett.127.060503. 37 A Reconstruction error of fractional Fantope optimizers Viewing the trace constraint as a convex relaxation over the Fantope provides a natura...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.