SANTS: A State-Adaptive Scheduler for World Action Models
Pith reviewed 2026-06-29 11:54 UTC · model grok-4.3
The pith
State-adaptive scheduler selects the right denoising depth along the video noise trajectory for each robot state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
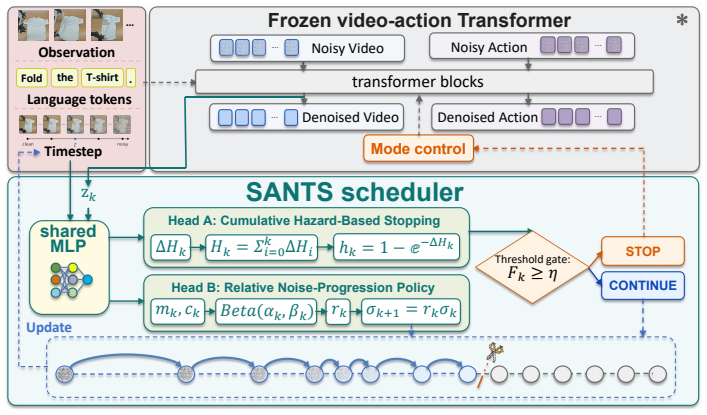
SANTS is a post-trained scheduler for video-to-action diffusion policies. At each decision point it takes the current video-state representation and noise level and jointly predicts a cumulative stopping hazard together with a relative noise-progression ratio. The scheduler is optimized end-to-end with a path-level reward computed after the frozen action branch produces its final action chunk, explicitly penalizing redundant video-state updates. This replaces the fixed terminal denoising depth with a state-dependent stopping rule along the noise trajectory.
What carries the argument
State-Adaptive Noise Trajectory Scheduler (SANTS) that predicts cumulative stopping hazard and relative noise-progression ratio from current video-state representation and noise level.
If this is right
- Adaptive selection along the video noise trajectory preserves the control benefits of full WAM future reasoning.
- Redundant video-state updates are removed while downstream action quality remains the training objective.
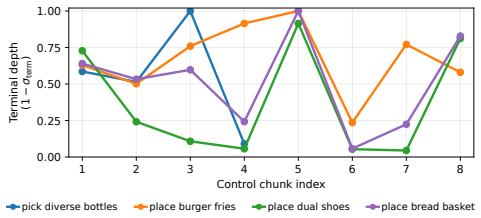
- Latency drops 81.7 percent on RoboTwin 2.0 and 79.0 percent on real-robot tasks at 94.4 percent and 73.1 percent success respectively.
- The scheduler can be post-trained without retraining the underlying video or action networks.
Where Pith is reading between the lines
- Similar hazard-based early stopping could be tested on non-video diffusion policies where intermediate representations lose task relevance.
- The approach suggests a general template for trading computation against prediction utility in any generative model used for control.
- If the reward proxy transfers across environments, the same scheduler architecture might apply to other modalities such as audio or point-cloud futures.
Load-bearing premise
The path-level reward computed after the frozen action branch generates the final action chunk is a faithful proxy for the optimal per-state stopping point along the noise trajectory.
What would settle it
An experiment that compares SANTS-chosen denoising depths against an oracle that selects the depth minimizing downstream action error on held-out tasks; a consistent gap in action error would falsify the scheduler's optimality.
Figures

read the original abstract
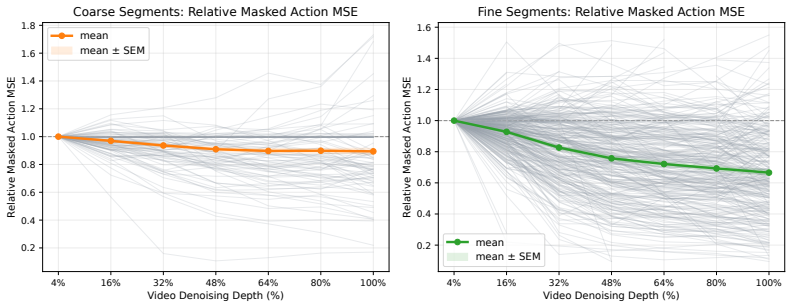
World Action Models (WAMs) improve robot manipulation by using video-based future representations to condition action generation. In pixel-space WAMs, however, the best action condition is not necessarily the fully denoised video. Controlled denoising-depth scans show that video refinement can reduce action error up to a state-dependent point, after which the gain may saturate or even reverse when late predictions become less action-relevant or physically unreliable. This suggests that action generation should use a state-dependent point along the video noise trajectory rather than a fixed terminal denoising depth. We introduce State-Adaptive Noise Trajectory Scheduler (SANTS), a lightweight scheduler for video-to-action diffusion policies. At each video decision point, SANTS reads the current video-state representation and noise level, then jointly predicts a cumulative stopping hazard and a relative noise-progression ratio. SANTS is post-trained with a path-level reward computed after the frozen action branch generates the final action chunk, so the scheduler is optimized for downstream action quality rather than intermediate video fidelity, while redundant video-state updates are explicitly penalized. Experiments show that SANTS reaches \(94.4\%\) overall success on RoboTwin 2.0 and \(73.1\%\) average success across seven real-robot tasks, while reducing latency by \(81.7\%\) and \(79.0\%\) relative to full video denoising, respectively. These results indicate that adaptive selection along the video noise trajectory can preserve the control benefits of WAM-style future reasoning while removing much of its redundant inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SANTS, a lightweight state-adaptive scheduler for video-to-action diffusion policies in World Action Models. It claims that the optimal point along the video noise trajectory for conditioning action generation is state-dependent (as shown by denoising-depth scans where refinement can saturate or reverse), and proposes jointly predicting a cumulative stopping hazard and relative noise-progression ratio from the current video-state representation and noise level. The scheduler is post-trained using a path-level reward derived after the frozen action branch produces the final action chunk, with explicit penalty on redundant updates. Experiments report 94.4% overall success on RoboTwin 2.0 and 73.1% average success on seven real-robot tasks, with latency reductions of 81.7% and 79.0% relative to full denoising.
Significance. If the central claims hold, the work could make WAM-style future reasoning more practical for real-time robot control by eliminating redundant inference while retaining performance gains. The post-training on downstream action quality (rather than video fidelity) and the explicit redundancy penalty are positive design choices. No machine-checked proofs or parameter-free derivations are present.
major comments (3)
- [Abstract] Abstract: the reported success rates (94.4%, 73.1%) and latency reductions (81.7%, 79.0%) are given without error bars, ablation details, dataset sizes, or statistical tests, so the claim that adaptive stopping is superior cannot be evaluated from the provided evidence.
- [Scheduler Training] Scheduler training description: the path-level reward is computed only after the frozen action branch generates the final chunk; no separate validation is provided that the learned hazard/ratio predictions recover the empirically optimal per-state stopping depths from the denoising scans, leaving open the possibility that the reward optimizes aggregate trajectory quality rather than marginal per-state action relevance.
- [Experiments] Experiments section: the denoising-depth scans that motivate the state-dependent claim are referenced but lack quantitative details on the number of states evaluated, the exact error curves, or how reversal of action relevance was measured, making it impossible to assess whether the scheduler training objective aligns with those observations.
minor comments (1)
- [Abstract] Notation for the hazard and ratio predictions should be introduced with explicit equations rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and evidence presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported success rates (94.4%, 73.1%) and latency reductions (81.7%, 79.0%) are given without error bars, ablation details, dataset sizes, or statistical tests, so the claim that adaptive stopping is superior cannot be evaluated from the provided evidence.
Authors: We agree that the abstract would benefit from additional context to support evaluation of the claims. In the revision we will update the abstract to reference error bars (standard deviation over multiple seeds), dataset sizes, the ablation studies already present in the experiments section, and the statistical tests used to compare against fixed-depth baselines. revision: yes
-
Referee: [Scheduler Training] Scheduler training description: the path-level reward is computed only after the frozen action branch generates the final chunk; no separate validation is provided that the learned hazard/ratio predictions recover the empirically optimal per-state stopping depths from the denoising scans, leaving open the possibility that the reward optimizes aggregate trajectory quality rather than marginal per-state action relevance.
Authors: The path-level reward is computed on the final action chunk precisely so that the scheduler optimizes for downstream action quality rather than video fidelity. We acknowledge the absence of an explicit validation comparing learned stopping depths to the scan optima. In the revision we will add such a validation on a held-out set of states, reporting quantitative alignment between the scheduler predictions and the empirically best depths from the scans. revision: yes
-
Referee: [Experiments] Experiments section: the denoising-depth scans that motivate the state-dependent claim are referenced but lack quantitative details on the number of states evaluated, the exact error curves, or how reversal of action relevance was measured, making it impossible to assess whether the scheduler training objective aligns with those observations.
Authors: We agree that the motivating scans require more quantitative detail. In the revision we will expand the experiments section to report the number of states evaluated, summarize or display the error curves, and describe the criterion used to identify reversal of action relevance. This will make explicit the alignment between the observed state dependence and the scheduler training objective. revision: yes
Circularity Check
No circularity: scheduler training uses independent downstream reward signal
full rationale
The paper's core derivation trains SANTS via a path-level reward computed from the frozen action branch after generating the final action chunk. This is a standard optimization setup that does not reduce the hazard/ratio predictions to a fitted constant by construction, nor does it rely on self-citations, imported uniqueness theorems, or ansatzes smuggled from prior work. The state-dependent stopping decision is justified by external denoising-depth scans and explicit redundancy penalties, remaining self-contained against the target performance metrics. No load-bearing step collapses to its own inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
World Action Models: A Survey
A survey that clarifies boundaries and organizes World Action Models by generation requirements and predictive substrates, identifying a trend toward generating less of the future.
Reference graph
Works this paper leans on
-
[1]
S. Wang, J. Shi, Z. Fu, X. He, F. Liu, C. Yang, Y . Zhou, Z. Fei, J. Gong, J. Fu, M. Z. Shou, X. Huang, X. Qiu, and Y .-G. Jiang. World action models: The next frontier in embodied ai,
-
[2]
URLhttps://arxiv.org/abs/2605.12090
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets, 2025. URLhttps:// arxiv.org/abs/2504.02792
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control, 2026. URLhttps://arxiv.org/abs/ 2601.21998
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning,
-
[7]
URLhttps://arxiv.org/abs/2601.16163
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations. In International Conference on Machine Learning, pages 24328–24346. PMLR, 2025. 9
2025
-
[9]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas, 2025. URLhttps://arxiv.org/ abs/2512.15692
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?, 2026. URLhttps://arxiv.org/abs/2603.16666
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Learning Visual Feature-Based World Models via Residual Latent Action
X. Zhang, Z. Xu, Y . Tao, Y . Wang, Y . She, and A. Boularias. Learning visual feature-based world models via residual latent action, 2026. URLhttps://arxiv.org/abs/2605.07079
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [14]
-
[15]
Spectrally-Guided Diffusion Noise Schedules
C. Esteves and A. Makadia. Spectrally-guided diffusion noise schedules, 2026. URLhttps: //arxiv.org/abs/2603.19222
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [16]
-
[17]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, W. Deng, Y . Guo, T. Nian, X. Xie, Q. Chen, K. Su, T. Xu, G. Liu, M. Hu, H.-a. Gao, K. Wang, Z. Liang, Y . Qin, X. Yang, P. Luo, and Y . Mu. Robotwin 2.0: A scalable data generator and bench- mark with strong domain randomization for robust bimanual robotic manipulation, 2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large-scale video generative pre-training for visual robot manipulation, 2023. URLhttps: //arxiv.org/abs/2312.13139
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, H. Zhang, and M. Zhu. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation, 2024. URLhttps://arxiv.org/abs/2410.06158
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, D. Zhao, and H. Chen. Worldvla: Towards autoregressive action world model, 2025. URLhttps: //arxiv.org/abs/2506.21539
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Q. Feng, J. Yu, J. Liu, Y . Jia, Z. Wu, H. Chen, Z. Qian, S. Gu, P. Jia, S. Ma, and S. Zhang. Harmowam: Harmonizing generalizable and precise manipulation via adaptive world action models, 2026. URLhttps://arxiv.org/abs/2605.10942
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. InIEEE International Conference on Robotics and Automation, 2017
2017
- [23]
-
[24]
J. Yang, K. Lin, J. Li, W. Zhang, T. Lin, L. Wu, Z. Su, H. Zhao, Y .-Q. Zhang, L. Chen, P. Luo, X. Yue, and H. Li. Rise: Self-improving robot policy with compositional world model, 2026. URLhttps://arxiv.org/abs/2602.11075. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [25]
-
[26]
Routray, H
S. Routray, H. Pan, U. Jain, S. Bahl, and D. Pathak. Vipra: Video prediction for robot actions,
- [27]
-
[28]
Y . Li, B. Zhang, C. Gu, Z. Ma, J. Zhang, J. Deng, X. Zhu, and L. Zhang. From imagined futures to executable actions: Mixture of latent actions for robot manipulation, 2026. URL https://arxiv.org/abs/2605.12167
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Y . Liu, P. Sun, S. Li, Y . Xie, L. Zhang, X. Chao, S. Dong, F. Chen, X.-P. Zhang, and W. Ding. Oa-wam: Object-addressable world action model for robust robot manipulation, 2026. URL https://arxiv.org/abs/2605.06481
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
MotuBrain: An Advanced World Action Model for Robot Control
MotuBrain Team, C. Xiang, F. Bao, H. Liu, H. Tan, H. Bi, J. Li, J. Liu, J. Pang, K. Jing, L. Liu, M. Cai, R. Cui, R. Zhao, R. Wang, S. Huang, Y . Feng, Y . Rong, Z. Wang, and J. Zhu. Motubrain: An advanced world action model for robot control, 2026. URLhttps://arxiv. org/abs/2604.27792
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [31]
-
[32]
H. Yang, Z. Long, Z. Ren, C. Zhou, S. Jin, H. Xu, W. Zhang, B. Cui, and B. Zhou. Being- h0.7: Improving vision-language-action model with video generation, 2026. URLhttps: //arxiv.org/abs/2605.00078
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models, 2020. URLhttps: //arxiv.org/abs/2010.02502
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[34]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. Dpm-solver: A fast ode solver for dif- fusion probabilistic model sampling in around 10 steps. InAdvances in Neural Information Processing Systems, 2022
2022
-
[35]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models, 2022. URLhttps://arxiv.org/abs/2211. 01095
2022
- [36]
-
[37]
J. Guo, Q. Li, P. Li, Z. Chen, N. Sun, Y . Su, H. Wang, Y . Zhang, X. Li, and H. Liu. Unified 4d world action modeling from video priors with asynchronous denoising, 2026. URLhttps: //arxiv.org/abs/2604.26694
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [38]
-
[39]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liu, M. Cao, P. Li, Q. Deng, W. Mei, X. Wang, X. Chen, X. Zhou, Y . Wang, Y . Chang, Y . Li, Y . Zhou, Y . Ye, Z. Liu, and Z. Zhu. Gigaworld-policy: An efficient action-centered world–action model, 2026. URLhttps://arxiv.org/abs/2603.17240
-
[40]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π 0.5: A Vision-Language-Action Model with Open-World Generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[44]
Decoupled Weight Decay Regularization
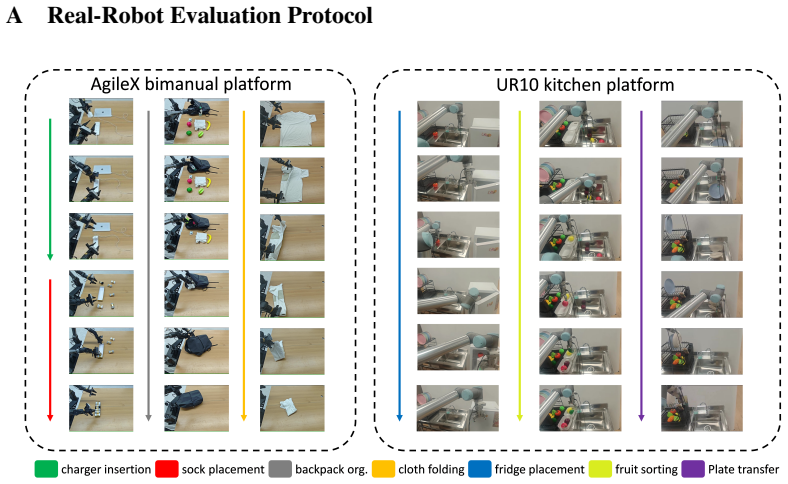
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 12 A Real-Robot Evaluation Protocol Figure 4: Real-robot task sequences on the AgileX bimanual and UR10 kitchen platforms. Colored arrows indicate temporal progress for each task. This appendix provides the hardware, observation, control, randomizatio...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.