Mags-RL: Wearing Multimodal LLMs a Magnifying Glass via Agentic Reinforcement Learning For Complex Scene Reasoning
Pith reviewed 2026-06-29 13:34 UTC · model grok-4.3
The pith
Mags-RL equips MLLMs with an external super-resolution magnifying glass agent that performs autonomous two-round reasoning to improve accuracy on cluttered scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an external super-resolution magnifying glass agent, invoked through agentic RL, lets MLLMs conduct two-round reasoning: an initial pass produces a rationale and autonomously identifies regions of interest without extra annotations, after which the agent crops and upscales those regions so the model can revisit and verify its earlier reasoning to reach a final answer, yielding superior performance on complex scene reasoning benchmarks.
What carries the argument
Two-round reasoning loop in which the first round generates a rationale and selects regions autonomously, and the second round invokes a super-resolution agent to upscale those regions before verification.
If this is right
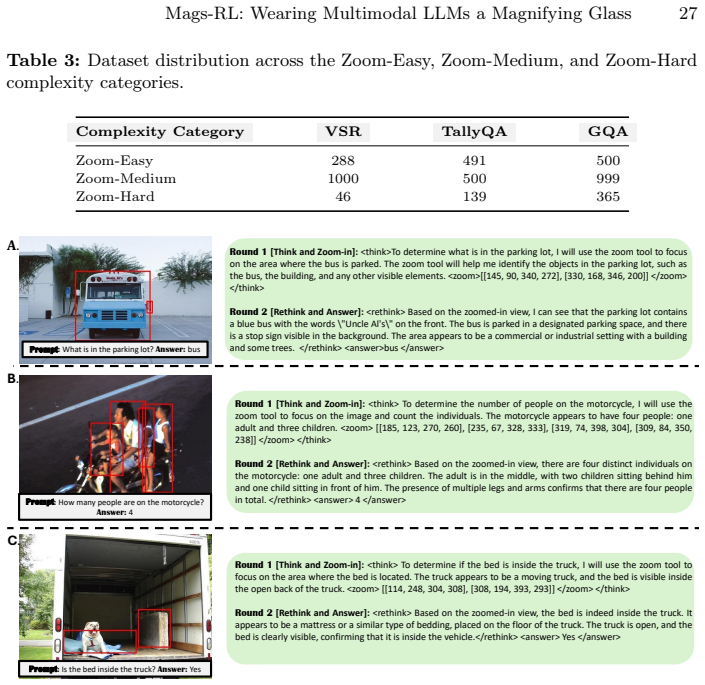
- Superior performance against recent competing methods on VSR, TallyQA, and GQA subsets with precise visual grounding.
- Data-efficient RL training that reaches reasonable performance using only 40 samples via curriculum learning.
- Region identification occurs without relying on additional human annotations such as bounding boxes.
- The two-round structure separates initial rationale generation from detail verification, allowing the model to correct early mistakes after upscaling.
Where Pith is reading between the lines
- The same two-round autonomous selection plus external agent pattern could transfer to other detail-sensitive multimodal tasks such as medical imaging or document understanding.
- Removing the need for pre-provided bounding boxes may encourage future MLLM designs to rely more on internal rationale steps rather than external detectors.
- Curriculum-based training on tiny datasets hints that similar agentic loops might work in low-resource or few-shot multimodal settings beyond the three benchmarks tested.
Load-bearing premise
The initial rationale generation step can reliably identify regions of interest without any additional annotations, and the invoked super-resolution agent will supply fine-grained details that meaningfully improve verification in the second round.
What would settle it
If replacing the super-resolution upscaling step with the original low-resolution crops produces no measurable gain in final answer accuracy on the same test sets, the benefit of the magnifying glass agent would be refuted.
Figures

















read the original abstract
Despite their popularity and success, Multimodal Large Language Models (MLLMs) often struggle to interpret images accurately, which limits their reasoning capability in complex scenarios (e.g., high object density and complex background clutter). Prior work mainly addresses this limitation by incorporating explicit visual cues like bounding boxes that require extra annotations. In addition, the resulting low-resolution crops often miss fine-grained details that MLLMs require for accurate reasoning. Therefore, we propose Mags-RL, an Agentic Reinforcement Learning (RL) framework that equips MLLMs with an external super-resolution "magnifying glass" agent for high-resolution fine-grained inspection. Specifically, the model performs two-round reasoning: in the first round, it generates an initial rationale and autonomously identifies regions of interest without relying on additional annotations; in the second round, it invokes a super-resolution agent to crop and upscale those regions, then revisits and verifies its earlier reasoning to produce the final answer. We also introduce a novel curriculum learning strategy that enables data-efficient RL training, needing as few as only 40 training samples to achieve reasonable performance. Experiments on VSR, TallyQA, and GQA subsets show its superior performance against recent strong competing methods, demonstrating high-quality reasoning with precise visual grounding. Code and weights will be released soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Mags-RL, an Agentic Reinforcement Learning framework that equips Multimodal Large Language Models (MLLMs) with an external super-resolution 'magnifying glass' agent. The approach performs two-round reasoning: the first round generates an initial rationale and autonomously identifies regions of interest without additional annotations; the second round invokes the super-resolution agent to crop and upscale those regions before verifying the rationale to produce the final answer. A novel curriculum learning strategy is said to enable data-efficient RL training with as few as 40 samples. Experiments on subsets of VSR, TallyQA, and GQA are asserted to show superior performance against recent strong competing methods, with high-quality reasoning and precise visual grounding.
Significance. If the empirical claims hold with proper controls and ablations, the work could meaningfully advance MLLM reasoning in high-density, cluttered scenes by avoiding reliance on explicit annotations and using modular external agents for fine-grained inspection. The emphasis on curriculum-based RL for training with only 40 samples represents a potential strength in data efficiency that, if reproducible, would be valuable for practical deployment. The two-round verification structure offers a clear, falsifiable mechanism that could be tested on additional benchmarks.
major comments (2)
- [Abstract] Abstract: The central claim of 'superior performance' on VSR, TallyQA, and GQA subsets is stated without any quantitative results, baseline comparisons, error bars, training hyperparameters, or ablation studies. This absence is load-bearing because the manuscript's contribution rests entirely on the empirical demonstration that the two-round RL process outperforms prior methods; without these data the claim cannot be evaluated.
- [Abstract] Abstract (method description): No formulation is given for the RL components (reward function, state/action space, policy network, or curriculum schedule). This directly affects assessment of the weakest assumption that the first-round rationale can autonomously select regions whose upscaled versions improve second-round verification; without the training mechanics it is impossible to determine whether the policy learns task-relevant selection rather than spurious crops.
minor comments (2)
- [Title] Title: The phrasing 'Wearing Multimodal LLMs a Magnifying Glass' is grammatically awkward and does not clearly convey the intended meaning of equipping the model with an external agent.
- [Abstract] Abstract: The statement 'Code and weights will be released soon' is conventional but could usefully include a specific repository or expected release window.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and agree that the abstract can be strengthened with additional details to better support evaluation of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'superior performance' on VSR, TallyQA, and GQA subsets is stated without any quantitative results, baseline comparisons, error bars, training hyperparameters, or ablation studies. This absence is load-bearing because the manuscript's contribution rests entirely on the empirical demonstration that the two-round RL process outperforms prior methods; without these data the claim cannot be evaluated.
Authors: We agree that the abstract would be more informative with key quantitative results. In the revised version we will add specific accuracy gains on each dataset (e.g., +X% on VSR, +Y% on TallyQA) together with the main baselines used. Full tables with error bars, hyperparameters, and ablations already appear in Sections 4 and 5; the abstract revision will make the central empirical claim evaluable without requiring the reader to consult the body. revision: yes
-
Referee: [Abstract] Abstract (method description): No formulation is given for the RL components (reward function, state/action space, policy network, or curriculum schedule). This directly affects assessment of the weakest assumption that the first-round rationale can autonomously select regions whose upscaled versions improve second-round verification; without the training mechanics it is impossible to determine whether the policy learns task-relevant selection rather than spurious crops.
Authors: The abstract supplies a high-level overview. We will revise it to include a concise formulation of the RL components (reward combining answer correctness and region utility, action space over crop coordinates and scale factors, policy integrated with the MLLM backbone, and the 40-sample curriculum that progressively raises scene complexity). Complete equations and training mechanics are already given in Section 3; the abstract addition will directly address the concern about whether the learned policy selects task-relevant regions. revision: yes
Circularity Check
No circularity: empirical RL framework with no derivations or self-referential predictions
full rationale
The paper describes an empirical agentic RL method for MLLM reasoning with a super-resolution agent and curriculum training on 40 samples. No equations, first-principles derivations, or predictions appear in the provided abstract or described content. The central claims rest on experimental results from RL training rather than any internal definitions, fitted parameters renamed as predictions, or self-citation chains that reduce the result to its inputs by construction. The method is self-contained against external benchmarks via reported performance on VSR, TallyQA, and GQA.
Axiom & Free-Parameter Ledger
invented entities (1)
-
super-resolution magnifying glass agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the AAAI conference on artificial intelligence
Acharya,M.,Kafle,K.,Kanan,C.:Tallyqa:Answeringcomplexcountingquestions. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 8076– 8084 (2019)
2019
-
[2]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al.: Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: Pro- ceedings ofthe 26thannualinternational conference on machine learning.pp
Bengio, Y., Louradour, J., Collobert, R., Weston, J.: Curriculum learning. In: Pro- ceedings ofthe 26thannualinternational conference on machine learning.pp. 41–48 (2009)
2009
-
[7]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., Florence, P., Fu, C., Arenas, M.G., Gopalakrishnan, K., Han, K., Hausman, K., Herzog, A., Hsu, J., Ichter, B., Irpan, A., Joshi, N., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, L., Lee, T.W.E., Levine, S., Lu, Y., Michalewski...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Win- ter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Findings of the association for computational linguistics: ACL 2024 pp
Caffagni, D., Cocchi, F., Barsellotti, L., Moratelli, N., Sarto, S., Baraldi, L., Cornia, M., Cucchiara, R.: The revolution of multimodal large language models: A survey. Findings of the association for computational linguistics: ACL 2024 pp. 13590– 13618 (2024)
2024
-
[10]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleash- ing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
arXiv preprint arXiv:2506.06366 (2025)
Chen, L., Zhang, Y., Feng, J., Chai, H., Zhang, H., Fan, B., Ma, Y., Zhang, S., Li, N., Liu, T., et al.: Ai agent behavioral science. arXiv preprint arXiv:2506.06366 (2025)
-
[12]
arXiv preprint arXiv:2505.09655 (2025)
Chen, X., Zhu, W., Qiu, P., Dong, X., Wang, H., Wu, H., Li, H., Sotiras, A., Wang, Y., Razi, A.: Dra-grpo: Exploring diversity-aware reward adjustment for r1-zero- like training of large language models. arXiv preprint arXiv:2505.09655 (2025)
-
[13]
Chen, X., Zhu, W., Qiu, P., Wang, H., Li, H., Wu, H., Dong, X., Sotiras, A., Wang, Y., Razi, A.: Prompt-ot: An optimal transport regularization paradigm for knowledgepreservationinvision-languagemodeladaptation.In:Proceedingsofthe IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 667–676 (2026)
2026
-
[14]
arXiv preprint arXiv:2512.24052 (2025)
Chen, Y., Zhu, W., Chen, X., Wang, Z., Li, X., Qiu, P., Wang, H., Dong, X., Xiong, Y., Schneider, A., et al.: Aha: Aligning large audio-language models for reasoning hallucinations via counterfactual hard negatives. arXiv preprint arXiv:2512.24052 (2025)
-
[15]
Agent-R1: A Unified and Modular Framework for Agentic Reinforcement Learning
Cheng, M., Ouyang, J., Yu, S., Yan, R., Luo, Y., Liu, Z., Wang, D., Liu, Q., Chen, E.: Agent-r1: Training powerful llm agents with end-to-end reinforcement learning. arXiv preprint arXiv:2511.14460 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Advances in neural information processing systems30(2017)
Christiano, P.F., Leike, J., Brown, T., Martic, M., Legg, S., Amodei, D.: Deep reinforcement learning from human preferences. Advances in neural information processing systems30(2017)
2017
-
[17]
arXiv preprint arXiv:2508.01617 (2025)
Dong, X., Zhu, W., Chen, X., Wang, Z., Qiu, P., Tang, S., Li, X., Wang, Y.: Llada-medv: Exploring large language diffusion models for biomedical image un- derstanding. arXiv preprint arXiv:2508.01617 (2025)
-
[18]
PaLM-E: An Embodied Multimodal Language Model
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
GRIT: Teaching MLLMs to Think with Images
Fan, Y., He, X., Yang, D., Zheng, K., Kuo, C.C., Zheng, Y., Narayanaraju, S.J., Guan, X., Wang, X.E.: Grit: Teaching mllms to think with images. arXiv preprint arXiv:2505.15879 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019) Mags-RL: Wearing Multimodal LLMs a Magnifying Glass 17
2019
-
[21]
arXiv preprint arXiv:2512.16848 (2025)
Jiang, Y., Jiang, L., Teney, D., Moor, M., Brbic, M.: Meta-rl induces exploration in language agents. arXiv preprint arXiv:2512.16848 (2025)
-
[22]
Advances in Neural Information Processing Systems36, 28541–28564 (2023)
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems36, 28541–28564 (2023)
2023
-
[23]
arXiv preprint arXiv:2505.04921 (2025)
Li, Y., Liu, Z., Li, Z., Zhang, X., Xu, Z., Chen, X., Shi, H., Jiang, S., Wang, X., Wang, J., et al.: Perception, reason, think, and plan: A survey on large multimodal reasoning models. arXiv preprint arXiv:2505.04921 (2025)
-
[24]
In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Z., Yang, B., Liu, Q., Ma, Z., Zhang, S., Yang, J., Sun, Y., Liu, Y., Bai, X.: Monkey: Image resolution and text label are important things for large multi- modal models. In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26763–26773 (2024)
2024
-
[25]
Transactions of the Association for Computational Linguistics11, 635–651 (2023)
Liu, F., Emerson, G., Collier, N.: Visual spatial reasoning. Transactions of the Association for Computational Linguistics11, 635–651 (2023)
2023
-
[26]
Advances in neural information processing sys- tems35, 27730–27744 (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022)
2022
-
[27]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Wei, F.: Kosmos- 2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Qiu, P., Zhu, W., Kumar, S., Chen, X., Yang, J., Sun, X., Razi, A., Wang, Y., Soti- ras, A.: Multimodal variational autoencoder: A barycentric view. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 20060–20068 (2025)
2025
-
[29]
In: Proceed- ings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Rasley, J., Rajbhandari, S., Ruwase, O., He, Y.: Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In: Proceed- ings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. pp. 3505–3506 (2020)
2020
-
[30]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Schmalfuss, J., Chang, N., VS, V., Shen, M., Bruhn, A., Alvarez, J.M.: Parc: A quantitative framework uncovering the symmetries within vision language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 25081–25091 (2025)
2025
-
[31]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shao, H., Hu, Y., Wang, L., Song, G., Waslander, S.L., Liu, Y., Li, H.: Lmdrive: Closed-loop end-to-end driving with large language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15120– 15130 (2024)
2024
-
[33]
Advances in Neural Information Processing Systems37, 8612–8642 (2024)
Shao, H., Qian, S., Xiao, H., Song, G., Zong, Z., Wang, L., Liu, Y., Li, H.: Vi- sual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning. Advances in Neural Information Processing Systems37, 8612–8642 (2024)
2024
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
In: European conference on computer vision
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. In: European conference on computer vision. pp. 256–274. Springer (2024) 18 X. Dong et al
2024
-
[36]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Su, Z., Xia, P., Guo, H., Liu, Z., Ma, Y., Qu, X., Liu, J., Li, Y., Zeng, K., Yang, Z., et al.: Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers. arXiv preprint arXiv:2506.23918 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Wang, W., Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Zhu, J., Zhu, X., Lu, L., Qiao, Y., et al.: Enhancing the reasoning ability of multimodal large language models via mixed preference optimization. arXiv preprint arXiv:2411.10442 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
arXiv preprint arXiv:2401.06805 (2024)
Wang,Y.,Chen,W.,Han,X.,Lin,X.,Zhao,H.,Liu,Y.,Zhai,B.,Yuan,J.,You,Q., Yang, H.: Exploring the reasoning abilities of multimodal large language models (mllms): A comprehensive survey on emerging trends in multimodal reasoning. arXiv preprint arXiv:2401.06805 (2024)
-
[40]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[41]
In: 2023 IEEE International Conference on Big Data (BigData)
Wu, J., Gan, W., Chen, Z., Wan, S., Yu, P.S.: Multimodal large language models: A survey. In: 2023 IEEE International Conference on Big Data (BigData). pp. 2247–2256. IEEE (2023)
2023
-
[42]
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Wu, J., Guan, J., Feng, K., Liu, Q., Wu, S., Wang, L., Wu, W., Tan, T.: Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing. arXiv preprint arXiv:2506.09965 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Grounded chain-of-thought for multimodal large language models.arXiv preprint arXiv:2503.12799, 2025
Wu, Q., Yang, X., Zhou, Y., Fang, C., Song, B., Sun, X., Ji, R.: Grounded chain- of-thought for multimodal large language models. arXiv preprint arXiv:2503.12799 (2025)
-
[44]
IEEE Robotics and Automation Letters9(10), 8186–8193 (2024)
Xu, Z., Zhang, Y., Xie, E., Zhao, Z., Guo, Y., Wong, K.Y.K., Li, Z., Zhao, H.: Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters9(10), 8186–8193 (2024)
2024
-
[45]
arXiv preprint arXiv:2405.03162 (2024)
Yang, L., Xu, S., Sellergren, A., Kohlberger, T., Zhou, Y., Ktena, I., Kiraly, A., Ahmed, F., Hormozdiari, F., Jaroensri, T., et al.: Advancing multimodal medical capabilities of gemini. arXiv preprint arXiv:2405.03162 (2024)
-
[46]
arXiv preprint arXiv:2512.17306 (2025)
Yang, W., Xia, Y., Huang, J., Lu, S., Chen, Q.G., Xu, Z., Luo, W., Zhang, K., Wan, Y., Zhang, L.: Deep but reliable: Advancing multi-turn reasoning for thinking with images. arXiv preprint arXiv:2512.17306 (2025)
-
[47]
National Science Review11(12), nwae403 (2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024)
2024
- [48]
-
[49]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Zhang, G., Geng, H., Yu, X., Yin, Z., Zhang, Z., Tan, Z., Zhou, H., Li, Z., Xue, X., Li, Y., et al.: The landscape of agentic reinforcement learning for llms: A survey. arXiv preprint arXiv:2509.02547 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
ACM Computing Surveys (2025)
Zhang,M.,Yang,Y.,Xie,R.,Dhingra,B.,Zhou,S.,Pei,J.:Generalizabilityoflarge language model-based agents: A comprehensive survey. ACM Computing Surveys (2025)
2025
-
[51]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.: Multimodal chain- of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
In: ECCV (2024) Mags-RL: Wearing Multimodal LLMs a Magnifying Glass 19
Zheng, M., Sun, L., Dong, J., Pan, J.: Smfanet: A lightweight self-modulation feature aggregation network for efficient image super-resolution. In: ECCV (2024) Mags-RL: Wearing Multimodal LLMs a Magnifying Glass 19
2024
- [53]
-
[54]
Zhu, W., Li, X., Chen, X., Qiu, P., Vasa, V.K., Dong, X., Chen, Y., Lepore, N., Dumitrascu, O., Su, Y., et al.: Retinalgpt: A retinal clinical preference con- versational assistant powered by large vision-language models. arXiv preprint arXiv:2503.03987 (2025) A Prompt Degisn Details This section details the prompt design for training Mags-RL. Specificall...
-
[55]
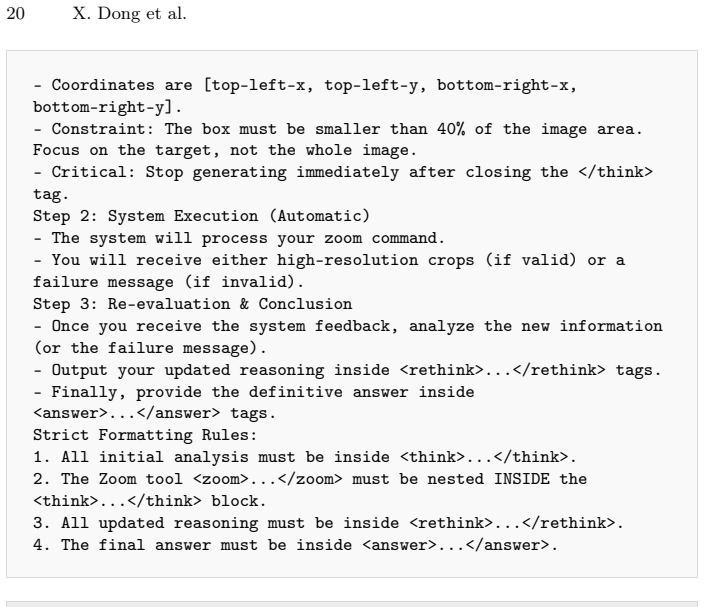
All initial analysis must be inside <think>...</think>
-
[56]
The Zoom tool <zoom>...</zoom> must be nested INSIDE the <think>...</think> block
-
[57]
All updated reasoning must be inside <rethink>...</rethink>
-
[58]
Information Density
The final answer must be inside <answer>...</answer>. Fig.10: The prompt suffix in stage 1 First, think between <think> and </think>, using <zoom>[[x1, y1, x2, y2]]</zoom> if details are unclear. Then, after receiving system feedback, provide your final reasoning in <rethink>... </rethink> and the final answer in <answer>...</answer>. Fig.11: Modified sys...
-
[59]
Object Scale: How small are the key elements relative to the image size?
-
[60]
Visual Clutter: Is the scene crowded, chaotic, or clean?
-
[61]
zoom_score
Text/Detail Level: Is there fine print, tiny textures, or distant background details that are hard to see? Based on your analysis, provide a "zoom_score" from 1 to 10: - Score 1-3 (Simple): - Subject is large, centered, and clearly visible. - No zoom needed. - Score 4-7 (Medium): - A standard scene with multiple objects or moderate distance. - Main elemen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.