Multi-Teacher Knowledge Distillation via Teacher-Informed Mixture Priors
Pith reviewed 2026-06-29 11:17 UTC · model grok-4.3
The pith
Multi-teacher Bayesian knowledge distillation uses a teacher-informed mixture prior to improve student accuracy and quantify uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
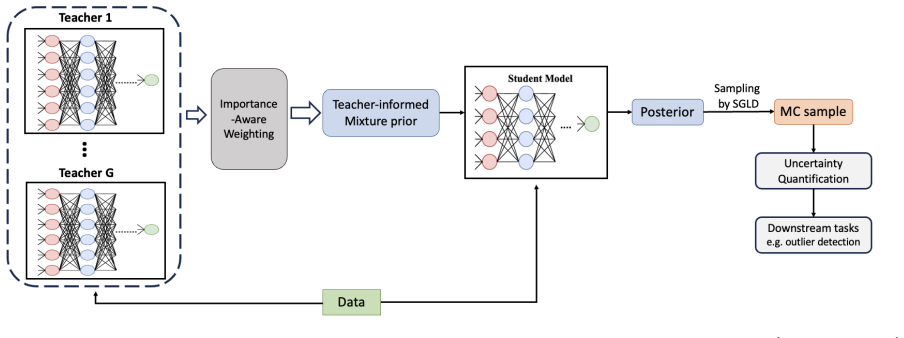
MT-BKD allows a distilled student model to learn from multiple teachers within the Bayesian framework by leveraging a teacher-informed prior that integrates external knowledge from teacher models and task-specific training data. An entropy-based weighting mechanism adaptively adjusts each teacher's influence. This results in enhanced interpretability of the learning process, improved predictive accuracy, and provision of uncertainty quantification.
What carries the argument
The teacher-informed mixture prior, which serves as the mechanism to integrate knowledge from multiple teachers and data in the Bayesian distillation process.
If this is right
- The student model effectively combines expertise from diverse teachers without one dominating.
- Predictions include uncertainty measures suitable for applications needing reliability assessment.
- Performance improves on tasks like image classification and protein prediction compared to standard distillation.
- The method scales to complex models including large language models.
- Robustness and generalization are enhanced through the mixture prior.
Where Pith is reading between the lines
- This approach might help in scenarios where teachers disagree by letting the prior and weighting resolve conflicts.
- Extending the entropy weighting to other Bayesian models could improve ensemble methods in statistics.
- Applying MT-BKD to sequential data or time-series tasks could test its adaptability further.
Load-bearing premise
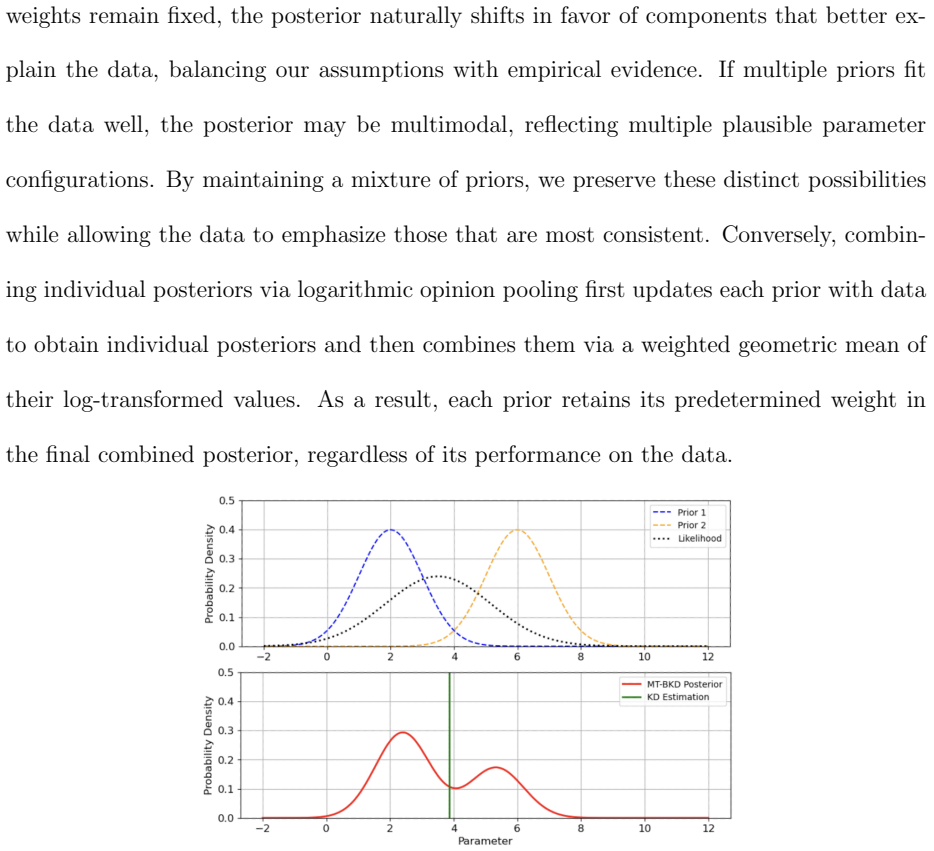
The teacher-informed prior integrates knowledge from the teachers and data in a way that improves results without adding biases or needing heavy tuning.
What would settle it
Running MT-BKD and standard distillation on a held-out real-world dataset and finding no gains in accuracy or poorer uncertainty calibration would challenge the claim.
Figures
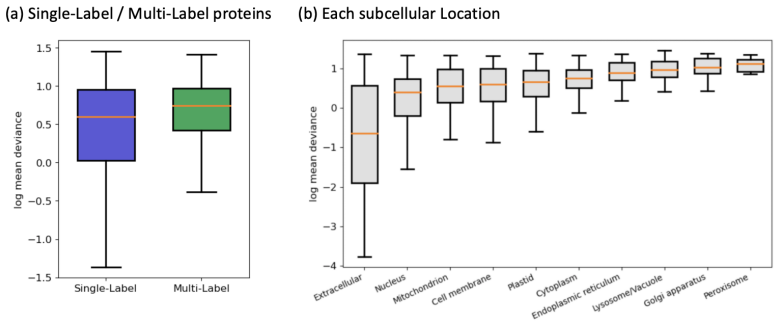

read the original abstract
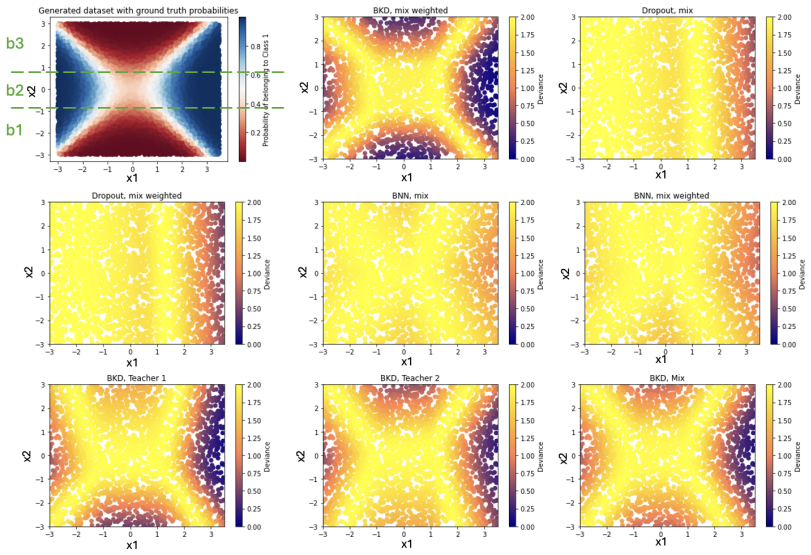
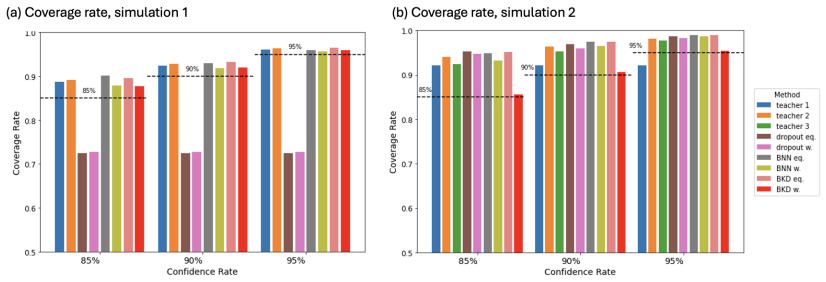
Knowledge distillation is a powerful method for model compression, enabling the efficient deployment of complex deep learning models (teachers), including large language models. However, its underlying statistical mechanisms remain unclear, and uncertainty evaluation is often overlooked, especially in real-world scenarios requiring diverse teacher expertise. To address these challenges, we introduce \textit{Multi-Teacher Bayesian Knowledge Distillation} (MT-BKD), where a distilled student model learns from multiple teachers within the Bayesian framework. Our approach leverages Bayesian inference to capture inherent uncertainty in the distillation process. We introduce a teacher-informed prior, integrating external knowledge from teacher models and task-specific training data, offering better generalization, robustness, and scalability. Additionally, an entropy-based weighting mechanism adaptively adjusts each teacher's influence, allowing the student to combine multiple sources of expertise effectively. MT-BKD enhances the interpretability of the student model's learning process, improves predictive accuracy, and provides uncertainty quantification. We validate MT-BKD on both synthetic and real-world tasks, including protein subcellular location prediction and image classification. Our experiments show improved performance and robust uncertainty quantification, highlighting the strengths of our MT-BKD framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-Teacher Bayesian Knowledge Distillation (MT-BKD), a Bayesian framework for distilling knowledge from multiple teachers to a student model. It introduces a teacher-informed mixture prior that integrates external knowledge from teachers and task-specific data, combined with an entropy-based weighting mechanism to adaptively balance teacher influence. The method is claimed to improve generalization, robustness, scalability, interpretability of the learning process, predictive accuracy, and uncertainty quantification. Validation is reported on synthetic data plus two real tasks (protein subcellular location prediction and image classification), with experiments showing improved performance and robust UQ relative to standard distillation.
Significance. If the central claims hold, the work supplies a statistically grounded extension of knowledge distillation to the multi-teacher setting, explicitly addressing uncertainty quantification that is frequently omitted in the literature. The teacher-informed prior and entropy weighting provide a mechanism for combining heterogeneous expertise without manual tuning, which could be relevant for compressing large models including LLMs. The empirical validation on both synthetic and applied tasks (protein localization, image classification) supplies concrete evidence of practical utility.
minor comments (3)
- The abstract and introduction would benefit from a concise statement of the precise form of the teacher-informed mixture prior (e.g., whether it is a finite mixture of teacher posteriors or a hierarchical construction) and the exact entropy-weighting formula, to allow readers to assess identifiability and computational cost without reading the full methods section.
- In the experimental section, clarify the baseline implementations (standard KD, ensemble averaging, etc.) and report whether the same hyper-parameter search budget was used for all methods; this would strengthen the claim of improved generalization.
- Notation for the student posterior and the mixture weights should be introduced once in a dedicated notation table or paragraph to avoid repeated re-definition across sections.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation of minor revision. The referee's summary correctly identifies the core elements of MT-BKD, including the teacher-informed mixture prior and entropy-based weighting, as well as the empirical validation on synthetic and real-world tasks.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents MT-BKD as a Bayesian framework incorporating a teacher-informed mixture prior and entropy-based weighting to integrate multiple teacher models. The central claims rest on this construction plus empirical validation on synthetic data and real tasks (protein localization, image classification). No load-bearing step reduces a prediction to a fitted quantity by definition, invokes self-citation as the sole justification for uniqueness or ansatz, or renames a known result. The derivation is self-contained against external benchmarks with independent content from the Bayesian prior and weighting scheme.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bates, D. M. and D. G. Watts (1988). Nonlinear Regression Analysis and Its Applications . Wiley Series in Probability and Statistics. Wiley
1988
-
[2]
Bauer, B. and M. Kohler (2019). On deep learning as a remedy for the curse of dimensionality in nonparametric regression. The Annals of Statistics\/ 47\/ (4), 2261--2285
2019
-
[3]
Bernardo, J. M. (1979). Reference posterior distributions for bayesian inference. Journal of the Royal Statistical Society Series B: Statistical Methodology\/ 41\/ (2), 113--128
1979
-
[4]
Cornebise, K
Blundell, C., J. Cornebise, K. Kavukcuoglu and D. Wierstra (2015). Weight uncertainty in neural network. In International conference on machine learning , pp.\ 1613--1622. PMLR
2015
-
[5]
Braulke, T. and J. S. Bonifacino (2009). Sorting of lysosomal proteins. Biochimica et Biophysica Acta (BBA)-Molecular Cell Research\/ 1793\/ (4), 605--614
2009
-
[6]
Chen, D., J.-P. Mei, H. Zhang, C. Wang, Y. Feng and C. Chen (2022). Knowledge distillation with the reused teacher classifier. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp.\ 11933--11942
2022
-
[7]
Chen, M.-H., J. G. Ibrahim and Q.-M. Shao (2000). Power prior distributions for generalized linear models. Journal of Statistical Planning and Inference\/ 84\/ (1-2), 121--137
2000
-
[8]
Dingwall, C. and R. A. Laskey (1991). Nuclear targeting sequences—a consensus? Trends in biochemical sciences\/ 16 , 478--481
1991
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner et al. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929\/
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[10]
Ma and Y
Fan, J., C. Ma and Y. Zhong (2020). A selective overview of deep learning. Statistical science: a review journal of the Institute of Mathematical Statistics\/ 36\/ (2), 264
2020
-
[11]
Fang, L., Y. Chen, W. Zhong and P. Ma (2024). Bayesian knowledge distillation: A bayesian perspective of distillation with uncertainty quantification. In Proceedings of the 41st International Conference on Machine Learning , pp.\ 12935--12956. PMLR
2024
-
[12]
Faraway, J. J. (2016). Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models\/ (Second Edition ed.). Chapman & Hall/CRC Texts in Statistical Science. CRC Press
2016
-
[13]
Suzuki, G
Fukuda, T., M. Suzuki, G. Kurata, S. Thomas, J. Cui and B. Ramabhadran (2017). Efficient knowledge distillation from an ensemble of teachers. In Interspeech , pp.\ 3697--3701
2017
-
[14]
Gal, Y. and Z. Ghahramani (2016). Dropout as a B ayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning , pp.\ 1050--1059. PMLR
2016
-
[15]
Garthwaite, P. H., J. B. Kadane and A. O'Hagan (2005). Statistical methods for eliciting probability distributions. Journal of the American statistical Association\/ 100\/ (470), 680--701
2005
-
[16]
Gelman, A., J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari and D. B. Rubin (2013). Bayesian Data Analysis\/ (3rd ed.). Boca Raton: Chapman and Hall/CRC
2013
-
[17]
Gelman, A., J. B. Carlin, H. S. Stern and D. B. Rubin (1995). Bayesian Data Analysis . Chapman and Hall/CRC
1995
-
[18]
Genest, C., K. J. McConway and M. J. Schervish (1986). Characterization of externally bayesian pooling operators. The Annals of Statistics\/ , 487--501
1986
-
[19]
Girolami, M. and B. Calderhead (2011). Riemann manifold L angevin and H amiltonian M onte C arlo methods. Journal of the Royal Statistical Society Series B: Statistical Methodology\/ 73\/ (2), 123--214
2011
-
[20]
Bengio and A
Goodfellow, I., Y. Bengio and A. Courville (2016). Deep Learning . MIT Press
2016
-
[21]
Gou, J., B. Yu, S. J. Maybank and D. Tao (2021). Knowledge distillation: A survey. International Journal of Computer Vision\/ 129\/ (6), 1789--1819
2021
-
[22]
Gui, S., Z. Wang, J. Chen, X. Zhou, C. Zhang and Y. Cao (2023). Mt4mtl-kd: a multi-teacher knowledge distillation framework for triplet recognition. IEEE Transactions on Medical Imaging\/
2023
-
[23]
Kohler, A
Gy \"o rfi, L., M. Kohler, A. Krzyzak and H. Walk (2006). A distribution-free theory of nonparametric regression . Springer Science & Business Media
2006
-
[24]
Zhou and X
He, M., X. Zhou and X. Wang (2024). Glycosylation: mechanisms, biological functions and clinical implications. Signal Transduction and Targeted Therapy\/ 9\/ (1), 194
2024
-
[25]
Distilling the Knowledge in a Neural Network
Hinton, G., O. Vinyals, J. Dean and others (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531\/
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Horowitz, J. L. and E. Mammen (2007). Rate-optimal estimation for a general class of nonparametric regression models with unknown link functions
2007
-
[27]
Stein, D
Huang, D., N. Stein, D. B. Rubin and S. Kou (2020). Catalytic prior distributions with application to generalized linear models. Proceedings of the National Academy of Sciences\/ 117\/ (22), 12004--12010
2020
-
[28]
Hung, M.-C. and W. Link (2011). Protein localization in disease and therapy. Journal of cell science\/ 124\/ (20), 3381--3392
2011
-
[29]
G., M.-H
Ibrahim, J. G., M.-H. Chen, Y. Gwon and F. Chen (2015). The power prior: theory and applications. Statistics in medicine\/ 34\/ (28), 3724--3749
2015
-
[30]
Kondratyuk, D., L. Yu, X. Gu, J. Lezama, J. Huang, R. Hornung et al. (2023). Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125\/
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Rathod, K
Korattikara Balan, A., V. Rathod, K. P. Murphy and M. Welling (2015). Bayesian dark knowledge. Advances in neural information processing systems\/ 28
2015
- [32]
-
[33]
Lin, Z., H. Akin, R. Rao, B. Hie, Z. Zhu, W. Lu et al. (2023). Evolutionary-scale prediction of atomic-level protein structure with a language model. Science\/ 379\/ (6637), 1123--1130
2023
-
[34]
Zhang and J
Liu, Y., W. Zhang and J. Wang (2020). Adaptive multi-teacher multi-level knowledge distillation. Neurocomputing\/ 415 , 106--113
2020
-
[35]
Lu, J., T. Wu, B. Zhang, S. Liu, W. Song, J. Qiao et al. (2021). Types of nuclear localization signals and mechanisms of protein import into the nucleus. Cell communication and signaling\/ 19\/ (1), 60
2021
-
[36]
Courtroom Analogy: New Perspective on Uncertainty-Aware Classification
Malinin, A., B. Mlodozeniec and M. Gales (2019). Ensemble distribution distillation. arXiv preprint arXiv:1905.00076\/
-
[37]
McLachlan, G. J. and D. Peel (2000). Finite Mixture Models . Wiley-Interscience
2000
-
[38]
Menon, A. K., A. S. Rawat, S. Reddi, S. Kim and S. Kumar (2021). A statistical perspective on distillation. In International Conference on Machine Learning , pp.\ 7632--7642. PMLR
2021
-
[39]
Nezafat, M
Owji, H., N. Nezafat, M. Negahdaripour, A. Hajiebrahimi and Y. Ghasemi (2018). A comprehensive review of signal peptides: Structure, roles, and applications. European journal of cell biology\/ 97\/ (6), 422--441
2018
-
[40]
Peng, X., Q. Bai, X. Xia, Z. Huang, K. Saenko and B. Wang (2019). Moment matching for multi-source domain adaptation. In Proceedings of the IEEE/CVF international conference on computer vision , pp.\ 1406--1415
2019
-
[41]
Phuong, M. and C. Lampert (2019). Towards understanding knowledge distillation. In International conference on machine learning , pp.\ 5142--5151. PMLR
2019
-
[42]
(2023, May)
Ray, S. (2023, May). Samsung bans chatgpt among employees after sensitive code leak. Forbes\/ . Published May 2, 2023
2023
-
[43]
Robbins, H. E. (1992). An empirical bayes approach to statistics. In Breakthroughs in Statistics: Foundations and basic theory , pp.\ 388--394. Springer
1992
-
[44]
Kerssen, M
Sch \"a fer, A., D. Kerssen, M. Veenhuis, W.-H. Kunau and W. Schliebs (2004). Functional similarity between the peroxisomal pts2 receptor binding protein pex18p and the n-terminal half of the pts1 receptor pex5p. Molecular and cellular biology\/ 24\/ (20), 8895--8906
2004
-
[45]
Schmidt-Hieber, J. (2020). Nonparametric regression using deep neural networks with relu activation function
2020
-
[46]
Shao, J. (1993). Linear model selection by cross-validation. Journal of the American statistical Association\/ 88\/ (422), 486--494
1993
-
[47]
Shen, Y., L. Xu, Y. Yang, Y. Li and Y. Guo (2022). Self-distillation from the last mini-batch for consistency regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp.\ 11943--11952
2022
-
[48]
Spiegelhalter, D. J., N. G. Best, B. P. Carlin and A. Linde (2014). The deviance information criterion: 12 years on. Journal of the Royal Statistical Society Series B: Statistical Methodology\/ 76\/ (3), 485--493
2014
-
[49]
Thumuluri, V., J. J. Almagro Armenteros, A. R. Johansen, H. Nielsen and O. Winther (2022). Deeploc 2.0: multi-label subcellular localization prediction using protein language models. Nucleic acids research\/ 50\/ (W1), W228--W234
2022
-
[50]
Touvron, H., T. Lavril, G. Izacard, X. Martinet, H. Jegou, E. Grave et al. (2024, July). The llama 3 herd of models. arXiv preprint arXiv:2407.21783\/
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
UniProt Consortium, T. (2018). Uniprot: the universal protein knowledgebase. Nucleic acids research\/ 46\/ (5), 2699--2699
2018
-
[52]
Jalaian and B
Vadera, M., B. Jalaian and B. Marlin (2020). Generalized B ayesian posterior expectation distillation for deep neural networks. In Conference on Uncertainty in Artificial Intelligence , pp.\ 719--728. PMLR
2020
-
[53]
Vicol, J
Wang, K.-C., P. Vicol, J. Lucas, L. Gu, R. Grosse and R. Zemel (2018). Adversarial distillation of B ayesian neural network posteriors. In International conference on machine learning , pp.\ 5190--5199. PMLR
2018
-
[54]
Welling, M. and Y. W. Teh (2011). Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the 28th international conference on machine learning (ICML-11) , pp.\ 681--688
2011
-
[55]
Chiu and K.-H
Wu, M.-C., C.-T. Chiu and K.-H. Wu (2019). Multi-teacher knowledge distillation for compressed video action recognition on deep neural networks. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pp.\ 2202--2206. IEEE
2019
-
[56]
Yogev, O. and O. Pines (2011). Dual targeting of mitochondrial proteins: mechanism, regulation and function. Biochimica et Biophysica Acta (BBA)-Biomembranes\/ 1808\/ (3), 1012--1020
2011
-
[57]
You, S., C. Xu, C. Xu and D. Tao (2017). Learning from multiple teacher networks. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining , pp.\ 1285--1294
2017
-
[58]
Zagoruyko, S. and N. Komodakis (2016). Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv preprint arXiv:1612.03928\/
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[59]
Zhang, A., Z. C. Lipton, M. Li and A. J. Smola (2021). Dive into Deep Learning . Cambridge University Press
2021
-
[60]
Chen and C
Zhang, H., D. Chen and C. Wang (2022). Confidence-aware multi-teacher knowledge distillation. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pp.\ 4498--4502. IEEE
2022
-
[61]
Zhao, B., Q. Cui, R. Song, Y. Qiu and J. Liang (2022). Decoupled knowledge distillation. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pp.\ 11953--11962
2022
-
[62]
Wang and X
Zhao, S., X. Wang and X. Wei (2024). Mitigating accuracy-robustness trade-off via balanced multi-teacher adversarial distillation. IEEE Transactions on Pattern Analysis & Machine Intelligence\/ (01), 1--14
2024
-
[63]
and Lempitsky, V
Ganin, Y. and Lempitsky, V. (2015). Unsupervised domain adaptation by backpropagation. In International conference on machine learning , pages 1180--1189. PMLR
2015
-
[64]
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 770--778
2016
-
[65]
Lin, Z., Akin, H., Rao, R., Hie, B., Zhu, Z., Lu, W., Smetanin, N., Verkuil, R., Kabeli, O., Shmueli, Y., et al. (2023). Evolutionary-scale prediction of atomic-level protein structure with a language model. Science , 379(6637):1123--1130
2023
-
[66]
Y., et al
Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., Ng, A. Y., et al. (2011). Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning , volume 2011, page 4. Granada
2011
-
[67]
Peng, X., Bai, Q., Xia, X., Huang, Z., Saenko, K., and Wang, B. (2019). Moment matching for multi-source domain adaptation. In Proceedings of the IEEE/CVF international conference on computer vision , pages 1406--1415
2019
-
[68]
Shridhar, K., Laumann, F., and Liwicki, M. (2019). A comprehensive guide to B ayesian convolutional neural network with variational inference. arxiv 2019. arXiv preprint arXiv:1901.02731
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[69]
E., Wang, Y., Huang, H., McGarvey, P
Suzek, B. E., Wang, Y., Huang, H., McGarvey, P. B., Wu, C. H., and Consortium, U. (2015). Uniref clusters: a comprehensive and scalable alternative for improving sequence similarity searches. Bioinformatics , 31(6):926--932
2015
-
[70]
Campbell, J. I. and S. Austin (2002). Effects of response time deadlines on adults' strategy choices for simple addition. Memory & Cognition\/ 30\/ (6), 988--994
2002
-
[71]
Chi, M. T., P. J. Feltovich, and R. Glaser (1981). Categorization and representation of physics problems by experts and novices. Cognitive science\/ 5\/ (2), 121--152
1981
-
[72]
Schubert, C. C., T. K. Denmark, B. Crandall, A. Grome, and J. Pappas (2013). Characterizing novice-expert differences in macrocognition: an exploratory study of cognitive work in the emergency department. Annals of emergency medicine\/ 61\/ (1), 96--109
2013
-
[73]
write newline
" write newline "" before.all 'output.state := FUNCTION article output.bibitem format.authors "author" output.check author format.key output output.year.check new.block format.title "title" output.check new.block crossref missing format.jour.vol output format.article.crossref output.nonnull format.pages output if new.block note output fin.entry FUNCTION b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.