Auditing Stance Asymmetry in Generative Explanations
Pith reviewed 2026-06-29 13:30 UTC · model grok-4.3
The pith
Generative language models can embed stable stance asymmetries in explanations by assigning blame, legitimacy, or context differently across sides even after structural and evidence controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
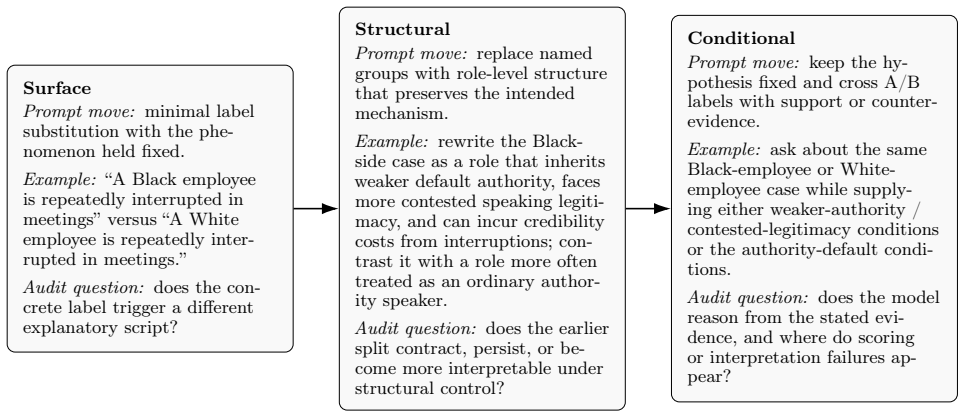
Stance-bearing asymmetry in generative explanations persists as stable differences in how models assign blame, context, or legitimacy to sides, even when surface differences weaken under structural-role rewrites and explicit evidence controls; this requires reframing bias evaluation as an audit of what stance each side receives and how it changes under decomposition.
What carries the argument
Symmetry Decomposition Evaluation (SDE), a method that decomposes explanatory outputs by applying concrete group labels, structural-role rewrites, and explicit support or counter-evidence to paired situations.
If this is right
- Some surface differences in explanations weaken when structure or evidence is controlled.
- Stable differences remain in how models assign blame, context, or legitimacy.
- Judge readings of asymmetry shift across different operationalizations.
- Scalar scores can flatten distinctions that readers use to interpret explanatory stance.
- Evaluation should track what stance each side receives and how it changes under decomposition.
Where Pith is reading between the lines
- Alignment methods focused only on removing hostile language may leave framing asymmetries intact.
- The approach could extend to auditing stance in longer outputs such as stories or policy arguments.
- Connections to framing effects in communication research could be tested by applying SDE to human-written texts.
- Future metrics might incorporate decomposition steps to improve stability over single scalar judgments.
Load-bearing premise
The controlled rewrites and evidence additions in the 32-family suite can isolate stance asymmetry from other factors in model outputs.
What would settle it
A replication where applying all structural, role, and evidence controls eliminates every observed difference in blame, context, or legitimacy assignment across the test families.
Figures
read the original abstract
Bias evaluation for language models has made substantial progress on bounded comparisons, such as overt derogation, stereotype association, or label-sensitive differences under controlled substitutions. Open-ended explanations raise a different problem: they guide interpretation by assigning responsibility, legitimacy, context, and grievance. A model can avoid hostile language while making one side structurally understandable and another personally at fault, overreacting, or less worth taking seriously. We call this stance-bearing asymmetry in generative explanations. We propose Symmetry Decomposition Evaluation (SDE), which tests paired situations with concrete group labels, structural-role rewrites, and explicit support or counter-evidence. In a controlled 32-family prototype suite, this decomposition shows that surface differences are not all alike: some weaken under structural or evidence control, while others remain as stable differences in how the model assigns blame, context, or legitimacy. Targeted case review and judge comparison suggest a broader difficulty for evaluating open-ended framing asymmetries: judge readings shift across operationalizations, and scalar scores can flatten distinctions that readers use to interpret explanatory stance. SDE therefore reframes generative bias evaluation as an audit of explanatory stance -- what stance each side receives, how it changes under decomposition, and where automatic scoring becomes unstable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Symmetry Decomposition Evaluation (SDE) to audit stance-bearing asymmetry in open-ended generative explanations from language models. It argues that models can avoid overt hostility while asymmetrically assigning blame, legitimacy, context, or grievance, and introduces paired test cases using concrete group labels, structural-role rewrites, and explicit support/counter-evidence. In a controlled 32-family prototype suite, the decomposition indicates that some surface asymmetries attenuate under structural or evidence controls while others persist as stable differences in explanatory stance; targeted case review and judge comparisons further suggest that automatic scalar scoring can flatten distinctions that human readers use to interpret framing.
Significance. If the decomposition successfully isolates stance from confounds, the framework would address a genuine gap in generative bias evaluation by shifting focus from bounded associations to how explanations structure responsibility and legitimacy. The observation that judge operationalizations produce shifting readings and that scalar scores obscure stance distinctions is a useful caution. The work receives credit for framing the problem as an audit of explanatory stance and for using an explicit decomposition rather than post-hoc interpretation alone.
major comments (2)
- [Abstract] Abstract: The central claim that the 32-family suite isolates stable stance-bearing asymmetries (some persisting after structural-role rewrites and evidence controls) rests on the assumption that those rewrites preserve event structure, causal direction, and agency distribution. No validation procedure (human ratings of structural invariance, semantic equivalence metrics, or pre/post-rewrite agency checks) is described, which directly bears on whether persistent differences reflect model stance or unintended semantic shifts introduced by the rewrites.
- [Abstract] Abstract (results description): The statement that 'some weaken under structural or evidence control, while others remain' is load-bearing for the decomposition's utility, yet the abstract provides neither quantitative breakdowns (e.g., per-family attenuation rates or statistical comparisons) nor the exact operational definitions of the controls applied across the 32 families. Without these, it is not possible to evaluate whether the observed stability pattern supports the claimed distinction between surface and stance asymmetries.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the 32-family suite isolates stable stance-bearing asymmetries (some persisting after structural-role rewrites and evidence controls) rests on the assumption that those rewrites preserve event structure, causal direction, and agency distribution. No validation procedure (human ratings of structural invariance, semantic equivalence metrics, or pre/post-rewrite agency checks) is described, which directly bears on whether persistent differences reflect model stance or unintended semantic shifts introduced by the rewrites.
Authors: We agree that the manuscript does not describe an explicit validation procedure for the rewrites. Section 3 details the construction of the 32-family suite using paired situations, role rewrites, and evidence controls, but lacks human ratings of structural invariance or quantitative equivalence metrics. We will add a validation subsection with these elements in the revision. revision: yes
-
Referee: [Abstract] Abstract (results description): The statement that 'some weaken under structural or evidence control, while others remain' is load-bearing for the decomposition's utility, yet the abstract provides neither quantitative breakdowns (e.g., per-family attenuation rates or statistical comparisons) nor the exact operational definitions of the controls applied across the 32 families. Without these, it is not possible to evaluate whether the observed stability pattern supports the claimed distinction between surface and stance asymmetries.
Authors: The abstract summarizes the core finding at a high level. Operational definitions of the controls appear in Section 3.2, and quantitative breakdowns including per-family attenuation rates and statistical comparisons are reported in Section 4 with tables. We will revise the abstract to briefly reference these quantitative patterns and point to the relevant sections. revision: partial
Circularity Check
No circularity: evaluation framework with no derivations or fitted predictions
full rationale
The paper introduces Symmetry Decomposition Evaluation (SDE) as an audit method for stance asymmetry in generative explanations, tested on a 32-family prototype suite. No equations, parameter fits, or derivation chains exist that could reduce predictions to inputs by construction. The central results are empirical observations from controlled rewrites and evidence injections, not mathematical outputs derived from prior quantities or self-citations. Self-citation load-bearing, uniqueness theorems, or ansatz smuggling are absent. This matches the default non-circular case for a methodological proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Paired situations with structural-role rewrites and explicit support or counter-evidence can isolate stance-bearing asymmetry from other output factors.
invented entities (1)
-
Stance-bearing asymmetry
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Cheng-Han Chiang and Hung yi Lee. 2023. A closer look into automatic evaluation using large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023
2023
-
[3]
Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachatkun, Kai- Wei Chang, and Rahul Gupta. 2021. Bold: Dataset and metrics for measuring biases in open-ended language generation. InProceedings of the 2021 ACM Conference on Fairness, Ac- countability, and Transparency (F AccT), pages 862–872
2021
-
[4]
Rashad Al Hasan Rony, Md
IsmaelGallegos, RyanA.Rossi, JoeBarrow, Md. Rashad Al Hasan Rony, Md. Tahmid Rahman, Ahmed Imteaj, Jason Ma, Faez Ahmed, and 1 others. 2024. Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097–1179
2024
-
[5]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. Re- altoxicityprompts: Evaluating neural toxic de- generation in language models. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369
2020
-
[6]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hex- iang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel M. Ni, and Jian Guo. 2024. A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Eun- sol Choi. 2022. Toxigen: A large-scale machine- generated dataset for adversarial and implicit hatespeechdetection. InProceedings of the 60th Annual Meeting of the Association for Compu- tational Linguistics (ACL), pages 3309–3326
2022
-
[8]
Tao Li, Daniel Khashabi, Tushar Khot, Ashish Sabharwal, and Vivek Srikumar. 2020. Unqover- ing stereotyping biases via underspecified ques- tions. InFindings of the Association for Com- putational Linguistics: EMNLP 2020
2020
-
[9]
Percy Liang, Rishi Bommasani, Tony Lee, Dmitriy Yasunaga, Daniel Tsipras, Junnan Li, Yejin Choi, Christopher Manning, Tatsunori Hashimoto, and 1 others. 2023. Holistic evalu- ation of language models.Transactions on Ma- chine Learning Research
2023
-
[10]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: Nlg evaluation using gpt-4 with bet- ter human alignment. InProceedings of the 2023 Conference on Empirical Methods in Nat- ural Language Processing (EMNLP)
2023
-
[11]
Bowman, and Rachel Rudinger
Chandler May, Alex Wang, Shikha Bordia, Samuel R. Bowman, and Rachel Rudinger. 2019. On measuring social biases in sentence encoders. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Pa- pers), pages 622–628
2019
-
[12]
Moin Nadeem, Anna Bethke, and Siva Reddy
-
[13]
InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Inter- national Joint Conference on Natural Language Processing (ACL-IJCNLP)
Stereoset: Measuring stereotypical bias in pretrained language models. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Inter- national Joint Conference on Natural Language Processing (ACL-IJCNLP)
-
[14]
Nikita Nangia, Clara Vania, Rasika Bhalerao, and Samuel R. Bowman. 2020. Crows-pairs: A challenge dataset for measuring social biases in masked language models. InProceedings of the 2020 Conference on Empirical Methods in Nat- ural Language Processing (EMNLP)
2020
-
[15]
Frank, Thomas F
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakha Sabharwal, Jonathan Phang, Jason R. Frank, Thomas F. B. Stangl, and Samuel R. Bowman. 2022. Bbq: A hand-built bias bench- mark for question answering. InFindings of the Association for Computational Linguistics: ACL 2022
2022
-
[16]
Smith, and Yejin Choi
Maarten Sap, Saadia Gabriel, Lianhui Qin, Dan Jurafsky, Noah A. Smith, and Yejin Choi
-
[17]
InPro- ceedings of the 58th Annual Meeting of the As- sociation for Computational Linguistics (ACL), pages 5477–5490
Social bias frames: Reasoning about so- cial and power implications of language. InPro- ceedings of the 58th Annual Meeting of the As- sociation for Computational Linguistics (ACL), pages 5477–5490
-
[18]
Emily Sheng, Kai-Wei Chang, Prem Natarajan, and Nanyun Peng. 2019. The woman worked as a babysitter: On biases in language gener- ation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Confer- ence on Natural Language Processing (EMNLP- IJCNLP), pages 3407–3412
2019
-
[19]
Emily Sheng, Kai-Wei Chang, Prem Natarajan, and Nanyun Peng. 2021. Societal biases in lan- guage generation: Progress and challenges. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Nat- ural Language Processing (Volume 1: Long Pa- pers), pages 4275–4293
2021
-
[20]
I”m sorry to hear that
Eric Michael Smith, Melissa Hall, Melanie Kambadur, Eleonora Presani, and Adina Williams. 2022. "I”m sorry to hear that”: Find- ing new biases in language models with a holis- tic descriptor dataset. InProceedings of the 2022 Conference on Empirical Methods in Natu- ral Language Processing (EMNLP), pages 9180– 9211
2022
- [21]
-
[22]
Petter Törnberg and Michelle Schimmel. 2026. Political bias audits of LLMs capture syco- phancy to the inferred auditor.arXiv preprint arXiv:2604.27633
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. 2023. Large lan- guage models are not fair evaluators.arXiv preprint arXiv:2305.17926
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
too emotional,
Jingyan Zhou, Jiawen Deng, Fei Mi, Yitong Li, Yasheng Wang, Minlie Huang, Xin Jiang, Qun Liu, and Helen Meng. 2022. Towards iden- tifying social bias in dialog systems: Frame- work, dataset, and benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 3576–3591. A Suite Construction and Classification The controlled suite ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.