Confidence-Orchestrated Self-Evolution against Uncertain LLM Feedback
Pith reviewed 2026-06-29 12:07 UTC · model grok-4.3
The pith
COSE uses an LLM's intrinsic confidence to weight its self-generated training updates and reduce errors from uncertain self-judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
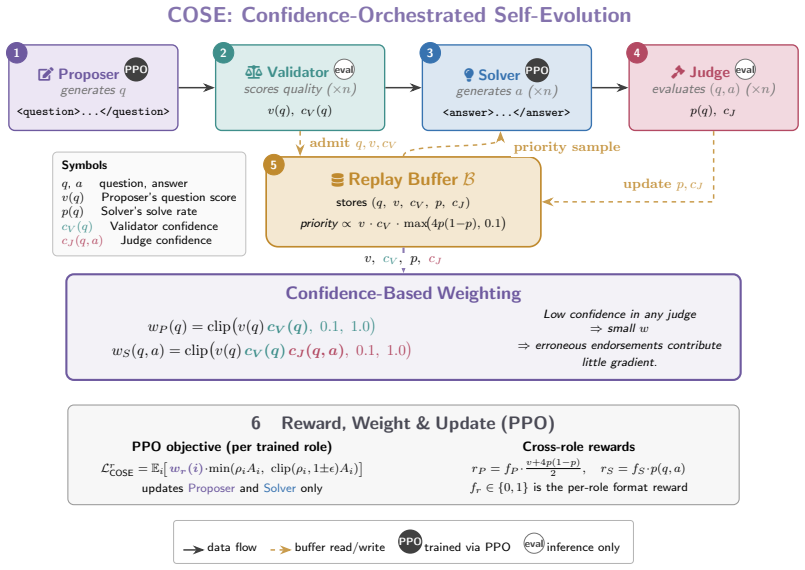
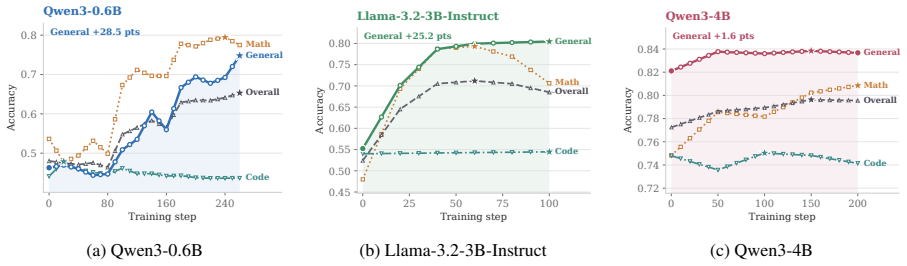
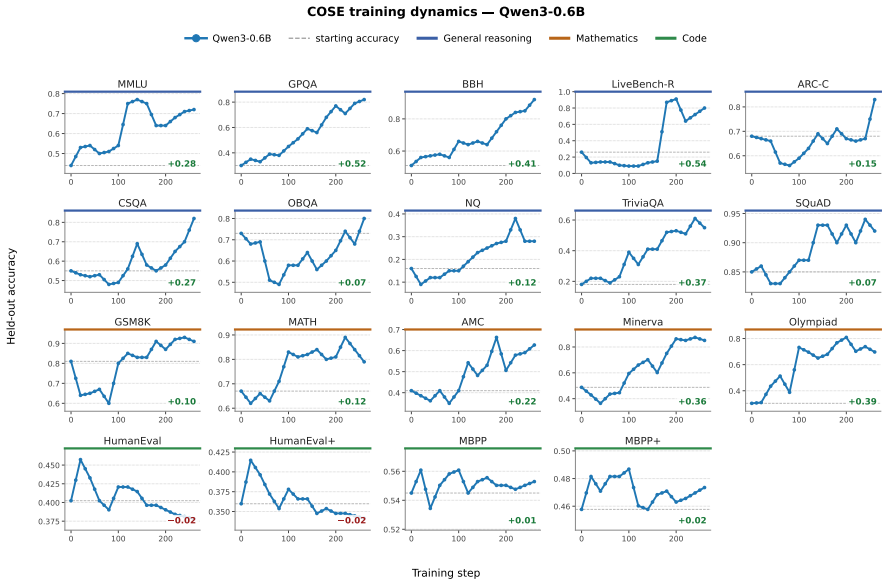
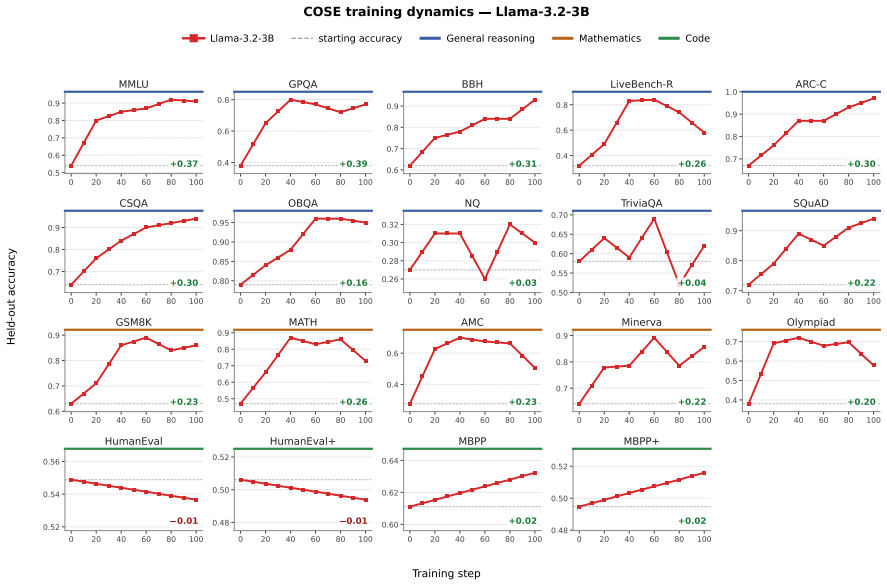
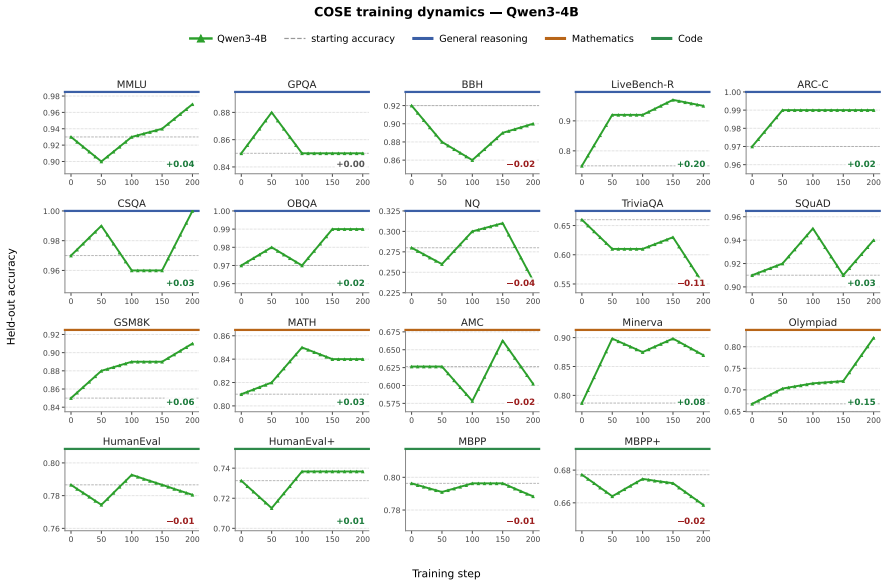
COSE introduces confidence-weighted PPO updates and confidence-prioritized replay to modulate learning from self-generated tasks and solutions, consistently improving over base models on 19 held-out benchmarks in general reasoning and mathematics for Qwen and Llama models from 0.6B to 4B parameters.
What carries the argument
The LLM's intrinsic confidence score, used to weight updates in PPO and prioritize samples in replay buffer to filter uncertain feedback.
If this is right
- Improves average performance in general reasoning and mathematics.
- Works across four different backbones in the 0.6B to 4B range.
- Remains competitive on code generation tasks.
- Offers a lightweight alternative to external verifiers for self-evolution.
Where Pith is reading between the lines
- Similar confidence-based filtering could be applied to other self-training methods like RLAIF.
- If confidence correlates well with accuracy, this scales to larger models.
- Testable by checking if performance gains disappear when confidence is randomized.
Load-bearing premise
The LLM's intrinsic confidence score is an accurate enough proxy for the correctness of its self-generated judgments.
What would settle it
Observing no improvement or degradation when using confidence weighting compared to treating all self-feedback equally, or low correlation between confidence and actual correctness on validation tasks.
Figures
read the original abstract
Self-evolving large language models (LLMs) learn by generating their own training tasks and solutions, reducing reliance on human-curated supervision. However, in many reasoning domains, the model must also validate generated tasks and judge generated answers to obtain training signals. This creates a training-signal challenge: erroneous self-judgments become erroneous gradient updates. Existing approaches either rely on external verifiers, which limits generality, or treat noisy self-generated feedback as supervision. We propose COSE (Confidence-Orchestrated Self-Evolution), which uses the LLM's intrinsic confidence as a lightweight uncertainty signal to modulate learning. COSE introduces confidence-weighted PPO updates and confidence-prioritized replay. Across 19 held-out benchmarks and four Qwen/Llama backbones (0.6B--4B), COSE consistently improves over base models and achieves the best average performance in general reasoning and mathematics, while remaining competitive on code. Code and data are available at https://anonymous.4open.science/r/COSE_-B5C2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COSE (Confidence-Orchestrated Self-Evolution), a method for self-evolving LLMs that uses the model's intrinsic confidence as an uncertainty signal to modulate PPO updates and prioritize replay in the training buffer. This is intended to reduce the impact of erroneous self-judgments in generating training signals for reasoning tasks. The authors report that across 19 held-out benchmarks and four small Qwen and Llama models, COSE improves over base models and achieves the best average performance in general reasoning and mathematics.
Significance. If the empirical results hold and the confidence proxy is valid, this work could offer a practical, lightweight alternative to external verifiers for self-supervised LLM improvement, advancing the field of autonomous model evolution in reasoning domains. The availability of code and data supports reproducibility.
major comments (2)
- [Abstract] Abstract: The abstract states performance improvements but supplies no numbers, error bars, ablation details, or statistical tests; the central claim cannot be evaluated from the provided text alone.
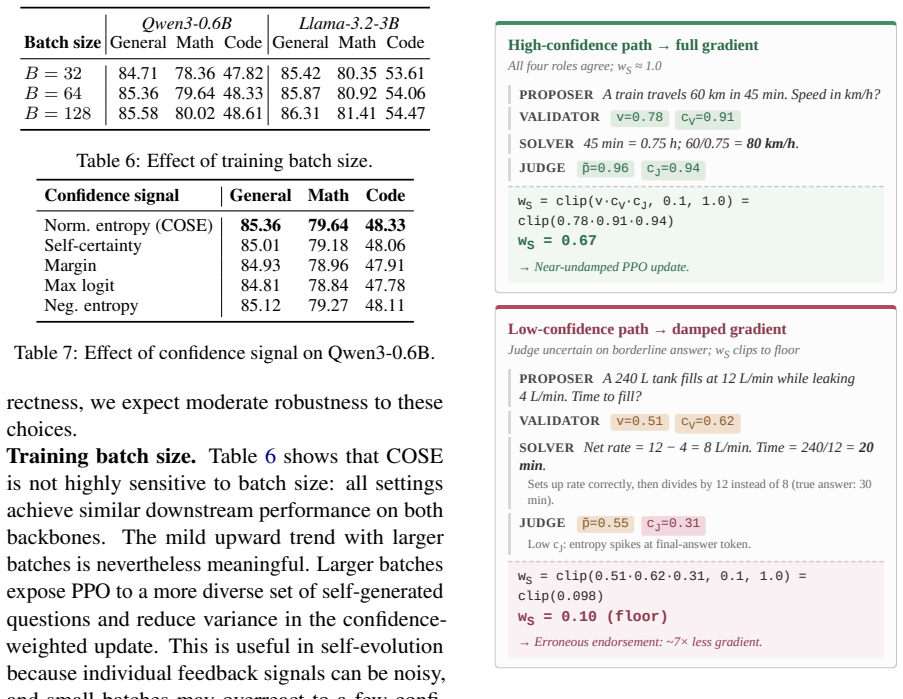
- [Method] The core mechanism (confidence-weighted PPO + prioritized replay) assumes the LLM's intrinsic confidence score tracks the accuracy of its own task/answer judgments closely enough that down-weighting low-confidence items removes more noise than useful gradient signal, but no direct measurement of confidence-accuracy correlation or ablation isolating the weighting effect from plain PPO is provided.
minor comments (1)
- [Abstract] The link to code and data uses an anonymous service, which is standard for review but should be replaced with a permanent repository upon acceptance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states performance improvements but supplies no numbers, error bars, ablation details, or statistical tests; the central claim cannot be evaluated from the provided text alone.
Authors: We agree that the abstract would benefit from quantitative details. In the revision we will add specific numbers (e.g., average improvement across the 19 benchmarks and four backbones), reference error bars and statistical tests reported in the main results section, and briefly note the ablation findings. revision: yes
-
Referee: [Method] The core mechanism (confidence-weighted PPO + prioritized replay) assumes the LLM's intrinsic confidence score tracks the accuracy of its own task/answer judgments closely enough that down-weighting low-confidence items removes more noise than useful gradient signal, but no direct measurement of confidence-accuracy correlation or ablation isolating the weighting effect from plain PPO is provided.
Authors: We acknowledge that a direct correlation analysis and an explicit ablation isolating the weighting component would provide stronger support. While the consistent gains across models and benchmarks serve as indirect validation, we will add both a confidence-accuracy correlation plot and a controlled ablation of confidence-weighted PPO versus standard PPO in the revised version. revision: yes
Circularity Check
No circularity; empirical method with no derivations or self-referential reductions.
full rationale
The paper describes COSE as an empirical technique that applies the LLM's intrinsic confidence scores to weight PPO updates and prioritize replay buffers. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method. The performance claims rest on held-out benchmark results across multiple models, which are externally measurable and not reduced to the inputs by construction. The core assumption (confidence as uncertainty proxy) is an explicit premise rather than a self-definitional loop, and the method remains falsifiable without requiring the result to hold tautologically.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Thomas Coste, Usman Anwar, Robert Kirk, and David Krueger. 2024. Reward model ensembles help miti- gate overoptimization. InInternational Conference on Learning Representations (ICLR). Yonatan Geifman and Ran El-Yaniv. 2017. Selec- tive classification for deep neural network...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
PMLR. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
OpenAI o1 system card.arXiv preprint arXiv:2412.16720. Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehen- sion. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL). Saurav Kadavath, Tom Conerly, Amanda Askell, To...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Spice: Self-play in corpus environments improves reasoning
SPICE: Self-play in corpus environments im- proves reasoning.arXiv preprint arXiv:2510.24684. Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Ling- ming Zhang. 2023. Is your code generated by Chat- GPT really correct? rigorous evaluation of large lan- guage models for code generation. InAdvances in Neural Information Processing Systems (NeurIPS). Wei Liu,...
-
[5]
InAdvances in Neural Information Processing Systems (NeurIPS), volume 37
LLM evaluators recognize and favor their own generations. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37. Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language under- standing by generative pre-training.OpenAI Blog. Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D....
2018
-
[6]
Proximal Policy Optimization Algorithms
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36. Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text. InProceedings of the Conference on Empirical Methods in Natural Langu...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Pride and prejudice: LLM amplifies self-bias in self-refinement
LiveBench: A challenging, contamination-free LLM benchmark. InProceedings of the International Conference on Learning Representations (ICLR). Junkang Wu, Yuexiang Xie, Zhengyi Yang, Jiancan Wu, Jinyang Gao, Bolin Ding, Xiang Wang, and Xiangnan He. 2024. β-DPO: Direct preference optimization with dynamic β. InAdvances in Neural Information Processing Syste...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.