Stay Fair! Ensuring Group Fairness in Diffusion Models Across Guidance Scales
Pith reviewed 2026-06-29 13:08 UTC · model grok-4.3
The pith
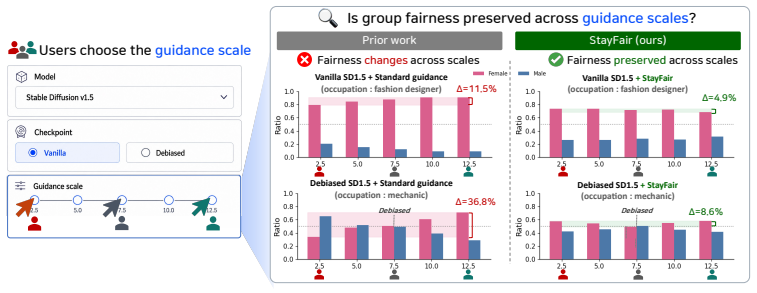
StayFair maintains group fairness in diffusion models at every guidance scale by correcting guidance bias separately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
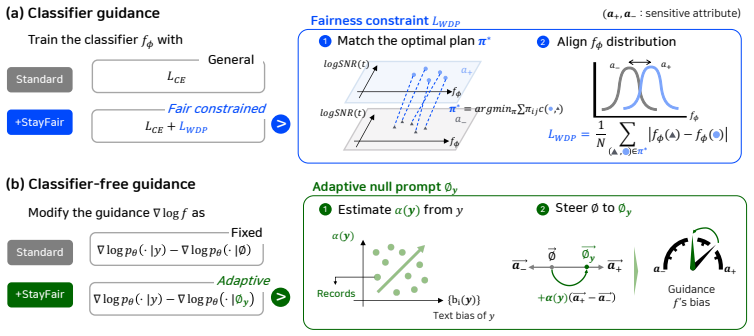
Extending Strong Demographic Parity to the guidance step produces a condition under which the target distribution keeps its group ratio for any guidance scale; StayFair satisfies this condition by equalizing the classifier output distributions across groups in classifier guidance and by applying a prompt-dependent offset to the null embedding in classifier-free guidance.
What carries the argument
The condition derived from extending Strong Demographic Parity to guidance, which ensures the target distribution retains its group ratio across scales and is enforced by modifying only the guidance step.
If this is right
- Fairness metrics become independent of the chosen guidance scale.
- StayFair can be added to any previously debiased diffusion model without retraining.
- Image quality and prompt alignment stay the same as in the original model.
- The approach works for both class-conditional and text-to-image generation tasks.
Where Pith is reading between the lines
- Users of image generators could change the guidance scale to control style or fidelity without fairness shifting as a side effect.
- The same separation of guidance bias could be tested in other sampling methods that use classifier or null conditioning.
- Combining StayFair with model-level debiasing might produce fairness guarantees that hold under distribution shift at inference time.
Load-bearing premise
Guidance bias grows monotonically with the guidance scale and eventually dominates high-guidance regimes.
What would settle it
Generate images at a range of guidance scales, compute group fairness metrics before and after applying StayFair, and check whether the metrics remain constant with scale.
Figures

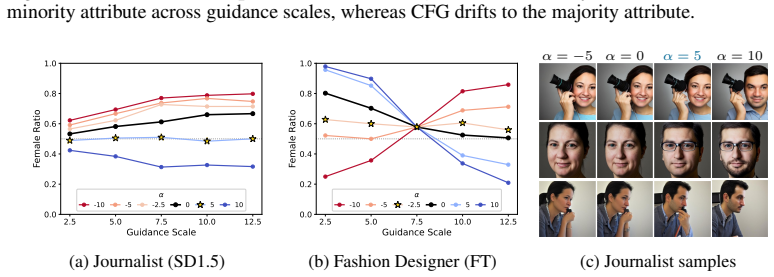
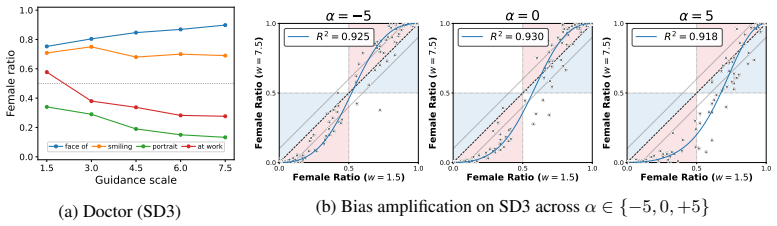
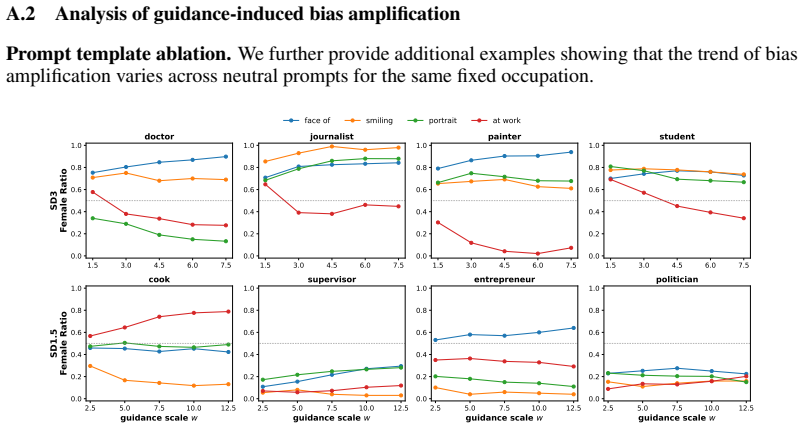
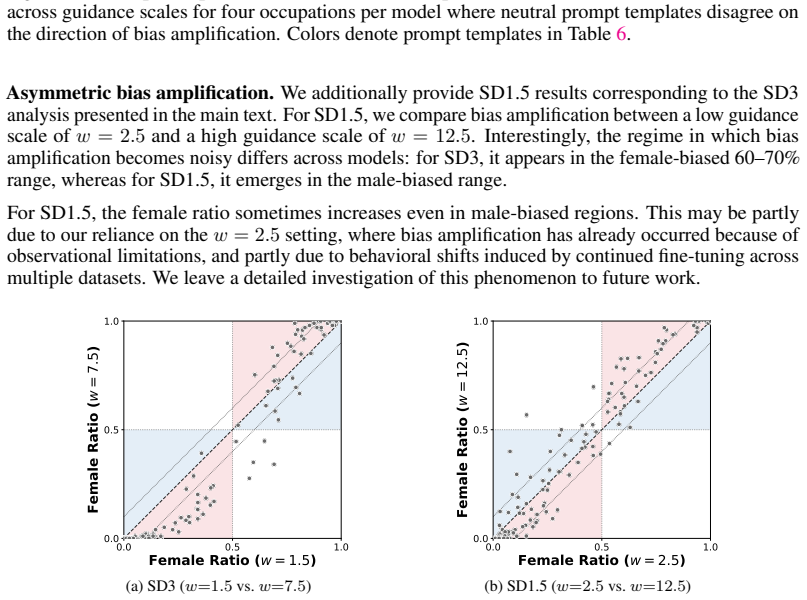
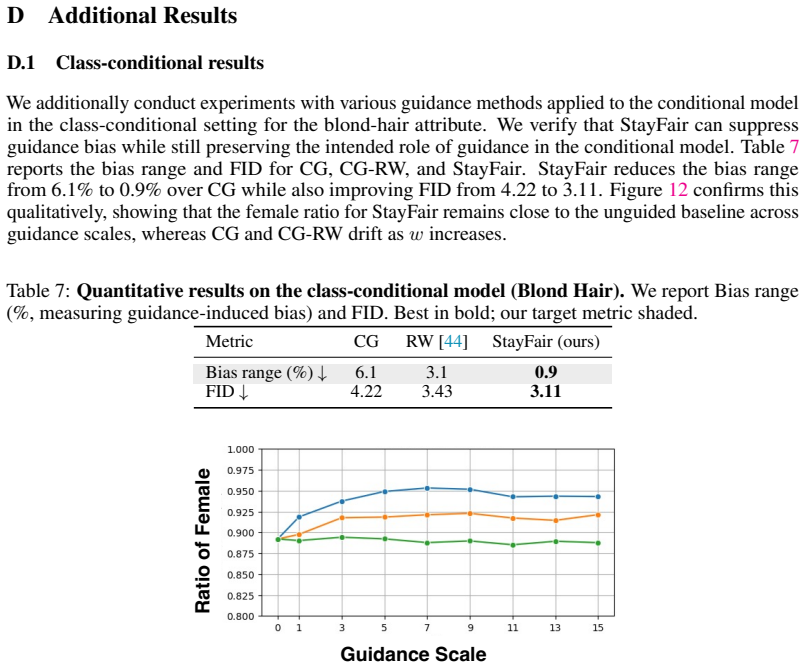
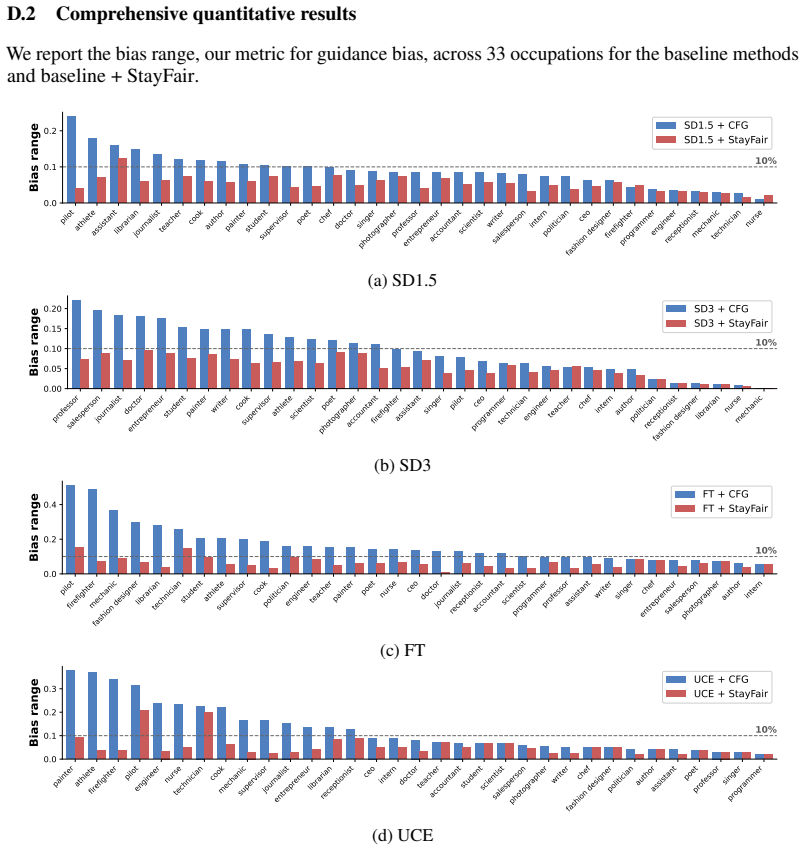




read the original abstract
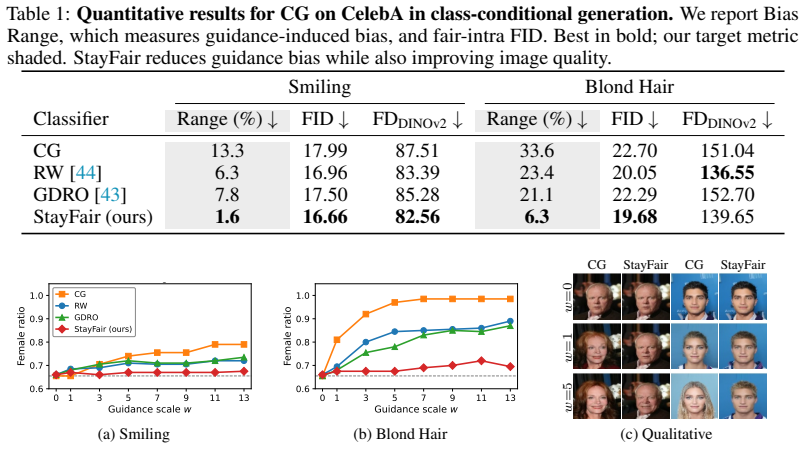
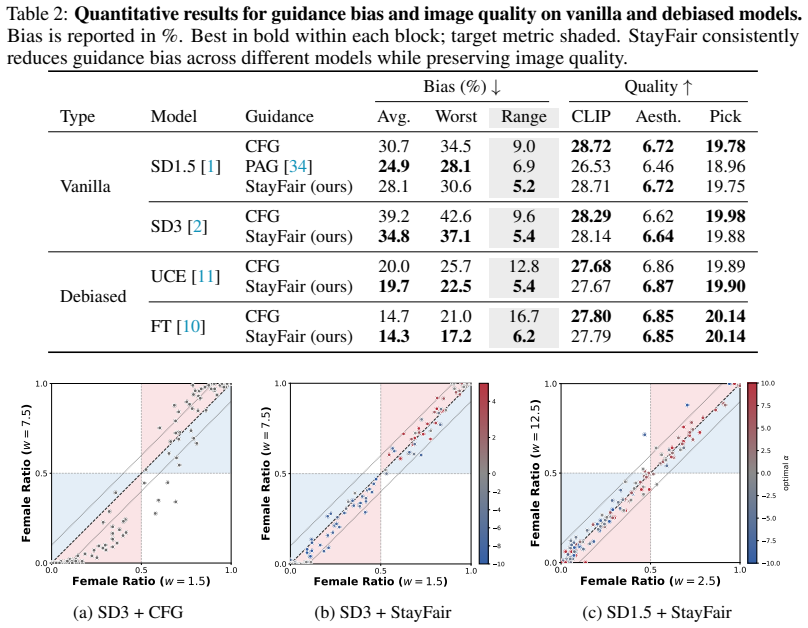
Diffusion models steer conditional generation with a tunable guidance scale to trade off prompt alignment and diversity. However, existing debiasing techniques are optimized for a single scale, degrading fairness when users adjust this parameter. We trace this behavior to a previously overlooked source by decomposing total bias into two components: a model bias and a guidance bias. While prior work primarily targets the former, we show that the guidance bias grows monotonically with the guidance scale, eventually dominating the high-guidance regimes users prefer. To address this, we extend Strong Demographic Parity to guidance and derive a condition under which the target distribution retains its group ratio across guidance scales. We propose StayFair, which leverages this condition to design fair guidance algorithms in both regimes. For classifier guidance, it equalizes the classifier's output distributions across groups; for classifier-free guidance, it shifts the null embedding by a prompt-dependent offset. Because StayFair modifies only the guidance step, it is orthogonal to model debiasing and can be layered onto existing fair diffusion models to extend their fairness across guidance scales. Across class-conditional and text-to-image generation, StayFair decouples fairness from the guidance scale without sacrificing image quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper decomposes bias in conditional diffusion models into model bias and guidance bias, shows that the latter grows monotonically with the guidance scale and dominates at high scales, extends Strong Demographic Parity to the guidance step, derives a condition under which group ratios are preserved across scales, and introduces StayFair. StayFair equalizes classifier output distributions for classifier guidance and applies a prompt-dependent offset to the null embedding for classifier-free guidance; the method modifies only the guidance step, is orthogonal to model-level debiasing, and is claimed to maintain image quality while decoupling fairness from the chosen guidance scale.
Significance. If the decomposition and derived condition hold, the result is significant because it removes a practical barrier to deploying fair diffusion models: existing debiasing methods are scale-specific and lose fairness when users increase the guidance scale for better prompt alignment. The orthogonality property allows StayFair to be layered on top of prior fair models without retraining, and the construction-by-equalization approach provides a clean, falsifiable mechanism that could be adopted in both class-conditional and text-to-image pipelines.
major comments (2)
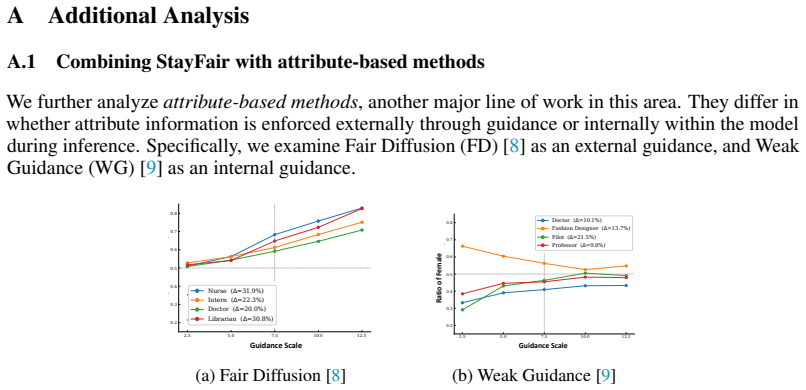
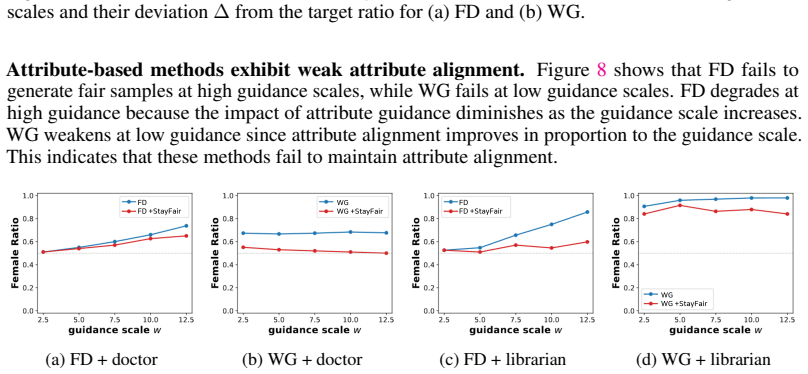
- [Abstract / §3] The monotonic-growth claim for guidance bias (abstract) is load-bearing for the central argument that it eventually dominates high-guidance regimes. The manuscript must supply the explicit decomposition (presumably in §3) together with the proof or empirical verification that the guidance term increases with scale for arbitrary classifiers or null embeddings; without this, the necessity of the StayFair correction cannot be assessed.
- [§4] The derived condition for retaining group ratios across scales (abstract) is the foundation of both StayFair variants. The manuscript should state this condition as an explicit equation or theorem and show that the proposed equalisation of classifier outputs (classifier guidance) and null-embedding shift (CFG) satisfy it by construction; any hidden dependence on fitted parameters or additional distributional assumptions must be flagged.
minor comments (2)
- [Abstract] Notation for the two bias components and the extended SDP should be introduced once and used consistently; the abstract uses “total bias,” “model bias,” and “guidance bias” without symbols.
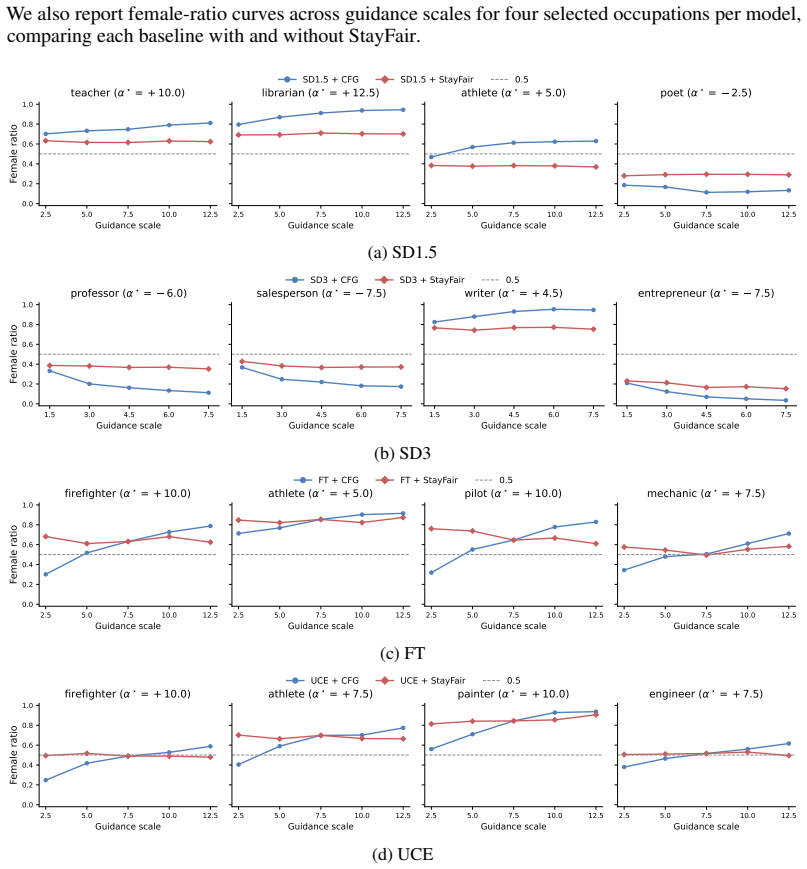
- [Experiments] The experimental section should report quantitative fairness metrics (e.g., demographic parity gap) at multiple guidance scales for both the baseline fair model and the StayFair-augmented version, together with standard image-quality metrics, to substantiate the “without sacrificing image quality” claim.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the recommendation of minor revision. The comments help clarify the presentation of our theoretical contributions. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §3] The monotonic-growth claim for guidance bias (abstract) is load-bearing for the central argument that it eventually dominates high-guidance regimes. The manuscript must supply the explicit decomposition (presumably in §3) together with the proof or empirical verification that the guidance term increases with scale for arbitrary classifiers or null embeddings; without this, the necessity of the StayFair correction cannot be assessed.
Authors: We agree that an explicit decomposition and proof are necessary for rigor. Section 3 already contains the bias decomposition into model and guidance components. In the revision we will restate this decomposition as a formal equation, provide a proof that the guidance bias term is monotonically non-decreasing in the guidance scale (under the standard diffusion guidance assumptions), and add empirical plots verifying the growth for multiple classifiers and null embeddings. This will directly support the claim that guidance bias dominates at high scales. revision: yes
-
Referee: [§4] The derived condition for retaining group ratios across scales (abstract) is the foundation of both StayFair variants. The manuscript should state this condition as an explicit equation or theorem and show that the proposed equalisation of classifier outputs (classifier guidance) and null-embedding shift (CFG) satisfy it by construction; any hidden dependence on fitted parameters or additional distributional assumptions must be flagged.
Authors: We will revise Section 4 to present the group-ratio preservation condition as an explicit theorem. We will then show, by direct substitution, that both the classifier-output equalization (classifier guidance) and the prompt-dependent null-embedding offset (CFG) satisfy the theorem by construction. All distributional assumptions (e.g., on classifier outputs or embedding spaces) and any dependence on fitted parameters will be stated explicitly in the theorem statement and proof. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The abstract presents a decomposition of total bias into model bias plus guidance bias, asserts monotonic growth of the latter with scale, extends Strong Demographic Parity to derive a retention condition for group ratios, and constructs StayFair to satisfy the condition by equalizing classifier outputs or shifting null embeddings. This constitutes a standard design step that implements a mathematically derived requirement rather than renaming a fit, smuggling an ansatz via self-citation, or reducing a claimed prediction to its own inputs. No equations appear in the abstract that would allow a self-definitional or fitted-input reduction, and the orthogonality claim follows directly from the scope of the modification. The full manuscript would need to be inspected for any load-bearing self-citation chains, but the provided text shows an independent derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InCVPR, pages 10684–10695, 2022
2022
-
[2]
Scaling rectified flow transform- ers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis. InICML, pages 12606–12633, 2024
2024
-
[3]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. In NeurIPS, volume 34, pages 8780–8794, 2021
2021
-
[4]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[5]
DALL-Eval: Probing the reasoning skills and social biases of text-to-image generation models
Jaemin Cho, Abhay Zala, and Mohit Bansal. DALL-Eval: Probing the reasoning skills and social biases of text-to-image generation models. InICCV, pages 3043–3054, 2023
2023
-
[6]
The bias amplification paradox in text-to- image generation
Preethi Seshadri, Sameer Singh, and Yanai Elazar. The bias amplification paradox in text-to- image generation. InNAACL, pages 6367–6384, 2024
2024
-
[7]
Racial biases in AIs and Gemini’s inability to write narratives about black people.Emerging Media, 2(2):277–287, 2024
Julia Barroso da Silveira and Ellen Alves Lima. Racial biases in AIs and Gemini’s inability to write narratives about black people.Emerging Media, 2(2):277–287, 2024
2024
-
[8]
Felix Friedrich, Manuel Brack, Lukas Struppek, Dominik Hintersdorf, Patrick Schramowski, Sasha Luccioni, and Kristian Kersting. Fair diffusion: Instructing text-to-image generation models on fairness.arXiv preprint arXiv:2302.10893, 2023
-
[9]
Rethinking training for de-biasing text-to-image generation: Unlocking the potential of stable diffusion
Eunji Kim, Siwon Kim, Minjun Park, Rahim Entezari, and Sungroh Yoon. Rethinking training for de-biasing text-to-image generation: Unlocking the potential of stable diffusion. InCVPR, pages 13361–13370, 2025
2025
-
[10]
Finetuning text-to-image diffusion models for fairness
Xudong Shen, Chao Du, Tianyu Pang, Min Lin, Yongkang Wong, and Mohan Kankanhalli. Finetuning text-to-image diffusion models for fairness. InICLR, 2024
2024
-
[11]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InWACV, pages 5111–5120, 2024
2024
-
[12]
Wasserstein fair classification, 2020
Ray Jiang, Aldo Pacchiano, Tom Stepleton, Heinrich Jiang, and Silvia Chiappa. Wasserstein fair classification, 2020
2020
-
[13]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InICCV, pages 3730–3738, 2015
2015
-
[14]
Stable bias: Evaluat- ing societal representations in diffusion models
Sasha Luccioni, Christopher Akiki, Margaret Mitchell, and Yacine Jernite. Stable bias: Evaluat- ing societal representations in diffusion models. InNeurIPS, volume 36, pages 56338–56351, 2023
2023
-
[15]
Typology of risks of generative text-to- image models
Charlotte Bird, Eddie Ungless, and Atoosa Kasirzadeh. Typology of risks of generative text-to- image models. InAAAI/ACM AIES, pages 396–410, 2023
2023
-
[16]
Leander Girrbach, Stephan Alaniz, Genevieve Smith, and Zeynep Akata. A large scale analysis of gender biases in text-to-image generative models.arXiv preprint arXiv:2503.23398, 2025
-
[17]
Stable Diffusion exposed: Gender bias from prompt to image
Yankun Wu, Yuta Nakashima, and Noa Garcia. Stable Diffusion exposed: Gender bias from prompt to image. InAAAI/ACM AIES, 2024
2024
-
[18]
Easily accessible text-to- image generation amplifies demographic stereotypes at large scale
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. Easily accessible text-to- image generation amplifies demographic stereotypes at large scale. InFAccT, pages 1493–1504, 2023
2023
-
[19]
Venkatesh Babu
Rishubh Parihar, Abhijnya Bhat, Abhipsa Basu, Saswat Mallick, Jogendra Nath Kundu, and R. Venkatesh Babu. Balancing act: Distribution-guided debiasing in diffusion models. InCVPR, pages 6668–6678, 2024. 10
2024
-
[20]
Fairqueue: Rethinking prompt learning for fair text-to-image generation.NeurIPS, 37:22878–22926, 2024
Christopher T Teo, Milad Abdollahzadeh, Xinda Ma, and Ngai-Man Cheung. Fairqueue: Rethinking prompt learning for fair text-to-image generation.NeurIPS, 37:22878–22926, 2024
2024
-
[21]
Self-discovering inter- pretable diffusion latent directions for responsible text-to-image generation
Hang Li, Chengzhi Shen, Philip Torr, V olker Tresp, and Jindong Gu. Self-discovering inter- pretable diffusion latent directions for responsible text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12006–12016, 2024
2024
-
[22]
De-stereotyping text-to-image models through prompt tuning.arXiv preprint arXiv:2302.02369, 2024
Eunji Kim, Siwon Kim, Chaehun Shin, and Sungroh Yoon. De-stereotyping text-to-image models through prompt tuning.arXiv preprint arXiv:2302.02369, 2024
-
[23]
Training unbiased diffusion models from biased dataset
Yeongmin Kim, Byeonghu Na, Minsang Park, JoonHo Jang, Dongjun Kim, Wanmo Kang, and Il-Chul Moon. Training unbiased diffusion models from biased dataset. InICLR, 2024
2024
-
[24]
arXiv preprint arXiv:2302.00070 , year=
Ching-Yao Chuang, Varun Jampani, Yuanzhen Li, Antonio Torralba, and Stefanie Jegelka. Debiasing vision-language models via biased prompts.arXiv preprint arXiv:2302.00070, 2023
-
[25]
LightFair: Towards an efficient alternative for fair T2I diffusion via debiasing pre-trained text encoders
Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Kangli Zi, and Qingming Huang. LightFair: Towards an efficient alternative for fair T2I diffusion via debiasing pre-trained text encoders. InNeurIPS, volume 38, pages 22671–22724, 2026
2026
-
[26]
Mining GOLD samples for conditional GANs
Sangwoo Mo, Chiheon Kim, Sungwoong Kim, Minsu Cho, and Jinwoo Shin. Mining GOLD samples for conditional GANs. InNeurIPS, 2019
2019
-
[27]
Rethinking prompt design for inference-time scaling in text-to-visual generation
Subin Kim, Sangwoo Mo, Mamshad Nayeem Rizve, Yiran Xu, Difan Liu, Jinwoo Shin, and Tobias Hinz. Rethinking prompt design for inference-time scaling in text-to-visual generation. InCVPR, 2026
2026
-
[28]
Universal guidance for diffusion models
Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models. InCVPRW, pages 843–852, 2023
2023
-
[29]
Tfg: Unified training-free guidance for diffusion models.NeurIPS, 37:22370–22417, 2024
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Zou, and Stefano Ermon. Tfg: Unified training-free guidance for diffusion models.NeurIPS, 37:22370–22417, 2024
2024
-
[30]
Applying guidance in a limited interval improves sample and distribution quality in diffusion models
Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models. InNeurIPS, 2024
2024
-
[31]
Seyedmorteza Sadat, Otmar Hilliges, and Romann M. Weber. Eliminating oversaturation and artifacts of high guidance scales in diffusion models. InICLR, 2025
2025
-
[32]
Guiding a diffusion model with a bad version of itself
Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself. InNeurIPS, volume 37, pages 52996–53021, 2024
2024
-
[33]
Improving sample quality of diffusion models using self-attention guidance
Susung Hong, Gyuseong Lee, Wooseok Jang, and Seungryong Kim. Improving sample quality of diffusion models using self-attention guidance. InICCV, pages 7462–7471, 2023
2023
-
[34]
Self-rectifying diffusion sampling with perturbed-attention guidance
Donghoon Ahn, Hyoungwon Cho, Jaewon Min, Wooseok Jang, Jungwoo Kim, SeonHwa Kim, Hyun Hee Park, Kyong Hwan Jin, and Seungryong Kim. Self-rectifying diffusion sampling with perturbed-attention guidance. InECCV, pages 1–17, 2024
2024
-
[35]
How I met your bias: Investigating bias amplification in diffusion models
Nathan Roos, Ekaterina Iakovleva, Ani Gjergji, Vito Paolo Pastore, and Enzo Tartaglione. How I met your bias: Investigating bias amplification in diffusion models. InWACV, pages 5374–5383, 2026
2026
-
[36]
A review on fairness in machine learning.ACM computing surveys (CSUR), 55(3):1–44, 2022
Dana Pessach and Erez Shmueli. A review on fairness in machine learning.ACM computing surveys (CSUR), 55(3):1–44, 2022
2022
-
[37]
Discovering and mitigating visual biases through keyword explanation
Younghyun Kim, Sangwoo Mo, Minkyu Kim, Kyungmin Lee, Jaeho Lee, and Jinwoo Shin. Discovering and mitigating visual biases through keyword explanation. InCVPR, 2024. 11
2024
-
[38]
Understanding the Effects of Distractors on Reasoning Vision-Language Models
Jiyun Bae, Hyunjong Ok, Sangwoo Mo, and Jaeho Lee. Do reasoning vision-language models inversely scale in test-time compute? a distractor-centric empirical analysis.arXiv preprint arXiv:2511.21397, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Fairness through awareness
Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. Fairness through awareness. InITCS, 2012
2012
-
[40]
Equality of opportunity in supervised learning
Moritz Hardt, Eric Price, and Nathan Srebro. Equality of opportunity in supervised learning. In NeurIPS, 2016
2016
-
[41]
Muhammad Bilal Zafar, Isabel Valera, Manuel Gomez Rodriguez, and Krishna P. Gummadi. Fairness constraints: Mechanisms for fair classification. InAISTATS, 2017
2017
-
[42]
A reductions approach to fair classification
Alekh Agarwal, Alina Beygelzimer, Miroslav Dudík, John Langford, and Hanna Wallach. A reductions approach to fair classification. InICML, 2018
2018
-
[43]
Hashimoto, and Percy Liang
Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. InICLR, 2020
2020
-
[44]
Simple data balancing achieves competitive worst-group-accuracy
Badr Youbi Idrissi, Martin Arjovsky, Mohammad Pezeshki, and David Lopez-Paz. Simple data balancing achieves competitive worst-group-accuracy. InCLeaR, 2022
2022
-
[45]
Fair regression with Wasserstein barycenters
Evgenii Chzhen, Christophe Denis, Mohamed Hebiri, Luca Oneto, and Massimiliano Pontil. Fair regression with Wasserstein barycenters. InNeurIPS, volume 33, pages 7321–7331, 2020
2020
-
[46]
Farhad Farokhi. Optimal pre-processing to achieve fairness and its relationship with total variation barycenter.arXiv preprint arXiv:2101.06811, 2021
-
[47]
Fairness through matching.Transactions on Machine Learning Research, 2025
Kunwoong Kim, Insung Kong, Jongjin Lee, Minwoo Chae, Sangchul Park, and Yongdai Kim. Fairness through matching.Transactions on Machine Learning Research, 2025
2025
-
[48]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, volume 33, pages 6840–6851, 2020
2020
-
[49]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021
2021
-
[50]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InNeurIPS, volume 35, pages 26565–26577, 2022
2022
-
[51]
Characteristic guidance: Non-linear correction for diffusion model at large guidance scale
Candi Zheng and Yuan Lan. Characteristic guidance: Non-linear correction for diffusion model at large guidance scale. InICML, pages 61386–61412, 2024
2024
-
[52]
Provable efficiency of guidance in diffusion models for general data distribution
Gen Li and Yuchen Jiao. Provable efficiency of guidance in diffusion models for general data distribution. InICML, pages 35034–35046, 2025
2025
-
[53]
Adaptive diffusion guidance via stochastic optimal control
Iskander Azangulov, Peter Potaptchik, Qinyu Li, Eddie Aamari, George Deligiannidis, and Judith Rousseau. Adaptive diffusion guidance via stochastic optimal control. InAISTATS, 2026
2026
-
[54]
Embedding arithmetic of multimodal queries for image retrieval
Guillaume Couairon, Matthijs Douze, Matthieu Cord, and Holger Schwenk. Embedding arithmetic of multimodal queries for image retrieval. InCVPR, pages 4950–4958, 2022
2022
-
[55]
Fair text-to-image diffusion via fair mapping
Jia Li, Lijie Hu, Jingfeng Zhang, Tianhang Zheng, Hua Zhang, and Di Wang. Fair text-to-image diffusion via fair mapping. InAAAI, volume 39, pages 26256–26264, 2025
2025
-
[56]
Input perturbation reduces exposure bias in diffusion models
Mang Ning, Enver Sangineto, Angelo Porrello, Simone Calderara, and Rita Cucchiara. Input perturbation reduces exposure bias in diffusion models. InICML, pages 26245–26265, 2023
2023
-
[57]
Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation
Kimmo Karkkainen and Jungseock Joo. Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. InWACV, pages 1548–1558, 2021
2021
-
[58]
GANs trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. InNeurIPS, pages 6626–6637, 2017. 12
2017
-
[59]
Breaking the spurious causality of conditional generation via fairness intervention with corrective sampling.Transactions on Machine Learning Research, 2023
Junhyun Nam, Sangwoo Mo, Jaeho Lee, and Jinwoo Shin. Breaking the spurious causality of conditional generation via fairness intervention with corrective sampling.Transactions on Machine Learning Research, 2023
2023
-
[60]
Cresswell, Rasa Hosseinzadeh, Yi Sui, Brendan Leigh Ross, Valentin Villecroze, Zhaoyan Liu, Anthony L
George Stein, Jesse C. Cresswell, Rasa Hosseinzadeh, Yi Sui, Brendan Leigh Ross, Valentin Villecroze, Zhaoyan Liu, Anthony L. Caterini, J. Eric T. Taylor, and Gabriel Loaiza-Ganem. Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models. InNeurIPS, 2023
2023
-
[61]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763, 2021
2021
-
[62]
Yolov10: Real-time end-to-end object detection.NeurIPS, 37:107984–108011, 2024
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Yolov10: Real-time end-to-end object detection.NeurIPS, 37:107984–108011, 2024
2024
-
[63]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InEMNLP, pages 7514–7528, 2021
2021
-
[64]
LAION-5B: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. LAION-5B: An open large-scale dataset for training next generation image-text models....
2022
-
[65]
Pick-a-Pic: An open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-Pic: An open dataset of user preferences for text-to-image generation. InNeurIPS, volume 36, pages 36652–36663, 2023
2023
-
[66]
Perception prioritized training of diffusion models
Jooyoung Choi, Jungbeom Lee, Chaehun Shin, Sungwon Kim, Hyunwoo Kim, and Sungroh Yoon. Perception prioritized training of diffusion models. InCVPR, pages 11472–11481, 2022
2022
-
[67]
% # +! $ # '&
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. In NeurIPS, volume 29, 2016. 13 Appendix A Additional Analysis 15 A.1 Combining StayFair with attribute-based methods . . . . . . . . . . . . . . . . . . 15 A.2 Analysis of guidance-induced ...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.