MACReD: A Multi-Agent Collaborative Reasoning Framework for Reaction Diagram Parsing
Pith reviewed 2026-06-29 12:30 UTC · model grok-4.3
The pith
A multi-agent framework parses complex chemical reaction diagrams by coordinating specialized agents and fusing their outputs into consistent reactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
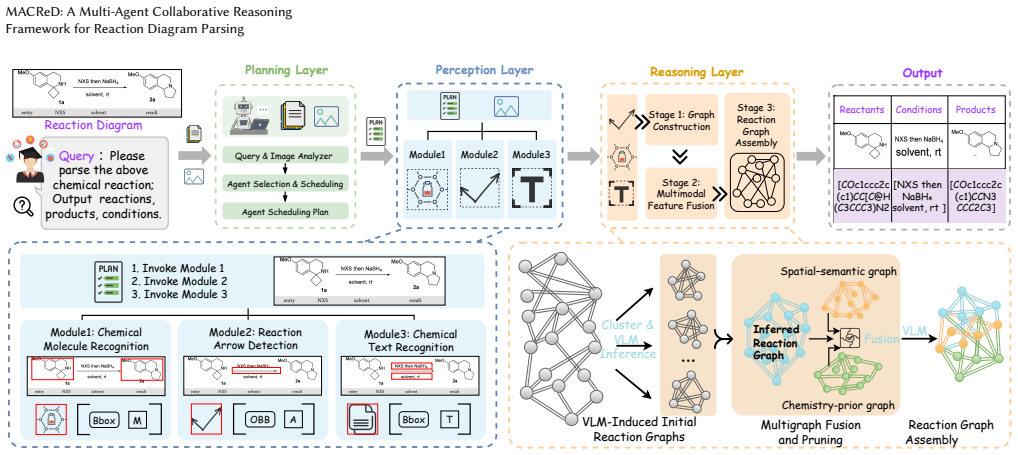
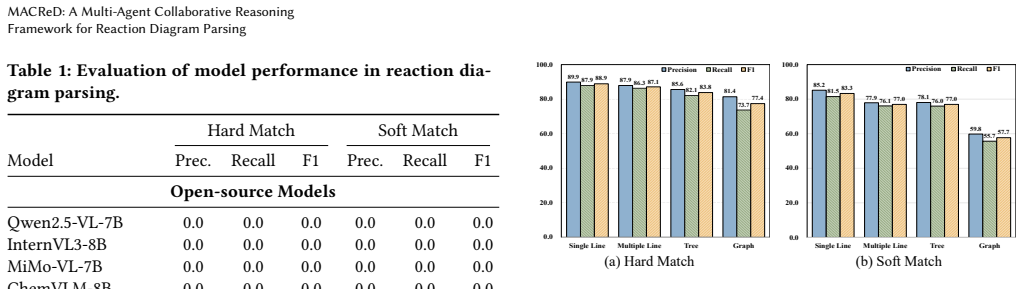
MACReD uses a planning and perception layer with fine-grained detection agents for molecular structures, arrows, and text, followed by a reasoning layer that applies multigraph fusion to merge heterogeneous cues and produce chemically valid global reaction reconstructions, reaching F1 scores of 75.2 percent under hard match and 84.6 percent under soft match on the RxnScribe benchmark while the baseline reaches 69.1 percent and 80.0 percent.
What carries the argument
Hierarchical multi-agent coordination inside a vision-language model, where perception agents feed a reasoning layer that performs multigraph fusion to enforce chemically consistent global reasoning across the diagram.
If this is right
- The method improves extraction accuracy on multi-step and tree-structured reactions that appear in literature.
- It maintains performance across varied diagram layouts that include intertwined visual elements.
- The multigraph fusion step allows integration of recognition outputs with higher-level chemical constraints.
- Benchmark gains indicate that agent specialization reduces errors that arise when a single model attempts all subtasks simultaneously.
Where Pith is reading between the lines
- The same agent-division pattern could be tested on other types of scientific diagrams that mix graphics and text, such as flow charts in engineering papers.
- If the multigraph fusion proves stable, it might serve as a template for combining outputs from multiple vision tools without retraining the underlying models.
- The approach leaves open whether the same hierarchy would still hold when diagrams are drawn in non-standard styles not represented in the current benchmark.
Load-bearing premise
Dividing diagram parsing among specialized agents and fusing their results with a multigraph will preserve spatial coherence and chemical validity on diagrams that single models cannot handle.
What would settle it
A collection of diagrams containing overlapping elements or multi-step branches where the agents produce locally correct detections but the fused output yields chemically invalid reactions or broken spatial relations.
Figures





read the original abstract
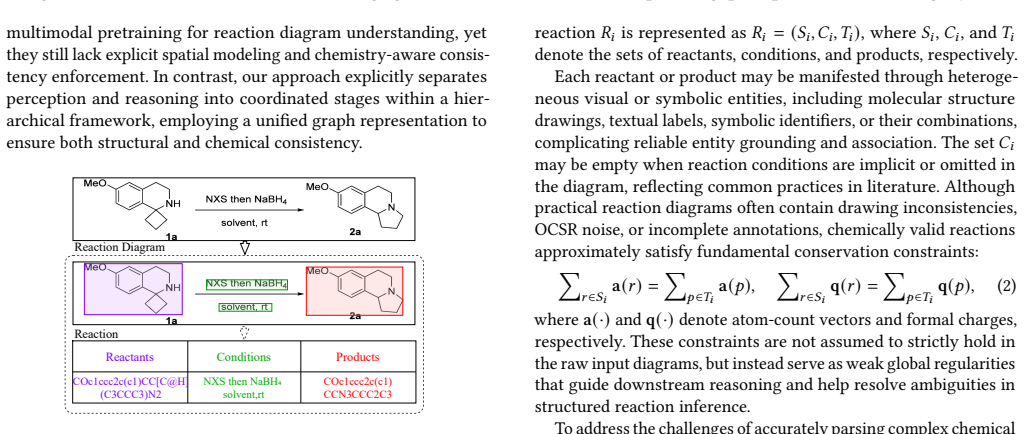
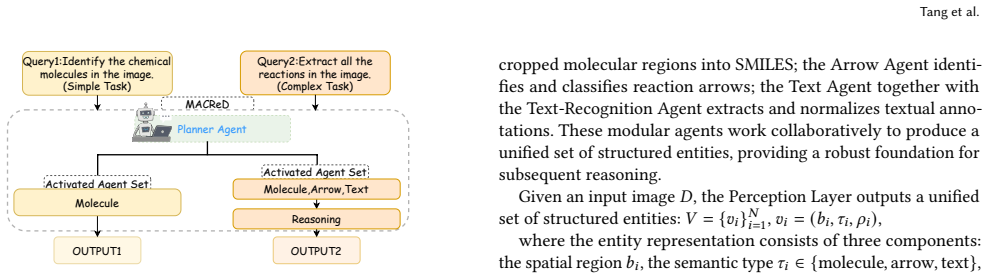
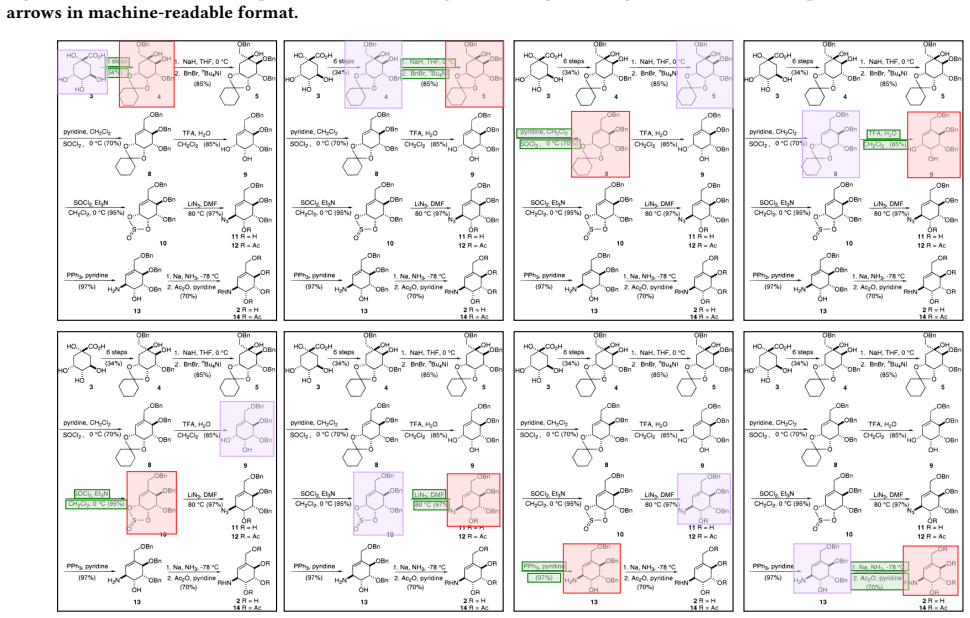
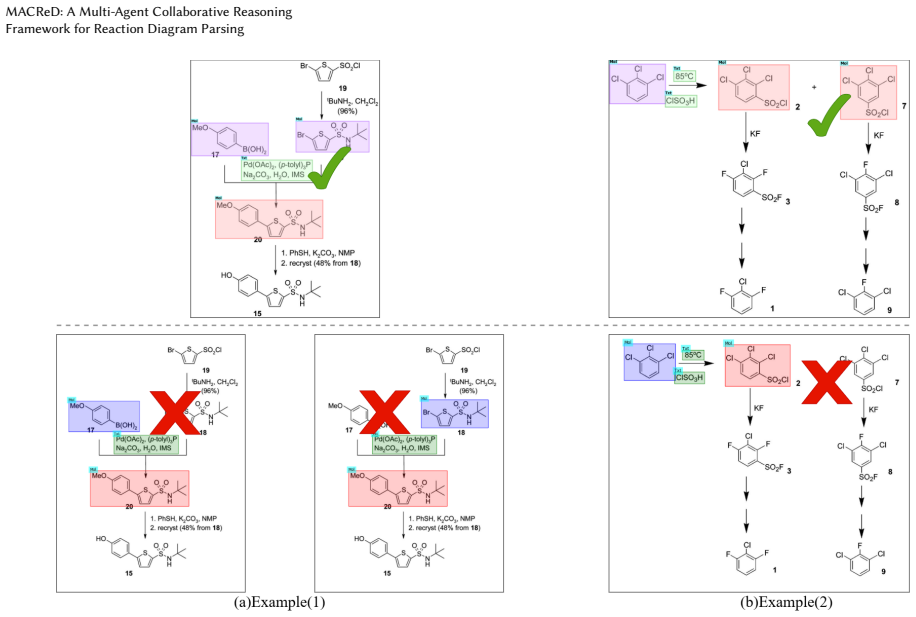
Parsing chemical reaction diagrams from scientific literature is challenging due to heterogeneous layouts, intertwined visual elements, and the difficulty of integrating recognition and reasoning. Existing vision-language models advance multimodal understanding but still fail on complex diagrams, struggling to maintain spatial coherence and to integrate multidimensional information during reasoning. To address these issues, we propose MACReD, a hierarchical multi-agent framework that coordinates specialized agents for molecular perception, arrow understanding, text extraction, and reaction reconstruction within a unified VLM-guided architecture. The planning and perception layers use flexible, fine-grained detection to handle visual complexity, while the reasoning layer uses a multigraph fusion mechanism to integrate heterogeneous cues and enforce chemically consistent global reasoning. Experiments on the RxnScribe benchmark show that MACReD achieves state-of-the-art performance, with F1 scores of 75.2% and 84.6% under hard and soft match criteria, outperforming the RxnScribe baseline, which obtains 69.1% and 80.0%, respectively. These results demonstrate the robustness of MACReD across diverse diagram layouts, including multi-step and tree-structured reactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MACReD, a hierarchical multi-agent framework for parsing chemical reaction diagrams. It coordinates specialized agents for molecular perception, arrow understanding, text extraction, and reaction reconstruction inside a VLM-guided architecture, using flexible detection in planning/perception layers and a multigraph fusion mechanism in the reasoning layer to enforce spatial coherence and chemical consistency. On the RxnScribe benchmark the method reports F1 scores of 75.2% (hard match) and 84.6% (soft match), outperforming the RxnScribe baseline (69.1%/80.0%).
Significance. If the reported gains are shown to be robust and attributable to the multi-agent coordination and multigraph fusion rather than backbone strength alone, the work would demonstrate a concrete advance in multimodal scientific-document understanding, offering a template for integrating heterogeneous visual and textual cues in complex diagrams.
major comments (1)
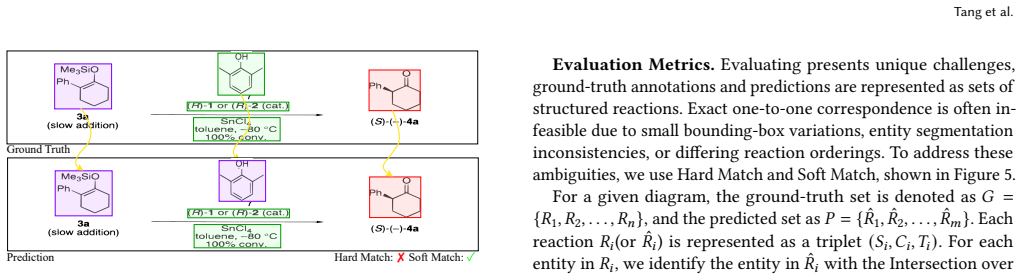
- [§4] §4 (Experiments) and abstract: the central SOTA claim rests on F1 scores of 75.2/84.6 vs. 69.1/80.0 without any description of data splits, evaluation protocol (exact definition of hard/soft match), whether the baseline was re-run under identical conditions, error bars, random seeds, or ablation studies isolating the contribution of hierarchical agent coordination versus a stronger VLM. These omissions make it impossible to attribute the performance delta to the claimed architectural mechanisms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and abstract: the central SOTA claim rests on F1 scores of 75.2/84.6 vs. 69.1/80.0 without any description of data splits, evaluation protocol (exact definition of hard/soft match), whether the baseline was re-run under identical conditions, error bars, random seeds, or ablation studies isolating the contribution of hierarchical agent coordination versus a stronger VLM. These omissions make it impossible to attribute the performance delta to the claimed architectural mechanisms.
Authors: We agree that the current manuscript does not provide sufficient detail on these experimental aspects, which limits the ability to attribute gains specifically to the multi-agent coordination and multigraph fusion. In the revised manuscript we will expand §4 to include: (i) the data splits used from the RxnScribe benchmark, (ii) the exact definitions of hard and soft match as applied, (iii) confirmation that the baseline was re-run under identical conditions, (iv) error bars and random seeds from multiple runs, and (v) ablation studies that isolate the hierarchical agent coordination and multigraph fusion components versus backbone strength alone. These additions will directly address the attribution concern. revision: yes
Circularity Check
No circularity: empirical framework evaluated on external benchmark with no derivation chain
full rationale
The paper describes a multi-agent architecture (MACReD) for diagram parsing and reports F1 scores on the named RxnScribe benchmark against a stated baseline. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The central claim reduces to an empirical performance delta on an external dataset, which is self-contained and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Seoin Back, Alán Aspuru-Guzik, Michele Ceriotti, Ganna Gryn’ova, Bartosz Grzybowski, Geun Ho Gu, Jason Hein, Kedar Hippalgaonkar, Rodrigo Hormáz- abal, Yousung Jung, et al. 2024. Accelerated chemical science with AI.Digital Discovery3, 1 (2024), 23–33
2024
-
[3]
Joe R McDaniel and Jason R Balmuth. 1992. Kekule: OCR-optical chemical (structure) recognition.Journal of chemical information and computer sciences 32, 4 (1992), 373–378
1992
-
[4]
Richard Casey, Stephen Boyer, Paul Healey, Alex Miller, Bernadette Oudot, and Karl Zilles. 1993. Optical recognition of chemical graphics. InProceedings of 2nd International Conference on Document Analysis and Recognition (ICDAR’93). IEEE, 627–631
1993
-
[5]
P Ibison, M Jacquot, F Kam, AG Neville, Richard W Simpson, C Tonnelier, T Venczel, and A Peter Johnson. 1993. Chemical literature data extraction: the CLiDE Project.Journal of Chemical Information and Computer Sciences33, 3 (1993), 338–344
1993
-
[6]
Aniko T Valko and A Peter Johnson. 2009. CLiDE Pro: the latest generation of CLiDE, a tool for optical chemical structure recognition.Journal of chemical information and modeling49, 4 (2009), 780–787
2009
-
[7]
Igor V Filippov and Marc C Nicklaus. 2009. Optical structure recognition software to recover chemical information: OSRA, an open source solution
2009
-
[8]
Paolo Frasconi, Francesco Gabbrielli, Marco Lippi, and Simone Marinai. 2014. Markov logic networks for optical chemical structure recognition.Journal of chemical information and modeling54, 8 (2014), 2380–2390
2014
-
[9]
Joshua Staker, Kyle Marshall, Robert Abel, and Carolyn M McQuaw. 2019. Molecu- lar structure extraction from documents using deep learning.Journal of chemical information and modeling59, 3 (2019), 1017–1029
2019
-
[10]
Kohulan Rajan, Achim Zielesny, and Christoph Steinbeck. 2021. DECIMER 1.0: deep learning for chemical image recognition using transformers.Journal of Cheminformatics13, 1 (2021), 61
2021
-
[11]
Sanghyun Yoo, Ohyun Kwon, and Hoshik Lee. 2022. Image-to-graph transform- ers for chemical structure recognition. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 3393–3397
2022
-
[12]
Yujie Qian, Jiang Guo, Zhengkai Tu, Zhening Li, Connor W Coley, and Regina Barzilay. 2023. MolScribe: robust molecular structure recognition with image- to-graph generation.Journal of chemical information and modeling63, 7 (2023), 1925–1934
2023
-
[13]
Yufan Chen, Ching Ting Leung, Yong Huang, Jianwei Sun, Hao Chen, and Hanyu Gao. 2024. MolNexTR: a generalized deep learning model for molecular image recognition.Journal of Cheminformatics16, 1 (2024), 141
2024
-
[14]
Dat Quoc Nguyen, Zenan Zhai, Hiyori Yoshikawa, Biaoyan Fang, Christian Druckenbrodt, Camilo Thorne, Ralph Hoessel, Saber A Akhondi, Trevor Cohn, Timothy Baldwin, et al. 2020. ChEMU: named entity recognition and event extrac- tion of chemical reactions from patents. InEuropean conference on information retrieval. Springer, 572–579
2020
-
[15]
Jiang Guo, A Santiago Ibanez-Lopez, Hanyu Gao, Victor Quach, Connor W Coley, Klavs F Jensen, and Regina Barzilay. 2021. Automated chemical reaction extraction from scientific literature.Journal of chemical information and modeling 62, 9 (2021), 2035–2045
2021
-
[16]
Damian M Wilary and Jacqueline M Cole. 2021. ReactionDataExtractor: A tool for automated extraction of information from chemical reaction schemes.Journal of chemical information and modeling61, 10 (2021), 4962–4974
2021
-
[17]
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al . 2025. Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free.arXiv preprint arXiv:2505.06708(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.182231, 2 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al . 2024. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology15, 3 (2024), 1–45
2024
-
[20]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. 2024. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence46, 8 (2024), 5625–5644
2024
-
[21]
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, and Aman Chadha
- [22]
-
[23]
Yujie Qian, Jiang Guo, Zhengkai Tu, Connor W Coley, and Regina Barzilay. 2023. RxnScribe: a sequence generation model for reaction diagram parsing.Journal of chemical information and modeling63, 13 (2023), 4030–4041
2023
- [24]
-
[25]
Ali Dorri, Salil S Kanhere, and Raja Jurdak. 2018. Multi-agent systems: A survey. Ieee Access6 (2018), 28573–28593
2018
-
[26]
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. 2025. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
OpenAI Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, and Aidan Clark et al. 2024. GPT-4o System Card.ArXivabs/2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, and et al. 2025. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805 [cs.CL] https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, and Lianghao Deng et al. 2025. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Junxian Li, Di Zhang, Xunzhi Wang, Zeying Hao, Jingdi Lei, Qian Tan, Cai Zhou, Wei Liu, Yaotian Yang, Xinrui Xiong, et al. 2025. Chemvlm: Exploring the power of multimodal large language models in chemistry area. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 415–423
2025
- [31]
-
[32]
Yashar Talebirad and Amirhossein Nadiri. 2023. Multi-agent collaboration: Harnessing the power of intelligent llm agents.arXiv preprint arXiv:2306.03314 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [33]
-
[34]
Mingcheng Li, Xiaolu Hou, Ziyang Liu, Dingkang Yang, Ziyun Qian, Jiawei Chen, Jinjie Wei, Yue Jiang, Qingyao Xu, and Lihua Zhang. 2025. MCCD: Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Gener- ation. InProceedings of the Computer Vision and Pattern Recognition Conference. 13263–13272
2025
-
[35]
Binpeng Shi, Yu Luo, Jingya Wang, Yongxin Zhao, Shenglin Zhang, Bowen Hao, Chenyu Zhao, Yongqian Sun, Zhi Zhang, Ronghua Sun, et al. 2025. FlowXpert: Tang et al. Expertizing Troubleshooting Workflow Orchestration with Knowledge Base and Multi-Agent Coevolution. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4839–4850
2025
-
[36]
Zhangtao Cheng, Yuhao Ma, Jian Lang, Kunpeng Zhang, Ting Zhong, Yong Wang, and Fan Zhou. 2025. Generative Thinking, Corrective Action: User- Friendly Composed Image Retrieval via Automatic Multi-Agent Collaboration. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 334–344
2025
-
[37]
Damian M Wilary and Jacqueline M Cole. 2023. ReactionDataExtractor 2.0: a deep learning approach for data extraction from chemical reaction schemes. Journal of Chemical Information and Modeling63, 19 (2023), 6053–6067
2023
-
[38]
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. 2025. PaddleOCR 3.0 Technical Report. arXiv:2507.05595 [cs.CV] https://arxiv.org/abs/2507.05595
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. 2020. A comprehensive survey on graph neural networks.IEEE transactions on neural networks and learning systems32, 1 (2020), 4–24
2020
-
[40]
Si Zhang, Hanghang Tong, Jiejun Xu, and Ross Maciejewski. 2019. Graph convo- lutional networks: a comprehensive review.Computational Social Networks6, 1 (2019), 1–23
2019
-
[41]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, and Mingkun Yang et al. 2025. Qwen2.5-VL Technical Report. arXiv:2502.13923 [cs.CV] https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, and Yuchen Duan et al. 2025. InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models. arXiv:2504.10479 [cs.CV] https://arxiv.org/abs/2504.10479
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [43]
-
[44]
molecule_expert
Mark Martori and Daniel Probst. 2022.Machine Learning approach for chemical reactions digitalisation.https://github.com/markmartorilopez/ A Details of the Ablation Study Table 3 presents a detailed ablation study of MACReD across four common layouts: Single Line, Multiple Line, Tree, and Graph. Eval- uation metrics include Precision, Recall, and F1-score ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.