No Safe Dose: How Training Data Drives Unsafe Image Generation
Pith reviewed 2026-06-29 13:38 UTC · model grok-4.3
The pith
The proportion of unsafe images in training data directly raises the rate of unsafe outputs from text-to-image models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
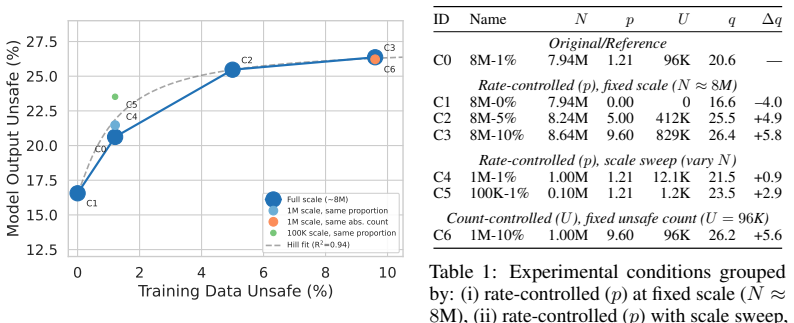
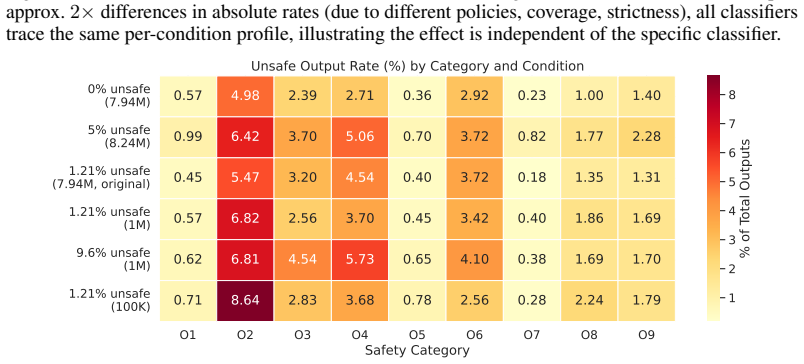
Training the same text-to-image architecture on datasets that differ solely in the fraction of unsafe images produces a monotonic rise in unsafe model outputs, from 16.6 percent at zero contamination to 25.5 percent at five percent contamination; the operative variable is the proportion rather than the absolute count of unsafe training images, while a residual baseline risk persists even at zero contamination and is partly traceable to the frozen text encoder.
What carries the argument
The controlled dose-response relationship between the proportion of unsafe training images and measured output unsafety, isolated via factorial dataset construction.
If this is right
- Safety filtering of training data lowers output unsafety without harming FID, CLIPscore, or ImageReward.
- Swapping the text encoder for a safer variant reduces the zero-contamination baseline from 16.6 percent to 9.6 percent.
- Data curation and text-encoder safety function as independent, additive interventions.
- The proportion of unsafe images, rather than their total count, governs the safety outcome across dataset scales from 100K to 8M.
Where Pith is reading between the lines
- The same proportion-driven effect may appear in other generative modalities once comparable controlled datasets become available.
- If model capabilities continue to grow, the residual baseline unsafety could interact with new compositional behaviors in ways the current experiments do not test.
- Repeated safety filtering at both data and encoder stages might drive the floor still lower, but that combined regime lies outside the reported design.
Load-bearing premise
The datasets differ only in the fraction of unsafe images and the four safety classifiers give an unbiased reading of true output unsafety.
What would settle it
Generating images from models trained on increasing proportions of unsafe data and finding no corresponding rise in the fraction flagged unsafe by the classifiers would falsify the central claim.
Figures


read the original abstract
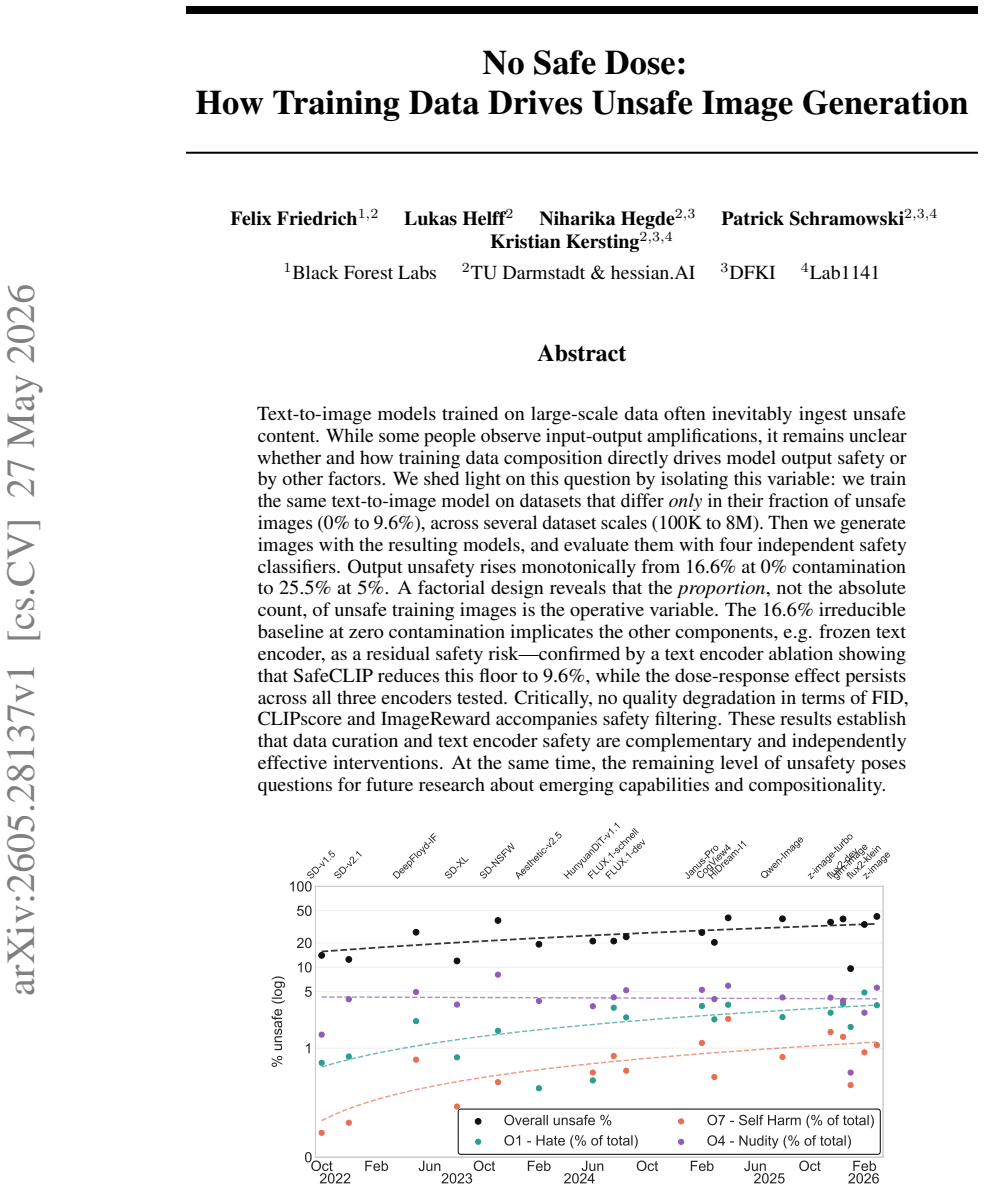
Text-to-image models trained on large-scale data often inevitably ingest unsafe content. While some people observe input-output amplifications, it remains unclear whether and how training data composition directly drives model output safety or by other factors. We shed light on this question by isolating this variable: we train the same text-to-image model on datasets that differ \emph{only} in their fraction of unsafe images (0\% to 9.6\%), across several dataset scales (100K to 8M). Then we generate images with the resulting models, and evaluate them with four independent safety classifiers. Output unsafety rises monotonically from 16.6\% at 0\% contamination to 25.5\% at 5\%. A factorial design reveals that the \emph{proportion}, not the absolute count, of unsafe training images is the operative variable. The 16.6\% irreducible baseline at zero contamination implicates the other components, e.g. frozen text encoder, as a residual safety risk -- confirmed by a text encoder ablation showing that SafeCLIP reduces this floor to 9.6\%, while the dose-response effect persists across all three encoders tested. Critically, no quality degradation in terms of FID, CLIPscore and ImageReward accompanies safety filtering. These results establish that data curation and text encoder safety are complementary and independently effective interventions. At the same time, the remaining level of unsafety poses questions for future research about emerging capabilities and compositionality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training text-to-image models on datasets differing only in the fraction of unsafe images (0% to 9.6%) at scales from 100K to 8M produces a monotonic rise in output unsafety (measured by four classifiers) from 16.6% at zero contamination to 25.5% at 5%. A factorial design isolates proportion (not absolute count) as the operative variable. A 16.6% baseline at zero contamination is attributed to other components such as the frozen text encoder; an ablation with SafeCLIP lowers this floor to 9.6% while the dose-response persists. Safety filtering incurs no measurable degradation in FID, CLIPscore, or ImageReward, implying data curation and text-encoder safety are complementary interventions.
Significance. If the empirical results hold after verification of dataset construction and classifier validity, the work supplies a controlled demonstration that unsafe training proportion directly drives output unsafety, with the factorial design and text-encoder ablation providing evidence that proportion is causal and that residual risks arise from other model components. The absence of quality trade-offs strengthens the practical implication that curation is an effective, low-cost intervention complementary to encoder-level fixes.
major comments (3)
- [Methods] Methods (dataset construction and factorial design): The claim that datasets 'differ only in their fraction of unsafe images' is load-bearing for the monotonic dose-response and 'proportion, not count' conclusion, yet the manuscript supplies no description of the curation procedure, caption generation, visual distribution matching, or controls for other statistics. Without these details, alternative explanations (e.g., correlated changes in caption style or image quality) cannot be excluded.
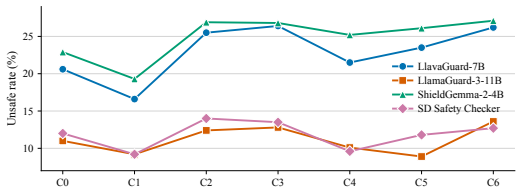
- [Results] Results (safety classifier evaluation): The reported rates (16.6% to 25.5%) and monotonic relationship rest on four independent classifiers, but no inter-classifier agreement statistics, calibration curves, or human validation against perceived unsafety are provided. This measurement gap directly affects the reliability of the baseline, the dose-response, and the text-encoder ablation results.
- [Ablations] Ablations (text encoder): The SafeCLIP ablation is cited to confirm the 16.6% floor arises from the text encoder, yet the manuscript does not report the precise experimental factors in the factorial design, sample sizes per cell, or any statistical test for the proportion-vs-count contrast. These omissions prevent assessment of whether the design isolates the claimed variable.
minor comments (1)
- [Abstract] The abstract states results across 'several dataset scales (100K to 8M)' but does not include a table or figure breaking down unsafety rates by scale; adding this would clarify whether the proportion effect is scale-invariant.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important gaps in methodological transparency and validation that we will address in revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Methods] Methods (dataset construction and factorial design): The claim that datasets 'differ only in their fraction of unsafe images' is load-bearing for the monotonic dose-response and 'proportion, not count' conclusion, yet the manuscript supplies no description of the curation procedure, caption generation, visual distribution matching, or controls for other statistics. Without these details, alternative explanations (e.g., correlated changes in caption style or image quality) cannot be excluded.
Authors: We agree that the current manuscript does not provide sufficient detail on dataset construction to fully substantiate the claim that the datasets differ solely in unsafe-image fraction. Although the source datasets and filtering criteria are referenced, explicit descriptions of the curation pipeline, caption generation method, visual-distribution matching steps, and controls for confounding statistics (image quality, caption style, etc.) are missing. In the revised manuscript we will add a dedicated subsection in Methods that documents these procedures and the controls employed. revision: yes
-
Referee: [Results] Results (safety classifier evaluation): The reported rates (16.6% to 25.5%) and monotonic relationship rest on four independent classifiers, but no inter-classifier agreement statistics, calibration curves, or human validation against perceived unsafety are provided. This measurement gap directly affects the reliability of the baseline, the dose-response, and the text-encoder ablation results.
Authors: We acknowledge that the reliability of the four safety classifiers requires additional quantitative support. We will add inter-classifier agreement statistics (pairwise agreement rates and Cohen’s kappa) and any available calibration information to the revised Results section. Human validation against perceived unsafety was not performed in the original study; we will therefore note this as a limitation and reference the classifiers’ prior validation in the literature rather than claim new human-grounded evidence. revision: partial
-
Referee: [Ablations] Ablations (text encoder): The SafeCLIP ablation is cited to confirm the 16.6% floor arises from the text encoder, yet the manuscript does not report the precise experimental factors in the factorial design, sample sizes per cell, or any statistical test for the proportion-vs-count contrast. These omissions prevent assessment of whether the design isolates the claimed variable.
Authors: We agree that the factorial design must be described with greater precision. The revised manuscript will explicitly list the experimental factors, the number of samples per cell, and the statistical tests (including any regression or ANOVA results) used to demonstrate that proportion, rather than absolute count, drives the observed effect. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential reductions
full rationale
The paper reports direct experimental outcomes from training identical models on datasets that differ only in unsafe image fraction (0% to 9.6%), then measuring generated image unsafety via four classifiers. No equations, fitted parameters, or derivations appear in the supplied text. Claims such as the monotonic rise from 16.6% to 25.5% and the proportion-vs-count factorial result are presented as observed data points, not quantities defined in terms of themselves or reduced via self-citation. The text-encoder ablation is likewise an independent experimental contrast. Because the central results rest on external measurement rather than any internal definitional loop, the derivation chain (such as it is) is self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Safety classifiers accurately measure image unsafety
- domain assumption Datasets differ only in the fraction of unsafe images
Reference graph
Works this paper leans on
-
[1]
Birhane and V
A. Birhane and V . U. Prabhu. Large image datasets: A pyrrhic win for computer vision? In 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1536–1546. IEEE, 2021
2021
-
[2]
A. Birhane, V . U. Prabhu, and E. Kahembwe. Multimodal datasets: misogyny, pornography, and malignant stereotypes.arXiv preprint arXiv:2110.01963, 2021
-
[3]
Birhane, S
A. Birhane, S. Han, V . Boddeti, S. Luccioni, et al. Into the laion’s den: Investigating hate in multimodal datasets.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[4]
Black, M
K. Black, M. Janner, Y . Du, I. Kostrikov, and S. Levine. Training diffusion models with reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[5]
Brack, F
M. Brack, F. Friedrich, D. Hintersdorf, L. Struppek, P. Schramowski, and K. Kersting. SEGA: Instructing text-to-image models using semantic guidance. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[6]
Brack, F
M. Brack, F. Friedrich, K. Kornmeier, L. Tsaban, P. Schramowski, K. Kersting, and A. Passos. LEdits++: Limitless image editing using text-to-image models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[7]
Brack, S
M. Brack, S. Katakol, F. Friedrich, P. Schramowski, H. Ravi, K. Kersting, and A. Kale. How to train your text-to-image model: Evaluating design choices for synthetic training captions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, October 2025
2025
-
[8]
Carlini, J
N. Carlini, J. Hayes, M. Nasr, M. Jagielski, V . Sehwag, F. Tramer, B. Balle, D. Ippolito, and E. Wallace. Extracting training data from diffusion models. In32nd USENIX Security Symposium (USENIX Security 23), pages 5253–5270, 2023. 11
2023
-
[9]
Stable diffusion safety checker
CompVis. Stable diffusion safety checker. https://huggingface.co/CompVis/ stable-diffusion-safety-checker , 2022. CLIP-based NSFW concept classifier shipped with Stable Diffusion
2022
-
[10]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorber, A. Sauer, F. Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In International Conference on Machine Learning (ICML), 2024
2024
-
[11]
AI Act: Regulatory Framework on Artificial Intelligence
European Commission. AI Act: Regulatory Framework on Artificial Intelligence. https:// digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai , 2024. Regulation (EU) 2024/1689. Accessed: 2026-05-19
2024
-
[12]
Friedrich, W
F. Friedrich, W. Stammer, P. Schramowski, and K. Kersting. Revision transformers: Instructing language models to change their values. InEuropean Conference on Artificial Intelligence (ECAI), 2023
2023
-
[13]
Friedrich, M
F. Friedrich, M. Brack, L. Struppek, D. Hintersdorf, P. Schramowski, S. Luccioni, and K. Ker- sting. Auditing and instructing text-to-image generation models on fairness.AI and Ethics, 2024
2024
-
[14]
Friedrich, S
F. Friedrich, S. Tedeschi, P. Schramowski, M. Brack, R. Navigli, H. Nguyen, B. Li, and K. Ker- sting. LLMs lost in translation: M-ALERT uncovers cross-linguistic safety inconsistencies. In ICLR Workshop on Building Trust in Language Models and Applications, 2025
2025
-
[15]
F. Friedrich, T. G. Welsch, M. Brack, et al. Beyond overcorrection: Evaluating diversity in T2I models with DivBench.arXiv preprint arXiv:2507.03015, 2025
-
[16]
S. Y . Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyrnis, T. Nguyen, R. Marten, M. Wortsman, D. Ghosh, J. Zhang, et al. Datacomp: In search of the next generation of multimodal datasets. Advances in Neural Information Processing Systems, 36, 2024
2024
-
[17]
Gandikota, J
R. Gandikota, J. Materzy´nska, J. Fiotto-Kaufman, and D. Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[18]
Gandikota, H
R. Gandikota, H. Orgad, Y . Belinkov, J. Materzy´nska, and D. Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024
2024
-
[19]
Gebru, J
T. Gebru, J. Morgenstern, B. Vecchione, J. W. Vaughan, H. Wallach, H. D. Iii, and K. Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
2021
-
[20]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, M. Riviere, S. Pathak, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024. URL https://arxiv.org/abs/ 2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
-
[22]
Nano banana (gemini 2.5 flash image): Multimodal image generation and editing
Google. Nano banana (gemini 2.5 flash image): Multimodal image generation and editing. https://www.digitalocean.com/resources/articles/nano-banana, 2025. AI image generation and editing model within the Gemini 2.5 Flash system
2025
- [23]
-
[24]
Härle, F
R. Härle, F. Friedrich, M. Brack, S. Wäldchen, B. Deiseroth, P. Schramowski, and K. Kersting. Measuring and guiding monosemanticity. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[25]
Helff, F
L. Helff, F. Friedrich, M. Brack, K. Kersting, and P. Schramowski. LlavaGuard: An open VLM- based framework for safeguarding vision datasets and models. InInternational Conference on Machine Learning (ICML), 2025. 12
2025
-
[26]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[27]
Hintersdorf, L
D. Hintersdorf, L. Struppek, M. Brack, F. Friedrich, P. Schramowski, and K. Kersting. Does CLIP know my face?Journal of Artificial Intelligence Research (JAIR), 2024
2024
-
[28]
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggine, and M. Khabsa. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[30]
Kumari, B
N. Kumari, B. Zhang, S.-Y . Wang, E. Shechtman, R. Zhang, and J.-Y . Zhu. Ablating concepts in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[31]
K. Lee, H. Liu, M. Ryu, O. Watkins, Y . Du, C. Boutilier, P. Abbeel, M. Ghavamzadeh, and S. S. Gu. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
G. Li, K. Chen, S. Zhang, J. Zhang, and T. Zhang. Art: Automatic red-teaming for text-to- image models to protect benign users. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
- [33]
-
[34]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, pages 740–755. Springer, 2014
2014
-
[35]
S. Lu, Z. Wang, L. Li, Y . Liu, and A. W.-K. Kong. MACE: Mass concept erasure in diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[36]
A. S. Luccioni, C. Akiki, M. Mitchell, and Y . Jernite. Stable bias: Evaluating societal represen- tations in diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023
2023
-
[37]
Midjourney: Ai-based image generation system
Midjourney, Inc. Midjourney: Ai-based image generation system. https://www.midjourney. com, 2025. Text-to-image model known for stylized and high-quality visual generation
2025
- [38]
-
[39]
Nakamura, M
T. Nakamura, M. Mishra, S. Tedeschi, Y . Chai, J. T. Stillerman, F. Friedrich, et al. Aurora- M: Open source continual pre-training for multilingual language and code. InInternational Conference on Computational Linguistics (COLING) Industry Track, 2025
2025
-
[40]
Prx: Text-to-image generation via rectified flow transformer.HuggingFace blog,
Photoroom. Prx: Text-to-image generation via rectified flow transformer.HuggingFace blog,
-
[41]
Available athttps://huggingface.co/Photoroom/prx-1024-t2i-beta
-
[42]
Poppi, T
S. Poppi, T. Poppi, F. Cocchi, M. Cornia, L. Baraldi, and R. Cucchiara. Safe-clip: Removing nsfw concepts from vision-and-language models. InEuropean Conference on Computer Vision, pages 340–356. Springer, 2024
2024
-
[43]
Y . Qu, X. Shen, X. He, M. Backes, S. Zannettou, and Y . Zhang. Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. InProceedings of the 2023 ACM SIGSAC conference on computer and communications security, pages 3403–3417, 2023. 13
2023
-
[44]
Quaye, A
J. Quaye, A. Parrish, O. Inel, C. Rastogi, H. R. Kirk, M. Kahng, E. Van Liemt, M. Bartolo, J. Tsang, J. White, et al. Adversarial nibbler: An open red-teaming method for identifying diverse harms in text-to-image generation. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 388–406, 2024
2024
-
[45]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[46]
Raffel, N
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[47]
Rando, D
J. Rando, D. Paleka, D. Lindner, L. Heim, and F. Tramèr. Red-teaming the stable diffusion safety filter. InNeurIPS ML Safety Workshop, 2022
2022
-
[48]
Reuel, A
A. Reuel, A. Ghosh, J. Chim, A. Tran, Y . Long, J. Mickel, et al. Who evaluates AI’s social impacts? mapping coverage and gaps in first and third party evaluations. InInternational Conference on Machine Learning (ICML), 2026
2026
-
[49]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[50]
P. Röttger, G. Attanasio, F. Friedrich, J. Goldzycher, et al. MSTS: A multimodal safety test suite for vision-language models.arXiv preprint arXiv:2501.10057, 2025
-
[51]
Schramowski, C
P. Schramowski, C. Tauchmann, and K. Kersting. Can machines help us answering question 16 in datasheets, and in turn reflecting on inappropriate content? InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1350–1361, 2022
2022
-
[52]
Schramowski, M
P. Schramowski, M. Brack, B. Deiseroth, and K. Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22522–22531, 2023
2023
-
[53]
Schuhmann, R
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in Neural Information Processing Systems, 35: 25278–25294, 2022
2022
-
[54]
Seshadri, S
P. Seshadri, S. Singh, and Y . Elazar. The bias amplification paradox in text-to-image generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), 2024
2024
-
[55]
Solaiman, Z
I. Solaiman, Z. Talat, W. Agnew, L. Ahmad, D. Baker, S. L. Blodgett, C. Chen, H. Daumé III, J. Dodge, I. Duan, et al. Evaluating the social impact of generative AI systems in systems and society. InOxford Handbook on the Foundations and Regulation of Generative AI, 2023
2023
-
[56]
Somepalli, V
G. Somepalli, V . Singla, M. Goldblum, J. Geiping, and T. Goldstein. Diffusion art or digital forgery? investigating data replication in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[57]
Startsev, A
V . Startsev, A. Ustyuzhanin, A. Kirillov, D. Baranchuk, and S. Kastryulin. Alchemist: Turning public text-to-image data into generative gold. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025
2025
-
[58]
Steed and A
R. Steed and A. Caliskan. Image representations learned with unsupervised pre-training contain human-like biases. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 701–713, 2021
2021
-
[59]
Struppek, D
L. Struppek, D. Hintersdorf, F. Friedrich, P. Schramowski, and K. Kersting. Exploiting cultural biases via homoglyphs in text-to-image synthesis.Journal of Artificial Intelligence Research (JAIR), 2023. 14
2023
-
[60]
Tedeschi, F
S. Tedeschi, F. Friedrich, P. Schramowski, K. Kersting, R. Navigli, H. Nguyen, and B. Li. ALERT: A comprehensive benchmark for assessing large language models’ safety through red teaming. InWorkshop on Red Teaming Generative AI Models, 2024
2024
-
[61]
Wallace, M
B. Wallace, M. Dang, R. Rafailov, L. Zhou, A. Lou, S. Purushwalkam, S. Ermon, C. Xiong, S. Joty, and N. Naik. Diffusion model alignment using direct preference optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[62]
B. Wang, W. Chen, H. Pei, C. Xie, M. Kang, C. Zhang, C. Xu, Z. Xiong, R. Dutta, R. Schaeffer, S. T. Truong, S. Arora, M. Mazeika, D. Hendrycks, Z. Lin, Y . Cheng, S. Koyejo, D. Song, and B. Li. Decodingtrust: A comprehensive assessment of trustworthiness in GPT models. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benc...
2023
-
[63]
C. Wu, J. Li, J. Zhou, J. Lin, K. Gao, K. Yan, S. ming Yin, S. Bai, X. Xu, Y . Chen, Y . Chen, Z. Tang, Z. Zhang, Z. Wang, A. Yang, B. Yu, C. Cheng, D. Liu, D. Li, H. Zhang, H. Meng, H. Wei, J. Ni, K. Chen, K. Cao, L. Peng, L. Qu, M. Wu, P. Wang, S. Yu, T. Wen, W. Feng, X. Xu, Y . Wang, Y . Zhang, Y . Zhu, Y . Wu, Y . Cai, and Z. Liu. Qwen-image technical report,
-
[64]
URLhttps://arxiv.org/abs/2508.02324
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[66]
Y . Yang, B. Hui, H. Yuan, N. Gong, and Y . Cao. SneakyPrompt: Jailbreaking text-to-image generative models. InProceedings of the IEEE Symposium on Security and Privacy (S&P), 2024
2024
- [67]
- [68]
-
[69]
Zhang, K
E. Zhang, K. Wang, X. Xu, Z. Wang, and H. Shi. Forget-me-not: Learning to forget in text-to- image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2024
2024
-
[70]
Zheng, L
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, J. E. Gonzalez, I. Stoica, C. Barrett, and Y . Sheng. Sglang: Efficient execution of structured language model programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 15 Appendix A Dose–response modeling To summarize potential saturation in the dose–response...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.