Natural Functional Gradients for Smooth Trajectory Optimization
Pith reviewed 2026-06-29 11:52 UTC · model grok-4.3
The pith
Natural functional gradients produce smoother and more feasible robot trajectories in narrow passages via function-space updates estimated from black-box samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Optimizing a Gaussian-smoothed surrogate objective through natural functional gradients, estimated by Monte-Carlo sampling of black-box trajectory evaluations, yields trajectories that remain collision-free and smooth in highly constrained manipulation tasks, with regularity controlled independently of any chosen time discretization.
What carries the argument
The natural functional gradient in function space, which supplies geometry-aware updates while a Gaussian-smoothed surrogate regularizes the landscape and permits independent control of trajectory regularity.
If this is right
- Trajectory regularity can be adjusted without changing the time discretization chosen for the problem.
- The estimator applies when analytic gradients are unavailable or noisy due to collision and contact simulation.
- Motions achieve higher feasibility and lower jerk than representative planning and trajectory-optimization baselines in narrow-clearance settings.
- Updates operate intrinsically in function space, preserving global trajectory properties across different discretizations.
Where Pith is reading between the lines
- The black-box estimator could be paired with learned proposal distributions to reduce sampling variance in high-dimensional trajectory spaces.
- The same function-space construction might transfer to non-robotic problems that optimize curves or surfaces under geometric constraints.
- In contact-rich settings the method may exhibit lower sensitivity to simulator noise than methods that rely on local analytic derivatives.
Load-bearing premise
A practical Monte-Carlo estimator of the natural functional gradient can be formed from black-box trajectory evaluations alone and stays reliable when analytic gradients cannot be computed because of collision checking or contact simulation.
What would settle it
On a narrow-passage manipulation task, the method produces trajectories whose collision rate or jerk measure exceeds that of a standard baseline optimizer such as CHOMP when both are run with the same number of objective evaluations.
Figures


read the original abstract
Generating collision-free and smooth motions remains a central challenge in robotic manipulation, particularly in cluttered environments and narrow passages where feasible regions are highly constrained and fragmented. We propose a trajectory optimization framework that performs geometry-aware updates directly in function space using natural functional gradients. The method optimizes a Gaussian-smoothed surrogate objective that regularizes the optimization landscape through smooth trajectory perturbations while preserving trajectory-level structure. Because the updates are defined intrinsically in function space, trajectory regularity can be controlled independently of a particular time discretization. We derive a practical Monte-Carlo estimator of the natural functional gradient that requires only black-box trajectory evaluations, making the method applicable when analytic gradients are unavailable or unreliable due to collision checking and contact-rich simulation. Experiments on constrained robotic manipulation tasks demonstrate that the proposed method improves trajectory feasibility and produces smoother motions than representative planning and trajectory optimization baselines in environments with narrow geometric clearances. Additional results, videos, and implementation details are available at the project page: https://kisangpark.github.io/natural-functional-gradient/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a trajectory optimization framework for robotic manipulation that performs geometry-aware updates in function space via natural functional gradients. It optimizes a Gaussian-smoothed surrogate objective to regularize the landscape while preserving trajectory structure, derives a Monte-Carlo estimator of the natural functional gradient that uses only black-box trajectory evaluations, and reports improved feasibility and smoothness over baselines on constrained tasks with narrow clearances.
Significance. If the Monte-Carlo estimator is shown to be reliable, the approach could enable black-box trajectory optimization in contact-rich settings where analytic gradients fail, offering a function-space alternative that decouples regularity from discretization. The emphasis on intrinsic function-space updates and Gaussian smoothing is a potential strength for handling fragmented feasible regions.
major comments (2)
- [Abstract / Methods (Monte-Carlo estimator)] Abstract and methods (estimator derivation): the claim that a practical Monte-Carlo estimator of the natural functional gradient exists, requires only black-box evaluations, and remains effective under collision checking and contact-rich simulation is load-bearing for the central contribution, yet no variance bounds, sample-complexity guarantees, or analysis of estimator behavior on piecewise-constant/discontinuous costs are provided; Gaussian smoothing alone does not automatically control variance for narrow-clearance collision indicators.
- [Experiments] Experiments section: the reported gains in trajectory feasibility and smoothness over baselines lack ablations on Monte-Carlo sample count versus success rate or failure modes in narrow passages; without these, it is unclear whether the improvements are attributable to the black-box estimator or to hidden analytic components, favorable seeds, or task-specific tuning.
minor comments (1)
- [Abstract] The project page link is provided but the manuscript should include a brief statement on code/data availability for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying the scope of our claims and outlining planned revisions to strengthen the presentation of the Monte-Carlo estimator and experimental validation.
read point-by-point responses
-
Referee: Abstract and methods (estimator derivation): the claim that a practical Monte-Carlo estimator of the natural functional gradient exists, requires only black-box evaluations, and remains effective under collision checking and contact-rich simulation is load-bearing for the central contribution, yet no variance bounds, sample-complexity guarantees, or analysis of estimator behavior on piecewise-constant/discontinuous costs are provided; Gaussian smoothing alone does not automatically control variance for narrow-clearance collision indicators.
Authors: We agree that the manuscript provides a derivation of the Monte-Carlo estimator from the Gaussian-smoothed surrogate but does not include variance bounds, sample-complexity guarantees, or a dedicated analysis of its behavior on discontinuous collision costs. The smoothing regularizes the objective to enable gradient estimation from black-box evaluations, yet we acknowledge it does not inherently bound estimator variance in narrow-clearance settings. In revision we will add an explicit discussion of observed empirical variance across the reported tasks, state the lack of theoretical guarantees as a limitation, and clarify that the contribution centers on the practical applicability demonstrated in contact-rich simulation rather than on formal concentration results. revision: partial
-
Referee: Experiments section: the reported gains in trajectory feasibility and smoothness over baselines lack ablations on Monte-Carlo sample count versus success rate or failure modes in narrow passages; without these, it is unclear whether the improvements are attributable to the black-box estimator or to hidden analytic components, favorable seeds, or task-specific tuning.
Authors: The experiments use only black-box trajectory evaluations with no analytic gradient components. To address the concern, we will add an ablation study that varies the Monte-Carlo sample count, reports corresponding success rates, and documents failure modes specifically in narrow-passage tasks. This will help isolate the estimator's contribution from other experimental factors. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a derivation of a Monte-Carlo estimator for natural functional gradients from functional analysis, with the estimator explicitly constructed to use only black-box evaluations. Experimental claims of improved feasibility and smoothness rest on direct comparisons to baselines rather than any reduction of outputs to fitted inputs or self-referential definitions by construction. No load-bearing step matches the enumerated circularity patterns; the method remains independent of its own fitted values or prior self-citations for its core claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Probabilistic roadmaps for path planning in high- dimensional configuration spaces,
L. E. Kavraki, P. ˇSvestka, J. Latombe, and M. H. Over- mars, “Probabilistic roadmaps for path planning in high- dimensional configuration spaces,”IEEE Transactions on Robotics and Automation, vol. 12, no. 4, pp. 566–580, 1996
1996
-
[2]
Rapidly-exploring random trees: A new tool for path planning,
S. M. LaValle, “Rapidly-exploring random trees: A new tool for path planning,” Tech. Rep. TR 98-11, Computer Science Department, Iowa State University, Oct. 1998
1998
-
[3]
Sampling-based algorithms for optimal motion planning,
S. Karaman and E. Frazzoli, “Sampling-based algorithms for optimal motion planning,”The International Journal of Robotics Research, vol. 30, no. 7, pp. 846–894, 2011
2011
-
[4]
Chomp: Covariant hamiltonian opti- mization for motion planning,
M. Zucker, N. Ratliff, A. D. Dragan, M. Pivtoraiko, M. Klingensmith, C. M. Dellin, J. A. Bagnell, and PREPRINT VERSION S. S. Srinivasa, “Chomp: Covariant hamiltonian opti- mization for motion planning,”The International Journal of Robotics Research, vol. 32, no. 9-10, pp. 1164–1193, 2013
2013
-
[5]
Mo- tion planning with sequential convex optimization and convex collision checking,
J. Schulman, Y . Duan, J. Ho, A. Lee, I. Awwal, H. Brad- low, J. Pan, S. Patil, K. Goldberg, and P. Abbeel, “Mo- tion planning with sequential convex optimization and convex collision checking,”The International Journal of Robotics Research, vol. 33, no. 9, pp. 1251–1270, 2014
2014
-
[6]
Stomp: Stochastic trajectory optimization for motion planning,
M. Kalakrishnan, S. Chitta, E. Theodorou, P. Pastor, and S. Schaal, “Stomp: Stochastic trajectory optimization for motion planning,” inProceedings of the IEEE Interna- tional Conference on Robotics and Automation (ICRA), pp. 4569–4574, 2011
2011
-
[7]
arXiv preprint arXiv:2310.17274 (2023)
B. Sundaralingam, S. Hari, A. Fishman, C. Garrett, K. V . Wyk, V . Blukis, A. Millane, H. Oleynikova, A. Handa, F. Ramos, N. Ratliff, and D. Fox, “Curobo: Parallelized collision-free minimum-jerk robot motion generation,” arXiv preprint arXiv:2310.17274, 2023
-
[8]
Functional gradient motion planning in reproducing kernel hilbert spaces,
Z. Marinho, B. Boots, A. D. Dragan, A. Byravan, G. J. Gordon, and S. S. Srinivasa, “Functional gradient motion planning in reproducing kernel hilbert spaces,” inPro- ceedings of Robotics: Science and Systems (RSS), 2016
2016
-
[9]
Gaussian process motion planning,
M. Mukadam, X. Yan, and B. Boots, “Gaussian process motion planning,” inProceedings of the IEEE Interna- tional Conference on Robotics and Automation (ICRA), pp. 9–15, 2016
2016
-
[10]
Mo- tion planning as probabilistic inference using gaussian processes and factor graphs,
J. Dong, M. Mukadam, F. Dellaert, and B. Boots, “Mo- tion planning as probabilistic inference using gaussian processes and factor graphs,” inProceedings of Robotics: Science and Systems (RSS), 2016
2016
-
[11]
A generalized path integral control approach to reinforcement learn- ing,
E. A. Theodorou, J. Buchli, and S. Schaal, “A generalized path integral control approach to reinforcement learn- ing,”Journal of Machine Learning Research, vol. 11, pp. 3137–3154, 2010
2010
-
[12]
Robot trajectory optimization using ap- proximate inference,
M. Toussaint, “Robot trajectory optimization using ap- proximate inference,” inProceedings of the 26th Annual International Conference on Machine Learning (ICML), pp. 1049–1056, 2009
2009
-
[13]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
S. Levine, “Reinforcement learning and control as prob- abilistic inference: Tutorial and review,”arXiv preprint arXiv:1805.00909, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Completely derandom- ized self-adaptation in evolution strategies,
N. Hansen and A. Ostermeier, “Completely derandom- ized self-adaptation in evolution strategies,”Evolutionary computation, vol. 9, no. 2, pp. 159–195, 2001
2001
-
[15]
Online convex optimization in the bandit setting: gradient de- scent without a gradient,
A. Flaxman, A. T. Kalai, and H. B. McMahan, “Online convex optimization in the bandit setting: gradient de- scent without a gradient,” inProceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA, Vancouver, British Columbia, Canada, January 23-25, 2005, pp. 385–394, SIAM, 2005
2005
-
[16]
Optimal rates for zero-order convex opti- mization: The power of two function evaluations,
J. C. Duchi, M. I. Jordan, M. J. Wainwright, and A. Wibisono, “Optimal rates for zero-order convex opti- mization: The power of two function evaluations,”IEEE Trans. Inf. Theory, vol. 61, no. 5, pp. 2788–2806, 2015
2015
-
[17]
A theoretical analysis of optimization by gaussian continuation,
H. Mobahi and J. W. Fisher III, “A theoretical analysis of optimization by gaussian continuation,” inProc. of the Twenty-Ninth AAAI Conference on Artificial Intelligence, January 25-30, 2015, Austin, Texas, USA(B. Bonet and S. Koenig, eds.), pp. 1205–1211, AAAI Press, 2015
2015
-
[18]
On grad- uated optimization for stochastic non-convex problems,
E. Hazan, K. Y . Levy, and S. Shalev-Shwartz, “On grad- uated optimization for stochastic non-convex problems,” inProceedings of the 33nd International Conference on Machine Learning, ICML, New York City, NY, USA, June 19-24, 2016(M. Balcan and K. Q. Weinberger, eds.), vol. 48, pp. 1833–1841, JMLR.org, 2016
2016
-
[19]
RRT-Connect: An efficient approach to single-query path planning,
J. J. K. Jr. and S. M. LaValle, “RRT-Connect: An efficient approach to single-query path planning,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pp. 995–1001, 2000
2000
-
[20]
Chomp: Gradient optimization techniques for efficient motion planning,
N. Ratliff, M. Zucker, J. A. Bagnell, and S. Srinivasa, “Chomp: Gradient optimization techniques for efficient motion planning,” inProceedings of the IEEE Interna- tional Conference on Robotics and Automation (ICRA), pp. 489–494, May 2009
2009
-
[21]
Finding locally optimal, collision-free trajectories with sequential convex optimization,
J. Schulman, J. Ho, A. Lee, I. Awwal, H. Bradlow, and P. Abbeel, “Finding locally optimal, collision-free trajectories with sequential convex optimization,” inPro- ceedings of Robotics: Science and Systems (RSS), 2013
2013
-
[23]
N. Hansen, Y . Akimoto, and P. Baudis, “CMA-ES/pycma on Github.” Zenodo, DOI:10.5281/zenodo.2559634, Feb. 2019
-
[24]
Random gradient- free minimization of convex functions,
Y . E. Nesterov and V . G. Spokoiny, “Random gradient- free minimization of convex functions,”Found. Comput. Math., vol. 17, no. 2, pp. 527–566, 2017
2017
-
[25]
Generalizing gaussian smoothing for random search,
K. Gao and O. Sener, “Generalizing gaussian smoothing for random search,” inInternational Conference on Ma- chine Learning, 17-23 July 2022, Baltimore, Maryland, USA, vol. 162 ofProceedings of Machine Learning Research, pp. 7077–7101, PMLR, 2022
2022
-
[26]
Natural gradient works efficiently in learn- ing,
S. Amari, “Natural gradient works efficiently in learn- ing,”Neural Computation, vol. 10, no. 2, pp. 251–276, 1998
1998
-
[27]
V . I. Bogachev,Gaussian measures. No. 62, American Mathematical Soc., 1998
1998
-
[28]
Da Prato and J
G. Da Prato and J. Zabczyk,Stochastic equations in infinite dimensions, vol. 152. Cambridge university press, 2014
2014
-
[29]
Riesz and B
F. Riesz and B. S. Nagy,Functional analysis. Courier Corporation, 2012
2012
-
[30]
Model Predictive Path Integral Control using Covariance Variable Importance Sampling
G. Williams, A. Aldrich, and E. Theodorou, “Model predictive path integral control using covariance variable importance sampling,”arXiv preprint arXiv:1509.01149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
Sampling-based path planning on configuration-space costmaps,
L. Jaillet, J. Cort ´es, and T. Sim ´eon, “Sampling-based path planning on configuration-space costmaps,”IEEE Transactions on Robotics, vol. 26, no. 4, pp. 635–646, 2010. PREPRINT VERSION SUPPLEMENTARYAPPENDIX APPENDIXA PROOF Lemma A.1(Directional derivative identity).Letε∼ N(0, σ 2Σ). Then, for anyµ∈ Hand anyh∈ H Σ = Range(Σ1/2), the directional derivati...
2010
-
[32]
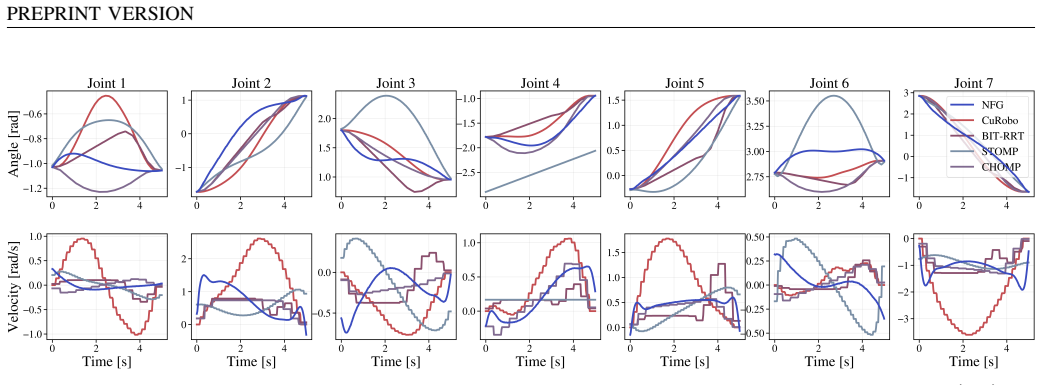
BiTRRT:For sampling-based planners such as BiTRRT, the outputs typically consist of sparse geometric waypoints that connect the start and goal configurations. When these sparse configurations are linearly interpolated to match the 100 Hz shared execution resolution, collisions were occasionally observed along the resampled trajectory segments. This phenom...
-
[33]
These methods optimize a fixed set of waypoints to minimize a cost function
CHOMP and STOMP:For discrete-time optimization methods such as CHOMP and STOMP, the discrepancies observed under the unified evaluation were primarily driven by kinematic inconsistencies arising from the discretization of the trajectory. These methods optimize a fixed set of waypoints to minimize a cost function. Our analysis revealed that while the optim...
-
[34]
cuRobo:For cuRobo, we utilized the built-in functionality to approximate the attached cylindrical object and robot links using collision spheres. While this approximation is efficient for collision checking within the planner’s native framework, it introduces a geometric discrepancy compared to the high-fidelity meshes used in the MuJoCo simulator. This d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.