Learning When to Optimize: Verified Optimization Skills from Expert GPU-Kernel Lineages
Pith reviewed 2026-06-29 12:24 UTC · model grok-4.3
The pith
KLineage reverses expert GPU kernel lineages to extract verified optimization skills that teach LLMs precisely when optimizations apply.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
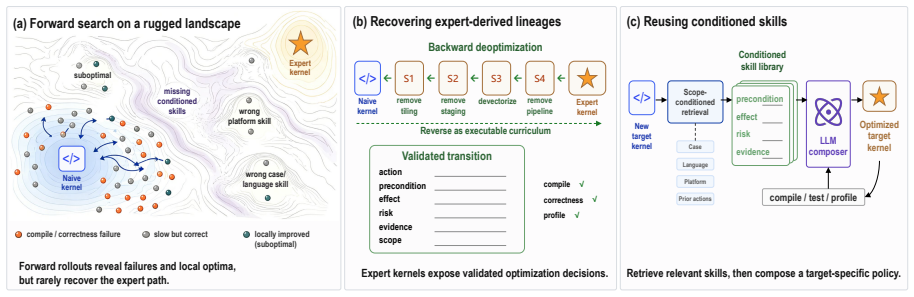
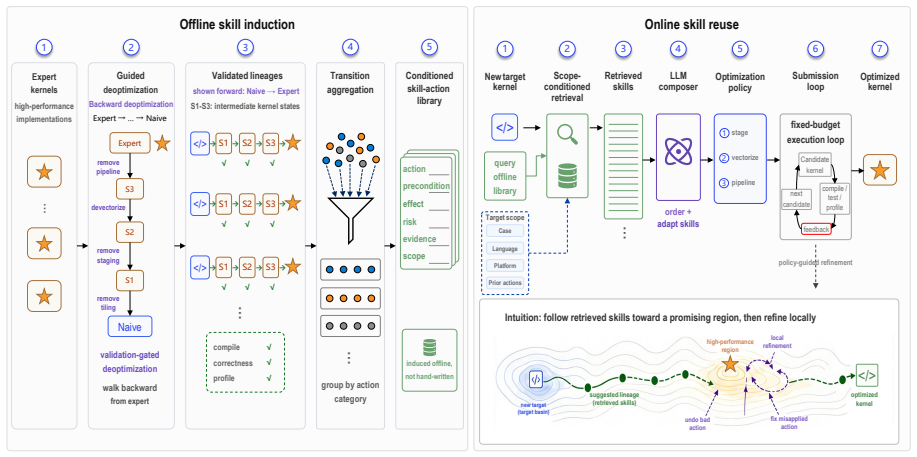
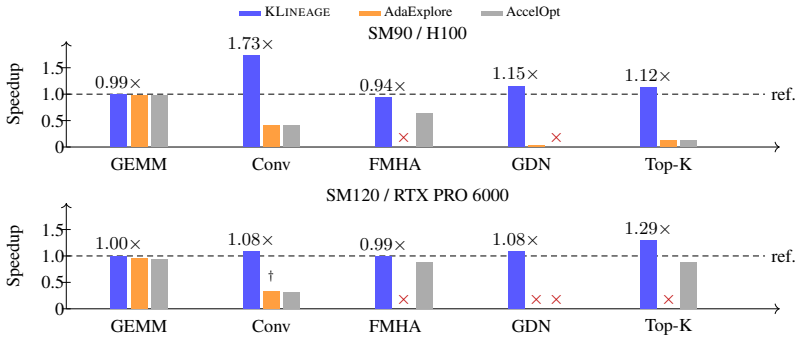
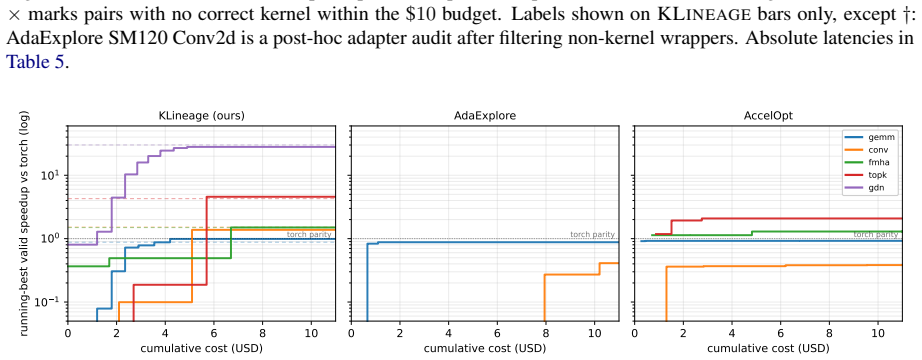
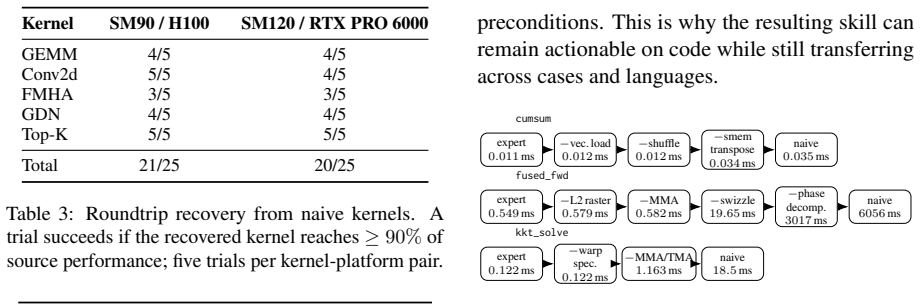
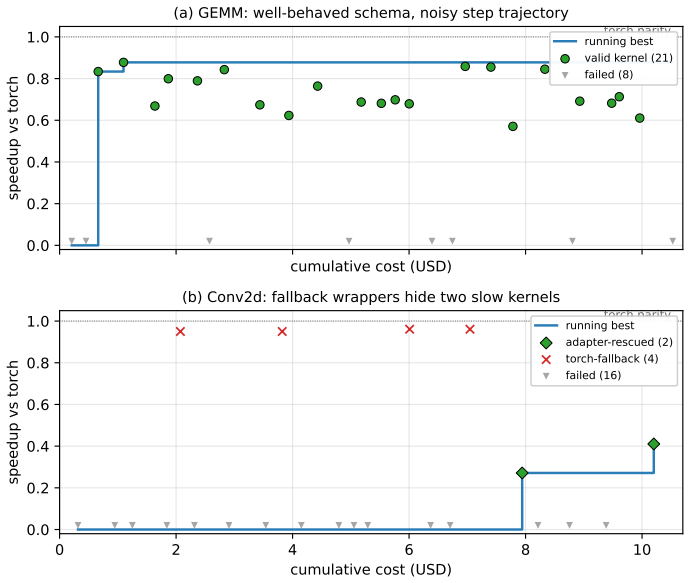
KLineage learns optimization skills from expert kernels by walking backward through validation-gated simplifications, reversing each accepted step into a reusable skill that records the optimization intent, its application location in code, validity conditions, effect, and avoided failures. A downstream LLM applies these skills to new code under the same compile, correctness, and profile gates. This lineage-derived curriculum outperforms memory-based LLM-kernel baselines on five expert workloads across two NVIDIA architectures in both kernel quality and optimization efficiency under fixed budget, with a 22-instance held-out check against memorization.
What carries the argument
KLineage, the process of reversing expert kernel lineages via validation-gated simplifications to produce skills that encode optimization applicability conditions.
If this is right
- The skills improve both final kernel quality and number of optimization steps needed relative to memory baselines.
- The same skill set works across two different NVIDIA architectures without retraining.
- A 22-instance held-out check shows the method avoids simple memorization of source cases.
- Skills are applied only when the original validation gates are satisfied, preserving correctness.
Where Pith is reading between the lines
- Similar backward extraction could be applied to other code-generation domains where expert examples exist but applicability rules are implicit.
- The approach suggests that expert code contains explicit, transferable knowledge about optimization preconditions that forward search alone does not discover.
- If the skills remain stable across larger sets of workloads, the method could shrink the effective search space for LLM kernel agents.
- Testing the same lineage reversal on CPU or accelerator kernels would reveal whether the technique generalizes beyond GPU code.
Load-bearing premise
Skills extracted from expert lineages will transfer to new code surfaces while preserving soundness and performance gains when applied under the same compile, correctness, and profile gates.
What would settle it
Applying the extracted skills to a new held-out workload produces either invalid kernels or no improvement in final performance or optimization steps compared with memory-based baselines under identical budget and gates.
Figures
read the original abstract
LLM-based agents are increasingly used to generate GPU kernels, but they often know what optimizations to try without knowing when those optimizations are sound. We introduce KLineage, which learns this missing "when" knowledge from expert kernels: instead of relying on forward rollouts, KLineage walks expert implementations backward through validation-gated simplifications and reverses each accepted step into a reusable optimization skill. Each skill records not only the optimization intent, but also where it applies in code, what conditions made it valid, what effect it had, and what failures its assumptions avoid. A downstream LLM materializes these skills on new code surfaces under the same compile/correctness/profile gate. On five expert workloads across two NVIDIA architectures, these lineage-derived skills serve as an effective optimization curriculum, exceeding recent memory-based LLM-kernel baselines in both final kernel quality and optimization efficiency under the same fixed budget. We additionally use a separate 22-instance held-out check as a sanity test against source-case memorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KLineage, which extracts reusable optimization skills from expert GPU-kernel lineages by walking backward through validation-gated simplifications and reversing each accepted step. Each skill records the optimization intent, applicability location in code, validity conditions, performance effect, and avoided failure modes. A downstream LLM then applies these skills to new code surfaces under identical compile/correctness/profile gates. On five expert workloads across two NVIDIA architectures the lineage-derived skills are reported to outperform recent memory-based LLM-kernel baselines in both final kernel quality and optimization efficiency under a fixed budget; a separate 22-instance held-out set serves only as a sanity check against source-case memorization.
Significance. If the extracted skills prove transferable while preserving soundness and gains, the approach would supply a concrete mechanism for learning the missing 'when' component of optimization from verified expert lineages rather than forward rollouts. The fixed-budget comparison and explicit recording of conditions and failure modes are methodological strengths that could be reused beyond the current setting.
major comments (1)
- [Abstract] Abstract: the central claim that the lineage-derived skills constitute an effective optimization curriculum that exceeds baselines on new code surfaces is not supported by any quantitative results on the 22 held-out instances. These instances are described solely as a sanity test against source-case memorization; no performance, efficiency, or correctness numbers are supplied for them, leaving the transfer claim unverified.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the methodological strengths of the work. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the lineage-derived skills constitute an effective optimization curriculum that exceeds baselines on new code surfaces is not supported by any quantitative results on the 22 held-out instances. These instances are described solely as a sanity test against source-case memorization; no performance, efficiency, or correctness numbers are supplied for them, leaving the transfer claim unverified.
Authors: We agree that the abstract's phrasing could be read as implying quantitative support for transfer specifically on the 22 held-out instances, yet the manuscript supplies none. The five expert workloads constitute the primary evaluation of skill transfer to new code surfaces, while the 22-instance set functions only as a memorization sanity check. To resolve the ambiguity and strengthen the transfer claim, the revised manuscript will include the corresponding performance, efficiency, and correctness metrics for the 22 instances. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper derives optimization skills by walking expert GPU-kernel implementations backward through validation-gated simplifications and reversing accepted steps into reusable skills that record intent, applicability conditions, effects, and avoided failures. These skills are then materialized by a downstream LLM on code surfaces under the same compile/correctness/profile gates. No step reduces by construction to its inputs via self-definition, fitted parameters renamed as predictions, or self-citation load-bearing; the reported outperformance on the five expert workloads is an empirical comparison against external baselines rather than a tautological restatement of the lineage extraction process itself. The 22 held-out instances serve only as a memorization sanity check and introduce no circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert kernels contain sequences of simplifications that remain valid when reversed into general skills.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
- [2]
- [3]
-
[4]
Shiyi Cao, Ziming Mao, Joseph E. Gonzalez, and Ion Stoica. 2026. https://arxiv.org/abs/2602.19128 K-search: Llm kernel generation via co-evolving intrinsic world model . Preprint, arXiv:2602.19128
- [5]
-
[6]
Joshua H Davis, Klaudiusz Rydzy, Srinivasan Ramesh, Aadit Nilay, Daniel Nichols, Swapna Raj, Nikhil Jain, and Abhinav Bhatele. 2026. Keet: Explaining performance of gpu kernels using llm agents. arXiv preprint arXiv:2605.04467
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Kris Shengjun Dong, Sahil Modi, Dima Nikiforov, Sana Damani, Edward Lin, Siva Kumar Sastry Hari, and Christos Kozyrakis. 2026. https://arxiv.org/abs/2602.14293 Kernelblaster: Continual cross-task cuda optimization via memory-augmented in-context reinforcement learning . Preprint, arXiv:2602.14293
-
[8]
He Du, Qiming Ge, Jiakai Hu, Aijun Yang, Zheng Cai, Zixian Huang, Sheng Yuan, Qinxiu Cheng, Xinchen Xie, Yicheng Chen, Yining Li, Jiaxing Xie, Huanan Dong, Yaguang Wu, Xiangjun Huang, Jian Yang, Hui Wang, Bowen Zhou, Bowen Li, and 2 others. 2026 a . https://arxiv.org/abs/2603.28342 Kernel-smith: A unified recipe for evolutionary kernel optimization . Prep...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Weihua Du, Jingming Zhuo, Yixin Dong, Andre Wang He, Weiwei Sun, Zeyu Zheng, Manupa Karunaratne, Ivan Fox, Tim Dettmers, Tianqi Chen, Yiming Yang, and Sean Welleck. 2026 b . https://arxiv.org/abs/2604.16625 Adaexplore: Failure-driven adaptation and diversity-preserving search for efficient kernel generation . Preprint, arXiv:2604.16625
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
FlagOpen Project . 2026. Flaggems: A high-performance triton operator library for large language models. https://github.com/FlagOpen/FlagGems. V5.0.2, accessed 2026-05
2026
- [11]
- [12]
- [13]
-
[14]
Jianling Li, Shangzhan Li, Zhenye Gao, Qi Shi, Yuxuan Li, Zefan Wang, Jiacheng Huang, Haojie Wang, Jianrong Wang, Xu Han, Zhiyuan Liu, and Maosong Sun. 2025 b . https://arxiv.org/abs/2502.14752 Tritonbench: Benchmarking large language model capabilities for generating Triton operators . Preprint, arXiv:2502.14752
- [15]
- [16]
-
[17]
Mark Lou and Stefan K Muller. 2024. Automatic static analysis-guided optimization of cuda kernels. In Proceedings of the 15th International Workshop on Programming Models and Applications for Multicores and Manycores, pages 11--21
2024
-
[18]
Xing Ma, Yangjie Zhou, Wu Sun, Zihan Liu, Jingwen Leng, Yun Lin, Shixuan Sun, Minyi Guo, and Jin Song Dong. 2026. Cubridge: An llm-based framework for understanding and reconstructing high-performance attention kernels. arXiv preprint arXiv:2605.05023
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Gabriele Oliaro, Yichao Fu, May Jiang, Owen Lu, Junli Wang, Zhihao Jia, Hao Zhang, and Samyam Rajbhandari. 2026. https://arxiv.org/abs/2605.23215 Fastkernels: Benchmarking gpu kernel generation in production . Preprint, arXiv:2605.23215
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
KernelBench: Can LLMs Write Efficient GPU Kernels?
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher R \'e , and Azalia Mirhoseini. 2025. https://arxiv.org/abs/2502.10517 Kernelbench: Can llms write efficient GPU kernels? Preprint, arXiv:2502.10517
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
Tara Saba, Anne Ouyang, Xujie Si, and Fan Long. 2026. Cutegen: An llm-based agentic framework for generation and optimization of high-performance gpu kernels using cute. arXiv preprint arXiv:2604.01489
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Spector, Simran Arora, Aaryan Singhal, Arjun Parthasarathy, Daniel Y
Benjamin F. Spector, Simran Arora, Aaryan Singhal, Arjun Parthasarathy, Daniel Y. Fu, and Christopher R \'e . 2025. https://openreview.net/forum?id=0fJfVOSUra ThunderKittens : Simple, fast, and adorable AI kernels . In The Thirteenth International Conference on Learning Representations (ICLR)
2025
- [24]
-
[25]
Jianghui Wang, Vinay Joshi, Saptarshi Majumder, Xu Chao, Bin Ding, Ziqiong Liu, Pratik Prabhanjan Brahma, Dong Li, Zicheng Liu, and Emad Barsoum. 2025. https://arxiv.org/abs/2507.23194 Geak: Introducing Triton kernel AI agent and evaluation benchmarks . Preprint, arXiv:2507.23194
-
[26]
Anjiang Wei, Tianran Sun, Yogesh Seenichamy, Hang Song, Anne Ouyang, Azalia Mirhoseini, Ke Wang, and Alex Aiken. 2025. https://openreview.net/forum?id=IZKZIcPaHz Astra: A multi-agent system for GPU kernel performance optimization . In NeurIPS 2025 Fourth Workshop on Deep Learning for Code
2025
- [27]
-
[28]
Genghan Zhang, Shaowei Zhu, Anjiang Wei, Zhenyu Song, Allen Nie, Zhen Jia, Nandita Vijaykumar, Yida Wang, and Kunle Olukotun. 2025. Accelopt: A self-improving llm agentic system for ai accelerator kernel optimization. arXiv preprint arXiv:2511.15915
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Xinguo Zhu, Shaohui Peng, Jiaming Guo, Yunji Chen, Qi Guo, Yuanbo Wen, Hang Qin, Ruizhi Chen, Qirui Zhou, Ke Gao, Yanjun Wu, Chen Zhao, and Ling Li. 2026. https://doi.org/10.1609/aaai.v40i34.40155 QiMeng-Kernel : Macro-thinking micro-coding paradigm for LLM -based high-performance GPU kernel generation . Proceedings of the AAAI Conference on Artificial In...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.