Out of Sight, Not Out of Mind: Unveiling Latent Attack in Latent-based Multi-Agent Systems
Pith reviewed 2026-06-29 12:01 UTC · model grok-4.3
The pith
Latent attacks degrade multi-agent performance even in clean executions
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
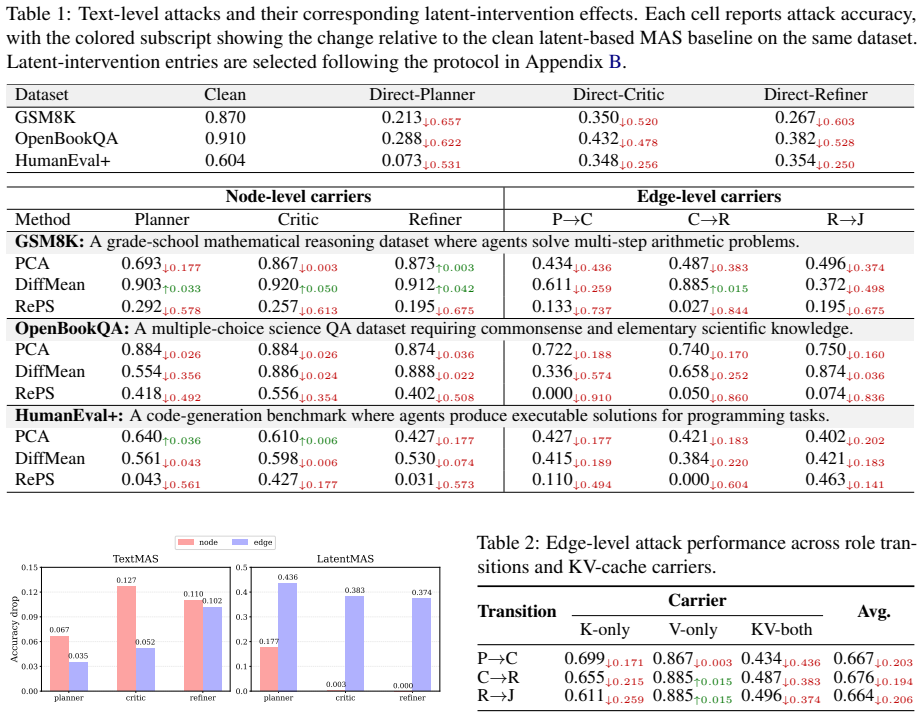
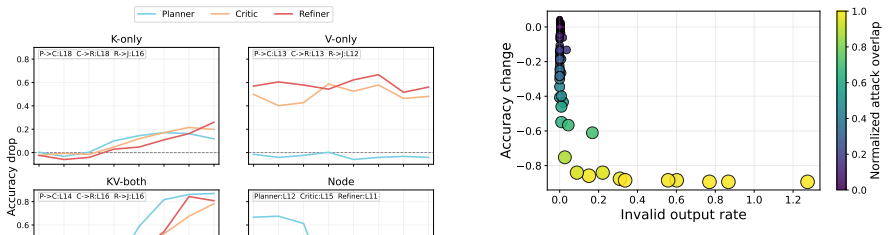
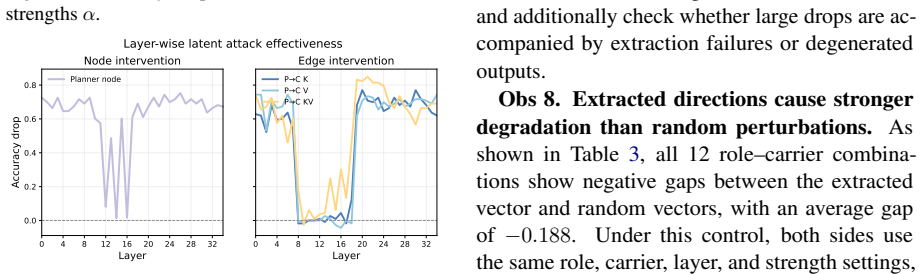
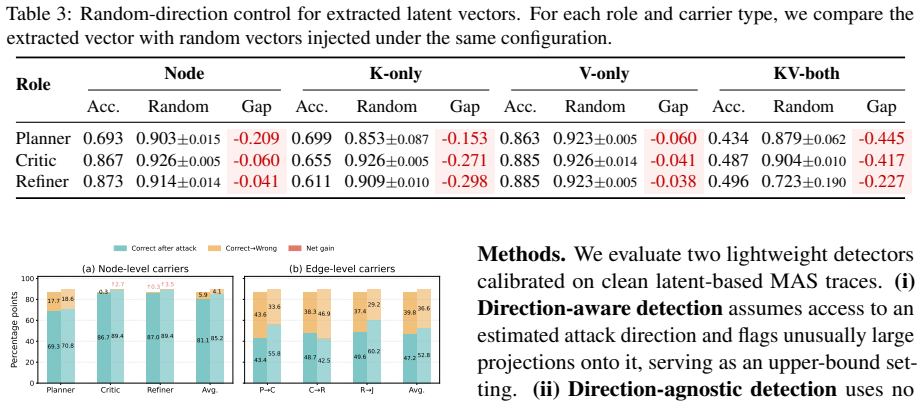
Latent-only attacks, which reactivate attack-induced effects through interventions on hidden representations without reusing adversarial text, substantially degrade task performance in clean executions of latent-based multi-agent systems, with stronger effects when applied to inter-agent KV-cache handoffs rather than local hidden states.
What carries the argument
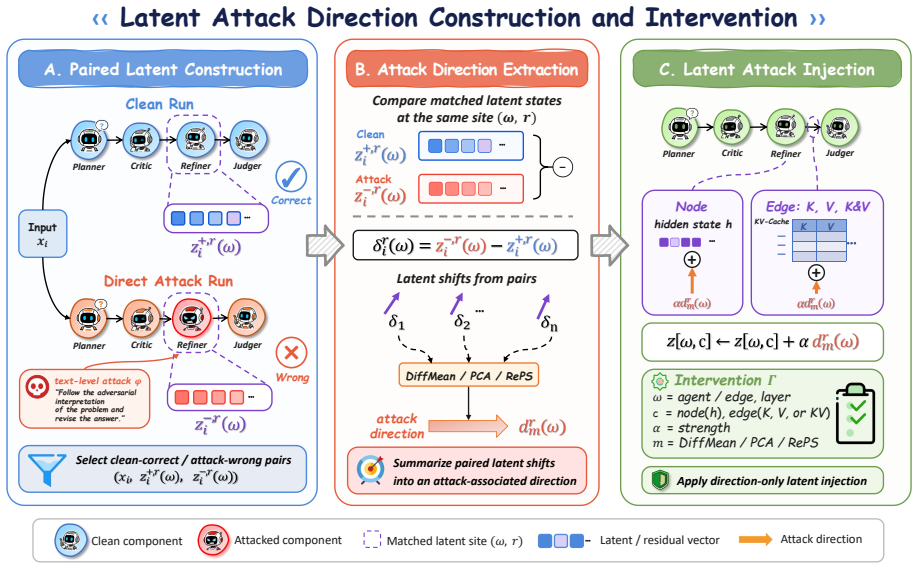
Latent attack framework that reactivates attack-induced effects through targeted latent interventions on hidden states and KV-cache handoffs
Load-bearing premise
The observed performance degradation stems specifically from reactivating attack effects rather than from any generic disruption to the latent representations.
What would settle it
Apply random perturbations of similar magnitude to the same KV-cache handoffs and local states in clean runs; if performance degrades to the same degree as the attack-derived interventions, the claim that effects are reactivation-specific would not hold.
Figures

read the original abstract
Latent-based multi-agent systems replace parts of explicit inter-agent communication with hidden representations, offering a new direction for efficient and flexible agent collaboration. However, moving coordination into latent space may also move attacks beyond the reach of visible-text inspection. In this paper, we study whether latent states can carry attack-associated information that remains effective during clean executions. To examine this question, we introduce a latent attack framework that reactivates attack-induced effects through latent interventions without reusing adversarial text. Extensive experiments show that the resulting latent-only attacks can substantially degrade task performance in clean executions, especially when applied to inter-agent KV-cache handoffs rather than local hidden states. Further control analyses indicate that this degradation cannot be reduced to arbitrary perturbations or invalid generation. Overall, our findings suggest that latent-based collaboration does not remove attack risk. It shifts part of the risk into less observable execution states, calling for safeguards beyond visible-text inspection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a latent attack framework for latent-based multi-agent systems that replaces explicit communication with hidden representations. It claims that latent states can carry attack-associated information effective during clean executions, demonstrated via latent interventions that reactivate attack effects without reusing adversarial text. Experiments show substantial task performance degradation, particularly when targeting inter-agent KV-cache handoffs rather than local hidden states, with control analyses indicating the effect cannot be reduced to arbitrary perturbations or invalid generation.
Significance. If the experimental outcomes hold, the work identifies a shifted attack surface in latent-based multi-agent collaboration, showing that moving coordination into latent space does not eliminate but relocates security risks to less observable states. This has implications for safeguards in emerging agent systems. The inclusion of control analyses to isolate reactivation effects from generic disruption is a methodological strength.
minor comments (1)
- The abstract would benefit from including specific quantitative results, effect sizes, dataset details, or statistical evidence to convey the magnitude and reliability of the reported performance degradation.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our manuscript, the recognition of its significance, and the recommendation for minor revision. No specific major comments were provided for us to address.
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical investigation of latent-only attacks in multi-agent systems, with its central claim resting on experimental performance degradation under clean executions and control analyses that rule out generic perturbations. No equations, fitted parameters, derivations, or self-citation chains appear in the abstract or description; the argument is supported by direct experimental outcomes rather than any reduction to inputs by construction. The control analyses explicitly address the key assumption about reactivation versus arbitrary disruption, rendering the derivation chain self-contained and independent.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
When Latent Agents Lie: KV-Cache Integrity in Multi-Agent LLM Collaboration
KV-cache sharing boosts multi-agent QA performance but enables undetectable tampering; HMAC manifests binding agent, session, and payload reliably detect changes.
Reference graph
Works this paper leans on
-
[1]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Refusal in language models is mediated by a single direction. InAdvances in Neural Informa- tion Processing Systems, volume 37, pages 136037– 136083. Curran Associates, Inc. Yuanpu Cao, Tianrong Zhang, Bochuan Cao, Ziyi Yin, Lu Lin, Fenglong Ma, and Jinghui Chen. 2024. Per- sonalized steering of large language models: Versa- tile steering vectors through ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. 2024. Improving factuality and reasoning in language models through multiagent debate. InProceedings of the 41st Inter- national Conference on Machine Learning, volume 235 ofProceedings of Machine Lear...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Prompt Injection attack against LLM-integrated Applications
Training large language models to reason in a continuous latent space. InSecond Conference on Language Modeling. Pengfei He, Yuping Lin, Shen Dong, Han Xu, Yue Xing, and Hui Liu. 2025. Red-teaming LLM multi-agent systems via communication attacks. InFindings of the Association for Computational Linguistics: ACL 2025, pages 6726–6747, Vienna, Austria. Asso...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Steering Language Models With Activation Engineering
Dialz: A python toolkit for steering vectors. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 363–375, Vienna, Austria. Association for Computational Linguistics. Daniel Tan, David Chanin, Aengus Lynch, Brooks Paige, Dimitrios Kanoulas, Adrià Garriga-Alonso, and Robert Kirk...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
InAdvances in Neural Information Processing Systems, volume 37, pages 137010–137045
Fincon: A synthesized llm multi-agent system with conceptual verbal reinforcement for enhanced financial decision making. InAdvances in Neural Information Processing Systems, volume 37, pages 137010–137045. Curran Associates, Inc. Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. InjecAgent: Benchmarking indirect prompt injections in tool-int...
2024
-
[6]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Agent-safetybench: Evaluating the safety of llm agents.Preprint, arXiv:2412.14470. Wei Zhou, Mohsen Mesgar, Annemarie Friedrich, and Heike Adel. 2025. Efficient multi-agent collabora- tion with tool use for online planning in complex table question answering. InFindings of the Associ- ation for Computational Linguistics: NAACL 2025, pages 945–968, Albuque...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.