Proprio: Latent Self-Scoring and Inference-Time Refinement for Physically Plausible Video Generation
Pith reviewed 2026-06-29 12:52 UTC · model grok-4.3
The pith
Frozen video generators contain internal flow-residual signals that can score and refine physical plausibility at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
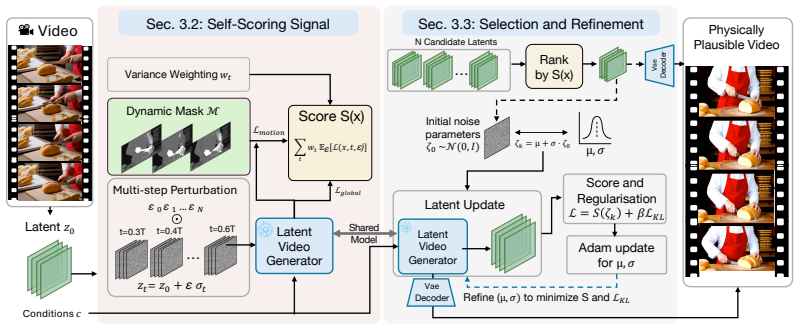
Proprio treats the model's flow residual under controlled latent perturbations as a self-scoring signal. Samples that are better explained by the generator's learned dynamics induce smaller and more stable residuals. Aggregating this signal across timesteps and perturbations, focusing it on motion-relevant regions with a dynamic spatiotemporal mask, and using it for best-of-N search, gradient-based self-refinement, or both yields consistent gains in physical plausibility on text-to-video and image-to-video benchmarks.
What carries the argument
Flow residual under controlled latent perturbations, aggregated and masked as an internal self-scoring signal for physical alignment.
If this is right
- Raises Physics-IQ from 32.2 to 37.5 and VideoPhy2-hard physical commonsense from 45.6 to 55.0 on the tested generators.
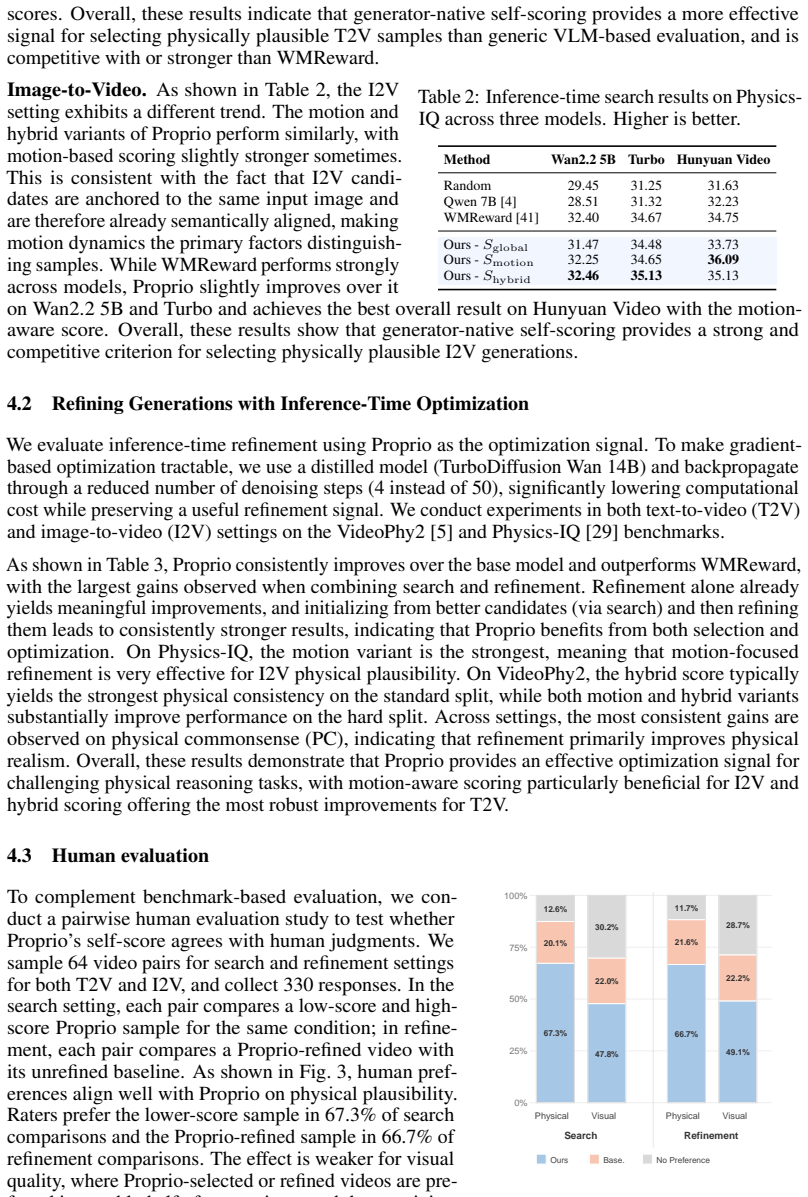
- Outperforms both VLM-based scoring and external world-model baselines in several benchmark settings.
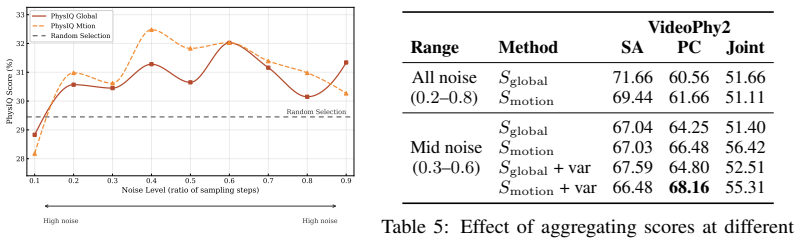
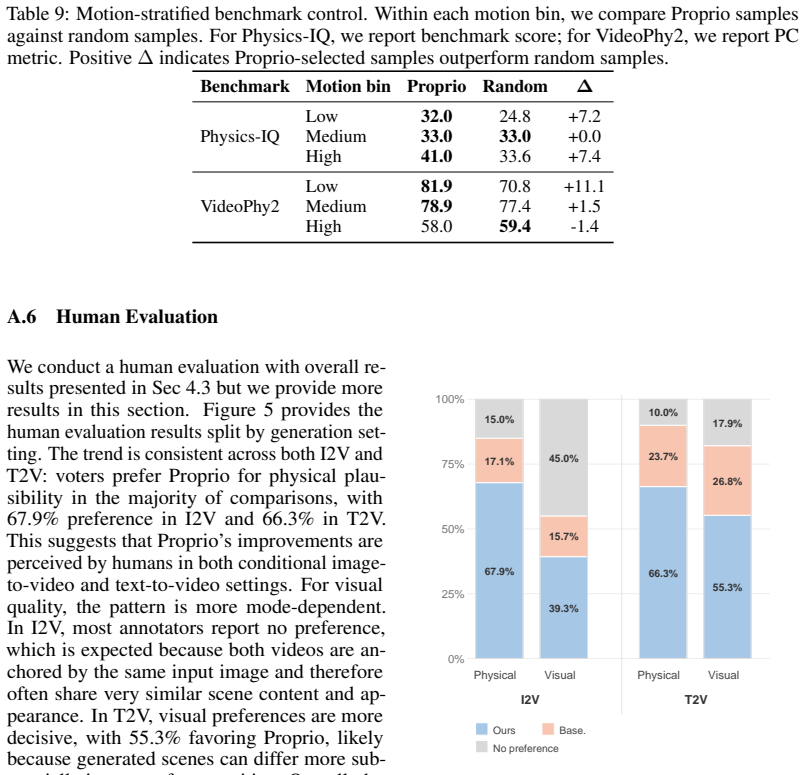
- Produces videos that human raters judge more physically plausible in about two-thirds of pairwise comparisons.
- Works on both text-to-video and image-to-video tasks without any additional training.
Where Pith is reading between the lines
- The same residual signal could be checked on generators trained on synthetic data lacking real physics to test whether the method still selects plausible outputs.
- If the signal proves architecture-independent, it might serve as a lightweight internal consistency check for other generative tasks such as 3D scene synthesis.
- Applying the perturbation schedule at different noise levels could reveal whether the physical signal is strongest at particular stages of the denoising process.
- The method leaves open whether the residual signal can be used to steer sampling during generation rather than only after full samples are produced.
Load-bearing premise
That smaller and more stable flow residuals under latent perturbations indicate better alignment with real physical dynamics rather than the generator's own training biases or artifacts.
What would settle it
A test in which videos containing clear, measurable physical violations (such as object interpenetration or gravity reversal) consistently produce smaller residuals than physically correct videos.
Figures





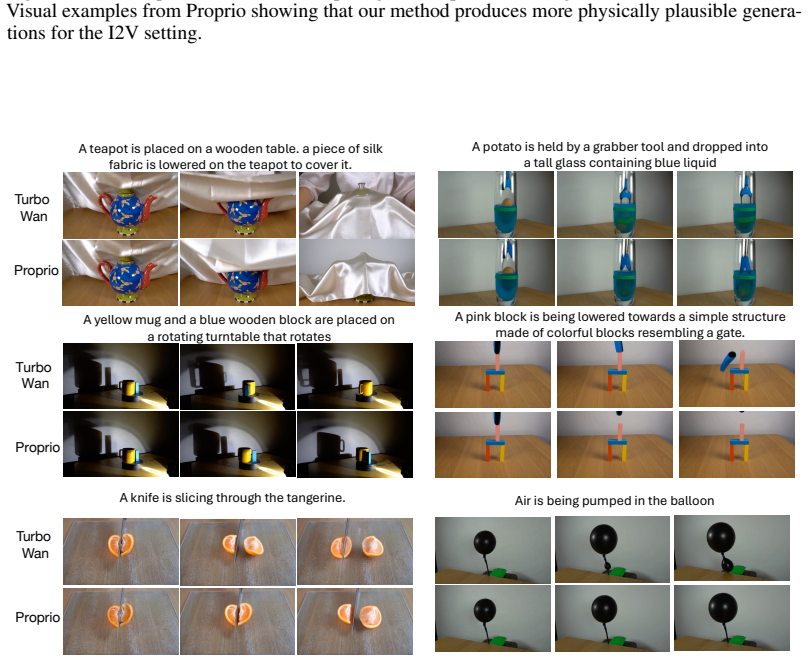


read the original abstract
Modern video generative models produce visually impressive results, yet frequently violate basic physical principles. We propose Proprio, a training-free framework that enables a frozen video generator to assess and improve the physical plausibility of its own outputs. Inspired by proprioception, the biological sense of one's own movement, Proprio treats the model's flow residual under controlled latent perturbations as a self-scoring signal. Samples that are better explained by the generator's learned dynamics induce smaller and more stable residuals. We aggregate this signal across timesteps and perturbations, focus it on motion-relevant regions with a dynamic spatiotemporal mask, and use it for best-of-N search, gradient-based self-refinement, or both. Across text-to-video and image-to-video benchmarks, Proprio consistently improves physical plausibility, outperforming VLM-based scoring, and external world-model baselines in several settings. With TurboWan2.2, Proprio improves Physics-IQ from 32.2 to 37.5 (+16.5%) and VideoPhy2-hard physical commonsense from 45.6 to 55.0 (+20.6%). Human evaluation further shows that raters prefer Proprio-selected or refined videos for physical plausibility in roughly two-thirds of comparisons. These results suggest that frozen video generators contain actionable internal signals for evaluating and improving the physical plausibility of their own outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Proprio, a training-free framework for frozen video generators that uses the model's own flow residuals under controlled latent perturbations as a self-scoring signal for physical plausibility. Samples better aligned with the generator's learned dynamics produce smaller, more stable residuals; these are aggregated across timesteps and perturbations, masked to motion regions, and applied via best-of-N selection or gradient refinement. Experiments on text-to-video and image-to-video benchmarks report gains over VLM-based scoring and external world-model baselines, including Physics-IQ rising from 32.2 to 37.5 and VideoPhy2-hard from 45.6 to 55.0, plus human preference for physical plausibility in roughly two-thirds of pairwise comparisons.
Significance. If the residual signal genuinely tracks physical dynamics rather than generator-internal consistency, the work offers a practical inference-time route to more plausible video synthesis without retraining or external supervisors. The training-free design and use of internal dynamics are strengths, as are the reported benchmark lifts and human-study results. However, the absence of direct validation that residuals correlate with real physical violations (as opposed to training-distribution artifacts) limits the strength of the central claim.
major comments (3)
- [Abstract] Abstract: The central assertion that smaller and more stable flow residuals indicate better physical plausibility rests on the premise that the signal distinguishes real-world physics violations from in-distribution artifacts, yet no controlled test (e.g., synthetic videos with explicit gravity or collision errors) is reported to establish this correlation independent of the generator's biases.
- [Abstract] Quantitative results (abstract): Improvements such as Physics-IQ +16.5% and VideoPhy2-hard +20.6% are stated without error bars, statistical significance, or ablation tables isolating the contribution of the dynamic mask, perturbation schedule, or aggregation method; this weakens the claim of consistent outperformance.
- [§3] Method description (abstract and §3): The scoring signal is derived entirely from the frozen generator's internal flow dynamics under self-induced perturbations, creating a self-referential loop; the manuscript provides no external physics oracle or cross-generator transfer experiment to confirm the residual measures physical fidelity rather than model-specific consistency.
minor comments (1)
- [Abstract] The abstract mentions 'dynamic spatiotemporal mask' without specifying its exact formulation or sensitivity analysis; a brief equation or pseudocode would clarify how motion-relevant regions are isolated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the training-free design and reported benchmark gains. We address each major comment below with honest assessment of the manuscript's current evidence and planned revisions. The responses focus on substance and aim to strengthen the central claims where possible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central assertion that smaller and more stable flow residuals indicate better physical plausibility rests on the premise that the signal distinguishes real-world physics violations from in-distribution artifacts, yet no controlled test (e.g., synthetic videos with explicit gravity or collision errors) is reported to establish this correlation independent of the generator's biases.
Authors: We agree that a controlled experiment using synthetic videos with explicit, isolated physics violations (e.g., gravity or collision errors) would provide the strongest direct evidence that residuals track physical fidelity rather than generator-specific artifacts. Our validation currently rests on Physics-IQ and VideoPhy2 benchmarks, which are constructed around physical commonsense violations, together with human preference results (approximately two-thirds favoring Proprio). We will add an explicit limitations paragraph in the revision discussing this distinction and the self-referential nature of the signal. A full synthetic-video experiment is not feasible within the current experimental budget but could be noted as future work. revision: partial
-
Referee: [Abstract] Quantitative results (abstract): Improvements such as Physics-IQ +16.5% and VideoPhy2-hard +20.6% are stated without error bars, statistical significance, or ablation tables isolating the contribution of the dynamic mask, perturbation schedule, or aggregation method; this weakens the claim of consistent outperformance.
Authors: The referee is correct that the abstract numbers are presented without accompanying error bars or significance tests. The full manuscript contains component ablations, but these are not summarized in the abstract and lack statistical reporting. In the revision we will (1) add error bars and significance statements to the abstract claims, (2) expand the ablation table to isolate the dynamic mask, perturbation schedule, and aggregation choices, and (3) ensure all quantitative statements in the abstract are directly supported by the main-text results. revision: yes
-
Referee: [§3] Method description (abstract and §3): The scoring signal is derived entirely from the frozen generator's internal flow dynamics under self-induced perturbations, creating a self-referential loop; the manuscript provides no external physics oracle or cross-generator transfer experiment to confirm the residual measures physical fidelity rather than model-specific consistency.
Authors: The self-referential design is deliberate: the method is intended to operate without any external physics oracle or additional trained models, which is the core practical advantage. Validation occurs via external benchmarks (Physics-IQ, VideoPhy2) and human raters who judge physical plausibility independently of the generator. A cross-generator transfer study would be informative but lies outside the stated scope of demonstrating utility on a single frozen model. We will revise §3 to more explicitly state this design choice and its relation to the training-free constraint. revision: no
Circularity Check
No significant circularity: internal signal validated on external benchmarks
full rationale
The derivation defines a scoring signal from the frozen model's own flow residuals under latent perturbations and uses it for selection or refinement. This is not circular because the central claim of improved physical plausibility is tested against independent external benchmarks (Physics-IQ, VideoPhy2-hard, human raters) rather than reducing to a self-definition or fitted input by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the derivation chain. The assumption that the signal tracks real physics is an empirical hypothesis, not a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow residuals under latent perturbations serve as a proxy for physical plausibility because samples better explained by the generator's learned dynamics produce smaller residuals.
Reference graph
Works this paper leans on
-
[1]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Improving geo-diversity of generated images with contextualized vendi score guidance
Reyhane Askari Hemmat, Melissa Hall, Alicia Sun, Candace Ross, Michal Drozdzal, and Adriana Romero- Soriano. Improving geo-diversity of generated images with contextualized vendi score guidance. In Proceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025
-
[6]
Lumiere: A space-time diffusion model for video generation.arXiv preprint arXiv:2401.12945, 2024
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, Yuanzhen Li, Michael Rubinstein, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, and Inbar Mosseri. Lumiere: A space-time diffusion model for video generation.arXiv preprint arXiv:2401.12945, 2024
-
[7]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Video generation models as world simulators
Tim Brooks, William Peebles, Aditya Ramesh, et al. Video generation models as world simulators. OpenAI technical report, 2024. Online; accessed from OpenAI
2024
-
[9]
Yuanhao Cai, Kunpeng Li, Menglin Jia, Jialiang Wang, Junzhe Sun, Feng Liang, Weifeng Chen, Felix Juefei-Xu, Chu Wang, Ali Thabet, et al. Phygdpo: Physics-aware groupwise direct preference optimization for physically consistent text-to-video generation.arXiv preprint arXiv:2512.24551, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Increasing the utility of synthetic images through chamfer guidance
Nicola Dall’Asen, Xiaofeng Zhang, Reyhane Askari Hemmat, Melissa Hall, Jakob Verbeek, Adriana Romero-Soriano, and Michal Drozdzal. Increasing the utility of synthetic images through chamfer guidance. arXiv preprint arXiv:2508.10631, 2025
-
[11]
Initno: Boosting text-to- image diffusion models via initial noise optimization
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to- image diffusion models via initial noise optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[12]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Mariam Hassan, Bastien Van Delft, Wuyang Li, and Alexandre Alahi. Factorized video generation: Decoupling scene construction and temporal synthesis in text-to-video diffusion models.arXiv preprint arXiv:2512.16371, 2025
-
[14]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[15]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogniti...
2024
-
[16]
Diffusion tree sampling: Scalable inference-time alignment of diffusion models
Vineet Jain, Kusha Sareen, Mohammad Pedramfar, and Siamak Ravanbakhsh. Diffusion tree sampling: Scalable inference-time alignment of diffusion models. InSecond Workshop on Test-Time Adaptation: Putting Updates to the Test! at ICML 2025
2025
-
[17]
Sangwon Jang, Taekyung Ki, Jaehyeong Jo, Saining Xie, Jaehong Yoon, and Sung Ju Hwang. Self-refining video sampling.arXiv preprint arXiv:2601.18577, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
How far is video generation from world model: A physical law perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective. InInternational Conference on Machine Learning, pages 28991–29017. PMLR, 2025
2025
-
[19]
Videopoet: A large language model for zero-shot video generation
Dan Kondratyuk, Lijun Yu, Xin Zhao, Mingxing Meng, Chenlin Yan, Alexandre Drouin, Maor Yi, Lijian Luo, Liangyu Gui, Zhenyao Wang, Wilson Sean, Cordelia Schmid, David Ross, Kihyuk Sohn, and Lu Jiang. Videopoet: A large language model for zero-shot video generation. InProceedings of the 41st International Conference on Machine Learning, pages 25105–25124, 2024
2024
-
[20]
Your diffusion model is secretly a zero-shot classifier
Alexander C Li, Mihir Prabhudesai, Shivam Duggal, Ellis Brown, and Deepak Pathak. Your diffusion model is secretly a zero-shot classifier. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2206–2217, 2023
2023
-
[21]
Xiner Li, Yulai Zhao, Chenyu Wang, Gabriele Scalia, Gokcen Eraslan, Surag Nair, Tommaso Biancalani, Shuiwang Ji, Aviv Regev, Sergey Levine, and Masatoshi Uehara. Derivative-free guidance in continuous and discrete diffusion models with soft value-based decoding.arXiv preprint arXiv:2408.08252, 2024
-
[22]
Xiner Li, Masatoshi Uehara, Xingyu Su, Gabriele Scalia, Tommaso Biancalani, Aviv Regev, Sergey Levine, and Shuiwang Ji. Dynamic search for inference-time alignment in diffusion models.arXiv preprint arXiv:2503.02039, 2025
-
[23]
Beyond VLM-Based Rewards: Diffusion-Native Latent Reward Modeling
Gongye Liu, Bo Yang, Yida Zhi, Zhizhou Zhong, Lei Ke, Didan Deng, Han Gao, Yongxiang Huang, Kaihao Zhang, Hongbo Fu, et al. Beyond vlm-based rewards: Diffusion-native latent reward modeling. arXiv preprint arXiv:2602.11146, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Physgen: Rigid-body physics- grounded image-to-video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. Physgen: Rigid-body physics- grounded image-to-video generation. InEuropean Conference on Computer Vision, pages 360–378. Springer, 2024
2024
-
[25]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[26]
Gpt4motion: Scripting physical motions in text-to-video generation via blender-oriented gpt planning
Jiaxi Lv, Yi Huang, Mingfu Yan, Jiancheng Huang, Jianzhuang Liu, Yifan Liu, Yafei Wen, Xiaoxin Chen, and Shifeng Chen. Gpt4motion: Scripting physical motions in text-to-video generation via blender-oriented gpt planning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2024
2024
-
[27]
Scaling inference time compute for diffusion models
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, and Saining Xie. Scaling inference time compute for diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2523–2534, 2025
2025
-
[28]
Video generation models are good latent reward models.arXiv preprint arXiv:2511.21541, 2025
Xiaoyue Mi, Wenqing Yu, Jiesong Lian, Shibo Jie, Ruizhe Zhong, Zijun Liu, Guozhen Zhang, Zixiang Zhou, Zhiyong Xu, Yuan Zhou, et al. Video generation models are good latent reward models.arXiv preprint arXiv:2511.21541, 2025
-
[29]
Do generative video mod- els understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video mod- els understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
2026
-
[30]
Extracting reward functions from diffusion models
Felipe Nuti, Tim Franzmeyer, and João F Henriques. Extracting reward functions from diffusion models. Advances in Neural Information Processing Systems, 36:50196–50220, 2023
2023
-
[31]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Yossi Adi, Leshem Choshen, Tavi Halperin, Tovi Ventura, Xi Zhang, Boliang Wang, Peng Yin, Dong Xu, Shir Gur, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Video motion transfer with diffusion transformers
Alexander Pondaven, Aliaksandr Siarohin, Sergey Tulyakov, Philip Torr, and Fabio Pizzati. Video motion transfer with diffusion transformers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22911–22921, 2025. 11
2025
-
[33]
Inference- time alignment of diffusion models with direct noise optimization
Zhiwei Tang, Jiangweizhi Peng, Jiasheng Tang, Mingyi Hong, Fan Wang, and Tsung-Hui Chang. Inference- time alignment of diffusion models with direct noise optimization. InForty-second International Confer- ence on Machine Learning
-
[34]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Wisa: World simulator assistant for physics-aware text-to-video generation
Jing Wang, Ao Ma, Ke Cao, Jun Zheng, Jiasong Feng, Zhanjie Zhang, Wanyuan Pang, and Xiaodan Liang. Wisa: World simulator assistant for physics-aware text-to-video generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[36]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Vlipp: Towards physically plausible video generation with vision and language informed physical prior
Xindi Yang, Baolu Li, Yiming Zhang, Zhenfei Yin, Lei Bai, Liqian Ma, Zhiyong Wang, Jianfei Cai, Tien-Tsin Wong, Huchuan Lu, et al. Vlipp: Towards physically plausible video generation with vision and language informed physical prior. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12360–12370, 2025
2025
-
[38]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Tfg: Unified training-free guidance for diffusion models
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Zou, and Stefano Ermon. Tfg: Unified training-free guidance for diffusion models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[40]
Jianhao Yuan, Fabio Pizzati, Francesco Pinto, Lars Kunze, Ivan Laptev, Paul Newman, Philip Torr, and Daniele De Martini. Likephys: Evaluating intuitive physics understanding in video diffusion models via likelihood preference.arXiv preprint arXiv:2510.11512, 2025
-
[41]
Jianhao Yuan, Xiaofeng Zhang, Felix Friedrich, Nicolas Beltran-Velez, Melissa Hall, Reyhane Askari- Hemmat, Xiaochuang Han, Nicolas Ballas, Michal Drozdzal, and Adriana Romero-Soriano. Inference-time physics alignment of video generative models with latent world models.arXiv preprint arXiv:2601.10553, 2026
-
[42]
Jintao Zhang, Kaiwen Zheng, Kai Jiang, Haoxu Wang, Ion Stoica, Joseph E Gonzalez, Jianfei Chen, and Jun Zhu. Turbodiffusion: Accelerating video diffusion models by 100-200 times.arXiv preprint arXiv:2512.16093, 2025
-
[43]
Videorepa: Learning physics for video generation through relational alignment with foundation models
Xiangdong Zhang, Jiaqi Liao, Shaofeng Zhang, Fanqing Meng, Xiangpeng Wan, Junchi Yan, and Yu Cheng. Videorepa: Learning physics for video generation through relational alignment with foundation models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[44]
Inference-time scaling of diffusion models through classical search
XiangCheng Zhang, Haowei Lin, Haotian Ye, James Zou, Jianzhu Ma, Yitao Liang, and Yilun Du. Inference-time scaling of diffusion models through classical search. InNeurIPS 2025 Workshop on Structured Probabilistic Inference{\&}Generative Modeling, . 12 A Additional experiments and ablations A.1 Diagnostic Study: Preference for natural video dynamics To tes...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.