Learning to Label: A Reinforced Self-Evolving Framework for Semi-supervised Referring Expression Segmentation
Pith reviewed 2026-06-29 12:44 UTC · model grok-4.3
The pith
Casting pseudo-label selection as reinforcement learning creates a self-evolving loop that jointly improves the model and its supervision signals for referring expression segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
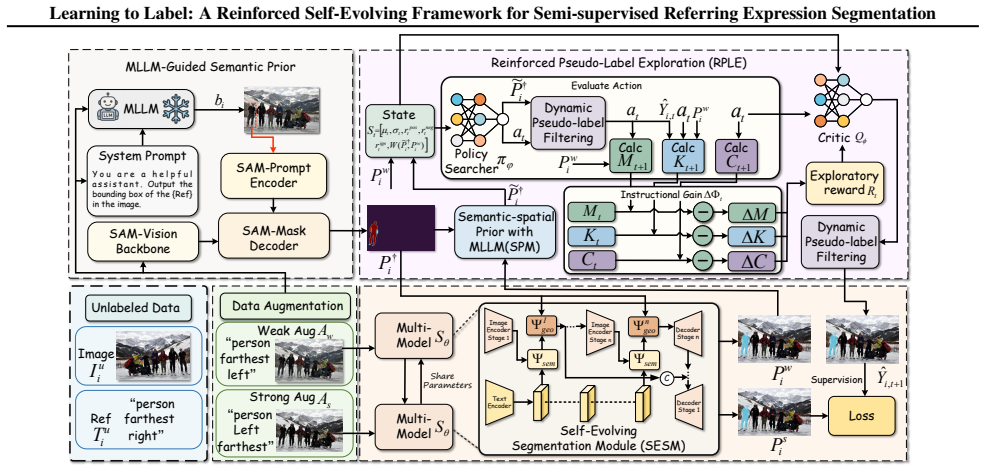
The central claim is that reinforced pseudo-label selection, formulated as an exploratory decision process that adaptively rewards high-utility pixel-level supervision based on multimodal priors and model predictions, enables a self-evolving loop for joint optimization of the segmentation model and pseudo-labels, progressively enhancing label reliability under sparse supervision.
What carries the argument
Reinforced pseudo-label selection as an exploratory decision process that adaptively rewards high-utility pixel-level supervision based on multimodal priors and model predictions.
If this is right
- Joint optimization of model and labels produces progressively more reliable supervision signals.
- The framework yields measurable accuracy gains over existing semi-supervised methods on RefCOCO, RefCOCO+, and RefCOCOg.
- Multimodal priors from an MLLM can be elevated into learnable guidance that conditions the segmentation network.
- The approach maintains generalization when supervision is limited to sparse image-text pairs.
Where Pith is reading between the lines
- The same reinforced selection loop could be tested on other pixel-level grounding tasks such as referring video segmentation.
- Replacing the MLLM prior extractor with a lighter vision-language model might reduce compute while preserving most gains.
- Monitoring the variance of reward signals across iterations could serve as an early indicator of training stability.
Load-bearing premise
The reinforcement mechanism for choosing pseudo-labels will produce stable improvements rather than unstable or collapsing learning dynamics.
What would settle it
Train the framework for multiple iterations on RefCOCO and measure whether the average IoU of selected pseudo-labels against a held-out ground-truth subset rises steadily or eventually declines.
Figures







read the original abstract
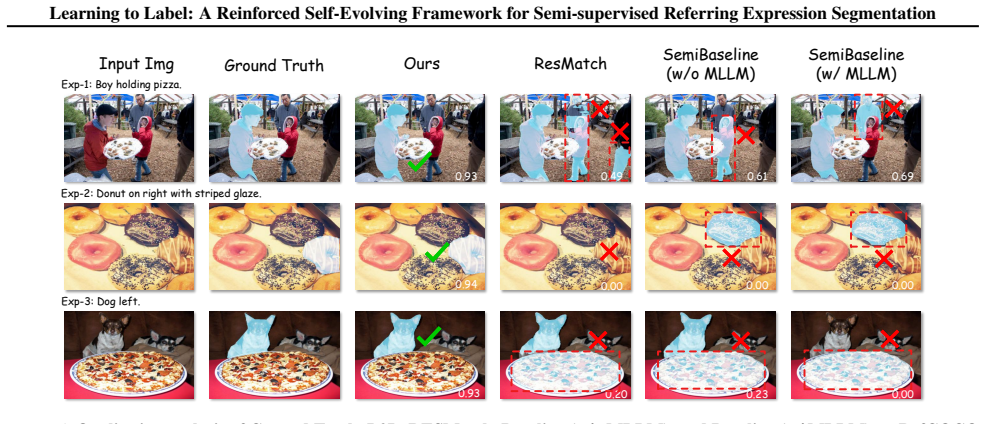
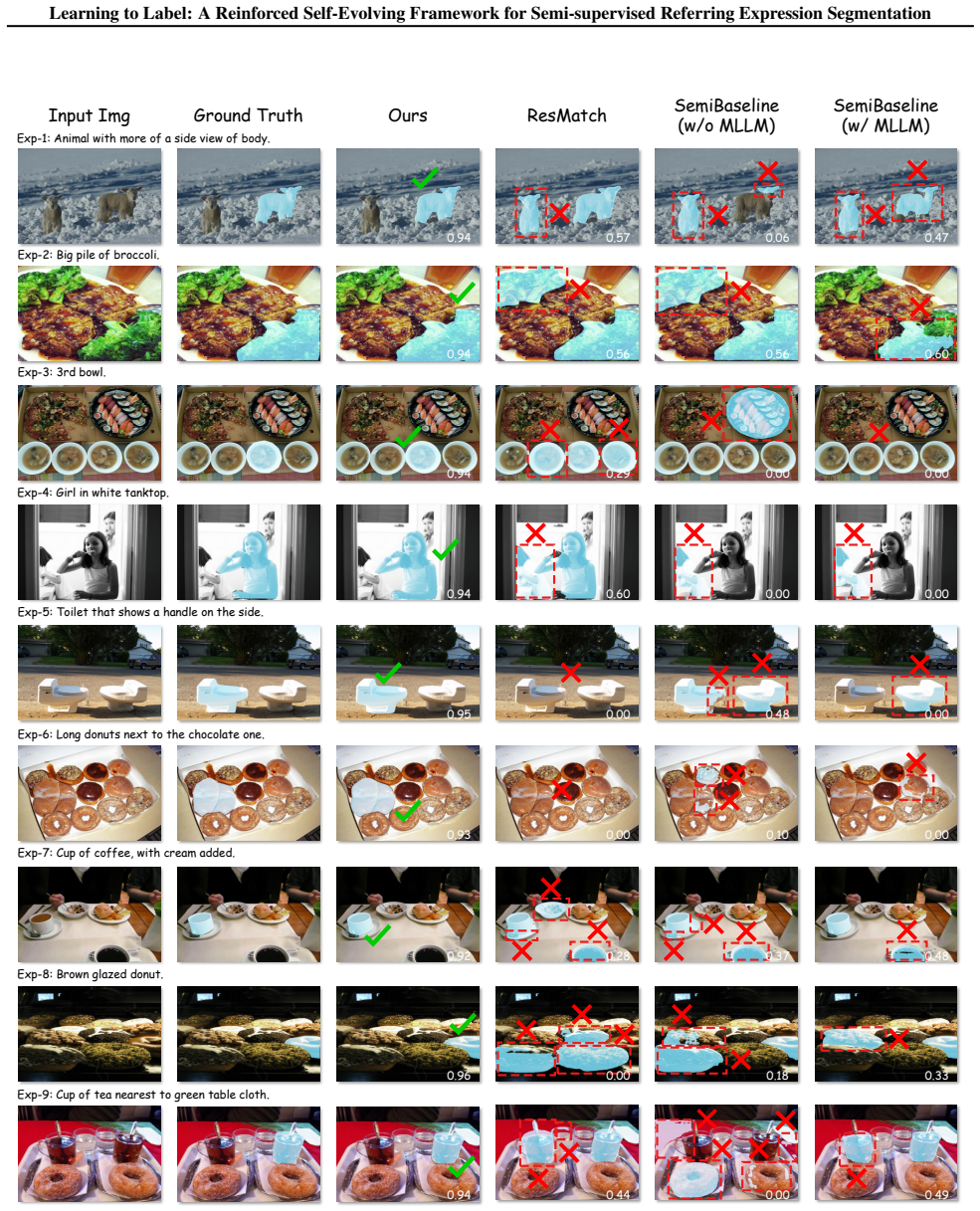
Semi-supervised referring expression segmentation (SS-RES) aims to achieve precise pixel-level language grounding under limited annotation, yet suffers from limited supervision and unreliable pseudo-labels when exploiting unlabeled image-text pairs. In this work, we propose Learning to Label, a reinforced self-evolving framework (L2L) that casts pseudo-label construction as a learnable decision-making process. To build foundational understanding, we leverage a multimodal large language model to extract semantic-spatial priors, which are instantiated as initial soft segmentation proposals and elevated, together with textual cues, into learnable guidance signals that condition a hierarchical segmentation network. To ensure stable learning, reinforced pseudo-label selection is formulated as an exploratory decision process that adaptively rewards high-utility pixel-level supervision based on multimodal priors and model predictions. This reinforced self-evolving loop enables joint optimization of the segmentation model and pseudo-labels, progressively enhancing label reliability under sparse supervision. Extensive experiments on RefCOCO, RefCOCO+, and RefCOCOg demonstrate improvements over existing methods, validating its effectiveness and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Learning to Label (L2L), a reinforced self-evolving framework for semi-supervised referring expression segmentation (SS-RES). It uses a multimodal large language model to extract semantic-spatial priors instantiated as initial soft segmentation proposals, which together with textual cues condition a hierarchical segmentation network. Pseudo-label construction is cast as a learnable decision-making process via reinforced pseudo-label selection formulated as an exploratory decision process that adaptively rewards high-utility pixel-level supervision based on multimodal priors and model predictions. This creates a self-evolving loop for joint optimization of the segmentation model and pseudo-labels to improve label reliability under sparse supervision. Experiments on RefCOCO, RefCOCO+, and RefCOCOg report improvements over existing methods.
Significance. If the reinforced selection mechanism can be shown to produce stable joint optimization without amplifying early errors, the framework would offer a novel way to address unreliable pseudo-labels in SS-RES by integrating MLLM priors with RL-based selection. This could advance semi-supervised pixel-level language grounding methods. The current presentation, however, provides no equations, state/action definitions, or stability analysis, preventing assessment of whether the central claim holds.
major comments (2)
- [Reinforced pseudo-label selection description] The reinforced pseudo-label selection is described as an 'exploratory decision process' that 'adaptively rewards high-utility pixel-level supervision,' but no equations, state space, action space, reward function, or policy update rules are provided. This formulation is load-bearing for the self-evolving loop claim, yet the combinatorial size of any per-pixel or region action space in RES is unaddressed, leaving open whether stability against confirmation bias or reward sparsity is achieved.
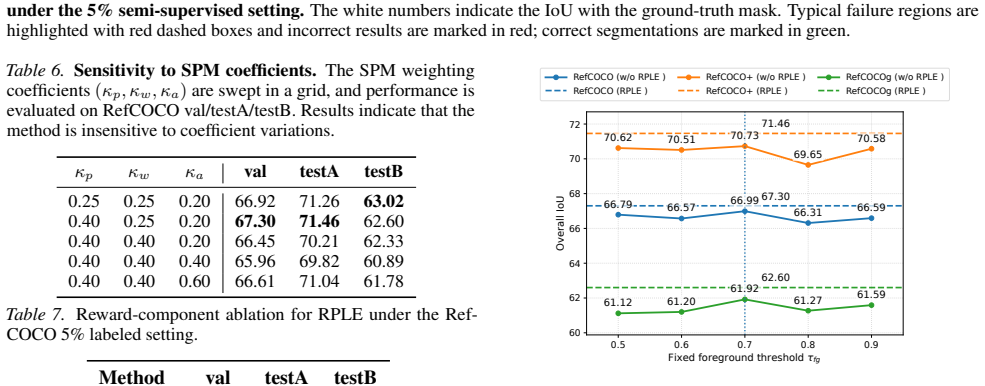
- [Experiments and results] The abstract and experimental claims state that the loop 'progressively enhancing label reliability' and yields improvements on RefCOCO datasets, but no ablation studies isolate the contribution of the RL selection, no error analysis on pseudo-label quality over iterations, and no verification that gains exceed those from MLLM priors alone. This undermines evaluation of the joint optimization claim.
minor comments (2)
- [Framework overview] The term 'hierarchical segmentation network' is introduced without architectural details or reference to its base model, making it difficult to reproduce the conditioning mechanism.
- [Framework overview] Notation for 'soft segmentation proposals' and 'learnable guidance signals' is introduced without formal definitions or equations, reducing clarity of how MLLM outputs are integrated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to provide the requested details and experiments.
read point-by-point responses
-
Referee: [Reinforced pseudo-label selection description] The reinforced pseudo-label selection is described as an 'exploratory decision process' that 'adaptively rewards high-utility pixel-level supervision,' but no equations, state space, action space, reward function, or policy update rules are provided. This formulation is load-bearing for the self-evolving loop claim, yet the combinatorial size of any per-pixel or region action space in RES is unaddressed, leaving open whether stability against confirmation bias or reward sparsity is achieved.
Authors: We agree that the current manuscript lacks sufficient mathematical detail on the reinforced pseudo-label selection. In the revised version we will add a dedicated subsection with explicit definitions of the state space (multimodal prior features concatenated with model predictions), region-level action space (to control combinatorial size), reward function (utility combining prior consistency and prediction confidence), and policy gradient update rules, along with analysis of how the exploratory process addresses confirmation bias and sparsity. revision: yes
-
Referee: [Experiments and results] The abstract and experimental claims state that the loop 'progressively enhancing label reliability' and yields improvements on RefCOCO datasets, but no ablation studies isolate the contribution of the RL selection, no error analysis on pseudo-label quality over iterations, and no verification that gains exceed those from MLLM priors alone. This undermines evaluation of the joint optimization claim.
Authors: We agree additional experiments are required. The revision will include ablations that disable the RL selection (replacing it with fixed thresholding), plots of pseudo-label IoU against ground-truth over iterations on a held-out subset, and a direct baseline using only the initial MLLM priors without the self-evolving loop, to isolate the contribution of the reinforced selection to the reported gains. revision: yes
Circularity Check
No significant circularity in the L2L framework derivation
full rationale
The paper's central claim is a reinforced self-evolving loop for joint optimization of segmentation model and pseudo-labels in SS-RES. This relies on external MLLM priors for initial proposals, standard RL formulation for pseudo-label selection as an exploratory decision process, and evaluation on standard benchmarks (RefCOCO etc.). No equations or steps reduce the target outcome to fitted parameters defined by the outcome itself, nor invoke self-citation chains for uniqueness or ansatzes. The derivation is self-contained with independent content from multimodal models and RL, warranting a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal large language models can extract usable semantic-spatial priors from image-text pairs for initial soft segmentation proposals.
invented entities (1)
-
Reinforced pseudo-label selection as exploratory decision process
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y ., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y ., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., and Lin, J. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y .-T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K. V ., Khedr, H., Huang, A., et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J. Bert: Pre-training of deep bidirectional trans- formers for language understanding.arXiv preprint arXiv:1810.04805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Li, J., Xie, Q., Gu, R., Xu, J., Liu, Y ., and Yu, X. Lgd: Leveraging generative descriptions for zero-shot referring image segmentation.arXiv preprint arXiv:2504.14467,
-
[5]
Ni, M., Zhang, Y ., Feng, K., Li, X., Guo, Y ., and Zuo, W. Ref-diff: Zero-shot referring image segmentation with generative models.arXiv preprint arXiv:2308.16777,
-
[6]
Text augmented spatial-aware zero-shot referring image segmentation.arXiv preprint arXiv:2310.18049,
Suo, Y ., Zhu, L., and Yang, Y . Text augmented spatial-aware zero-shot referring image segmentation.arXiv preprint arXiv:2310.18049,
-
[7]
Llafs++: Few-shot image segmentation with large language mod- els.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025a
Zhu, L., Chen, T., Ji, D., Xu, P., Ye, J., and Liu, J. Llafs++: Few-shot image segmentation with large language mod- els.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025a. Zhu, L., Chen, T., Xu, Q., Liu, X., Ji, D., Wu, H., Soh, D. W., and Liu, J. Popen: Preference-based optimization and ensemble for lvlm-based reasoning segmentation. ...
2020
-
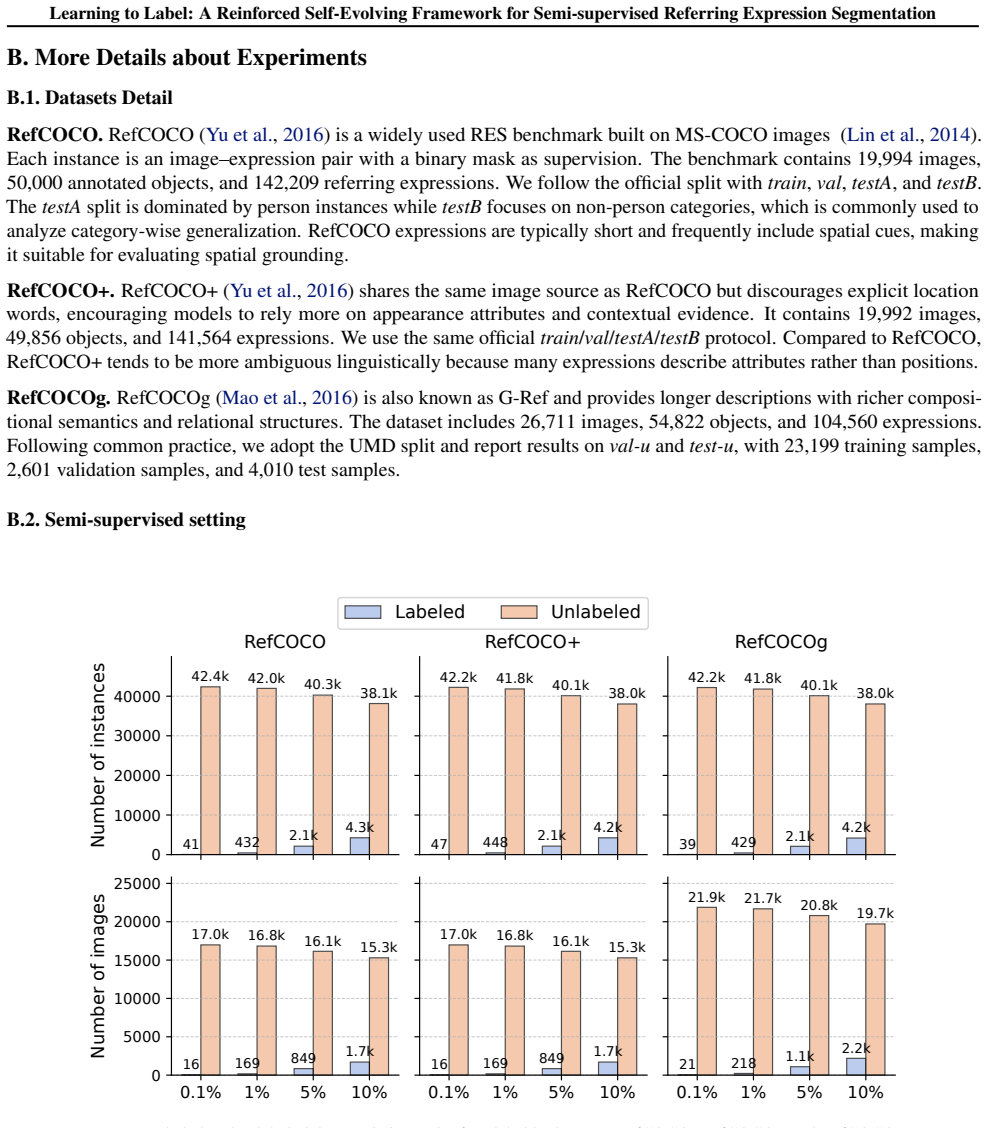
[8]
Each instance is an image–expression pair with a binary mask as supervision
is a widely used RES benchmark built on MS-COCO images (Lin et al., 2014). Each instance is an image–expression pair with a binary mask as supervision. The benchmark contains 19,994 images, 50,000 annotated objects, and 142,209 referring expressions. We follow the official split withtrain,val,testA, andtestB. ThetestAsplit is dominated by person instances...
2014
-
[9]
The dataset includes 26,711 images, 54,822 objects, and 104,560 expressions
is also known as G-Ref and provides longer descriptions with richer composi- tional semantics and relational structures. The dataset includes 26,711 images, 54,822 objects, and 104,560 expressions. Following common practice, we adopt the UMD split and report results onval-uandtest-u, with 23,199 training samples, 2,601 validation samples, and 4,010 test s...
2023
-
[10]
Reinforced Pseudo-Label Exploration (RPLE).RPLE is initialized with τf g = 0.70 and τbg = 0.20. When constructing the foreground/background/ignored regions, we suppress ambiguous boundary supervision by marking a 3-pixel-wide band around region boundaries as ignored. Both the actor and critic are implemented as two-layer MLPs with hidden size 64 and train...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.