AI, Take the Wheel: What Drives Delegation and Trust in Human-Computer Cooperative Question Answering?
Pith reviewed 2026-06-29 12:11 UTC · model grok-4.3
The pith
Humans in a question-answering game with AI outperform either alone but still miss correct AI suggestions and accept wrong ones due to bias and uncalibrated confidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
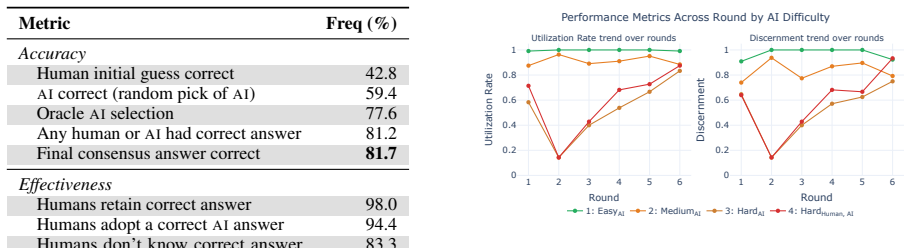
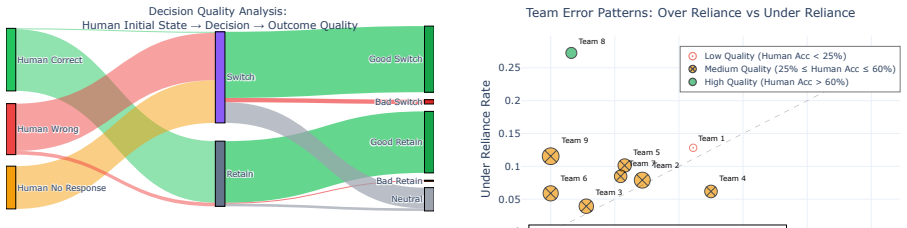
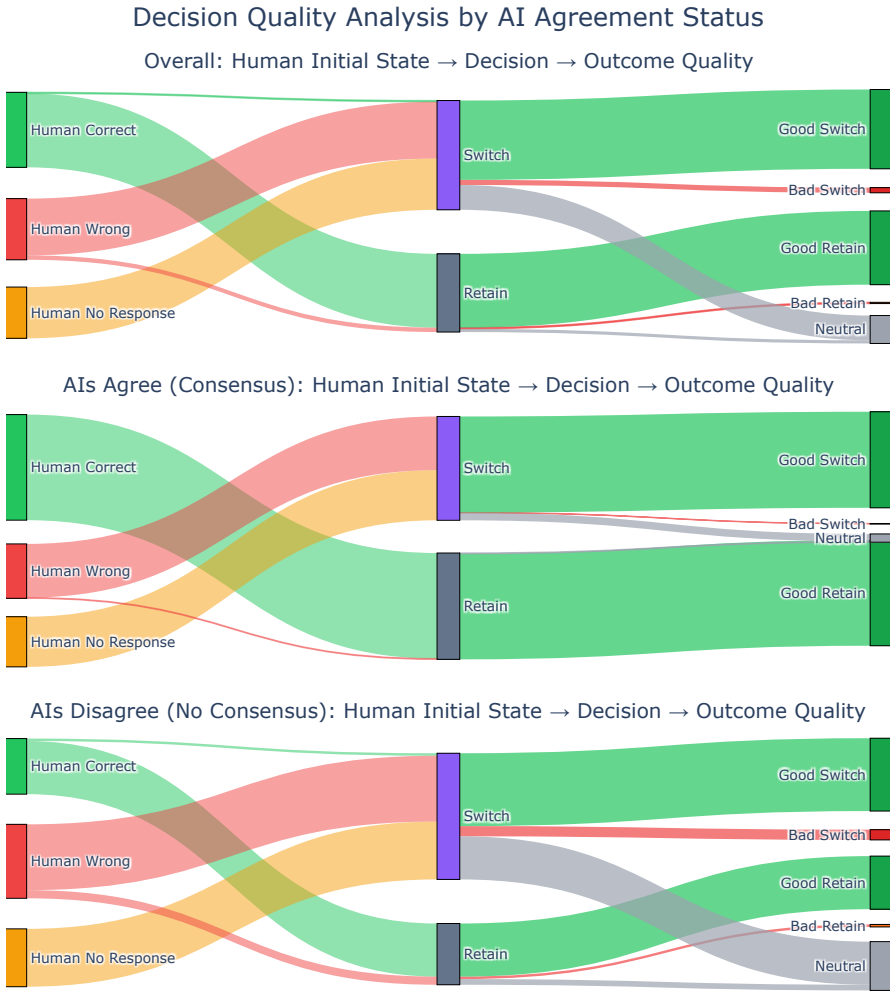
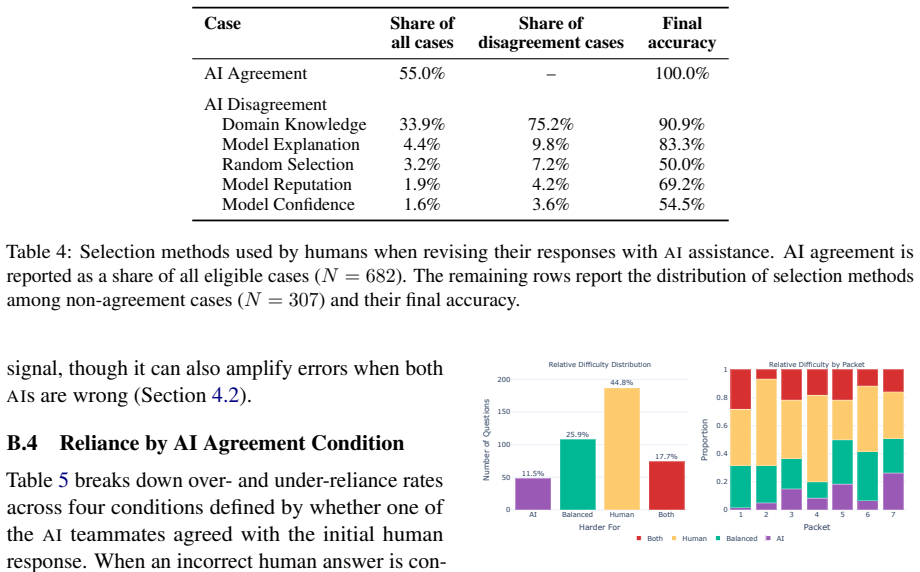
In 24 matches that produced 387 delegation decisions and 1440 adoption decisions, human-AI teams performed better than either humans or AI working alone, yet humans under-relied on correct AI suggestions in 3.9 percent of opportunities and over-relied on misleading AI suggestions in 1.7 percent of cases. When humans and AI disagreed, reported model confidence performed near chance. Confirmation bias produced markedly higher under-reliance (64.5 percent) precisely when an AI suggestion agreed with a human's initial incorrect answer. Both parties therefore contributed errors, and the study recommends calibrated confidence, evidence-grounded explanations, and mechanisms that help users refine t
What carries the argument
The separation of delegation choice (deciding to let AI act autonomously without seeing its output) from adoption choice (evaluating a visible AI suggestion), measured together for the same users inside a competitive question-answering game.
If this is right
- Human-AI teams reach higher accuracy than solo humans or solo AI in the same question-answering task.
- Suboptimal reliance appears in both directions: missed correct AI suggestions and accepted incorrect ones.
- Confirmation bias raises under-reliance sharply when AI output matches an initial human error.
- AI confidence scores are near chance level precisely when humans and AI disagree.
- Calibrated confidence, evidence-based explanations, and trust-refinement tools are proposed as direct remedies.
Where Pith is reading between the lines
- If the observed rates persist outside games, user training focused on detecting confirmation bias could measurably improve reliance accuracy.
- Interfaces that surface disagreement more visibly than agreement might reduce the 64.5 percent under-reliance spike.
- The same delegation-versus-adoption split could be measured in domains such as medical diagnosis or legal review to check whether the same bias patterns appear.
- Allowing users to adjust an AI's displayed confidence threshold over repeated interactions offers a testable way to close the performance gap.
Load-bearing premise
The competitive game format with expert humans and the chosen AI agents produces reliance decisions that generalize to other human-AI collaboration settings.
What would settle it
Repeating the same measures of under-reliance and over-reliance in a non-competitive, open-ended question-answering task with non-expert users would directly test whether the reported rates and bias patterns hold outside the game setting.
Figures




read the original abstract
AI systems are fallible, and humans can make mistakes in deciding whether to trust AI over their own judgment. Thus, improving human-AI collaboration requires understanding when, why, and how humans decide to rely on AI. We study two distinct reliance decisions: the delegation choice -- deciding when to let AI act autonomously without knowing its output, and the adoption choice -- evaluating AI suggestions and deciding how to use them. Both of these decoupled reliance patterns shape collaboration, but prior work rarely studies them together in realistic settings with the same users. We address this gap by studying collaborative human--AI teams competing in a question-answering game in which humans can choose when and how to work with AI agents to win. Our 24 matches pair 23 expert humans with 16 AI agents, capturing 387 delegation and 1440 adoption decisions. While human--AI collaboration performs better than either AI or humans alone, humans make suboptimal collaboration decisions, both under-relying on correct AI suggestions (3.9% of opportunities missed) and over-relying when AI misleads them (1.7%). Both parties contribute wrong answers: reported model confidence is near chance when humans and AI disagree, while confirmation bias drives higher under-reliance (64.5%) when an AI suggestion agrees with humans' initial incorrect answer. To close this gap, we recommend calibrated confidence, evidence-grounded explanations, and mechanisms that help users refine trust.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an observational study of human-AI collaboration in a competitive question-answering game. Across 24 matches pairing 23 expert humans with 16 AI agents, 387 delegation decisions and 1440 adoption decisions were recorded. The central claims are that human-AI teams outperform either humans or AI alone, yet humans exhibit suboptimal reliance patterns: under-reliance on correct AI suggestions in 3.9% of opportunities and over-reliance on incorrect AI suggestions in 1.7% of cases. Additional findings include model confidence near chance level on disagreements and confirmation bias producing 64.5% under-reliance when AI output matches an initial human error. The authors recommend calibrated confidence, evidence-grounded explanations, and trust-refinement mechanisms.
Significance. If the reported reliance rates and bias patterns hold, the work supplies concrete empirical data on when and why humans delegate or adopt AI output in a high-stakes collaborative setting. The design that measures both delegation and adoption decisions from the same participants is a clear strength, as is the scale of observed decisions. The findings could inform interface design for better-calibrated human-AI teams. However, the competitive expert QA context limits immediate generalizability, and the absence of statistical tests on the key percentages weakens the evidential basis for labeling the behavior 'suboptimal.'
major comments (2)
- [Abstract] Abstract: the central claim that humans 'make suboptimal collaboration decisions' is supported only by the raw percentages 3.9% and 1.7%; no statistical tests, confidence intervals, or comparison to a normative baseline (e.g., expected error under random or optimal policy) are reported, leaving open whether these rates differ reliably from chance or from optimal play within the game.
- [Abstract] Abstract and Discussion: the inference that the observed under- and over-reliance rates demonstrate generally suboptimal human decision-making is load-bearing for the paper's contribution, yet the design is confined to a competitive scoring game with expert participants and 16 specific AI agents; no within-paper comparison or robustness check tests whether the same direction or magnitude of bias appears in non-competitive tasks, with non-experts, or on different question distributions.
minor comments (2)
- [Abstract] The abstract states that 'reported model confidence is near chance when humans and AI disagree' but does not indicate how confidence was elicited from the AI agents or whether it was normalized across the 16 models.
- [Methods] Methods section (inferred from sample sizes): exclusion criteria, inter-rater reliability for decision coding, and any controls for order or fatigue effects across the 24 matches are not mentioned in the provided abstract, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evidential basis for our claims and the scope of generalizability. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that humans 'make suboptimal collaboration decisions' is supported only by the raw percentages 3.9% and 1.7%; no statistical tests, confidence intervals, or comparison to a normative baseline (e.g., expected error under random or optimal policy) are reported, leaving open whether these rates differ reliably from chance or from optimal play within the game.
Authors: We agree that statistical support would strengthen the central claim. In the revised manuscript we will add binomial confidence intervals around the reported 3.9% under-reliance and 1.7% over-reliance rates. We will also include explicit comparisons of these rates against (a) a random policy baseline derived from the observed human and AI accuracies and (b) an optimal policy that always follows the higher-accuracy agent on each question. These additions will clarify whether the observed deviations are statistically distinguishable from chance or optimal behavior within the game. revision: yes
-
Referee: [Abstract] Abstract and Discussion: the inference that the observed under- and over-reliance rates demonstrate generally suboptimal human decision-making is load-bearing for the paper's contribution, yet the design is confined to a competitive scoring game with expert participants and 16 specific AI agents; no within-paper comparison or robustness check tests whether the same direction or magnitude of bias appears in non-competitive tasks, with non-experts, or on different question distributions.
Authors: We acknowledge that the study is limited to a competitive expert QA setting with the 16 AI agents used. The manuscript does not assert that the observed bias magnitudes are universal. In revision we will qualify the abstract and discussion to state explicitly that the findings are tied to this high-stakes collaborative game and to recommend future work examining non-competitive tasks, non-expert participants, and varied question distributions. Because the current work is an observational study of existing matches, we cannot add new within-paper robustness experiments without collecting additional data. revision: partial
Circularity Check
No circularity: purely observational behavioral study with direct counts
full rationale
The paper is an empirical study reporting delegation and adoption decisions from 24 matches (387 delegation, 1440 adoption decisions). All key figures (3.9% under-reliance, 1.7% over-reliance, 64.5% confirmation bias) are direct tallies or percentages from recorded human choices against AI outputs. No equations, derivations, fitted parameters, or self-citation chains appear in the load-bearing claims. The central results are falsifiable observations from the specific game setup; generalizability is presented as an open question rather than derived. This matches the default non-circular case for observational work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InEmpirical Methods in Natural Language Processing
Dataset and baselines for sequential open- domain question answering. InEmpirical Methods in Natural Language Processing. Stephen M. Fleming and Hakwan C. Lau. 2014. How to measure metacognition.Frontiers in Human Neu- roscience, 8. Matt Gardner, Yoav Artzi, Victoria Basmov, Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Yanai Elazar,...
2014
-
[2]
how do i fool you?
Automation bias: a systematic review of fre- quency, effect mediators, and mitigators.Journal of the American Medical Informatics Association, 19(1):121–127. Catalina Gomez, Sue Min Cho, Shichang Ke, Chien- Ming Huang, and Mathias Unberath. 2025. Human- AI collaboration is not very collaborative yet: A tax- onomy of interaction patterns in AI-assisted dec...
2025
-
[3]
The impact of large language models in fi- nance: Towards trustworthy adoption.The Alan Tur- ing Institute. Laura R. Marusich, Jonathan Z. Bakdash, Yan Zhou, and Murat Kantarcioglu. 2024. Using ai uncertainty quantification to improve human decision-making. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org. Raja Par...
-
[4]
The clue mentions X
Effect of confidence and explanation on accu- racy and trust calibration in ai-assisted decision mak- ing. InProceedings of the 2020 conference on fair- ness, accountability, and transparency, pages 295– 305. A Additional Related Work This section outlines additional related work not featured in the main text of the paper. A.1 Human-AI Collaboration and A...
2020
-
[5]
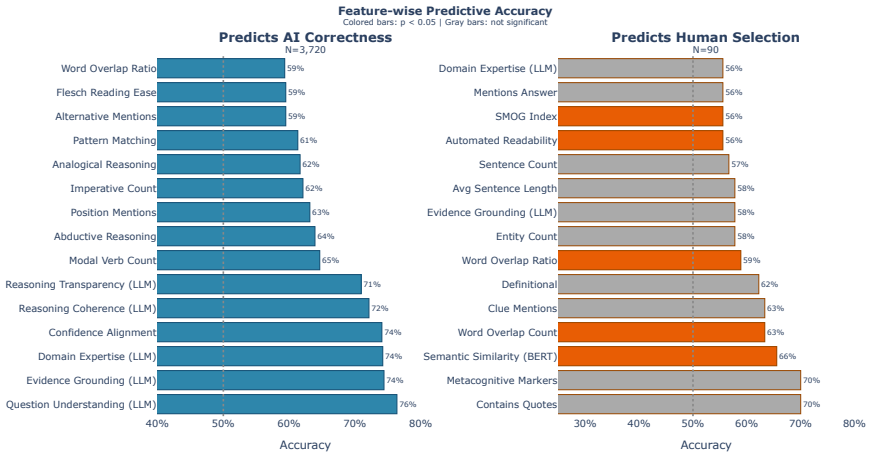
One shared signal:Only evidential_grounding appears in both top-10 lists, suggesting humans recognize quality when reasoning explicitly cites evidence
-
[6]
LLM features predict correctness: question_comprehension (76%), evidential_grounding (74%), domain_expertise_display (74%), and reasoning_coherence (72%) strongly predict whether theAIis correct
-
[7]
Surface features predict hu- man trust: has_quotes (70%), semantic_similarity (66%), and word_overlap_ratio (63%) predict human selection but are weak correctness signals
-
[8]
quizbowlAIagent
Implication:AIexplanations should make reasoning explicit through evidence citation. Humans should evaluate reasoning quality rather than surface familiarity. F.5 Implementation Details Features are extracted using a modular pipeline with seven extractors: • SurfaceLinguisticExtractor: Uses spaCy for tokenization and POS tagging; textstat for readability ...
-
[9]
All personal and identifiable information has been explicitly anonymized before release
Dataset:All tournament questions (tossup and bonus), human responses at each stage (initial guess, final answer),AIresponses (answers, confidence scores, explanations), muting decisions, answer correctness la- bels, and anonymized player metadata (experience level, team assignment). All personal and identifiable information has been explicitly anonymized ...
-
[10]
Available at https://github.com/qanta-org/ qb-tournament-runner
Tournament application:Source code for the web application, including the buzzer integration, bonus collaboration interface, moderator dashboard, and draft management system. Available at https://github.com/qanta-org/ qb-tournament-runner
-
[11]
Available at https://github.com/qanta-org/ qanta25-analysis
Analysis scripts:All scripts used for feature extraction, statistical testing, figure generation, and the logistic regression analyses reported in this paper. Available at https://github.com/qanta-org/ qanta25-analysis. System Models Used Calls Approach System 1 GPT-4o-mini (answer) 1 Single-shotlightweight model with strict JSON-only output for- mat. Sys...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.