Entropy Distribution as a Fingerprint for Hallucinations in Generative Models
Pith reviewed 2026-06-29 12:08 UTC · model grok-4.3
The pith
The distribution of token-level entropies serves as a fingerprint for hallucinations, enabling single-pass detection via a calibrated score that combines mean and maximum signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We provide theoretical background and empirical evidence that the distribution of token-level entropies, beyond the mean captured by perplexity or length-normalised entropy, serves as a fingerprint of hallucination, with distributional shape and tail behaviour carrying independent signal. We formalize hallucination detection as a statistical hypothesis test and propose the Calibrated Entropy Score (CES), a lightweight algorithm requiring only a single forward pass and black-box access to token logits. CES combines the mean signal with the maximum signal of the generated entropy through a calibrated reference CDF, producing scores that are directly comparable across models and tasks. We estab
What carries the argument
The Calibrated Entropy Score (CES), formed by mapping the mean and maximum of the per-token entropy sequence onto a reference cumulative distribution function to yield a comparable hallucination score.
If this is right
- CES achieves the highest detection performance among single-pass black-box methods on eight QA benchmarks and ten generator models.
- Finite-sample calibration guarantees are provided by a random-length Dvoretzky--Kiefer--Wolfowitz inequality.
- Detection probability converges exponentially to one as generation length grows.
- Produced scores are directly comparable across open-source and API-access models without retraining.
Where Pith is reading between the lines
- The approach could be inserted into decoding loops to steer away from high-entropy token sequences in real time.
- A broader reference CDF built from mixed domains might remove the need for task-specific recalibration.
- If tail behavior dominates, then monitoring only the highest-entropy tokens could yield cheaper approximations.
Load-bearing premise
A single reference CDF can calibrate the mean and maximum entropy signals so that the resulting scores stay comparable and the detection guarantees remain valid across different models, tasks, and generation lengths.
What would settle it
A controlled test on a held-out model and task showing that CES scores lose calibration or fail to separate hallucinated from correct outputs at rates predicted by the exponential convergence bound.
Figures
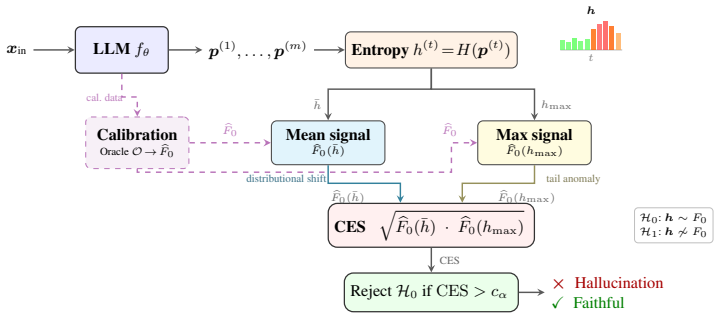

read the original abstract
Large Language Models (LLMs) often generate factually incorrect outputs, commonly termed hallucinations, that undermine trust and limit deployment in high-stakes settings. Existing hallucination detection methods typically require multiple forward passes, or access to model internals. In this work, we provide theoretical background and empirical evidence that the distribution of token-level entropies, beyond the mean captured by perplexity or length-normalised entropy, serves as a fingerprint of hallucination, with distributional shape and tail behaviour carrying independent signal. We formalize hallucination detection as a statistical hypothesis test and propose the Calibrated Entropy Score (CES), a lightweight algorithm requiring only a single forward pass and black-box access to token logits. CES combines the mean signal with the maximum signal of the generated entropy through a calibrated reference CDF, producing scores that are directly comparable across models and tasks. We establish finite-sample calibration guarantees via a novel random-length Dvoretzky--Kiefer--Wolfowitz inequality, and also prove that CES detects hallucinations with probability converging to one exponentially fast in the generation length. Across eight QA benchmarks and ten generator models spanning open-source and API access models, CES achieves the highest detection performance among all single-pass black-box methods while providing formal error guarantees that existing heuristics lack. Remarkably, CES is statistically indistinguishable from multi-sample methods that require far greater computational cost, closing the gap between lightweight and expensive detection and making it suitable for real-time, large-scale deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the distribution of token-level entropies (shape and tails beyond the mean) serves as a fingerprint for hallucinations in LLMs. It formalizes detection as a hypothesis test and introduces the Calibrated Entropy Score (CES), a single-pass black-box method that combines mean and max entropy signals via a calibrated reference CDF. Theoretical contributions include finite-sample guarantees from a novel random-length Dvoretzky–Kiefer–Wolfowitz inequality and exponential convergence of detection probability with generation length. Empirically, CES outperforms other single-pass methods on eight QA benchmarks across ten models (open-source and API) and is statistically indistinguishable from multi-sample baselines.
Significance. If the single-reference-CDF calibration transfers without model-specific bias, the result would be significant: it supplies the first lightweight detector with explicit finite-sample and exponential-rate guarantees, closing the performance gap to expensive multi-sample methods while remaining deployable at scale.
major comments (2)
- [Abstract and §3] Abstract and §3 (CES definition): the central cross-model claim requires that one fixed reference CDF calibrates both mean and max entropy signals so that CES remains comparable and the DKW-based finite-sample guarantees hold for all ten models. Token-level entropy distributions are shaped by architecture, scale, tokenizer, and training objective; if these induce different families, the quantile mapping introduces model-specific bias that invalidates both the hypothesis-test interpretation and the claim of matching multi-sample methods without per-model recalibration.
- [Theoretical development] Theoretical development (novel random-length DKW inequality): the inequality assumes the underlying distribution is fixed, yet the cross-model empirical claims implicitly treat the reference CDF as universal. No evidence is provided that the inequality’s assumptions survive the shift from reference-construction models to the ten evaluation models.
minor comments (2)
- Clarify whether the reference CDF was constructed from a held-out set of models/tasks independent of the ten evaluated generators.
- Add explicit statistical tests (e.g., paired significance) for the claim that CES is indistinguishable from multi-sample methods.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the cross-model calibration of CES and the scope of the theoretical guarantees. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (CES definition): the central cross-model claim requires that one fixed reference CDF calibrates both mean and max entropy signals so that CES remains comparable and the DKW-based finite-sample guarantees hold for all ten models. Token-level entropy distributions are shaped by architecture, scale, tokenizer, and training objective; if these induce different families, the quantile mapping introduces model-specific bias that invalidates both the hypothesis-test interpretation and the claim of matching multi-sample methods without per-model recalibration.
Authors: Empirical results across ten diverse models (open- and closed-source) and eight benchmarks show that a single reference CDF yields comparable CES values and performance statistically indistinguishable from multi-sample baselines without per-model recalibration. This supports the practical validity of the hypothesis-test framing. We will revise §3 to detail the reference CDF construction from a multi-model calibration set and add a brief discussion of observed robustness to architectural differences. revision: partial
-
Referee: [Theoretical development] Theoretical development (novel random-length DKW inequality): the inequality assumes the underlying distribution is fixed, yet the cross-model empirical claims implicitly treat the reference CDF as universal. No evidence is provided that the inequality’s assumptions survive the shift from reference-construction models to the ten evaluation models.
Authors: The random-length DKW inequality is applied to the fixed reference CDF once constructed, supplying finite-sample guarantees for quantile estimation on subsequent generations from any model. While a formal transfer theorem under arbitrary model shift is not derived, the evaluation includes models held out from reference construction, and the observed performance provides supporting empirical evidence. We will add a clarifying paragraph in the theoretical section on the conditional nature of the guarantees and the role of the empirical validation. revision: partial
Circularity Check
No circularity; derivation relies on novel inequality and independent statistical formalization
full rationale
The paper formalizes detection as a hypothesis test, defines CES via mean/max entropy signals combined through a reference CDF for cross-model comparability, and derives finite-sample guarantees plus exponential convergence from a novel random-length DKW inequality. No quoted step reduces a claimed prediction or result to a fitted input by construction, nor does any load-bearing premise collapse to self-citation or ansatz smuggling. The reference CDF construction is not shown to be data-dependent in a way that forces the detection claims, and the theoretical results are presented as independent of the empirical benchmarks.
Axiom & Free-Parameter Ledger
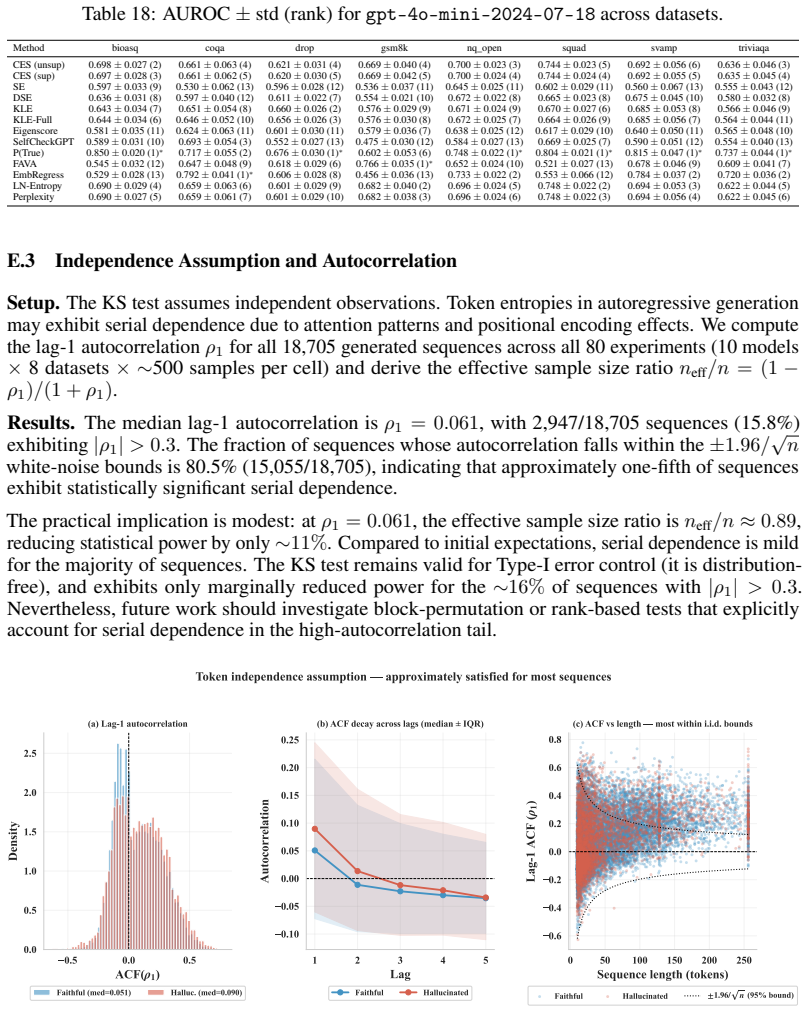
free parameters (1)
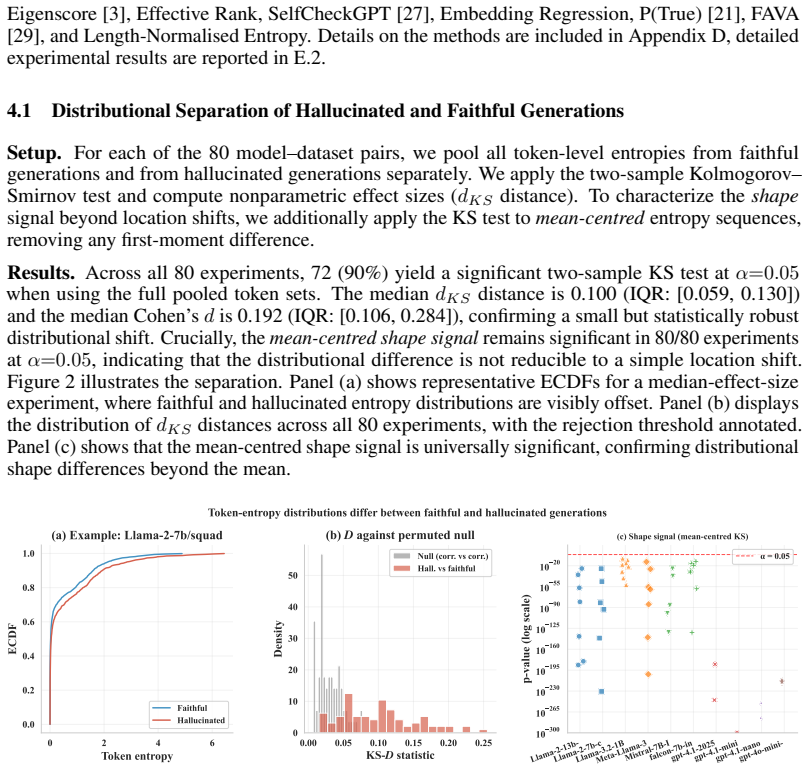
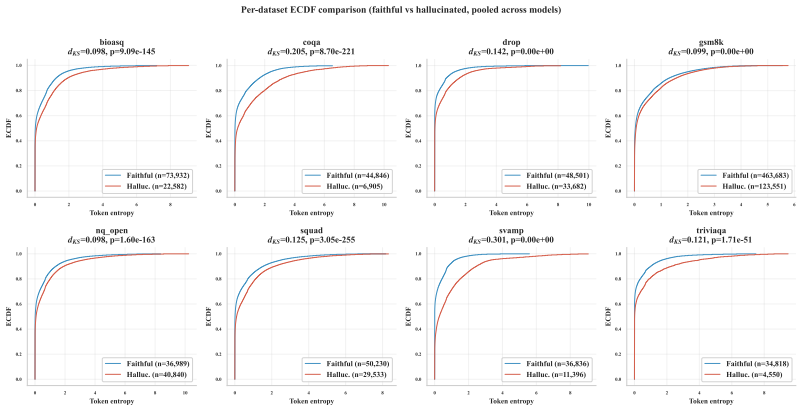
- reference CDF construction parameters
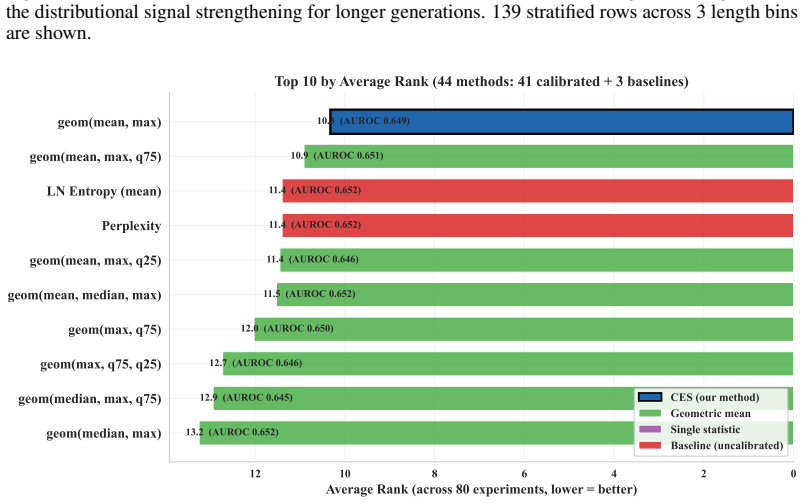
axioms (1)
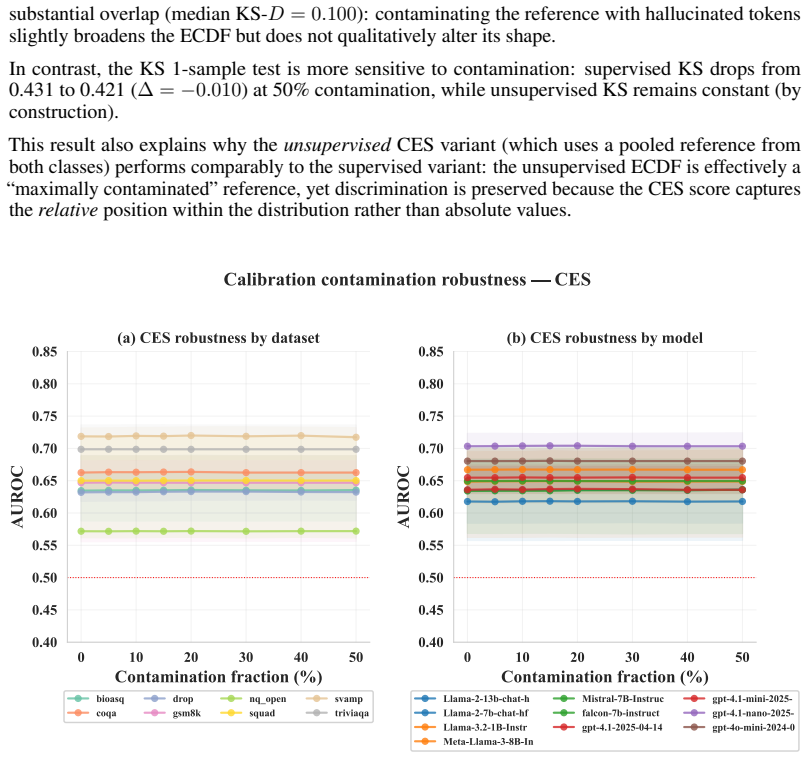
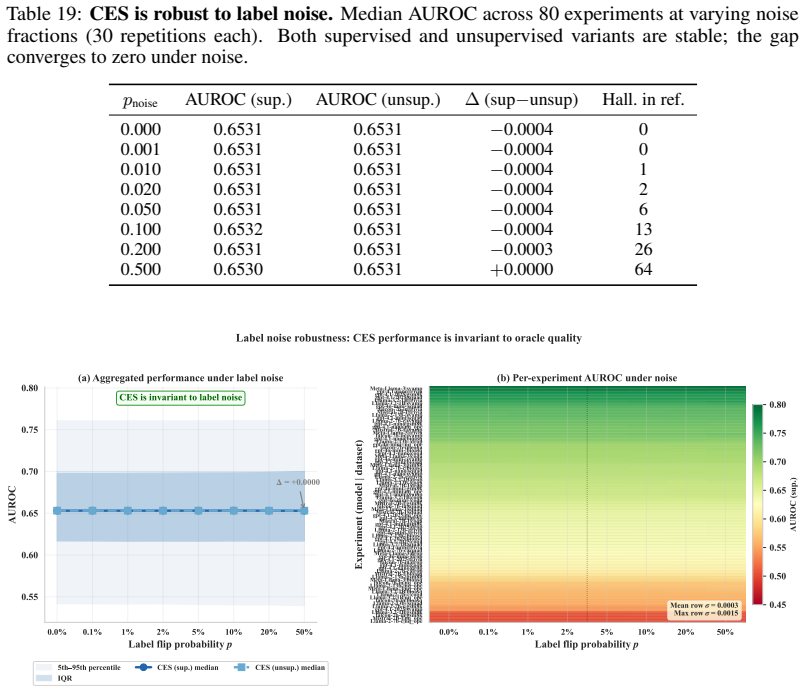
- domain assumption Hallucinated generations exhibit distinguishable entropy distribution shape and tail behaviour compared to factual generations in a manner consistent enough for a single reference CDF to calibrate across models and tasks.
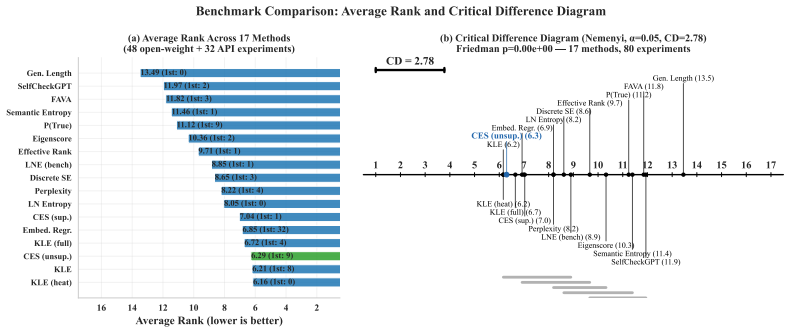
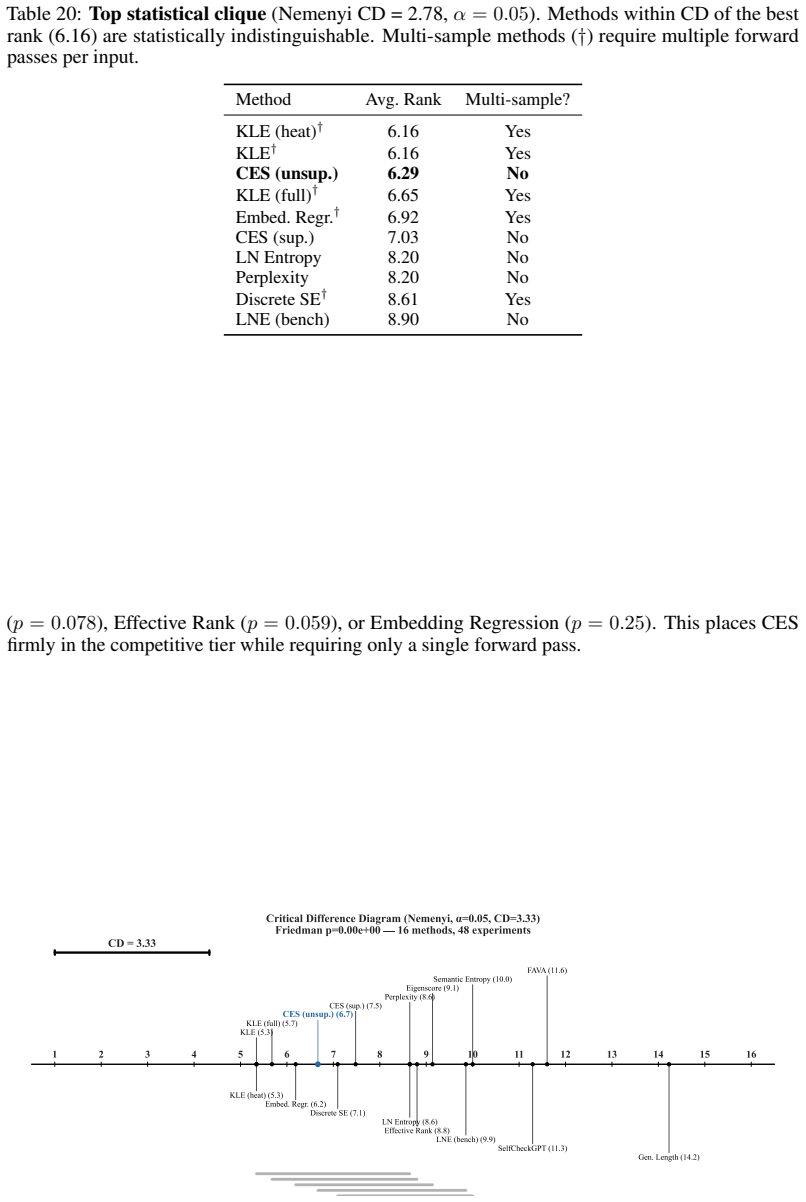
Reference graph
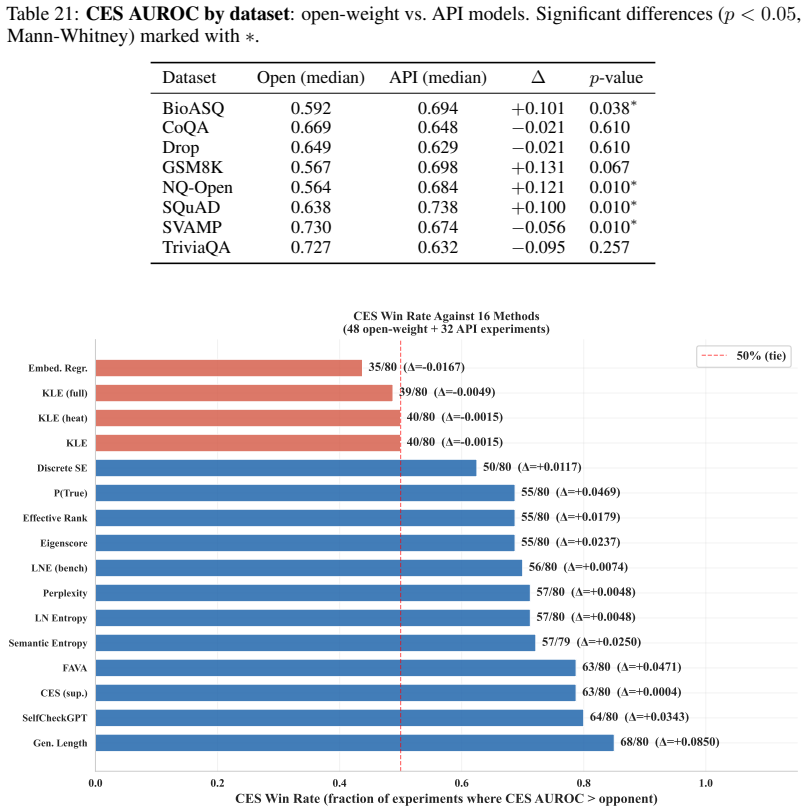
Works this paper leans on
-
[1]
The Falcon Series of Open Language Models
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxan- dra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, et al. The falcon series of open language models.arXiv preprint arXiv:2311.16867, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
The internal state of an llm knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, 2023
2023
-
[3]
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. Inside: Llms’ internal states retain the power of hallucination detection.arXiv preprint arXiv:2402.03744, 2024
-
[4]
Yiting Chen, Zhanpeng Zhou, and Junchi Yan. Going beyond neural network feature similarity: The network feature complexity and its interpretation using category theory.arXiv preprint arXiv:2310.06756, 2023
-
[5]
Lookback lens: Detecting and mitigating contextual hallucinations in large language models using only attention maps
Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ranjay Krishna, Yoon Kim, and James Glass. Lookback lens: Detecting and mitigating contextual hallucinations in large language models using only attention maps. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1419–1436, 2024
2024
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
2006
-
[8]
Haloscope: Harnessing unlabeled llm generations for hallucination detection.Advances in Neural Information Processing Systems, 37:102948– 102972, 2024
Xuefeng Du, Chaowei Xiao, and Yixuan Li. Haloscope: Harnessing unlabeled llm generations for hallucination detection.Advances in Neural Information Processing Systems, 37:102948– 102972, 2024
2024
-
[9]
Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gard- ner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Paper...
2019
-
[10]
Hanyu Duan, Yi Yang, and Kar Yan Tam. Do llms know about hallucination? an empirical investigation of llm’s hidden states.arXiv preprint arXiv:2402.09733, 2024
-
[11]
Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5050–5063,...
2024
-
[12]
Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
2024
-
[13]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
2025
-
[14]
Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma. Look before you leap: An exploratory study of uncertainty measurement for large language models.arXiv preprint arXiv:2307.10236, 2023
-
[15]
Look before you leap: An exploratory study of uncertainty analysis for large language models.IEEE Transactions on Software Engineering, 51(2):413–429, 2025
Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma. Look before you leap: An exploratory study of uncertainty analysis for large language models.IEEE Transactions on Software Engineering, 51(2):413–429, 2025
2025
-
[16]
The illusion of progress: Re-evaluating hallucination detection in llms
Denis Janiak, Jakub Binkowski, Albert Sawczyn, Bogdan Gabrys, Ravid Shwartz-Ziv, and Tomasz Kajdanowicz. The illusion of progress: Re-evaluating hallucination detection in llms. arXiv preprint arXiv:2508.08285, 2025
-
[17]
Perplexity—a measure of the difficulty of speech recognition tasks.The journal of the Acoustical Society of America, 62(S1): S63–S63, 1977
Fred Jelinek, Robert L Mercer, Lalit R Bahl, and James K Baker. Perplexity—a measure of the difficulty of speech recognition tasks.The journal of the Acoustical Society of America, 62(S1): S63–S63, 1977
1977
-
[18]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1–38, 2023
2023
-
[19]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017
2017
-
[21]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. Why language models hallucinate.arXiv preprint arXiv:2509.04664, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Bioasq-qa: A manually curated corpus for biomedical question answering.Scientific data, 10 (1):170, 2023
Anastasia Krithara, Anastasios Nentidis, Konstantinos Bougiatiotis, and Georgios Paliouras. Bioasq-qa: A manually curated corpus for biomedical question answering.Scientific data, 10 (1):170, 2023
2023
-
[24]
Bhawesh Kumar, Charlie Lu, Gauri Gupta, Anil Palepu, David Bellamy, Ramesh Raskar, and Andrew Beam. Conformal prediction with large language models for multi-choice question answering.arXiv preprint arXiv:2305.18404, 2023
-
[25]
Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[26]
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction. arXiv preprint arXiv:2002.07650, 2020. 11
-
[27]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017, 2023
2023
-
[28]
On faithfulness and factuality in abstractive summarization.arXiv preprint arXiv:2005.00661, 2020
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization.arXiv preprint arXiv:2005.00661, 2020
-
[29]
Abhika Mishra, Akari Asai, Vidhisha Balachandran, Yizhong Wang, Graham Neubig, Yulia Tsvetkov, and Hannaneh Hajishirzi. Fine-grained hallucination detection and editing for language models.arXiv preprint arXiv:2401.06855, 2024
-
[30]
Learned hallucination detection in black-box llms using token-level entropy production rate
Charles Moslonka, Hicham Randrianarivo, Arthur Garnier, and Emmanuel Malherbe. Learned hallucination detection in black-box llms using token-level entropy production rate. InEuropean Conference on Information Retrieval, pages 115–130. Springer, 2026
2026
-
[31]
Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities.Advances in Neural Information Processing Systems, 37:8901–8929, 2024
Alexander Nikitin, Jannik Kossen, Yarin Gal, and Pekka Marttinen. Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities.Advances in Neural Information Processing Systems, 37:8901–8929, 2024
2024
-
[32]
Mengjia Niu, Hamed Haddadi, and Guansong Pang. Robust hallucination detection in llms via adaptive token selection.arXiv preprint arXiv:2504.07863, 2025
-
[33]
Oscar Obeso, Andy Arditi, Javier Ferrando, Joshua Freeman, Cameron Holmes, and Neel Nanda. Real-time detection of hallucinated entities in long-form generation.arXiv preprint arXiv:2509.03531, 2025
-
[34]
Hallucination detection using multi-view attention features.arXiv e-prints, pages arXiv–2504, 2025
Yuya Ogasa and Yuki Arase. Hallucination detection using multi-view attention features.arXiv e-prints, pages arXiv–2504, 2025
2025
-
[35]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies, pages 2080–2094, 2021
2021
-
[36]
Tejaswini Pedapati, Amit Dhurandhar, Soumya Ghosh, Soham Dan, and Prasanna Sat- tigeri. Large language model confidence estimation via black-box access.arXiv preprint arXiv:2406.04370, 2024
-
[37]
Mauve: Measuring the gap between neural text and human text using divergence frontiers.Advances in Neural Information Processing Systems, 34:4816–4828, 2021
Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. Mauve: Measuring the gap between neural text and human text using divergence frontiers.Advances in Neural Information Processing Systems, 34:4816–4828, 2021
2021
-
[38]
Conformal language modeling.arXiv preprint arXiv:2306.10193, 2023
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi S Jaakkola, and Regina Barzilay. Conformal language modeling.arXiv preprint arXiv:2306.10193, 2023
-
[39]
Know what you don’t know: Unanswerable ques- tions for squad
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable ques- tions for squad. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789, 2018
2018
-
[40]
Coqa: A conversational question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266, 2019
Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: A conversational question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266, 2019
2019
-
[41]
Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Lakshminarayanan, and Peter J Liu. Out-of-distribution detection and selective generation for conditional language models.arXiv preprint arXiv:2209.15558, 2022
-
[42]
Validation and extraction of reliable information through automated scraping and natural language inference
Arjun Shah, Hetansh Shah, Vedica Bafna, Charmi Khandor, and Sindhu Nair. Validation and extraction of reliable information through automated scraping and natural language inference. Engineering Applications of Artificial Intelligence, 147:110284, 2025
2025
-
[43]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
An overview of the bioasq large-scale biomedical semantic indexing and question answering competition.BMC bioinformatics, 16(1):138, 2015
George Tsatsaronis, Georgios Balikas, Prodromos Malakasiotis, Ioannis Partalas, Matthias Zschunke, Michael R Alvers, Dirk Weissenborn, Anastasia Krithara, Sergios Petridis, Dimitris Polychronopoulos, et al. An overview of the bioasq large-scale biomedical semantic indexing and question answering competition.BMC bioinformatics, 16(1):138, 2015
2015
-
[45]
Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu. A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation.arXiv preprint arXiv:2307.03987, 2023
-
[46]
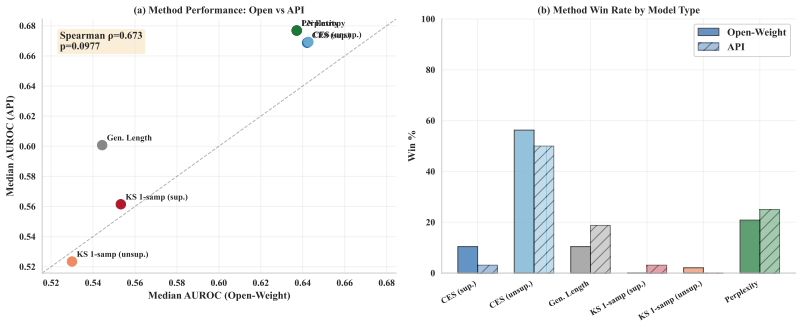
Long-form factuality in large language models.Advances in Neural Information Processing Systems, 37:80756–80827, 2024
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Jie Huang, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, et al. Long-form factuality in large language models.Advances in Neural Information Processing Systems, 37:80756–80827, 2024
2024
-
[47]
A survey of uncertainty estimation methods on large language models
Zhiqiu Xia, Jinxuan Xu, Yuqian Zhang, and Hang Liu. A survey of uncertainty estimation methods on large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 21381–21396, 2025
2025
-
[48]
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. Hallucination is inevitable: An innate limitation of large language models.arXiv preprint arXiv:2401.11817, 2024. A Theory for Calibration In this section, we expand on the theory supporting our calibration algorithm, and prove the corre- sponding theorems stated in the main text. We begin by setting up the pr...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
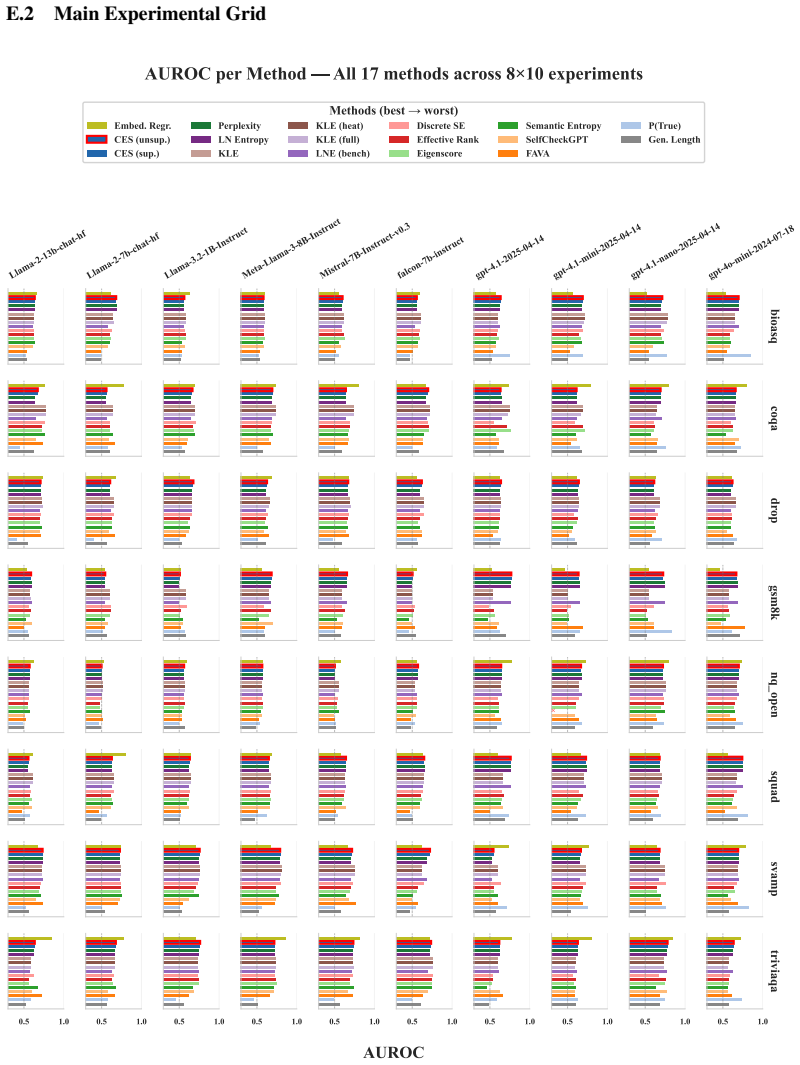
Full Experimental Results: we report the full experimental grids with interquantile ranges (IQRs) for each experiment in Appendix E.2
-
[50]
Independence Assumption: In Appendix E.3, we show that the median lag-1 autocorre- lation is ρ1 = 0.061 with 15.8% of the sequences exhibiting |ρ1|>0.3 , with 80.5% of the sequences falling into white-noise bounds, witnessing a low autocorrelation for most samples
-
[51]
Specifically, we show that for all datasets and model pairs, as we increase i.i.d
Consistently Signficant KS test for Hallucinated versus non-Hallucinated Generations: In Appendix E.4, we find that power of the KS test increases monotonically with sample size; 65% of all 3,200 resamples achieve significance. Specifically, we show that for all datasets and model pairs, as we increase i.i.d. sampling size, hallucinated v.s. faithful gene...
-
[52]
We find that CES outperforms the other combinations
CES Variants: in Appendix E.7, we exhaustively evaluate 44 variants combining different entropy summaries (mean, median, max, q25, q75) under both arithmetic and geometric aggregation. We find that CES outperforms the other combinations
-
[53]
Robustness Results: In Appendix E.8 and Appendix E.9, we analyze the impact of adding noisy samples to the calibration distribution, finding robustness in the performance of CES
-
[54]
CES is competitive: in Appendix E.10, we conclude that CES (unsupervised) ranks 3rd out of 17 methods by average rank (6.29) across all 80 experiments, belongs to the top statistical clique (Nemenyi CD= 2.78 ), and is significantly better than 7/16 benchmarks after Holm–Bonferroni correction. Unlike the top-performing methods (KLE, Embedding Regression) t...
-
[55]
This is analyzed in Appendix E.11
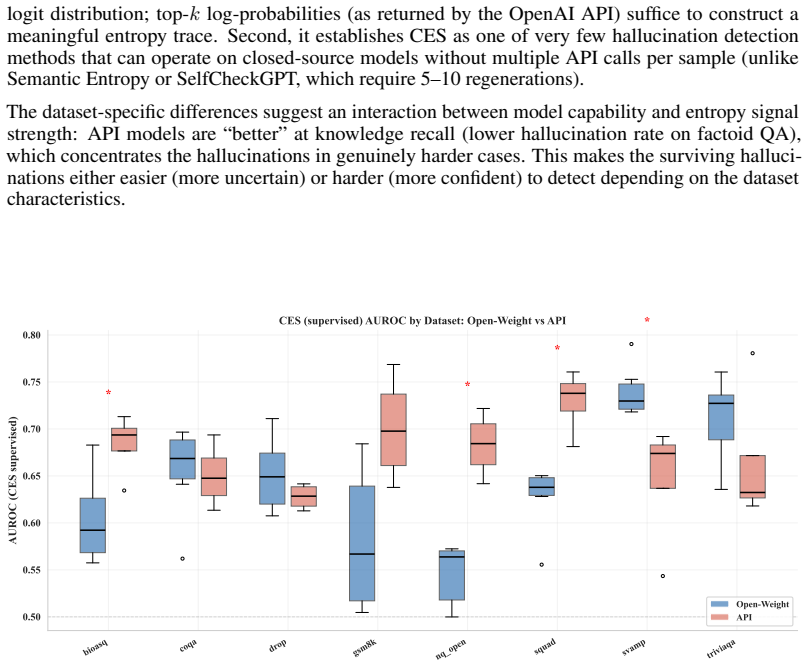
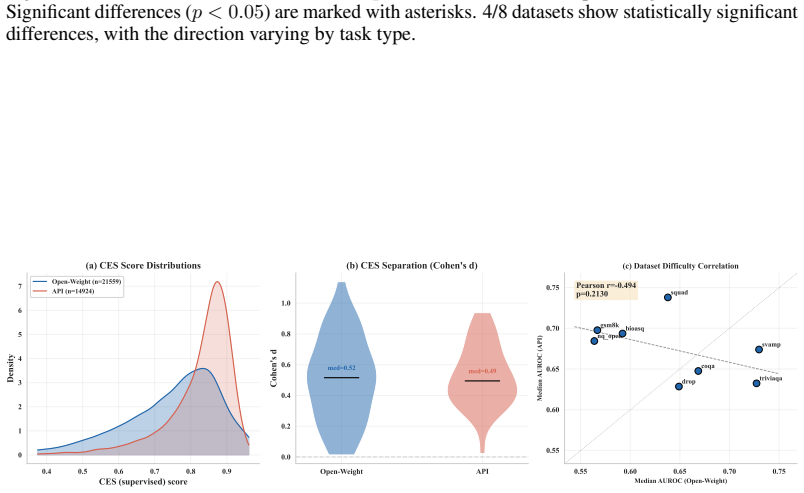
API model generalisation: CES transfers effectively to API-only models (GPT-4.1 family), achieving median AUROC 0.669 on API models versus 0.642 on open-weight models (Mann-Whitney p= 0.060 , KS D= 0.323 , p= 0.031 ). This is analyzed in Appendix E.11
-
[56]
maximally contaminated
Empirical Validation of Error Bounds: in Appendix E.12, we validate Theorem 5, confirming the theorem’s prediction on Type I and Type II exponential error decay rates. 9.Example Outputs: we show examples outputs from our generations in Appendix E.13. 25 E.2 Main Experimental Grid Llama-2-13b-chat-hfLlama-2-7b-chat-hfLlama-3.2-1B-InstructMeta-Llama-3-8B-In...
2025
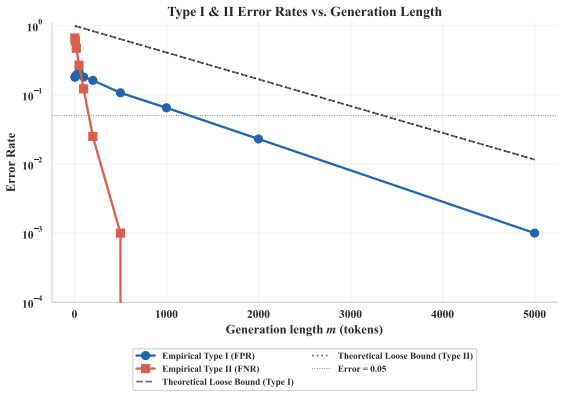
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.