ResearchLoop: An Evidence-Gated Control Plane for AI-Assisted Research
Pith reviewed 2026-06-29 11:56 UTC · model grok-4.3
The pith
ResearchLoop models AI-assisted research as evidence-gated state transitions in a repository runtime to keep claims auditable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ResearchLoop is an evidence-gated control plane for AI-assisted computational research that treats research questions, task contracts, evidence objects, claim ledgers, closeouts, and paper bindings as durable project state realized as a repository-backed runtime, with a complete protocol specification, state model, transition rules, claim-admission algorithm, and insight-compounding mechanism demonstrated through an experimental record spanning versions V0 to V9.
What carries the argument
The evidence-gated control plane with its defined state objects and transition rules, realized as a repository-backed runtime.
If this is right
- Task contracts and evidence objects must precede any claim ledger entry.
- The claim-admission algorithm gates what enters the ledger based on supplied evidence.
- Closeouts and paper bindings create explicit links from evidence to final outputs.
- All artifacts remain preserved for verification across the nine reported versions.
Where Pith is reading between the lines
- The repository-backed state model could extend to multi-researcher teams by adding shared access rules.
- The same state objects might support reproducibility checks in fields outside computational research.
- Automated collection of evidence objects from code execution logs could reduce manual overhead in the protocol.
Load-bearing premise
Enforcing the listed state objects and transition rules will meaningfully reduce the publication risk that paper claims become easier to state than to audit.
What would settle it
An independent re-audit of a completed ResearchLoop project that finds a lower rate of unverifiable claims than in matched projects conducted without the state model and admission rules.
Figures
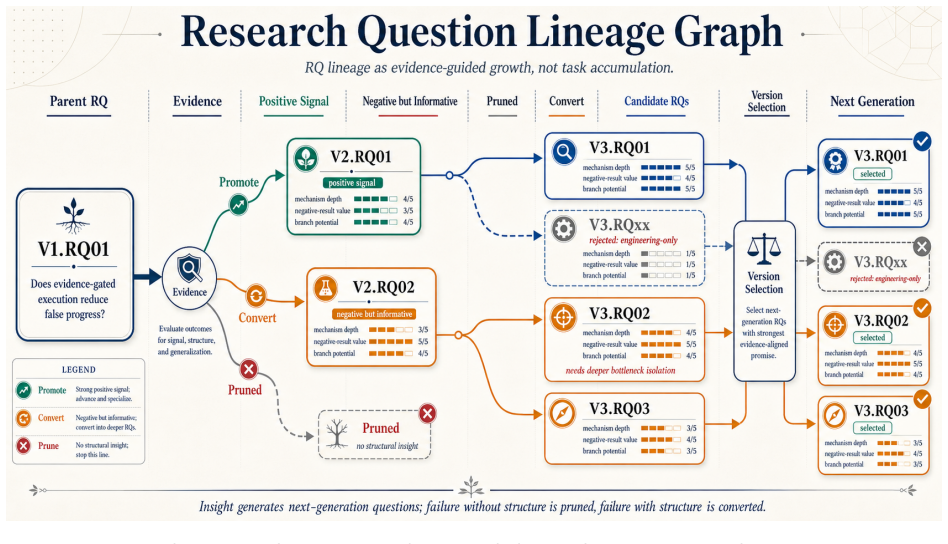

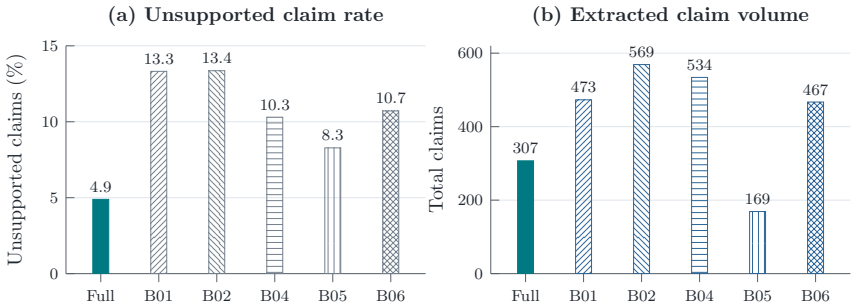
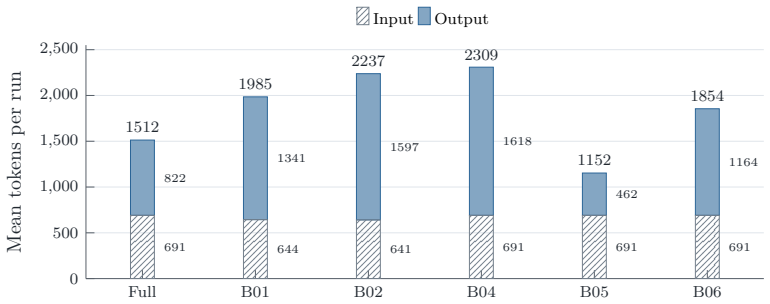
read the original abstract
AI-assisted research compresses ideation, implementation, evaluation, and manuscript writing into a single interactive loop. This compression is useful, but it also creates a publication risk: paper claims can become easier to state than to audit. We present ResearchLoop, an evidence-gated control plane for AI-assisted computational research. ResearchLoop treats research questions, task contracts, evidence objects, claim ledgers, closeouts, and paper bindings as durable project state, realized here as a repository-backed runtime. This technical report provides the complete protocol specification, state model, transition rules, claim-admission algorithm, and insight-compounding mechanism. It also reports the full experimental record spanning nine versions (V0--V9), including a self-hosting case study, a controlled task-suite study with component ablations, a mathematical olympiad evaluation, and a supplementary SciCode boundary experiment evaluated with the official generated-code harness. All artifacts, manifests, and verification reports are preserved in the project repository.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ResearchLoop, an evidence-gated control plane for AI-assisted computational research. It models research questions, task contracts, evidence objects, claim ledgers, closeouts, and paper bindings as durable repository-backed state, supplies the full protocol specification, state model, transition rules, claim-admission algorithm, and insight-compounding mechanism, and reports an experimental record across nine self-hosting versions (V0–V9), a controlled task-suite ablation study, a mathematical olympiad evaluation, and a SciCode harness boundary experiment, with all artifacts preserved in the repository.
Significance. If the state model and transition rules demonstrably reduce the fraction of unverifiable claims or auditor effort, the work would supply a concrete, repository-native mechanism for mitigating a recognized risk in AI-assisted research pipelines. The explicit provision of the complete protocol, all manifests, and verification reports constitutes a reproducibility strength.
major comments (1)
- [experimental record (V0–V9 case study, task-suite ablations, olympiad and SciCode evaluations)] The central claim—that treating the listed objects as durable state together with the claim-admission algorithm will reduce the risk that claims become easier to state than to audit—is not supported by the reported experiments. The V0–V9 self-hosting case study, task-suite ablations, olympiad evaluation, and SciCode run measure only whether the runtime executes the protocol and produces outputs; they contain no controlled (with/without ResearchLoop) measurement of auditor effort, fraction of claims traceable to evidence objects, or rate of unverifiable claims.
minor comments (2)
- [protocol specification] The abstract refers to an “insight-compounding mechanism” whose precise definition and interaction with the claim ledger should be stated explicitly in the protocol section.
- [state model] Notation for the state objects (research question, task contract, evidence object, etc.) is introduced in the abstract but would benefit from a single consolidated table or diagram early in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the distinction between protocol feasibility and direct measurement of risk reduction. We respond to the major comment below.
read point-by-point responses
-
Referee: [experimental record (V0–V9 case study, task-suite ablations, olympiad and SciCode evaluations)] The central claim—that treating the listed objects as durable state together with the claim-admission algorithm will reduce the risk that claims become easier to state than to audit—is not supported by the reported experiments. The V0–V9 self-hosting case study, task-suite ablations, olympiad evaluation, and SciCode run measure only whether the runtime executes the protocol and produces outputs; they contain no controlled (with/without ResearchLoop) measurement of auditor effort, fraction of claims traceable to evidence objects, or rate of unverifiable claims.
Authors: We agree that the reported experiments do not contain a controlled with/without comparison that directly quantifies reductions in auditor effort, claim traceability, or unverifiable-claim rates. The V0–V9 self-hosting record, task-suite ablations, olympiad evaluation, and SciCode harness run are intended to establish that the state model, transition rules, and claim-admission algorithm can be realized as repository-backed durable state and can be executed on representative research tasks, including the self-hosting case. The protocol’s design (evidence objects as prerequisites for claim admission, immutable ledgers, and closeout bindings) is presented as a mechanism that enforces traceability by construction; the experiments demonstrate that this mechanism is implementable and functional. We have revised the abstract, introduction, and a new limitations subsection to distinguish the feasibility results from a quantitative risk-reduction study and to note that a dedicated auditor-effort experiment remains future work. revision: partial
Circularity Check
No circularity: protocol and experiments are self-contained design descriptions
full rationale
The paper specifies a state model, transition rules, and claim-admission algorithm as an engineering artifact, then reports runtime behavior on task suites and self-hosting runs. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs. No self-citations are invoked as load-bearing uniqueness theorems. The self-hosting case study applies the system to its own development record but does not define the protocol's correctness via its own outputs; the central claims remain descriptive of the implemented control plane rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
McLean, Paul Norgaard, et al
Eser Ayg¨ un, Anastasiya Belyaeva, Gheorghe Comanici, Marc Coram, Hongyuan Cui, Jennifer Garrison, Renee Johnston, Amanda Kast, Cory Y. McLean, Paul Norgaard, et al. An AI system to help scientists write expert-level empirical software.Nature, 2026
2026
-
[2]
Introducing Devin, the first AI software engineer, 2024
Cognition AI. Introducing Devin, the first AI software engineer, 2024
2024
-
[3]
Floden, Pablo Prieto Barja, Emilio Palumbo, and Cedric Notredame
Paolo Di Tommaso, Maria Chatzou, Evan W. Floden, Pablo Prieto Barja, Emilio Palumbo, and Cedric Notredame. Nextflow enables reproducible computational workflows.Nature Biotechnology, 35(4):316–319, 2017
2017
-
[4]
Researchgym: Evaluating language model agents on real-world AI research, 2026
Aniketh Garikaparthi, Manasi Patwardhan, and Arman Cohan. Researchgym: Evaluating language model agents on real-world AI research, 2026
2026
-
[5]
Aider: AI pair programming in your terminal, 2023
Paul Gauthier. Aider: AI pair programming in your terminal, 2023
2023
-
[6]
Szostkiewicz, Dmytro Shved, Gavin J
Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J. Szostkiewicz, Dmytro Shved, Gavin J. Gyimesi, Jon M. Laurent, Samantha M. Wright, Muhammed T. Razzak, et al. A multi-agent system for automating scientific discovery.Nature, 2026
2026
-
[7]
Accelerating scientific discovery with co-scientist.Nature, 2026
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Petar Sirkovic, Artiom Myaskovsky, Grzegorz Glowaty, Felix Weissenberger, Alessio Orlandi, Dan Popovici, et al. Accelerating scientific discovery with co-scientist.Nature, 2026
2026
-
[8]
Yukun Huang, Leonardo F. R. Ribeiro, Momchil Hardalov, Bhuwan Dhingra, Markus Dreyer, and Venkatesh Saligrama. Deepfact: Co-evolving benchmarks and agents for deep research factuality.arXiv preprint arXiv:2603.05912, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Autonomous LLM-driven research—from data to human-verifiable research papers.NEJM AI, 2024
Tal Ifargan, Lukas Hafner, Maor Kern, Ori Alcalay, and Roy Kishony. Autonomous LLM-driven research—from data to human-verifiable research papers.NEJM AI, 2024
2024
-
[10]
Shashidhar Reddy Javaji, Yupeng Cao, Haohang Li, Yangyang Yu, Nikhil Muralidhar, and Zining Zhu. Can AI validate science? benchmarking LLMs for accurate scientific claim–evidence reasoning.arXiv preprint arXiv:2506.08235, 2025
-
[11]
Kitchenham, Tore Dyba, and Magne Jorgensen
Barbara A. Kitchenham, Tore Dyba, and Magne Jorgensen. Evidence-based software engineering. InProceedings of the 26th International Conference on Software Engineering, pages 273–281, 2004
2004
-
[12]
Snakemake—a scalable bioinformatics workflow engine
Johannes K¨ oster and Sven Rahmann. Snakemake—a scalable bioinformatics workflow engine. Bioinformatics, 34(20):3600–3600, 2018
2018
-
[13]
DVC: Data version control—Git for data & models, 2021.https://dvc.org
Ruslan Kuprieiev, Dmitry Petrov, Ivan Shcheklein, Pawe l Redzy´ nski, Casper da Costa-Luis, et al. DVC: Data version control—Git for data & models, 2021.https://dvc.org
2021
-
[14]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scien- tist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Alisia Lupidi, Bhavul Gauri, Thomas Simon Foster, Bassel Al Omari, Despoina Magka, Alberto Pepe, et al. AIRS-bench: a suite of tasks for frontier AI research science agents.arXiv preprint arXiv:2602.06855, 2026. 30
-
[16]
PROV-DM: The PROV data model
Luc Moreau and Paolo Missier. PROV-DM: The PROV data model. W3c recommendation, World Wide Web Consortium (W3C), 2013
2013
-
[17]
Alexander Novikov, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaEvolve: A coding agent for scientific and algorithmic dis...
2025
-
[18]
Patil, Kevin Lin, Sarah Wooders, and Joseph E
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems, 2024
2024
-
[19]
Clements
David Lorge Parnas and Paul C. Clements. A rational design process: How and why to fake it. IEEE Transactions on Software Engineering, SE-12(2):251–257, 1986
1986
-
[20]
Guidelines for conducting and reporting case study research in software engineering.Empirical Software Engineering, 14(2):131–164, 2009
Per Runeson and Martin H¨ ost. Guidelines for conducting and reporting case study research in software engineering.Empirical Software Engineering, 14(2):131–164, 2009
2009
-
[21]
Agent Laboratory: Using LLM Agents as Research Assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using LLM agents as research assistants.arXiv preprint arXiv:2501.04227, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
AgentRM: An OS-inspired resource manager for LLM agent systems, 2026
Jianshu She. AgentRM: An OS-inspired resource manager for LLM agent systems, 2026
2026
-
[23]
PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing
Yiwen Song, Yale Song, Tomas Pfister, and Jinsung Yoon. Paperorchestra: A multi-agent framework for automated AI research paper writing, 2026. arXiv:2604.05018
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Poskitt, and Rashina Hoda
Christoph Treude, Christopher M. Poskitt, and Rashina Hoda. Rethinking artifact evaluation for software engineering in the age of generative AI, 2026
2026
-
[25]
Chengcheng Wang, Qinhua Xie, Wei He, Jianyuan Guo, Shiqi Wang, and Chang Xu. Sibyl- autoresearch: Autonomous research needs self-evolving trial-and-error harnesses, not paper generators, 2026. arXiv:2605.22343
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Openhands: An open platform for AI software developers as generalist agents, 2024
Xingyao Wang et al. Openhands: An open platform for AI software developers as generalist agents, 2024
2024
-
[27]
PARNESS: A paper harness for end-to-end automated scien- tific research with dynamic workflows, full-text indexing, and cross-run knowledge accumulation,
Yuchen Wang and Zhongzhi Luan. PARNESS: A paper harness for end-to-end automated scien- tific research with dynamic workflows, full-text indexing, and cross-run knowledge accumulation,
-
[28]
Xing, and Zhiting Hu
Zhen Wang, Fan Bai, Zhongyan Luo, Jinyan Su, Kaiser Sun, Xinle Yu, Jieyuan Liu, Kun Zhou, Claire Cardie, Mark Dredze, Eric P. Xing, and Zhiting Hu. FIRE-Bench: Evaluating agents on the rediscovery of scientific insights, 2026
2026
-
[29]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R. Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 31
2024
-
[31]
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
Ruofeng Yang, Yongcan Li, and Shuai Li. ARIS: Autonomous research via adversarial multi- agent collaboration.arXiv preprint arXiv:2605.03042, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
MLflow: A platform for the machine learning lifecycle
Matei Zaharia, Andrew Chen, Aaron Davidson, Ali Ghodsi, Sue Ann Hong, Andy Konwinski, Siddharth Murching, Tomas Nykodym, Paul Ogilvie, Mani Parkhe, Fen Xie, and Corey Zumar. MLflow: A platform for the machine learning lifecycle. InProceedings of the 2nd International Workshop on Data Management for End-to-End Machine Learning, 2018. 32
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.