AtomComposer: Discovering Chemical Space from First Principles with Reinforcement Learning
Pith reviewed 2026-06-29 14:29 UTC · model grok-4.3
The pith
A multi-composition reinforcement learning agent constructs valid 3D isomers from scratch and generalizes to find up to ten times more on unseen chemical formulas than single-composition baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AtomComposer is a self-guided reinforcement learning agent that autonomously assembles valid three-dimensional isomers while respecting stoichiometric constraints. It is trained exclusively online with energy- and validity-based rewards under a multi-composition scheme that exposes the agent to many formulas simultaneously. This yields up to an order of magnitude more valid isomers on unseen test formulas than existing single-composition reinforcement-learning baselines that use per-step energy rewards.
What carries the argument
The multi-composition training scheme, which trains the agent across diverse chemical formulas at once so that learned policies generalize instead of overfitting to any single stoichiometry.
If this is right
- Molecular generation no longer requires large pre-curated datasets that introduce bias.
- Exploration of chemical configuration space can proceed from scratch via online interaction.
- A single trained agent can address many different stoichiometric targets without retraining.
- The same online reinforcement learning loop scales to larger or more complex composition spaces.
Where Pith is reading between the lines
- The same multi-composition principle could be tested on discovering molecules with targeted properties beyond validity and energy.
- If the agent learns reusable construction rules, it may transfer to related tasks such as crystal structure prediction under different constraints.
- The approach suggests that constraint-satisfaction problems in other discrete configuration spaces could benefit from simultaneous training on varied instances.
Load-bearing premise
Training the agent on multiple compositions at once is sufficient to produce broad generalization that works on entirely new chemical formulas without overfitting.
What would settle it
Run the multi-composition agent on a held-out set of formulas never seen during training and measure whether the count of valid isomers remains within a factor of two of the single-composition baselines rather than reaching an order-of-magnitude improvement.
Figures

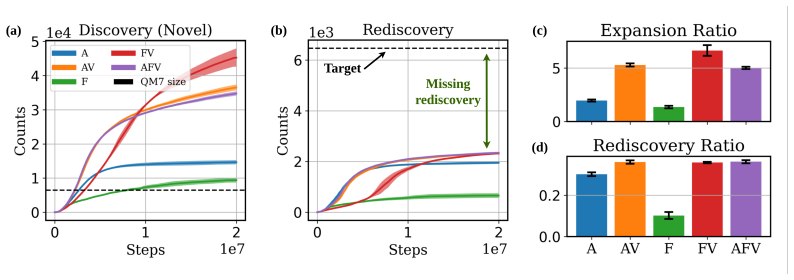
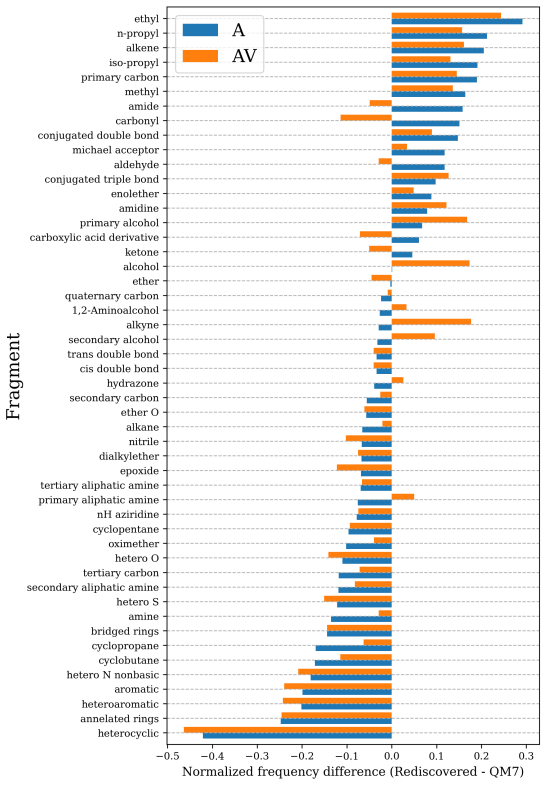
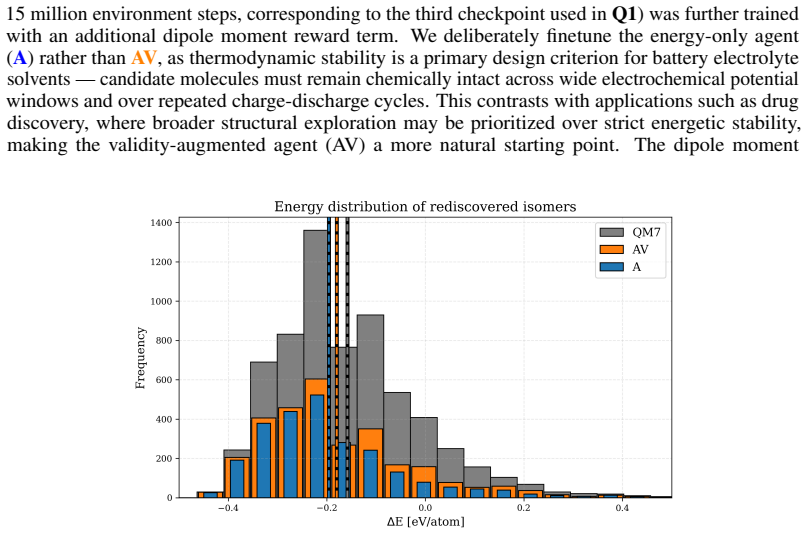
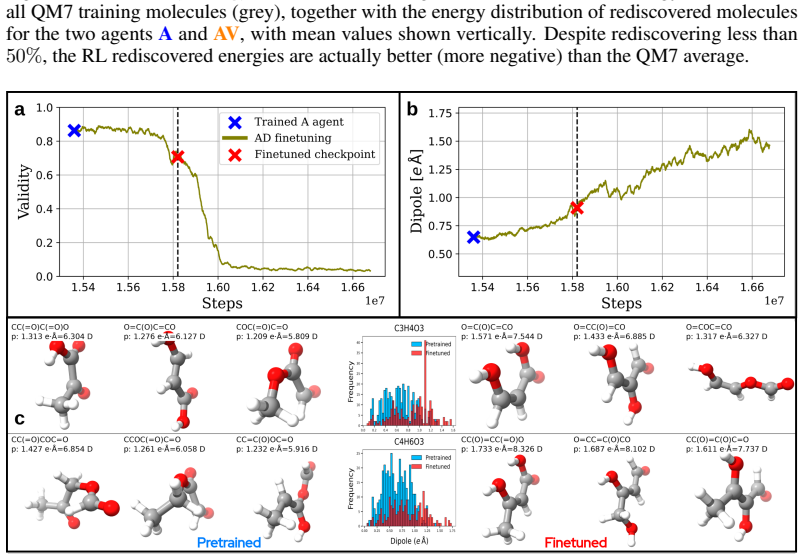
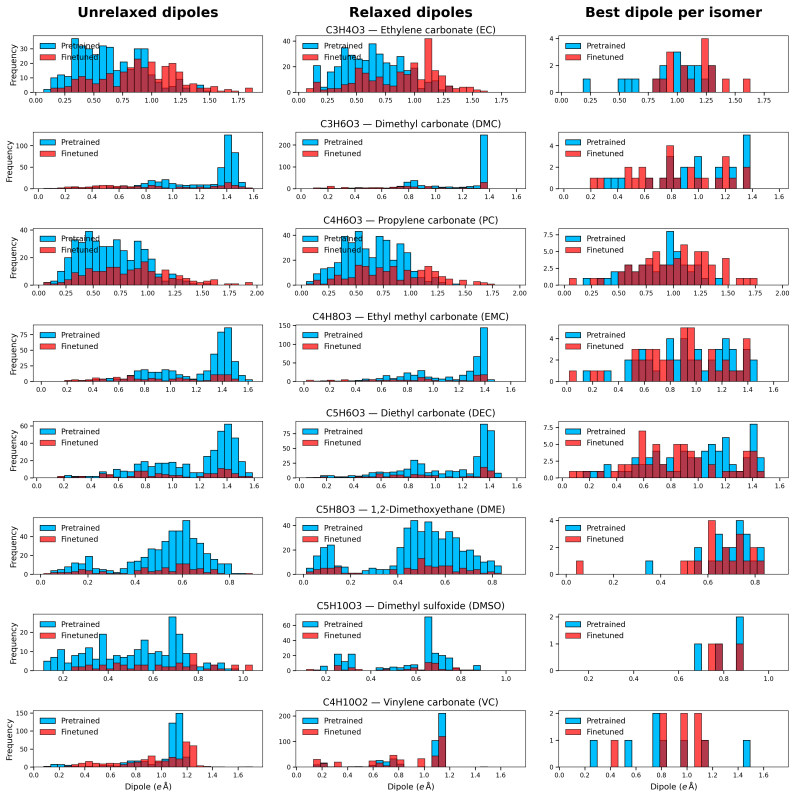
read the original abstract
Discovering novel stable molecules without training data remains a grand scientific challenge. Current molecular generative models are trained on large, pre-curated datasets, which introduce biases and limit exploration of novel chemistry. In contrast, we propose a new paradigm: autonomous, generalized agents capable of mapping vast, unknown chemical spaces without any pretraining. For the first time, we present AtomComposer, a self-guided agent that autonomously constructs valid 3D isomers under stoichiometric constraints and is trained exclusively online using reinforcement learning. Unlike existing approaches that generally overfit to a specific chemical formula, we establish a multi-composition training scheme that enables a broad generalization across diverse chemistry, guided by energy- and validity-based rewards. Our agent can discover up to an order of magnitude more valid isomers on unseen test formulas than existing single-composition reinforcement-learning baselines trained with per-step energy rewards. These results fulfill the promise of online reinforcement learning as a powerful paradigm for scalable, from-scratch exploration of chemical configuration space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AtomComposer, a reinforcement learning agent trained from scratch to autonomously construct valid 3D molecular isomers under stoichiometric constraints. It proposes a multi-composition training scheme using energy- and validity-based rewards that enables generalization across diverse chemistry, claiming the agent discovers up to an order of magnitude more valid isomers on unseen test formulas than single-composition RL baselines trained with per-step energy rewards.
Significance. If the generalization results hold under rigorous OOD evaluation, the work would demonstrate a viable path for dataset-free exploration of chemical configuration space via online RL, addressing biases in pre-curated training data and potentially enabling broader chemical discovery.
major comments (2)
- [Abstract, §3] Abstract and §3 (Methods): The headline claim of order-of-magnitude gains on 'unseen test formulas' is load-bearing for the central generalization thesis, yet the manuscript provides no explicit description of the multi-composition sampling procedure, the element sets or stoichiometry ranges used in training episodes versus test, or the precise operationalization of 'unseen' (e.g., novel element combinations, larger atom counts, or merely held-out stoichiometries). Without these details, it is impossible to distinguish genuine OOD generalization from reduced overfitting within statistically similar chemical spaces.
- [§4] §4 (Experiments): The comparison to 'existing single-composition reinforcement-learning baselines' requires a clear statement of whether those baselines were also evaluated under the same multi-composition regime or retrained per formula; if the latter, the performance gap may be attributable to training protocol differences rather than the multi-composition scheme itself.
minor comments (2)
- [§3] Notation for the validity and energy reward functions should be introduced with explicit equations rather than prose descriptions to allow reproducibility.
- [Figures] Figure captions should include the exact number of independent runs and error bars used to generate the reported performance statistics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity of our manuscript regarding the multi-composition training and baseline comparisons. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Methods): The headline claim of order-of-magnitude gains on 'unseen test formulas' is load-bearing for the central generalization thesis, yet the manuscript provides no explicit description of the multi-composition sampling procedure, the element sets or stoichiometry ranges used in training episodes versus test, or the precise operationalization of 'unseen' (e.g., novel element combinations, larger atom counts, or merely held-out stoichiometries). Without these details, it is impossible to distinguish genuine OOD generalization from reduced overfitting within statistically similar chemical spaces.
Authors: We agree that these details are essential and were insufficiently described in the original submission. We have revised §3 to explicitly detail the multi-composition sampling procedure (including how compositions are sampled per episode), the element sets (C, H, O, N and extensions) and stoichiometry ranges used in training versus test, and the definition of 'unseen' as novel element combinations and larger atom counts outside the training distribution. This revision clarifies the OOD evaluation. revision: yes
-
Referee: [§4] §4 (Experiments): The comparison to 'existing single-composition reinforcement-learning baselines' requires a clear statement of whether those baselines were also evaluated under the same multi-composition regime or retrained per formula; if the latter, the performance gap may be attributable to training protocol differences rather than the multi-composition scheme itself.
Authors: We agree this distinction must be stated clearly. The baselines were retrained per formula, consistent with their single-composition design. Our method's advantage stems from training one agent across multiple compositions. We have revised §4 to explicitly describe the protocols for our agent and the baselines, and added discussion noting that the gap reflects the multi-composition scheme rather than protocol alone. revision: yes
Circularity Check
No circularity; empirical RL performance claim is self-contained
full rationale
The paper reports an empirical result: an RL agent trained online with external energy/validity rewards discovers more valid isomers on held-out formulas than single-composition baselines. No derivation chain, equations, or self-citations are presented that reduce the performance claim to fitted parameters or prior author work by construction. The multi-composition scheme is an experimental training protocol whose generalization is tested directly against baselines; it does not contain self-definitional, fitted-input, or uniqueness-imported steps. The result is therefore not circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning with energy and validity rewards can guide construction of stable 3D molecular isomers.
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ameya Daigavane, Song Kim, Mario Geiger, and Tess Smidt
URL https://openreview.net/ forum?id=Snqhqz4LdK. Ameya Daigavane, Song Kim, Mario Geiger, and Tess Smidt. Symphony: Symmetry-equivariant point-centered spherical harmonics for molecule generation.arXiv preprint arXiv:2311.16199,
-
[3]
Raul Ortega Ochoa, Tejs Vegge, and Jes Frellsen. Molminer: Transformer architecture for fragment- based autoregressive generation of molecular stories.arXiv preprint arXiv:2411.06608,
-
[4]
Daniel Flam-Shepherd, Alexander Zhigalin, and Alán Aspuru-Guzik. Scalable fragment-based 3d molecular design with reinforcement learning.arXiv preprint arXiv:2202.00658,
-
[5]
An empirical investigation of the challenges of real-world reinforcement learning
Gabriel Dulac-Arnold, Nir Levine, Daniel J Mankowitz, Jerry Li, Cosmin Paduraru, Sven Gowal, and Todd Hester. An empirical investigation of the challenges of real-world reinforcement learning. arXiv preprint arXiv:2003.11881,
-
[6]
Reproducibility of Benchmarked Deep Reinforcement Learning Tasks for Continuous Control
Riashat Islam, Peter Henderson, Maziar Gomrokchi, and Doina Precup. Reproducibility of bench- marked deep reinforcement learning tasks for continuous control.arXiv preprint arXiv:1708.04133,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
A systematic survey of chemical pre-trained models.arXiv preprint arXiv:2210.16484,
22 Jun Xia, Yanqiao Zhu, Yuanqi Du, and Stan Z Li. A systematic survey of chemical pre-trained models.arXiv preprint arXiv:2210.16484,
-
[8]
Cédric Colas, Olivier Sigaud, and Pierre-Yves Oudeyer. A hitchhiker’s guide to statistical comparisons of reinforcement learning algorithms.arXiv preprint arXiv:1904.06979,
-
[9]
Mars: Markov molecular sampling for multi-objective drug discovery.arXiv preprint arXiv:2103.10432,
Yutong Xie, Chence Shi, Hao Zhou, Yuwei Yang, Weinan Zhang, Yong Yu, and Lei Li. Mars: Markov molecular sampling for multi-objective drug discovery.arXiv preprint arXiv:2103.10432,
-
[10]
URL https://doi.org/10.1021/ci300415d
doi: 10.1021/ci300415d. URL https://doi.org/10.1021/ci300415d. PMID: 23088335. Raghunathan Ramakrishnan, Pavlo O Dral, Matthias Rupp, and O Anatole von Lilienfeld. Quantum chemistry structures and properties of 134 kilo molecules.Scientific Data, 1,
-
[11]
doi: 10.26434/chemrxiv-2022-v5p6m-v3. Conor F Hayes, Roxana R ˘adulescu, Eugenio Bargiacchi, Johan Källström, Matthew Macfarlane, Mathieu Reymond, Timothy Verstraeten, Luisa M Zintgraf, Richard Dazeley, Fredrik Heintz, et al. A practical guide to multi-objective reinforcement learning and planning: Cf hayes et al. Autonomous Agents and Multi-Agent Systems...
-
[12]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.