Revisiting Anthropomorphic Reflection Markers in Large Language Model Reasoning
Pith reviewed 2026-06-29 13:11 UTC · model grok-4.3
The pith
Suppressing anthropomorphic markers like 'wait' and 'hmm' does not harm and can improve LLM reasoning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
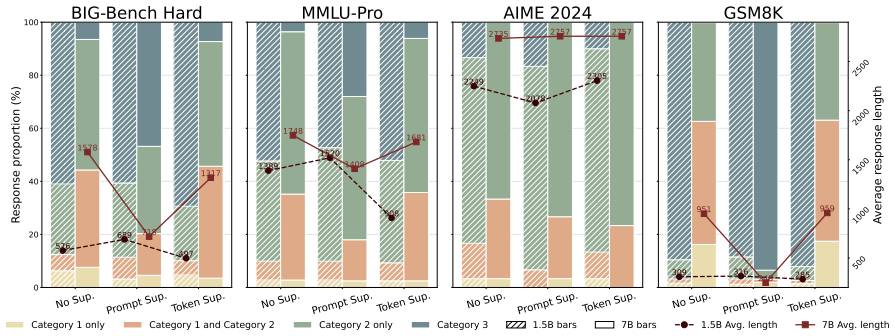
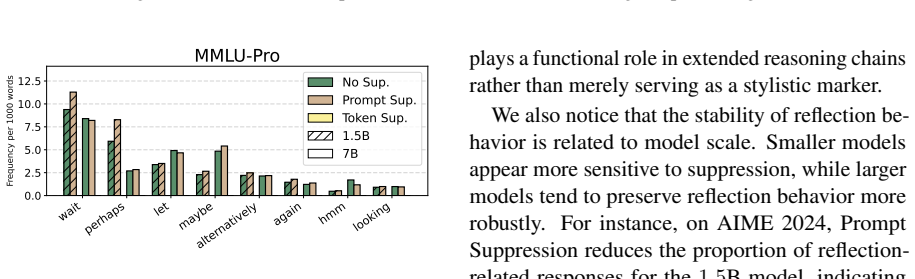
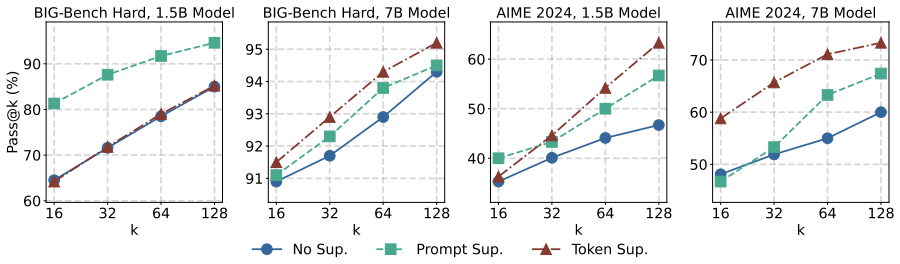
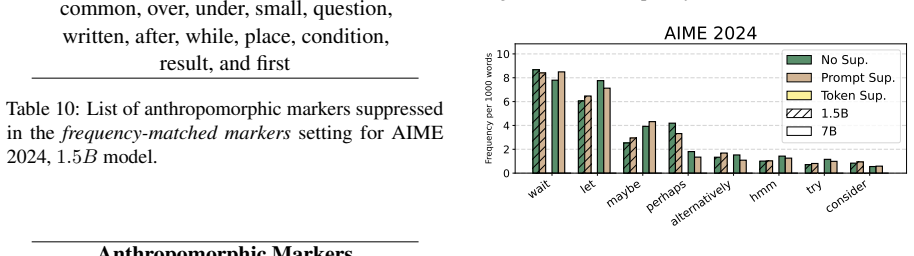
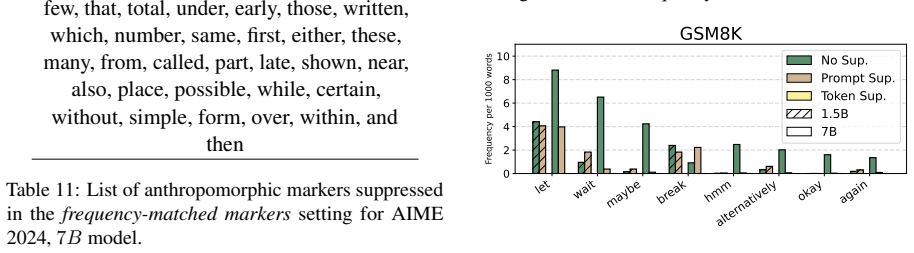
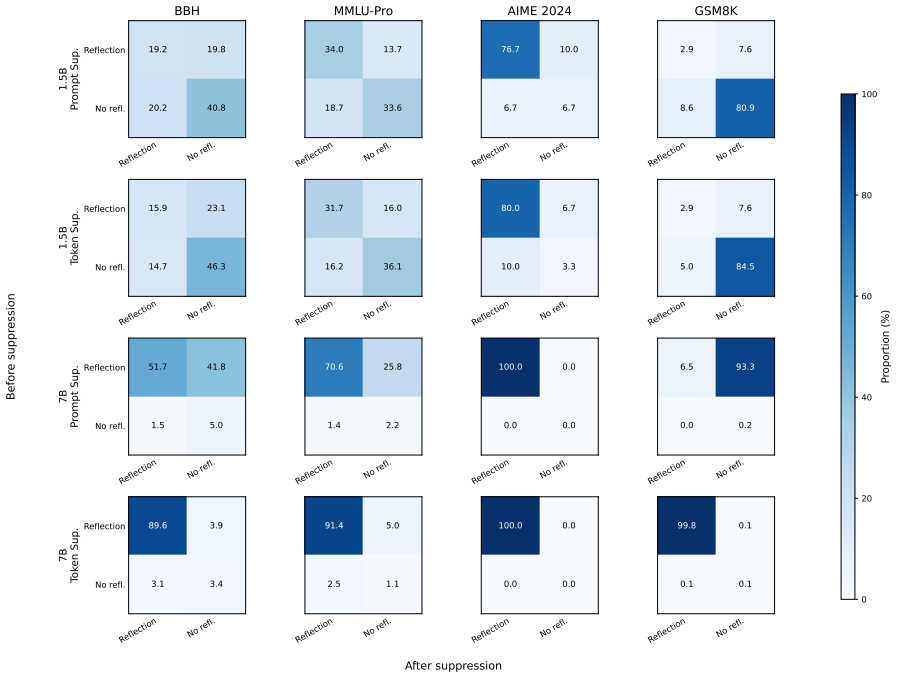
Anthropomorphic reflection markers are not uniformly necessary for reasoning performance: suppressing them can preserve or improve performance in several settings, especially under larger sampling budgets. Marker suppression does not necessarily remove reflection behavior, as models can still perform marker-free verification. These results suggest that anthropomorphic markers tend to be surface cues rather than reliable proxies for reflection itself.
What carries the argument
Prompt-level and token-level interventions that suppress anthropomorphic reflection markers to isolate their role in LLM reasoning.
If this is right
- Performance on reasoning tasks can be preserved or improved by removing anthropomorphic markers.
- Larger sampling budgets benefit more from marker suppression.
- Reflection continues without markers through alternative verification methods.
- Research should explore reasoning mechanisms independent of explicit marker patterns.
Where Pith is reading between the lines
- If markers are surface cues, training objectives that discourage them might yield more efficient models.
- The findings could apply to reducing overthinking in LLM outputs on complex tasks.
- Marker-free reflection suggests internal processes that could be studied through other output analysis methods.
Load-bearing premise
The prompt-level and token-level interventions remove only the target anthropomorphic markers without affecting other reasoning mechanisms.
What would settle it
Observing consistent performance degradation across all tested benchmarks and model scales when markers are suppressed would challenge the claim that suppression preserves or improves performance.
Figures





read the original abstract
Large Language Models (LLMs) often produce explicit reflective traces during complex reasoning, accompanied by anthropomorphic markers such as wait, hmm, and alternatively. Although these markers are commonly used as visible indicators of reflection, their mechanisms remain unclear, which leaves the risk of overthinking associated with redundant and repetitive reflection markers. In this work, we revisit anthropomorphic reflection markers, examining their necessity for reasoning and role in the reflection. We suppress these markers through prompt-level and token-level interventions, and analyze their effects on task performance across four benchmarks and two model scales. Our results show that anthropomorphic markers are not uniformly necessary for reasoning performance: suppressing them can preserve or improve performance in several settings, especially under larger sampling budgets. Meanwhile, marker suppression does not necessarily remove reflection behavior, as models can still perform marker-free verification. These suggest that anthropomorphic markers tend to be surface cues rather than reliable proxies for reflection itself, and motivate future research on reasoning mechanisms beyond explicit marker patterns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that anthropomorphic reflection markers (e.g., 'wait', 'hmm', 'alternatively') in LLMs are surface cues rather than necessary components of reasoning or reflection. Using prompt-level instructions and token-level logit penalties to suppress these markers, experiments across four benchmarks and two model scales show that performance can be preserved or improved (especially at larger sampling budgets) and that marker-free verification remains possible.
Significance. If the central empirical findings hold after addressing intervention controls, the work would usefully challenge reliance on visible anthropomorphic markers as proxies for reflection, encouraging study of internal mechanisms instead. The dual intervention approach (prompt and token) and use of public benchmarks are positive features that support potential reproducibility.
major comments (2)
- [§3] §3 (Intervention Design): The prompt-level and token-level suppression methods are presented as isolating the effect of marker removal, yet no ablations with neutral interventions (e.g., unrelated meta-instructions or non-marker logit penalties) or internal probes (e.g., hidden-state analysis of verification traces) are reported. This is load-bearing for the claim that performance changes reflect marker absence rather than other behavioral shifts induced by the interventions.
- [§4] §4 (Results): The abstract asserts performance preservation or gains across four benchmarks and two scales 'especially under larger sampling budgets,' but the manuscript provides no quantitative tables, per-benchmark accuracies, error bars, statistical tests, or sample exclusion criteria. Without these, the magnitude and reliability of the reported effects cannot be assessed.
minor comments (2)
- [Introduction] Introduction: The definition and enumeration of 'anthropomorphic reflection markers' would benefit from explicit examples drawn from model generations to clarify the exact token set targeted by interventions.
- [§3] The manuscript does not discuss potential side effects of the token-level penalty on output length, diversity, or generation time, which could indirectly affect benchmark scores.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (Intervention Design): The prompt-level and token-level suppression methods are presented as isolating the effect of marker removal, yet no ablations with neutral interventions (e.g., unrelated meta-instructions or non-marker logit penalties) or internal probes (e.g., hidden-state analysis of verification traces) are reported. This is load-bearing for the claim that performance changes reflect marker absence rather than other behavioral shifts induced by the interventions.
Authors: We acknowledge that neutral-intervention ablations would strengthen causal isolation. Our design relies on two orthogonal methods (prompt instructions and targeted logit penalties) that converge on similar performance outcomes, which we interpret as evidence that effects track marker suppression rather than generic behavioral shifts. The token-level method applies penalties only to the specific marker tokens without broad meta-instructions. We did not conduct unrelated controls or hidden-state probes. In revision we will add an explicit limitations paragraph discussing these gaps and noting that internal-mechanism analysis remains future work. revision: partial
-
Referee: [§4] §4 (Results): The abstract asserts performance preservation or gains across four benchmarks and two scales 'especially under larger sampling budgets,' but the manuscript provides no quantitative tables, per-benchmark accuracies, error bars, statistical tests, or sample exclusion criteria. Without these, the magnitude and reliability of the reported effects cannot be assessed.
Authors: The referee correctly notes the absence of detailed quantitative reporting. We will expand the results section in the revised manuscript to include full per-benchmark accuracy tables, error bars, statistical tests, and explicit sample-size and exclusion criteria so that effect sizes and reliability can be evaluated directly. revision: yes
Circularity Check
No circularity: empirical intervention study on public benchmarks
full rationale
The paper performs controlled experiments applying prompt-level instructions and token-level logit penalties to suppress specific anthropomorphic markers, then measures downstream accuracy on four standard benchmarks across two model scales. No equations, fitted parameters, or derivations are present; performance differences are reported as direct empirical outcomes rather than predictions derived from the interventions themselves. Claims about marker necessity rest on observable results under varying sampling budgets, not on self-referential definitions or self-citation chains. The work is self-contained against external benchmarks with no load-bearing self-citations or ansatzes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Yichao Fu, Junda Chen, Yonghao Zhuang, Zheyu Fu, Ion Stoica, and Hao Zhang. 2025. Reasoning without self-doubt: More efficient chain-of-thought through certainty probing. InICLR 2025 Workshop on Foun- dation Models in the Wild. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao So...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InFindings of the Association for Computational Linguistics: NAACL 2024, pages 3741–3753
When hindsight is not 20/20: Testing lim- its on reflective thinking in large language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 3741–3753. Associ- ation for Computational Linguistics. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: Nlg evaluation using gpt-4 with bet...
-
[3]
Reflexion: Language agents with verbal rein- forcement learning. InAdvances in Neural Informa- tion Processing Systems, volume 36. Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 oth- ers. 2025. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267. Charlie ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neu- ral Information Processing Systems, volume 36. Chenlong Wang, Yuanning Feng, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V
Wait, we don’t need to" wait"! removing thinking tokens improves reasoning efficiency.arXiv preprint arXiv:2506.08343, 3. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowd- hery, and Denny Zhou. 2023. Self-consistency im- proves chain of thought reasoning in language mod- els. InThe Eleventh International Conf...
-
[6]
Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600, 2025
Large language models are better reasoners with self-verification. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 2550–2575. Association for Computational Linguis- tics. Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. 2025. Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600. An Yang, Beic...
-
[7]
Which matches, so that’s correct
So that’s okay. . . . Which matches, so that’s correct. Figure 10: An example prompt used for external LLM judge (Part One). Prompt of the External LLM Judge (Part Two) These examples illustrate the pattern where the model performs reflection on intermediate parts of the reasoning before a final answer is derived. This shows that reflection is carried out...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.