A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
Pith reviewed 2026-06-29 12:04 UTC · model grok-4.3
The pith
Reversing benchmark construction from tool sequences to tasks doubles coverage and exposes saturation in agent evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
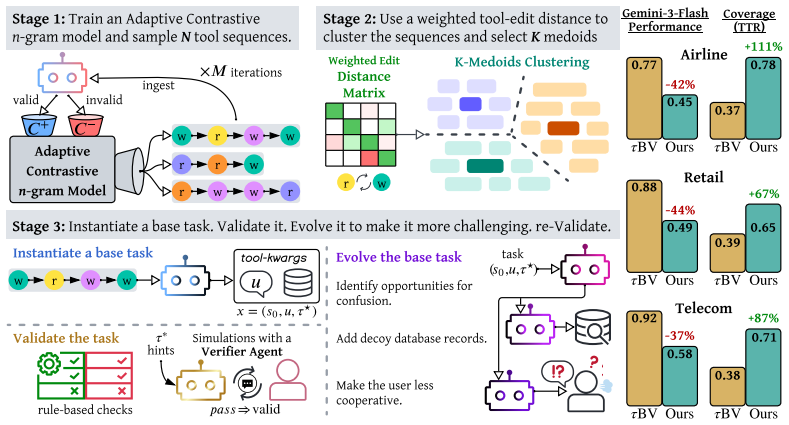
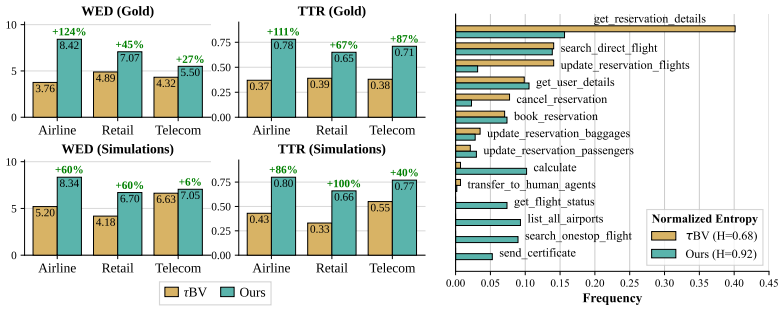
TASTE generates challenging tasks by sampling valid tool sequences with an Adaptive Contrastive n-gram model trained on LLM-judged validity signals, clustering representative sequences, instantiating them into complete benchmark tasks, and refining them through iterative difficulty evolution. Applied to the three domains of τ²-Bench, this creates τ^c-Bench where models nearly saturating the original benchmark suffer severe performance drops and where the tasks more than double the number of unique tool combinations agents must execute.
What carries the argument
Adaptive Contrastive n-gram model that samples valid tool sequences covering a vast range of combinations before tasks are built from them.
If this is right
- Models that nearly saturate τ²-Bench suffer severe performance drops on the new tasks.
- Generated tasks more than double the number of unique tool combinations agents must execute.
- High scores on existing benchmarks often reflect saturation rather than robust task-solving ability.
- Automating generation of difficult high-coverage benchmarks enables continuous scalable evaluation of future agents.
Where Pith is reading between the lines
- The reversal approach could be tested on agent tasks outside the three domains of τ²-Bench to check if coverage gains generalize.
- Similar sequence-first construction might address saturation in other AI evaluation settings that currently start from natural language scenarios.
- One could measure whether the clustering step preserves rare but important tool combinations that the n-gram model can produce.
Load-bearing premise
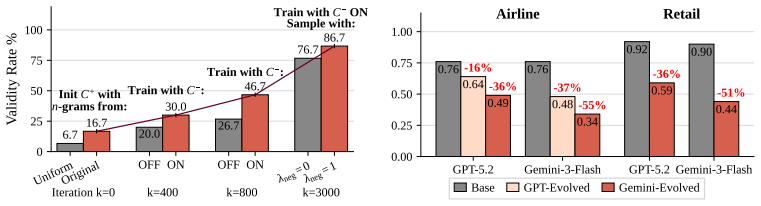
The Adaptive Contrastive n-gram model trained on LLM-judged validity signals produces valid tool sequences that cover a vast range of tool combinations without systematic bias or invalidity.
What would settle it
Human experts examining a random sample of the generated tool sequences and finding more than a small fraction invalid, or new models showing no performance drop on the resulting τ^c-Bench tasks.
Figures
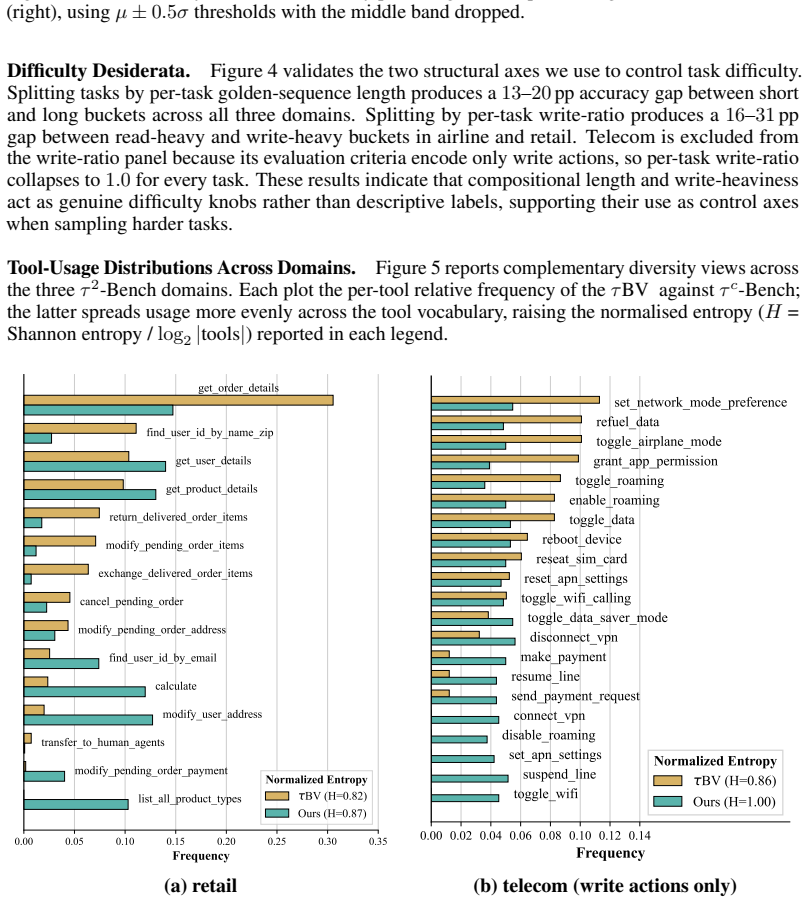




read the original abstract
As agent capabilities advance, existing benchmarks, such as $\tau^2$-Bench, are becoming increasingly saturated. Yet constructing new benchmark tasks remains complex, costly, and labor-intensive. Moreover, the standard approach, in which scenarios are first written in natural language and then mapped to tool sequences, captures only a narrow subset of the tool-use patterns agents exercise. In this paper, we address these problems by reversing the task construction process. We propose TASTE: Task Synthesis from Tool Sequence Evolution, an automatic method that generates challenging tasks with broader tool-use coverage. TASTE utilizes an Adaptive Contrastive $n$-gram model trained on LLM-judged validity signals. This enables sampling valid tool sequences that cover a vast range of tool combinations. TASTE then selects representative sequences from the pool via clustering, instantiates them into complete benchmark tasks, and refines them through iterative difficulty evolution. Using TASTE, we construct $\tau^c$-Bench, a challenging extension of the three domains of $\tau^2$-Bench. We evaluate $11$ agent/user LLM pairs and find that models nearly saturating $\tau^2$-Bench suffer severe performance drops on our tasks (e.g., Gemini-3-Flash falls from $0.82\!-\!0.94$ to $0.28\!-\!0.61$). Beyond increasing difficulty, our generated tasks more than double the number of unique tool combinations agents must execute. Our results suggest high scores on existing benchmarks often reflect saturation rather than robust task-solving ability. By automating the generation of difficult, high-coverage benchmarks, TASTE enables continuous, scalable evaluation of future agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TASTE (Task Synthesis from Tool Sequence Evolution), a method that reverses standard benchmark construction by first sampling valid tool sequences via an Adaptive Contrastive n-gram model trained on LLM-judged validity signals, clustering them, instantiating into tasks, and evolving difficulty. This produces τ^c-Bench as an extension of τ²-Bench across three domains. Evaluation on 11 agent/user LLM pairs shows models saturating τ²-Bench suffer large drops (e.g., Gemini-3-Flash from 0.82-0.94 to 0.28-0.61), while the new tasks more than double the number of unique tool combinations executed.
Significance. If the generated sequences prove valid and unbiased, the work would be significant for providing a scalable, automated route to high-coverage benchmarks that better distinguish saturation from robust agent capability. The reported performance degradation and doubled coverage supply concrete, falsifiable evidence supporting the saturation hypothesis, and the reversal of the construction pipeline (tool sequences first) is a clear methodological contribution.
major comments (3)
- [TASTE method (abstract and §3)] TASTE method (abstract and §3): The Adaptive Contrastive n-gram model is trained exclusively on LLM-judged validity signals, yet no protocol for collecting those signals, choice of judge LLM, inter-annotator agreement, or independent human validation is described. This directly undermines the central claim that sampled sequences are valid and cover a vast unbiased range of tool combinations.
- [Clustering and instantiation (§3.3)] Clustering and instantiation (§3.3): No criteria for clustering representative sequences, no validation of the n-gram model itself, and no statistical controls for bias in the resulting task pool are supplied. These omissions are load-bearing for the claim that τ^c-Bench genuinely doubles unique tool combinations without introducing malformed tasks.
- [Evaluation (§4)] Evaluation (§4): The reported performance drops (e.g., 0.28-0.61 range) are interpreted as evidence of increased difficulty, but without independent checks that the LLM-generated tasks are well-formed, it remains possible that drops partly reflect invalid or narrowly biased sequences rather than genuine capability gaps.
minor comments (2)
- [Abstract] Abstract: The specific LLM used for validity judgments and the exact domains of τ²-Bench are not named, reducing immediate clarity.
- [Notation] Notation: The superscripts in τ²-Bench and τ^c-Bench are introduced without an explicit definition paragraph, which could be added in §1 or §2.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas where additional methodological detail is needed to support the claims in our paper. We respond to each major comment below and commit to revisions that strengthen the description of TASTE without altering the core results.
read point-by-point responses
-
Referee: [TASTE method (abstract and §3)] TASTE method (abstract and §3): The Adaptive Contrastive n-gram model is trained exclusively on LLM-judged validity signals, yet no protocol for collecting those signals, choice of judge LLM, inter-annotator agreement, or independent human validation is described. This directly undermines the central claim that sampled sequences are valid and cover a vast unbiased range of tool combinations.
Authors: We agree that the manuscript should provide explicit details on the validity signal collection process. In the revised version we will expand §3 with a dedicated subsection describing the full protocol, including the judge LLM, prompting strategy, scale of signal collection, and any agreement metrics obtained. We will also report a small-scale independent human validation study on sampled sequences to corroborate the LLM judgments. revision: yes
-
Referee: [Clustering and instantiation (§3.3)] Clustering and instantiation (§3.3): No criteria for clustering representative sequences, no validation of the n-gram model itself, and no statistical controls for bias in the resulting task pool are supplied. These omissions are load-bearing for the claim that τ^c-Bench genuinely doubles unique tool combinations without introducing malformed tasks.
Authors: We concur that the clustering procedure and model validation require fuller specification. The revised manuscript will detail the clustering algorithm and selection criteria in §3.3, include validation metrics for the Adaptive Contrastive n-gram model, and add statistical analyses (e.g., coverage distributions and bias checks) demonstrating that the expanded task pool maintains validity while increasing unique tool combinations. revision: yes
-
Referee: [Evaluation (§4)] Evaluation (§4): The reported performance drops (e.g., 0.28-0.61 range) are interpreted as evidence of increased difficulty, but without independent checks that the LLM-generated tasks are well-formed, it remains possible that drops partly reflect invalid or narrowly biased sequences rather than genuine capability gaps.
Authors: We recognize that stronger evidence is needed to rule out malformed tasks as a partial cause of the observed drops. In the revision we will augment §4 with a human evaluation of a representative sample of generated tasks, reporting the proportion judged well-formed, to support the interpretation that performance degradation primarily reflects the increased coverage and difficulty rather than task invalidity. revision: yes
Circularity Check
No significant circularity; method is generative and externally grounded
full rationale
The paper presents TASTE as a generative pipeline that trains an Adaptive Contrastive n-gram model on LLM-judged validity signals, then clusters and instantiates sequences into tasks. No equations, predictions, or first-principles claims are shown to reduce by construction to the inputs (no self-definitional loops, no fitted parameters renamed as predictions, no load-bearing self-citations). The central claims about coverage and difficulty are evaluated via independent agent runs on the generated tasks, making the derivation self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- Adaptive Contrastive n-gram model parameters
axioms (1)
- domain assumption LLM judgments provide reliable validity signals for tool sequences
Reference graph
Works this paper leans on
-
[1]
Toolformer: Lan- guage models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Lan- guage models can teach themselves to use tools. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Syste...
2023
-
[2]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. In Amir Globersons, Lester Mackey, Danielle Belgrave, An- gela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Sy...
2024
-
[7]
Survey on Evaluation of LLM-based Agents
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar-Haim, Arman Cohan, and Michal Shmueli-Scheuer. Survey on evaluation of llm-based agents.CoRR, abs/2503.16416,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis. InThe Twelfth International Conference on Learning...
2024
-
[14]
Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (BFCL): from tool use to agentic evaluation of large language models. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, ed...
2025
-
[15]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2...
2024
-
[16]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=VTF8yNQM66
2024
-
[19]
Evaluation and benchmarking of LLM agents: A survey
Mahmoud Mohammadi, Yipeng Li, Jane Lo, and Wendy Yip. Evaluation and benchmarking of LLM agents: A survey. In Luiza Antonie, Jian Pei, Xiaohui Yu, Flavio Chierichetti, Hady W. Lauw, Yizhou Sun, and Srinivasan Parthasarathy, editors,Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, V .2, KDD 2025, Toronto ON, Canada, Aug...
-
[20]
A simple and fast algorithm for k-medoids clustering
Hae-Sang Park and Chi-Hyuck Jun. A simple and fast algorithm for k-medoids clustering. Expert Syst. Appl., 36(2):3336–3341, 2009. doi: 10.1016/J.ESW A.2008.01.039. URL https: //doi.org/10.1016/j.eswa.2008.01.039
-
[21]
Thomas McCoy, Paul Smolensky, Tal Linzen, Jianfeng Gao, and Asli Celikyilmaz
R. Thomas McCoy, Paul Smolensky, Tal Linzen, Jianfeng Gao, and Asli Celikyilmaz. How much do language models copy from their training data? evaluating linguistic novelty in text generation using RA VEN.Trans. Assoc. Comput. Linguistics, 11:652–670, 2023. doi: 10.1162/TACL\_A\_00567. URLhttps://doi.org/10.1162/tacl_a_00567
work page internal anchor Pith review doi:10.1162/tacl 2023
-
[22]
Finding groups in data.Hoboken: Wiley Online Library, 1: 371, 1990
Peter J Rousseeuw and L Kaufman. Finding groups in data.Hoboken: Wiley Online Library, 1: 371, 1990
1990
-
[23]
Api-bank: A comprehensive benchmark for tool-augmented llms
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api-bank: A comprehensive benchmark for tool-augmented llms. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023,...
-
[24]
Toolqa: A dataset for LLM question answering with external tools
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. Toolqa: A dataset for LLM question answering with external tools. In Alice Oh, Tristan Nau- mann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Ad- vances in Neural Information Processing Systems 36: Annual Conference on Neural In- formation Processing Systems 2023, Neu...
2023
-
[26]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, and Ruoming Pang. Toolsandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational L...
-
[27]
Agentic CLEAR: Automating Multi-Level Evaluation of LLM Agents
Asaf Yehudai, Lilach Eden, and Michal Shmueli-Scheuer. Agentic clear: Automating multi-level evaluation of llm agents, 2026. URLhttps://arxiv.org/abs/2605.22608
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated in- structions. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors,Proceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: ...
-
[29]
Unnatural instructions: Tuning language models with (almost) no human labor
Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. Unnatural instructions: Tuning language models with (almost) no human labor. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for 12 Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 20...
-
[30]
Wizardlm: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions. InThe Twelfth International Conference on Learning Rep- resentations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openrevie...
2024
-
[32]
N., Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, and Caiming Xiong
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh R. N., Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, and Caiming Xiong. Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets. In Amir Globersons, Lester M...
2024
-
[38]
Ryoo, Chien-Sheng Wu, Shelby Heinecke, Huan Wang, Silvio Savarese, Caiming Xiong, and Juan Carlos Niebles
Thai Quoc Hoang, Kung-Hsiang Huang, Shirley Kokane, Jianguo Zhang, Zuxin Liu, Ming Zhu, Jake Grigsby, Tian Lan, Michael S. Ryoo, Chien-Sheng Wu, Shelby Heinecke, Huan Wang, Silvio Savarese, Caiming Xiong, and Juan Carlos Niebles. LAM SIMULATOR: advancing data generation for large action model training via online exploration and trajectory feedback. In Wan...
2025
-
[41]
William Merrill, Noah A. Smith, and Yanai Elazar. Evaluating n-gram novelty of language models using rusty-dawg. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pages 14459–14473. Association for Computat...
-
[43]
Evaluating the evaluation of diversity in natural language generation
Guy Tevet and Jonathan Berant. Evaluating the evaluation of diversity in natural language generation. In Paola Merlo, Jörg Tiedemann, and Reut Tsarfaty, editors,Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021, pages 326–346. Association for Com...
-
[44]
URL https://doi.org/10.48550/arXiv.2501
Yuanzhe Shen, Zisu Huang, Zhengyuan Wang, Muzhao Tian, Zhengkang Guo, Chenyang Zhang, Shuaiyu Zhou, Zengjie Hu, Dailin Li, Jingwen Xu, Kaimin Wang, Wenhao Liu, Tianlong Li, Fengpeng Yue, Feng Hong, Cao Liu, and Ke Zeng. Trip-bench: A benchmark for long-horizon interactive agents in real-world scenarios.CoRR, abs/2602.01675, 2026. doi: 10.48550/ARXIV . 260...
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[45]
Filter unsuccessful runs (reward= 0.0)
Run pool.For every task i, gather the union of all simulation runs, pooled across agent, user simulator, and trialk. Filter unsuccessful runs (reward= 0.0)
-
[46]
Sequence extraction.For each run we read the agent’s tool calls in turn order and concate- nate their identifiers into one ordered tool sequence (¯σ)
-
[47]
The intuition is that the shortest successful trajectory is the cleanest evidence of a working solution path
Per-task pick.If more then a single candidate exist, we pick the candidate ofminimal length. The intuition is that the shortest successful trajectory is the cleanest evidence of a working solution path
-
[48]
This keeps the per-cell sequence count equal to the cell’s task count and avoids selection bias against hard tasks
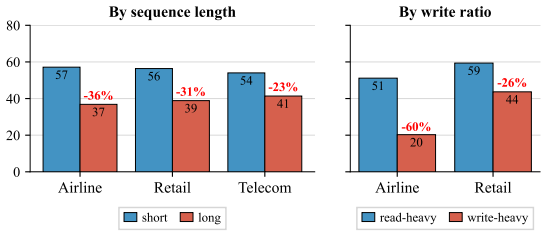
Gold fallback.If no candidate exists for task i — we use the task’s gold tool sequence ( ¯σ⋆). This keeps the per-cell sequence count equal to the cell’s task count and avoids selection bias against hard tasks. 15 Airline Retail Telecom 0 20 40 60 80 57 56 54 37 39 41-36% -31% -23% By sequence length short long Airline Retail 51 59 20 44 -60% -26% By writ...
-
[49]
action hints
(LLM)Policy coherence review. An LLM reviews the task instructions against the policy (Box D.4). 6.(Simulation)Verifier agent. Described below. Verifier agent.The verifier agent of Section 3.3 is built on τ 2-Bench’sLLMGTAgent workflow, which primes an LLM with the full list of gold tool calls (“action hints”) before running the task in τ 2-Bench’s standa...
-
[50]
A careful agent catches these by looking things up in the DB
DB-grounded misdirection.The user leads the agent towards plausible but wrong argument values. A careful agent catches these by looking things up in the DB. e.g., Decoy entity - where a similar-but-wrong entity exists in the DB that plausibly matches the user’s vague description, with subtle disqualifier
-
[51]
e.g., Eligibility Pressure - where a user demands an action that policy forbids, such as ineligible refund
Policy Enforcement.The user pushes the agent toward actions that policy forbids, or beyond what the task requires. e.g., Eligibility Pressure - where a user demands an action that policy forbids, such as ineligible refund
-
[52]
e.g., Information withholding
Conversational adversity.The user controls the flow of information to stress-test the agent’s patience and robustness. e.g., Information withholding. Task evolution: environment perturbation.A second LLM call materializes the designed tech- niques into concrete database records, which are merged intos 0 additively. Task evolution: scenario rewriting.A thi...
2025
-
[53]
Once they provide the options, choose HAT500 and HAT600, confirm the change to economy class, and authorize payment for any difference using your credit card (credit_card_1111111)
Specifically ask the agent to search for one-stop flights via Chicago for that day. Once they provide the options, choose HAT500 and HAT600, confirm the change to economy class, and authorize payment for any difference using your credit card (credit_card_1111111). After that is confirmed, ask the agent for a list of all airports the airline serves for you...
2024
-
[54]
Start by providing your email to authenticate
-
[55]
Ask for your current profile details and then update your default address to 202 Oak St, Seattle, WA 98101, USA
-
[56]
Inquire about the status of order #W1111111
-
[57]
You want to change the payment method for order #W1111111 to your gift card, but first, you need to see your saved payment methods to get the gift card ID
-
[58]
Ask for a general list of all product categories
Before finalizing the payment change, express interest in the store's products. Ask for a general list of all product categories
-
[59]
Ask for specific details on the 'Ultra Headphones' (Product ID: 1234567890)
-
[60]
Now, confirm you want to switch the payment for #W1111111 to your gift card (gift_card_9998887)
-
[61]
Next, cancel order #W2222222 because you ordered it by mistake
-
[62]
Ask to see the list of product categories again to make sure you didn't miss anything
-
[63]
Ask for the product category list one more time, claiming you accidentally closed the previous one
-
[64]
Ask the agent to calculate how much it would cost to buy 3 items priced at $45.50 each
-
[65]
Ask to see your profile details again to verify the address change
-
[66]
Check the details of order #W1111111 one last time to ensure the payment update was successful
-
[67]
Ask the agent to update your default address one more time to include 'Apt 4B' at the same 202 Oak St location
Realize you omitted the apartment number in your address. Ask the agent to update your default address one more time to include 'Apt 4B' at the same 202 Oak St location. Wait for the agent to confirm completion of each action before requesting the next one or changing your mind. EVOLVED TASK KNOWN INFO You are Alice Vance. Your email is alice.v@example.co...
-
[68]
First, report the symptom to the agent
-
[69]
If the agent suggests a software-level fix like toggling Airplane Mode, follow their instructions
-
[70]
If the service still doesn't work after that, ask the agent to check if there is anything wrong with your account or line
-
[71]
Ask the agent to send you the payment request link
If the agent identifies an overdue bill (B990123) as the reason for a service suspension, express surprise but agree to pay it immediately. Ask the agent to send you the payment request link
-
[72]
Ask the agent if you should try taking it out and putting it back in
Once the agent confirms they have sent the payment request, mention that you also dropped your phone earlier today and are worried the SIM card might have shifted. Ask the agent if you should try taking it out and putting it back in
-
[73]
EVOLVED TASK KNOWN INFO You are Ido Levy
Wait for the agent to confirm completion of each action before requesting the next one. EVOLVED TASK KNOWN INFO You are Ido Levy. Your phone number is 555-432-1098. TASK INSTRUCTIONS Start by tersely reporting 'No Service' and demanding a fix, but withhold your phone number or account ID until explicitly asked. When the agent reviews your account, incorre...
-
[74]
Every action name exists in the tool spec
-
[75]
Sequence is non-empty
-
[76]
No action repeats 3+ times in a row with no intervening action (degenerate)
-
[77]
‘transfer_to_human_agents‘) must be the LAST action; nothing follows it
A handoff/transfer action (e.g. ‘transfer_to_human_agents‘) must be the LAST action; nothing follows it. ### Phase B -- Logical Flow (apply via the policy/tool spec to identify what counts as identification, lookup, write, diagnostic, corrective)
-
[78]
‘find_user_id_by_*‘, ‘get_customer_by_*‘), if present, must come before any action that depends on knowing who the customer is
Identification (e.g. ‘find_user_id_by_*‘, ‘get_customer_by_*‘), if present, must come before any action that depends on knowing who the customer is. Sequences may also omit identification (sub-task sequences -- identification assumed external)
-
[79]
Each mutated entity needs its own preceding READ; multiple writes on the same entity may share one
Read-before-write on existing entities: a WRITE that mutates an existing entity needs a prior READ of that entity, IF identification is present AND the policy requires verification before mutation. Each mutated entity needs its own preceding READ; multiple writes on the same entity may share one. Sub-task sequences without identification waive this
-
[80]
send/issue
Causal ordering: if A produces an ID/state that B consumes, A must precede B. If A is "send/issue" and B is the matching "check/respond/pay", A must precede B
-
[81]
Diagnostic-before-corrective: when the domain has both, a corrective WRITE without any preceding diagnostic READ is suspect (unless purely account-management)
-
[82]
same READ before/after a corrective WRITE to verify)
Repetition is valid only if each call targets a different entity or serves a distinct purpose (e.g. same READ before/after a corrective WRITE to verify)
-
[83]
### Phase C -- Benchmark Viability
No logical contradictions: when the policy says an action transitions an entity into a status that forbids further operations of a given kind, subsequent actions of that kind on the same entity are invalid. ### Phase C -- Benchmark Viability
-
[84]
Each sub-sequence must independently satisfy A and B
Multi-intent decomposition: a sequence may concatenate sub-sequences (one per user intent). Each sub-sequence must independently satisfy A and B. A fresh identification or top-level READ mid-sequence often signals a new intent, not a duplicate
-
[85]
Edge cases are valuable; uncommon is fine
Scenario constructibility: a coherent, realistic interaction must exist that naturally yields these actions in this order. Edge cases are valuable; uncommon is fine
-
[86]
Sequences leading the agent to refuse a request are still valid (they represent the actions taken before the decision)
Policy plausibility: at least one DB configuration must exist where every action is policy-allowed. Sequences leading the agent to refuse a request are still valid (they represent the actions taken before the decision)
-
[87]
analysis
Dataset utility: reject only when the sequence is trivially degenerate (same GENERIC repeated with no purpose), models no recognizable intent, or is too artificial to reflect any real interaction. ## Reference patterns (1 per domain) VALID: - Airline -- lookup then cancel: ‘[get_reservation_details, cancel_reservation]‘. - Retail -- auth + lookup + modify...
-
[88]
Describe the SYMPTOM (not the technical cause) when the sequence is diagnostic/troubleshooting
**reason_for_call** -- the user’s high-level request. Describe the SYMPTOM (not the technical cause) when the sequence is diagnostic/troubleshooting. For policy-dependent actions, include a specific policy-compliant reason
-
[89]
Use the actual generated IDs for the domain’s entities
**known_info** -- info the user knows. Use the actual generated IDs for the domain’s entities. Provide enough for the agent to retrieve the user’s record (email/phone/name+DOB depending on what the lookup tools accept)
-
[90]
- In dual-actor domains, also:
**task_instructions** -- behavioural directives. MUST include verbatim: - "Wait for the agent to confirm completion of each action before requesting the next one or changing your mind. CRITICAL: Do NOT end the conversation in the same message where you confirm or agree to an action. After you confirm an action, you MUST wait for the agent’s response confi...
-
[91]
For each action, identify the user statement/behaviour that requires it at this position
-
[92]
If two adjacent actions could be swapped, revise
-
[93]
IDs are consistent across ‘known_info‘ and arguments
-
[94]
Policy-dependent actions: required condition is established and a specific reason is in the user’s text
-
[95]
User intent matches what the actions do
-
[96]
(Dual-actor only) Each action’s ‘requestor‘ matches the tool spec actor; user actions have ‘{{}}‘ arguments unless the spec defines parameters. 28
-
[97]
Argument audit: every argument key exists in the spec; enum values are verbatim
-
[98]
System limits respected; dynamic-pool IDs used verbatim where applicable
-
[99]
requestor
(‘calculate‘ only) expressions have spaces around operators. ## Context - Domain: {domain} - Policy: {policy} - Tool Spec: {tool_spec} - Example task: {example_task} - Action sequence to realize, with placeholders for arguments: {evaluation_criteria} ## Output (JSON only -- no markdown, no explanation) For domains where every tool is agent-side, omit ‘req...
-
[100]
Active" before suspend
**Status / state compatibility.** Each entity’s status must satisfy the precondition of every action targeting it (e.g. cancellable-class status before a cancel; "Active" before suspend; "Overdue" before a payment request; the OPPOSITE state before a toggle). The INITIAL DB satisfies the precondition of the FIRST action; later transitions are produced by ...
-
[101]
**Referential integrity.** Every cross-reference resolves: action-argument IDs exist in the right collection (or are runtime-created -- see rule 7); "owns" arrays (‘user.reservations‘, ‘user.orders‘, ‘customer.line_ids‘, ‘customer.bill_ids‘) match the corresponding back-references; nested references (‘reservation.user_id‘, ‘bill.customer_id‘, ‘line.plan_i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.