Not All Uncertainty Is Equal: How Uncertainty Granularity Shapes Human Verification in LLM-Assisted Decision Making
Pith reviewed 2026-06-29 09:57 UTC · model grok-4.3
The pith
Uncertainty shown at the token level increases agreement with LLM answers while relation-level uncertainty reduces external verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
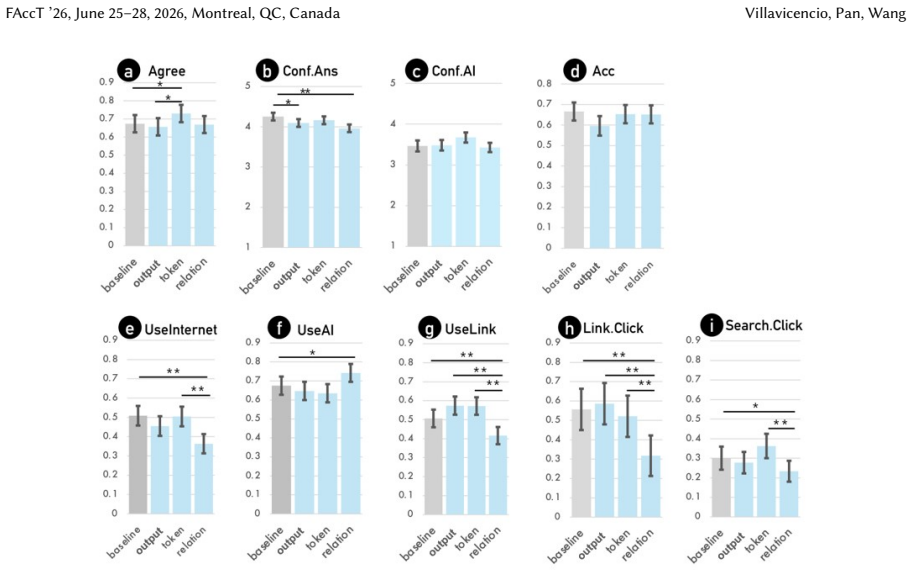
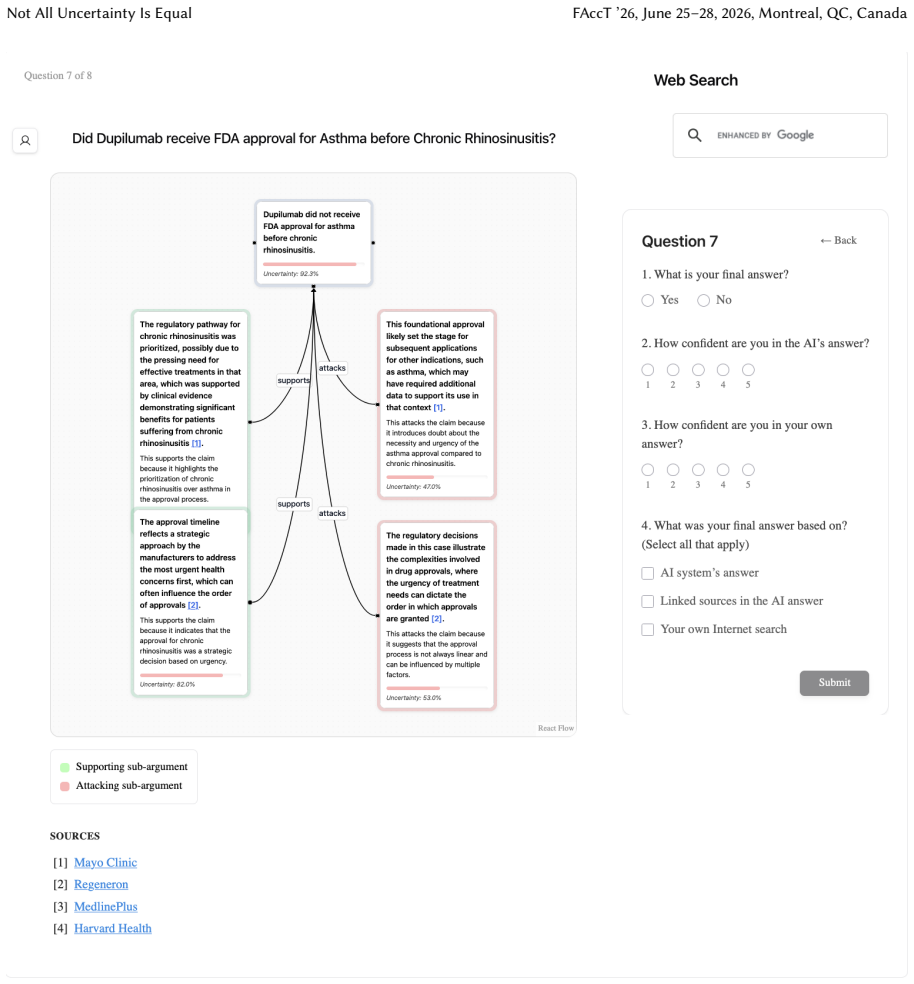
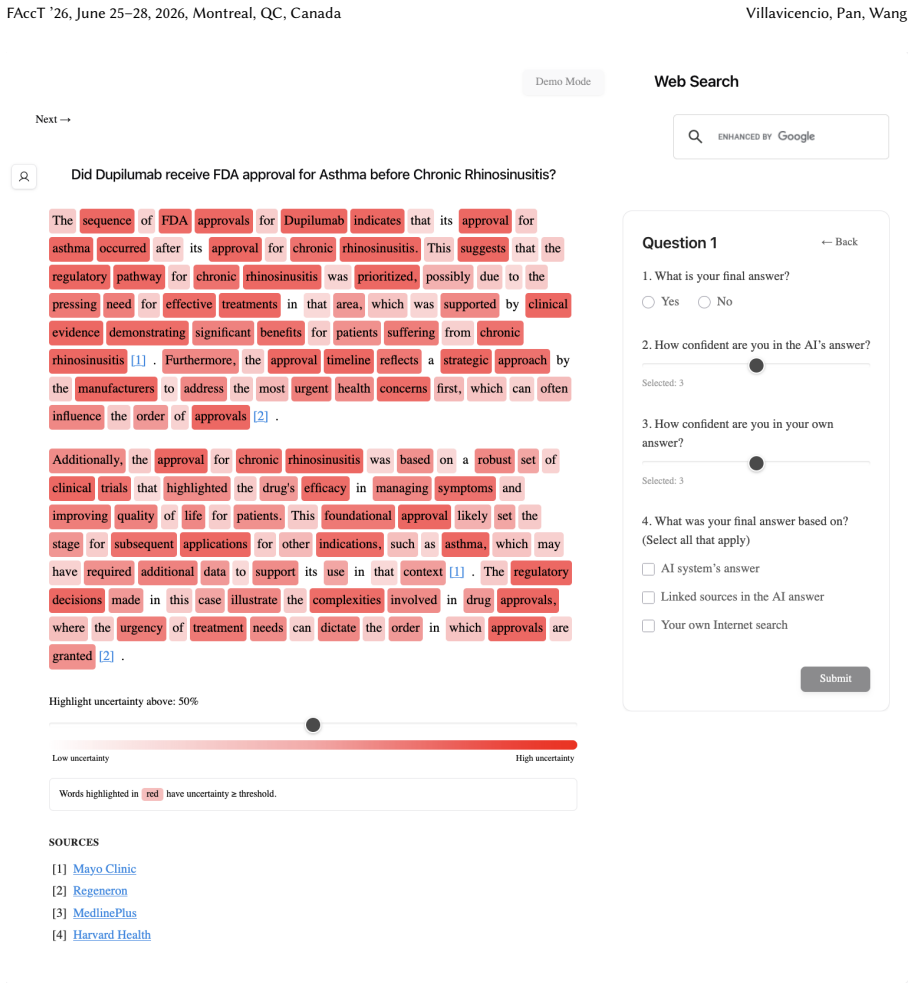
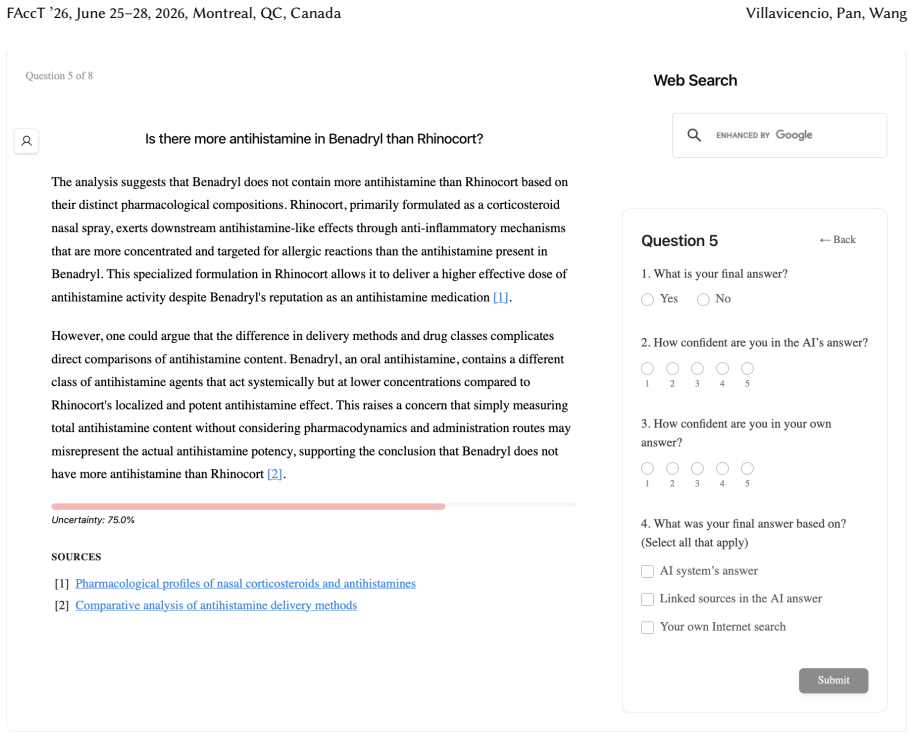
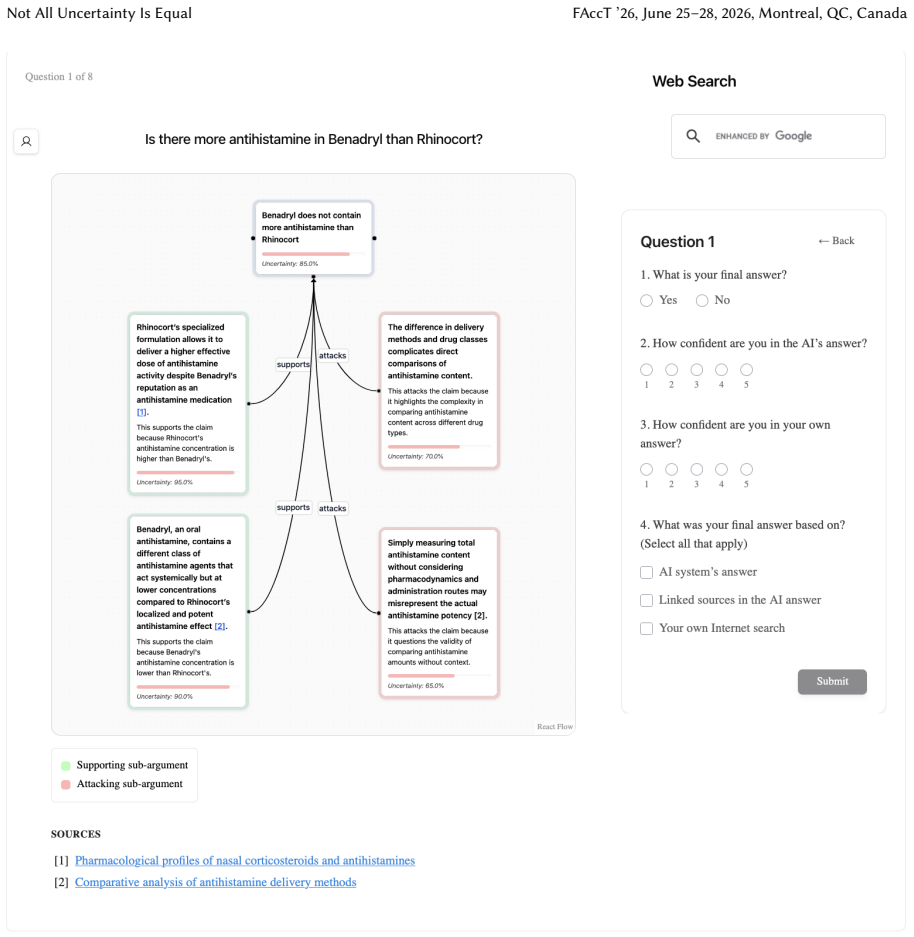
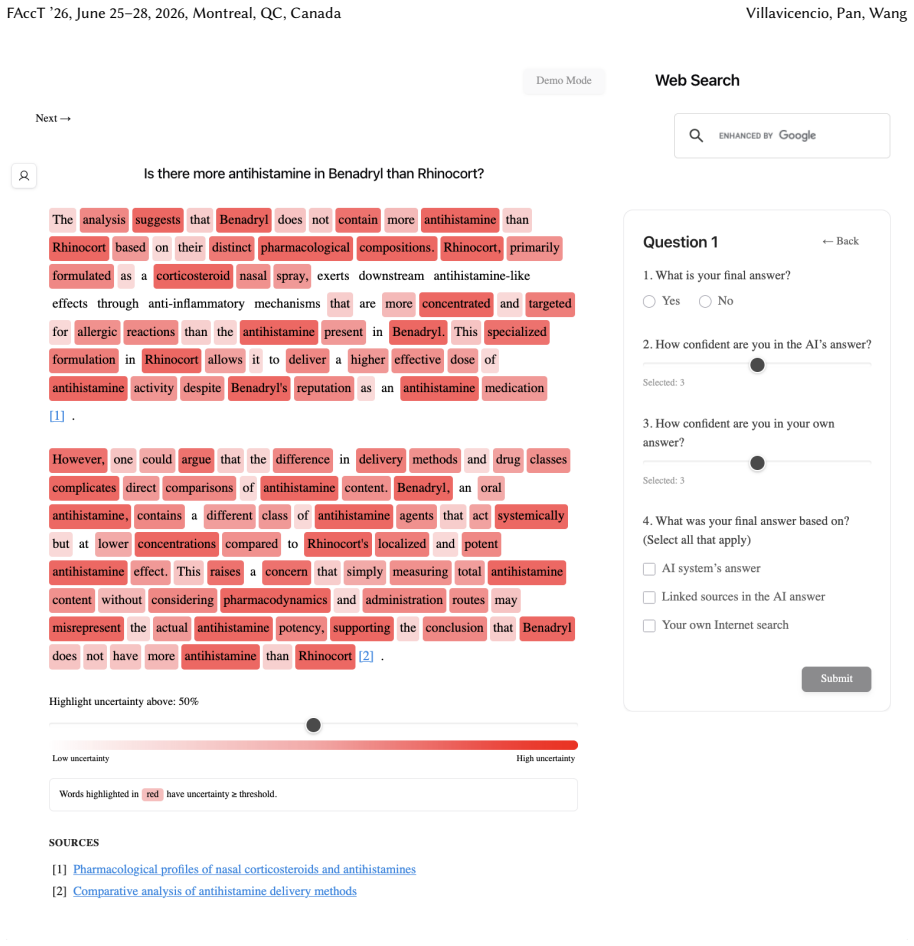
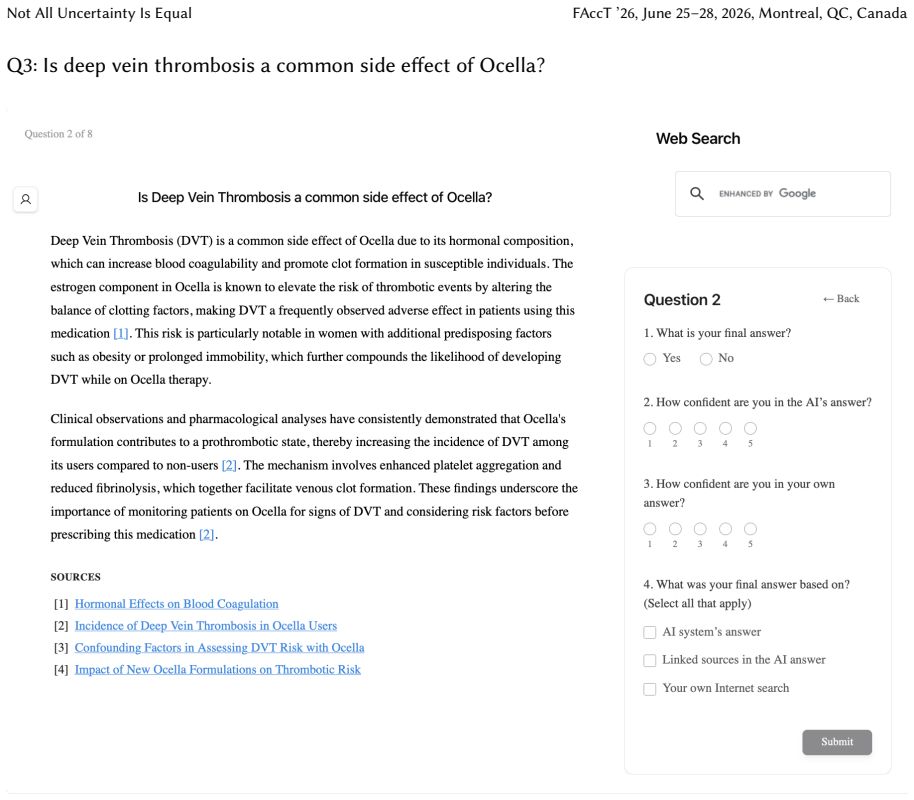
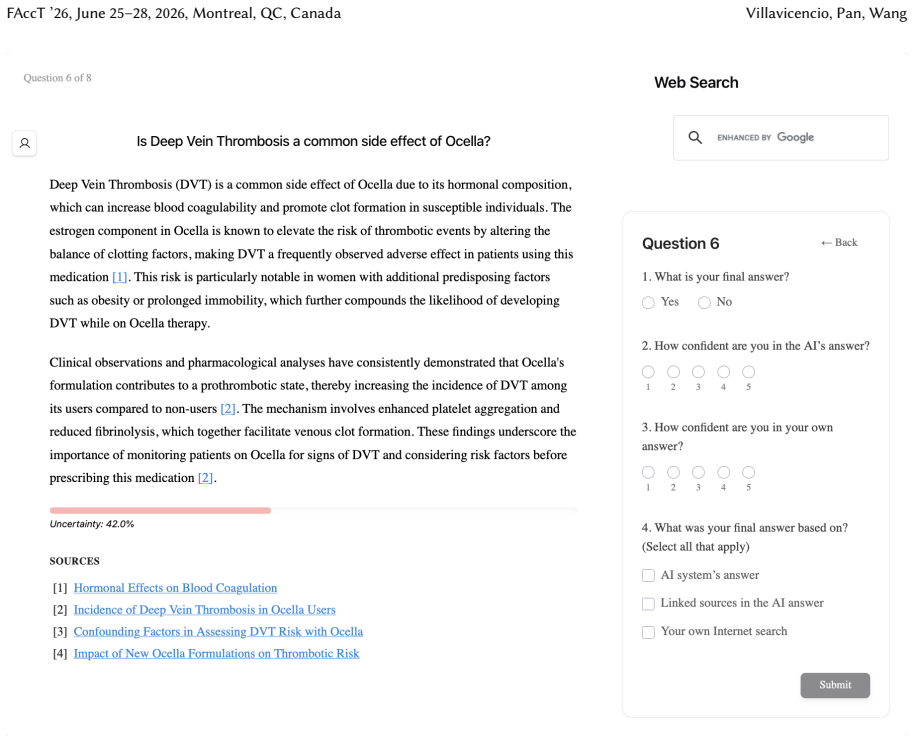
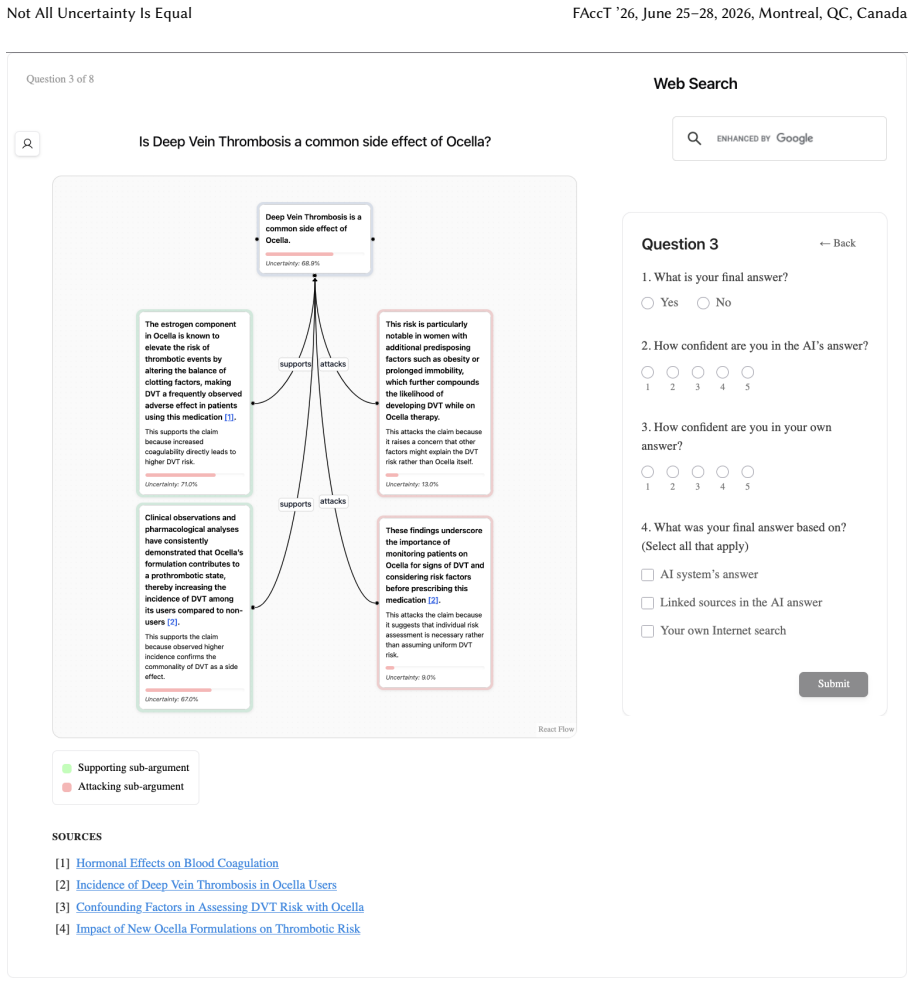
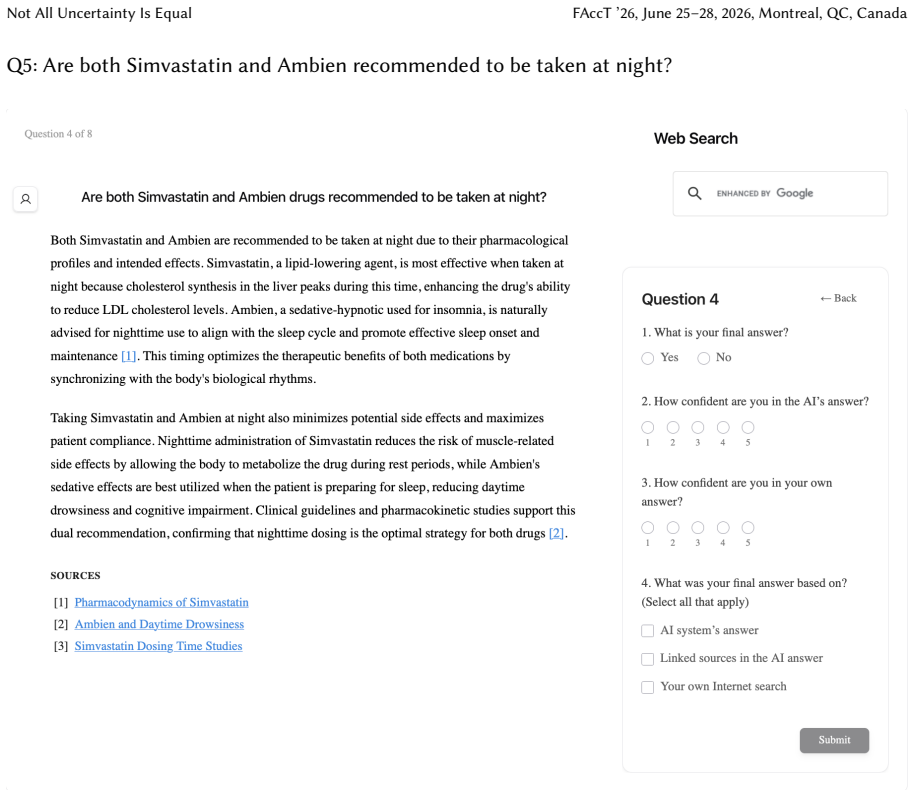
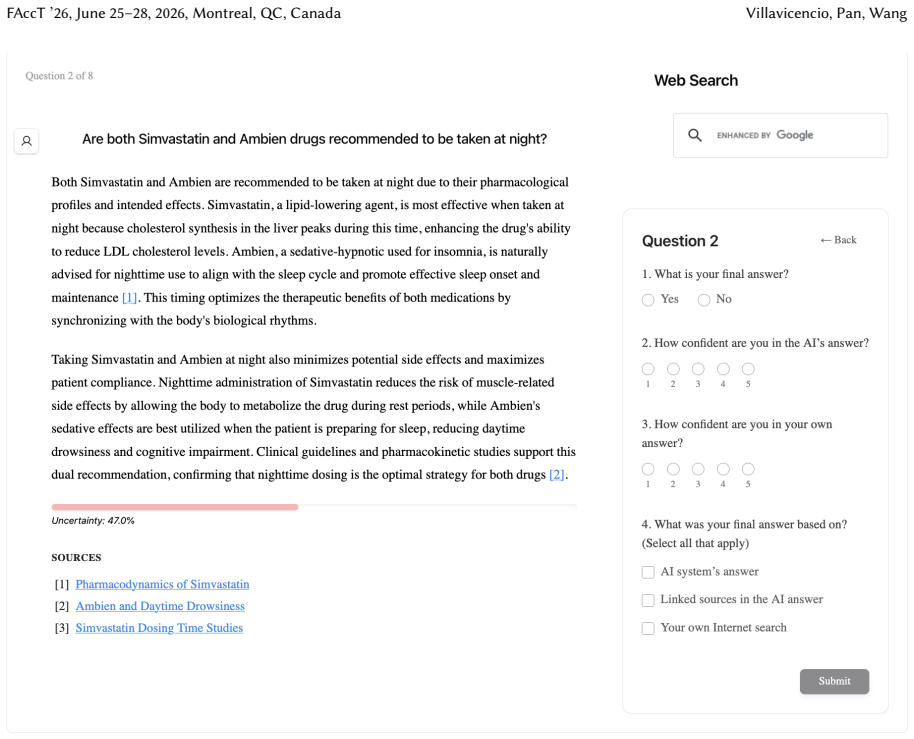
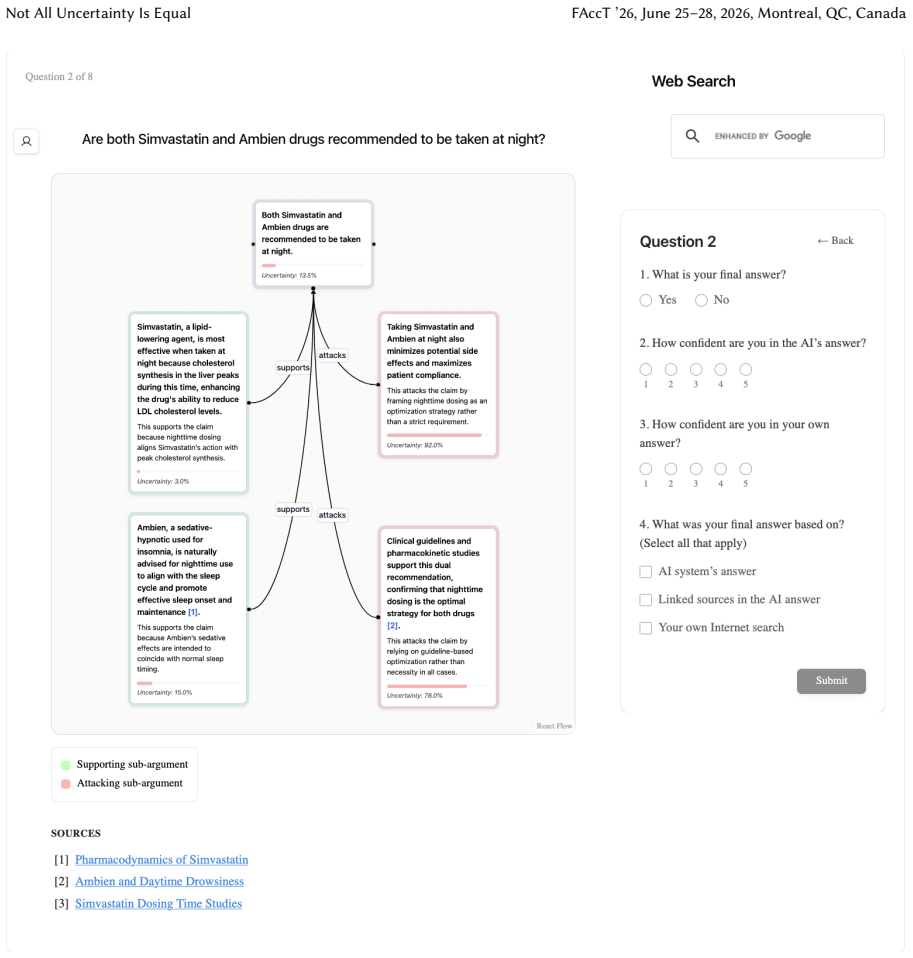
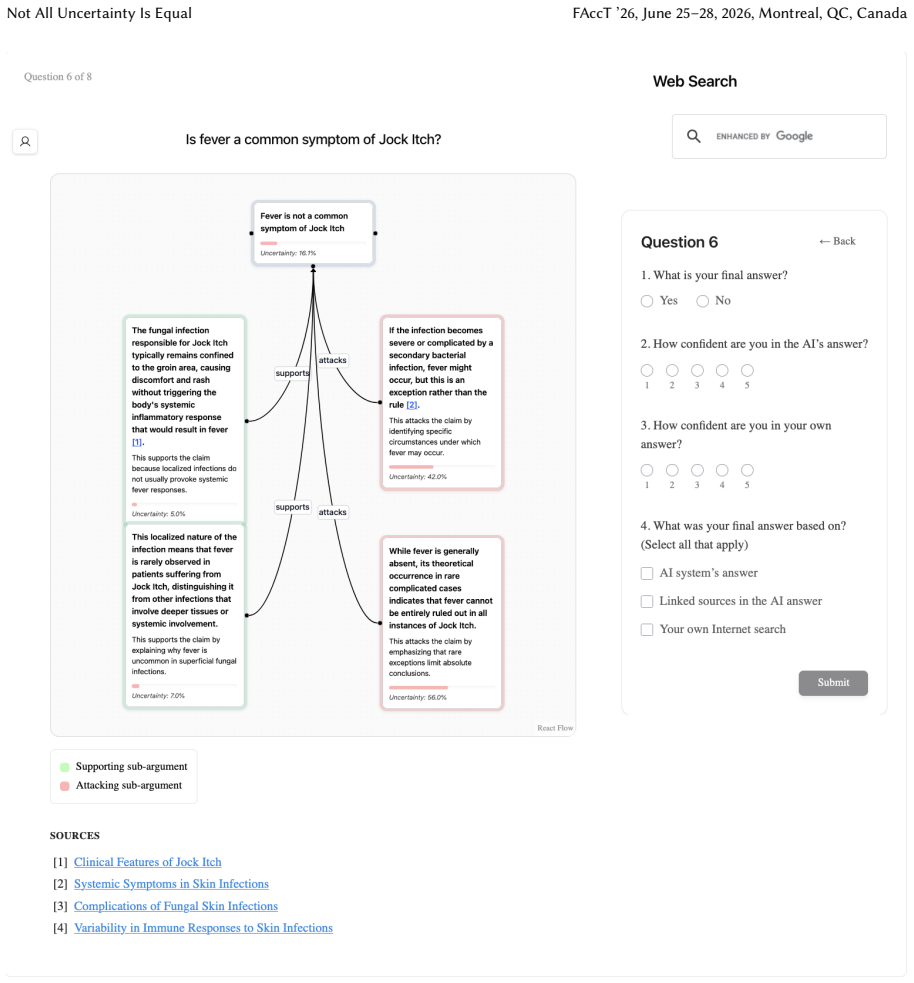
Token-level uncertainty increased users' agreement with the AI; output- and relation-level uncertainty did not increase agreement but reduced users' confidence in their own answers; relation-level uncertainty also reduced external verification behaviors such as internet searches and URL checks.
What carries the argument
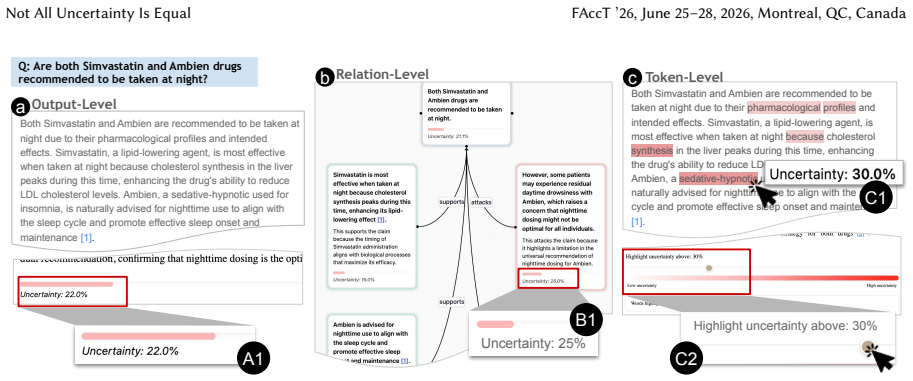
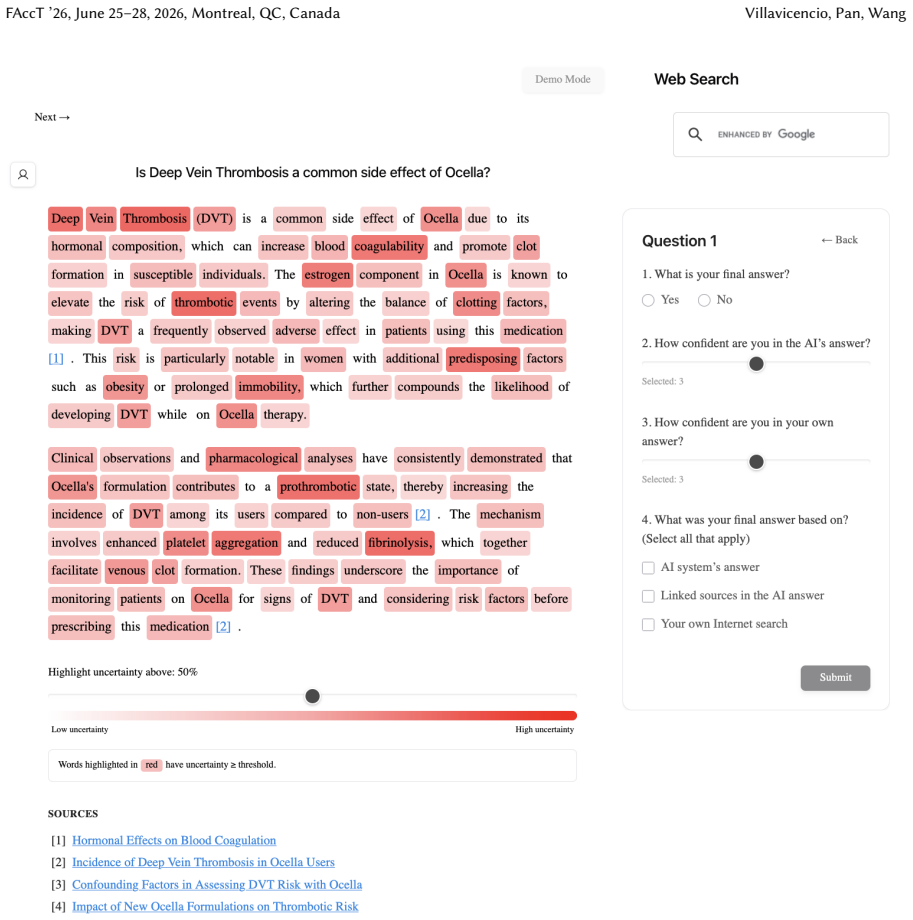
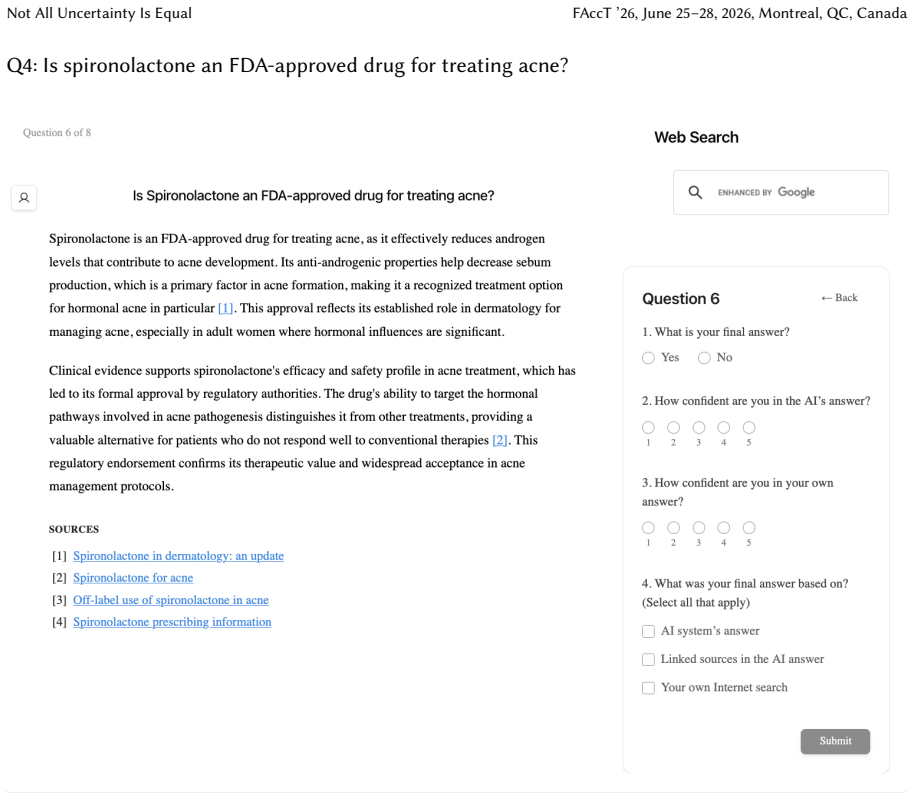
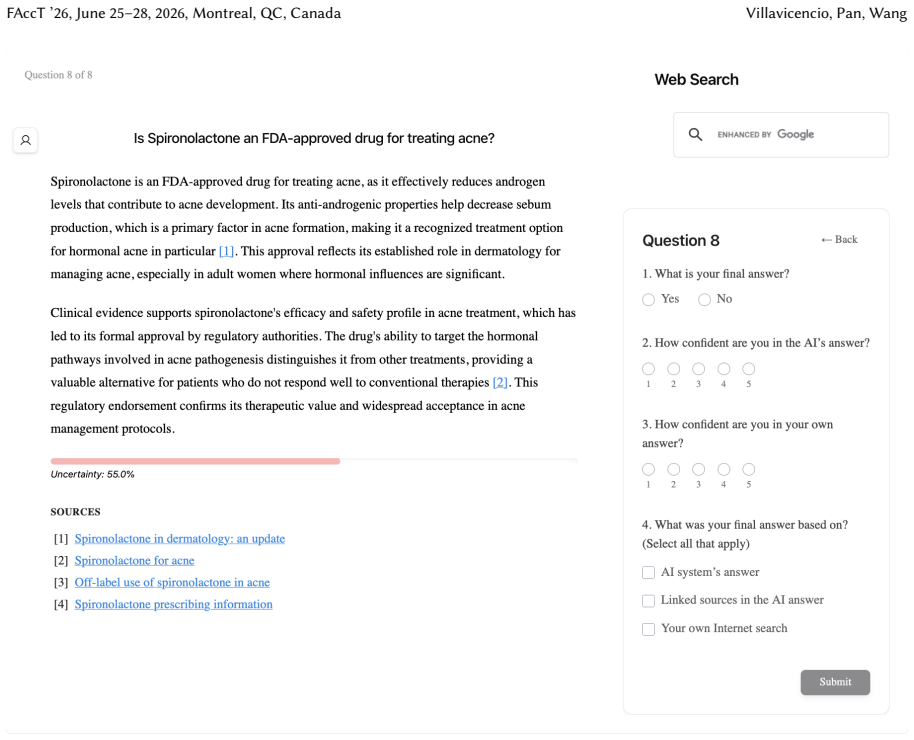
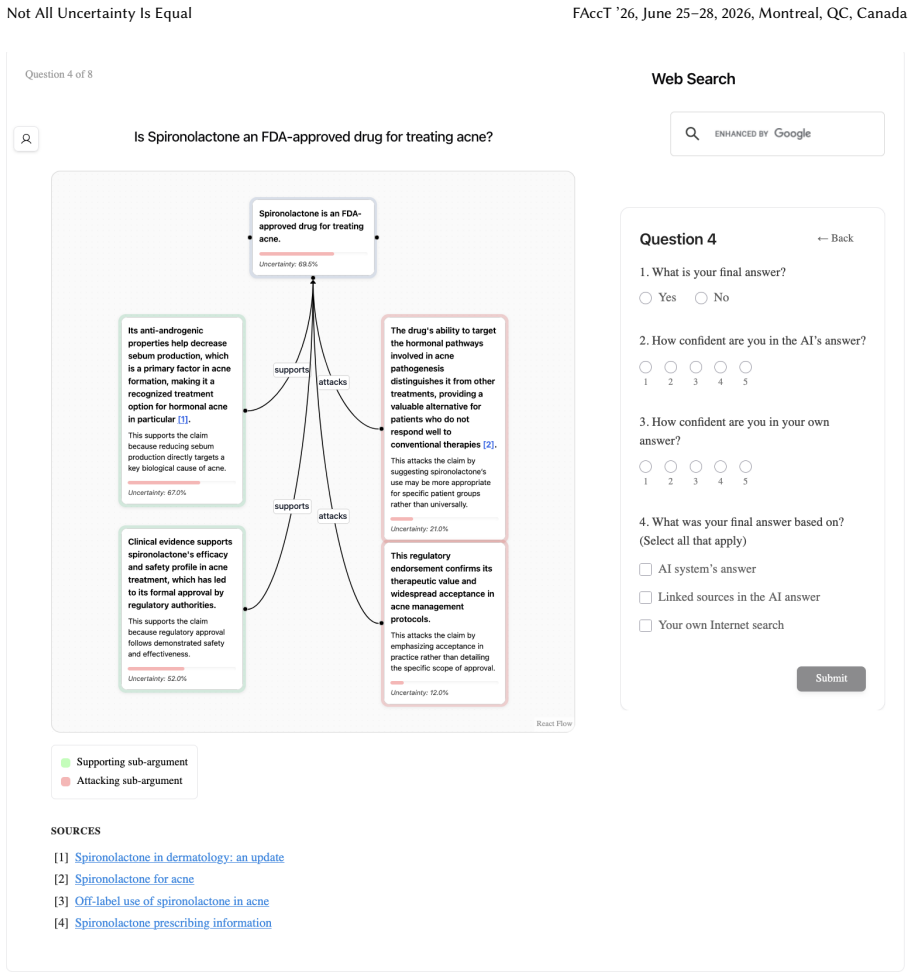
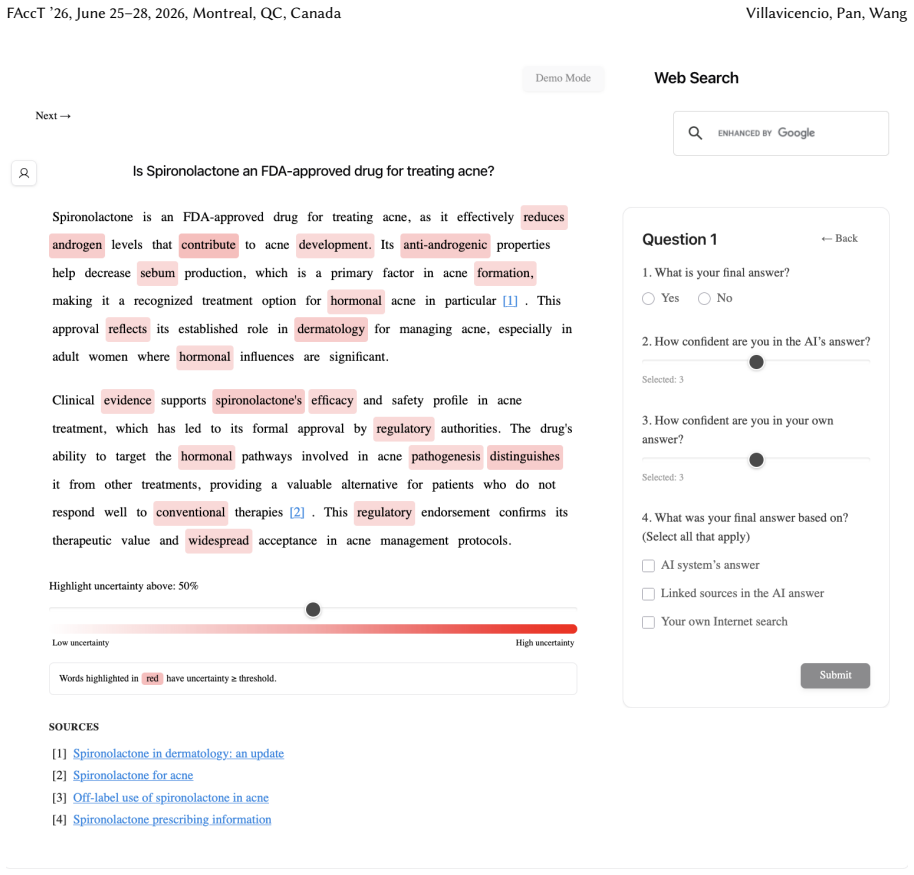
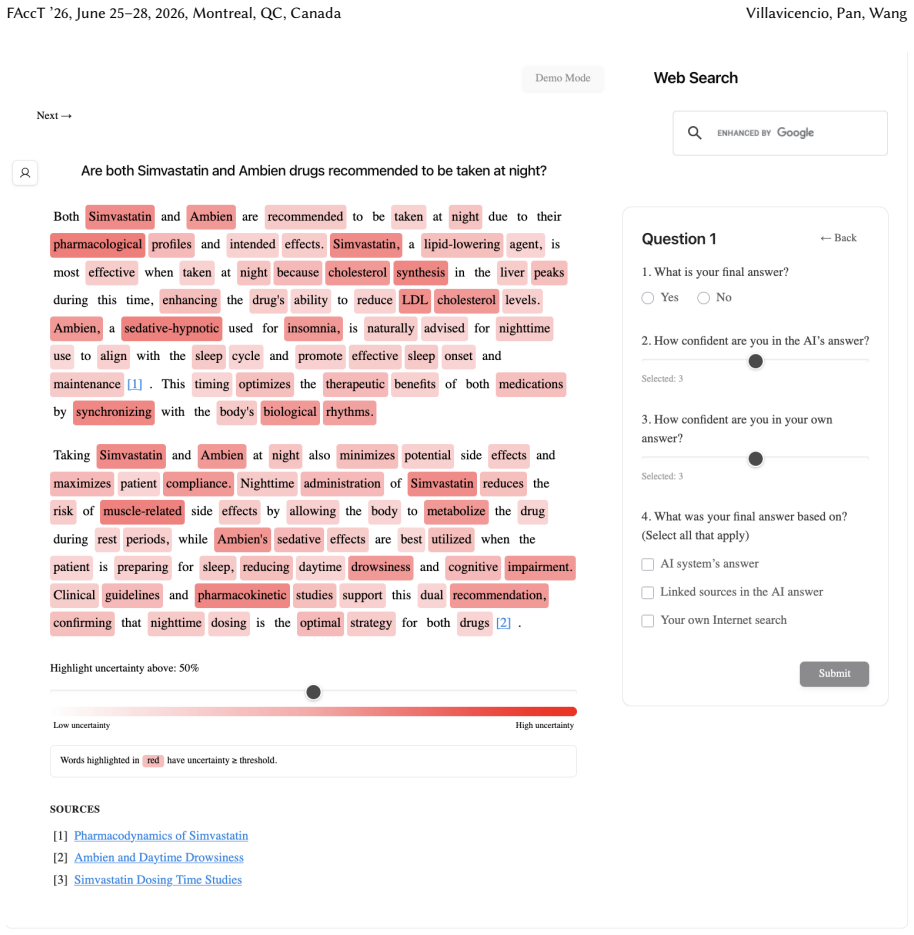
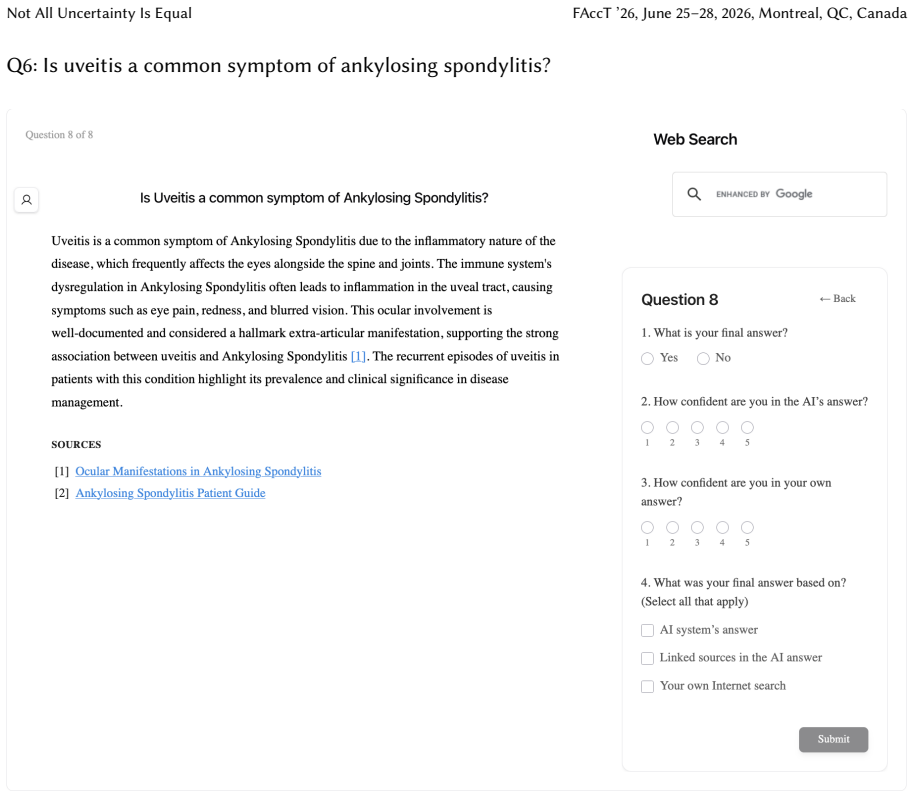
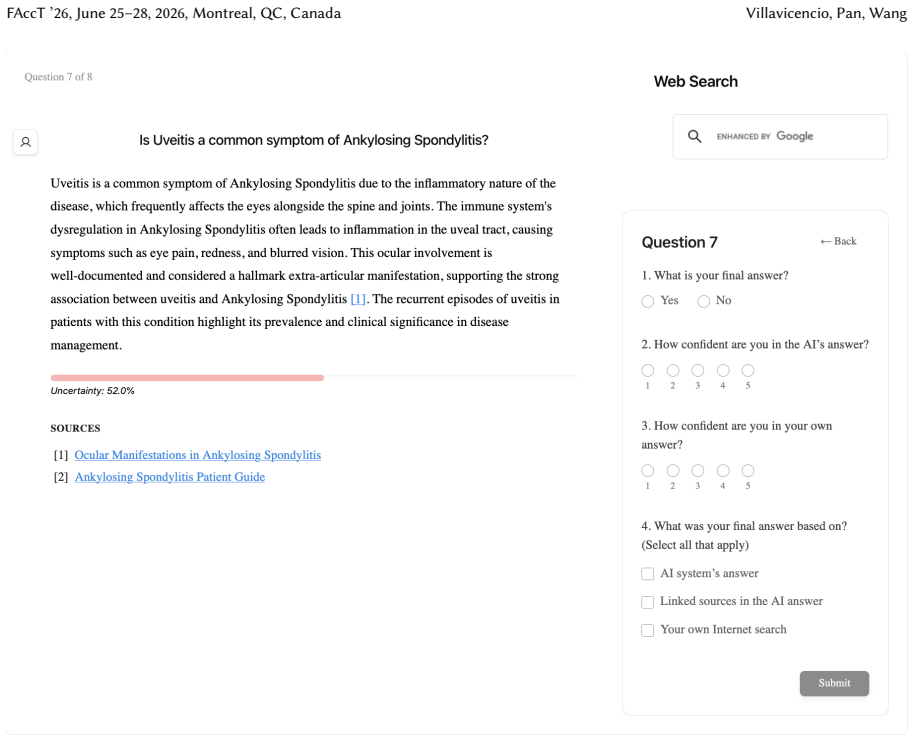
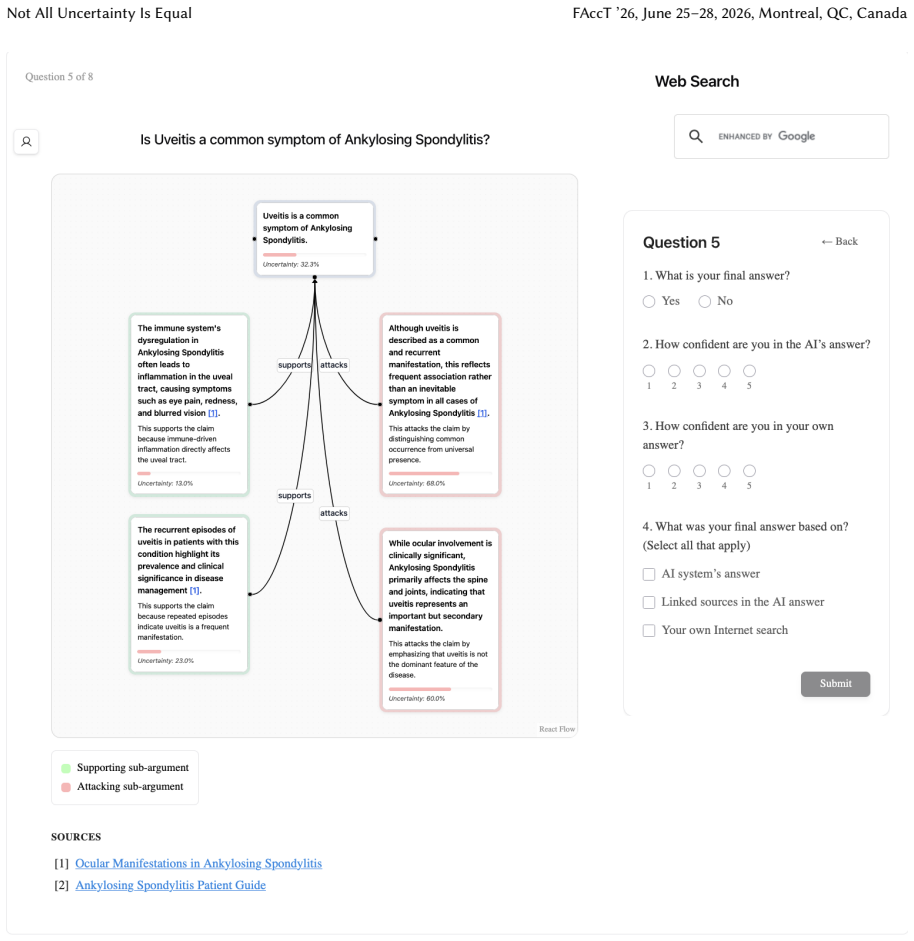
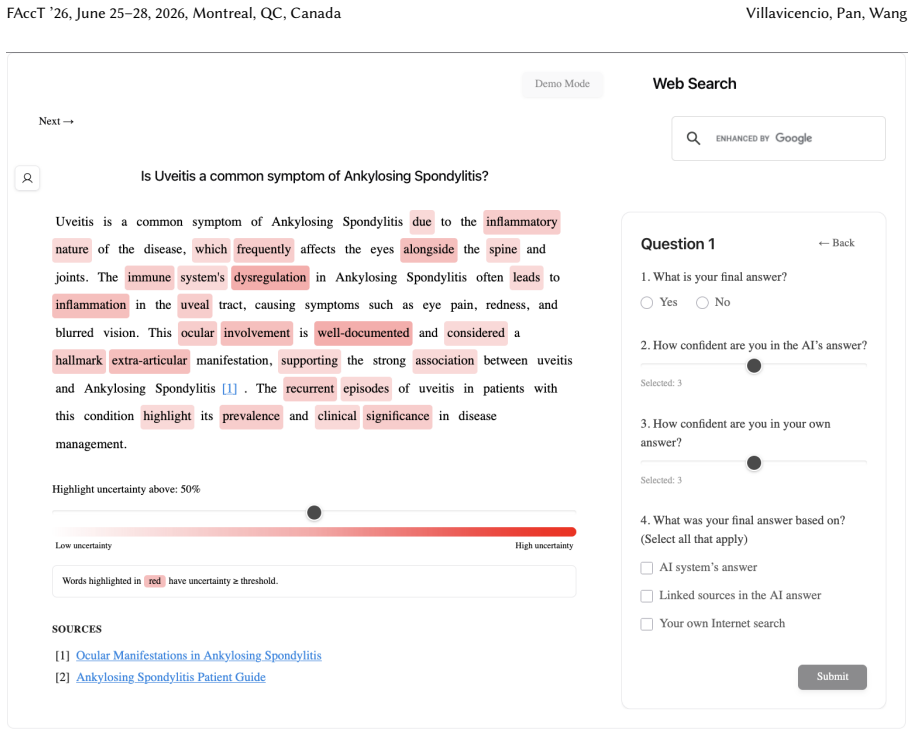
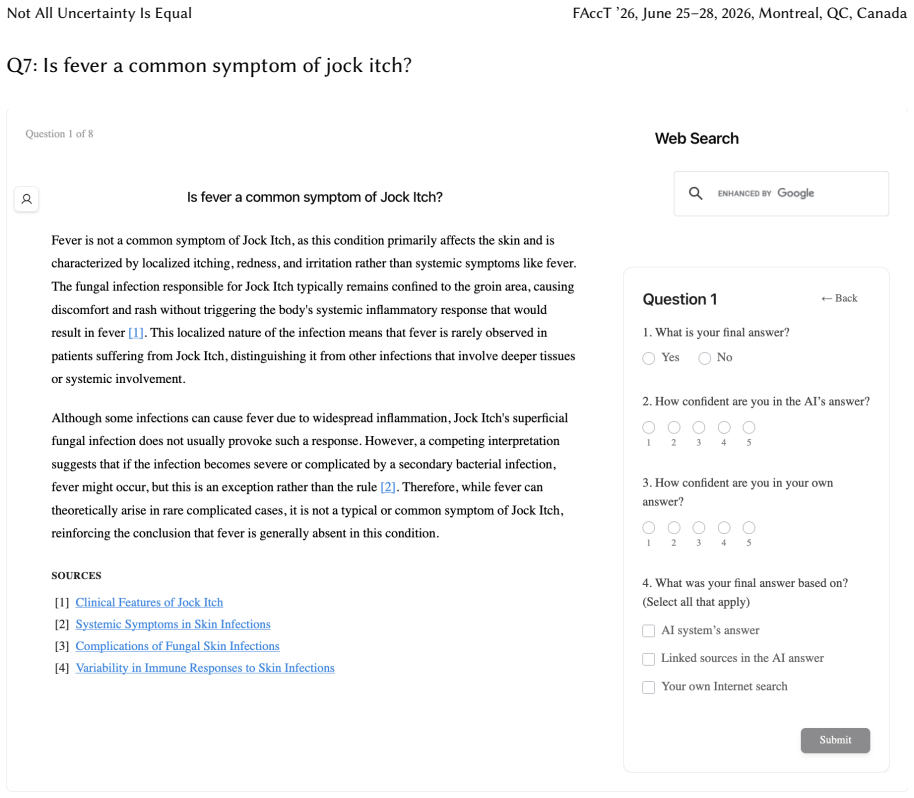
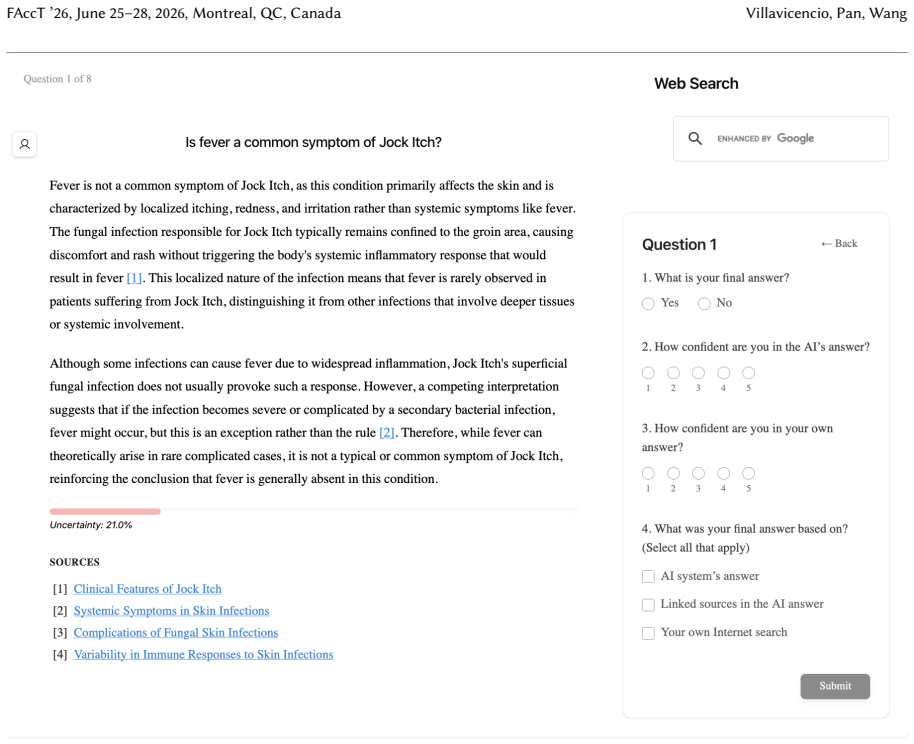
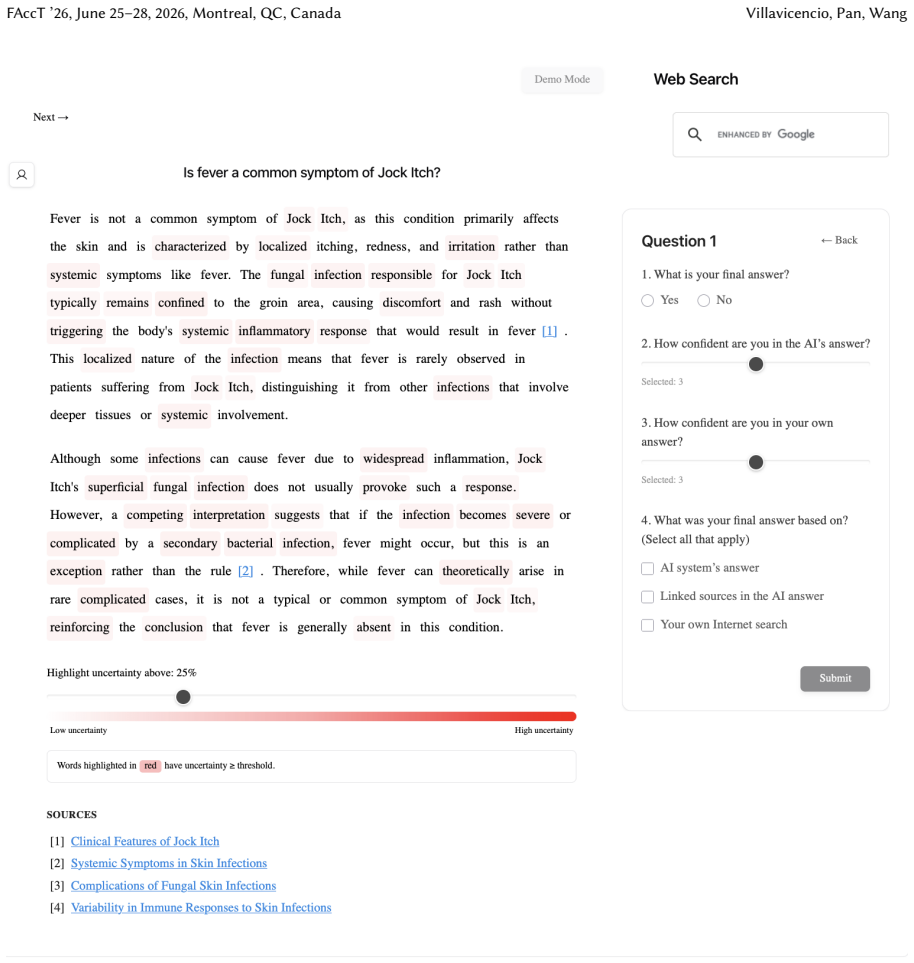
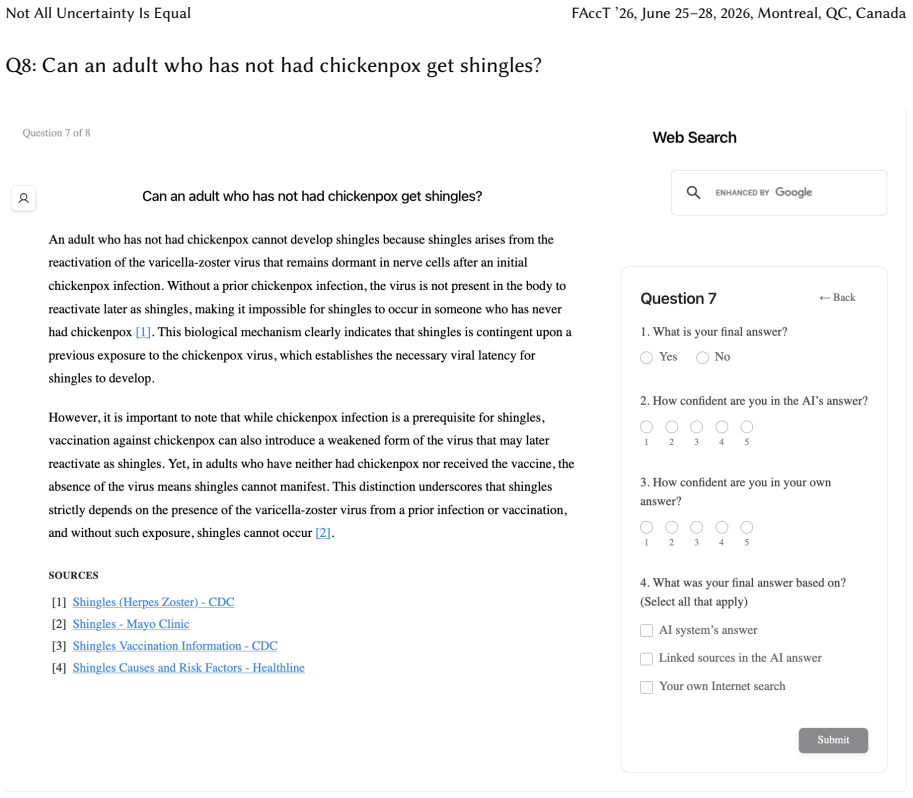
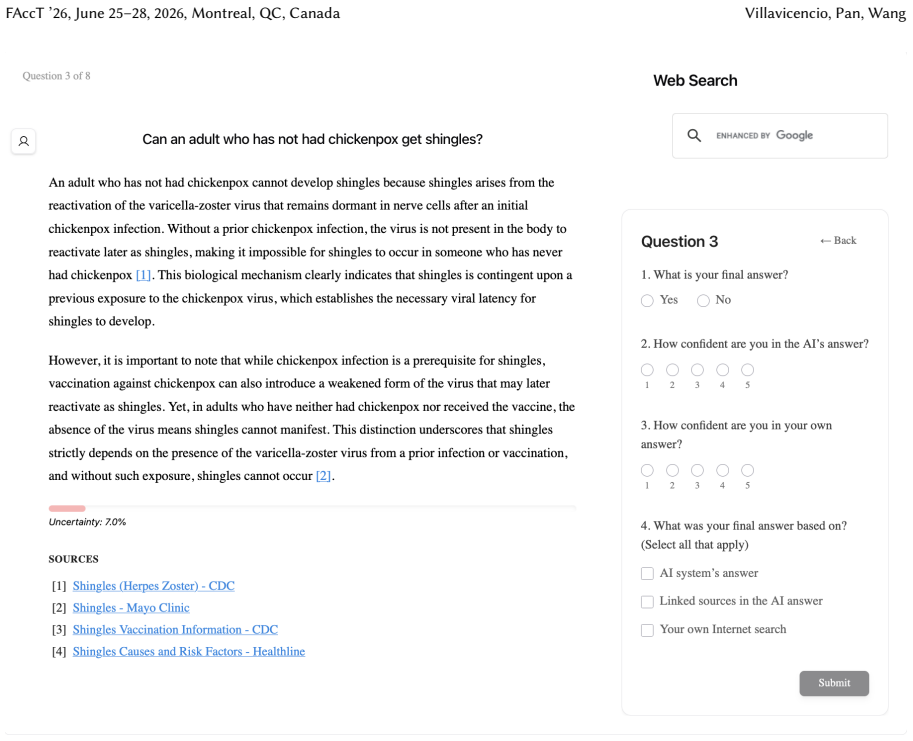
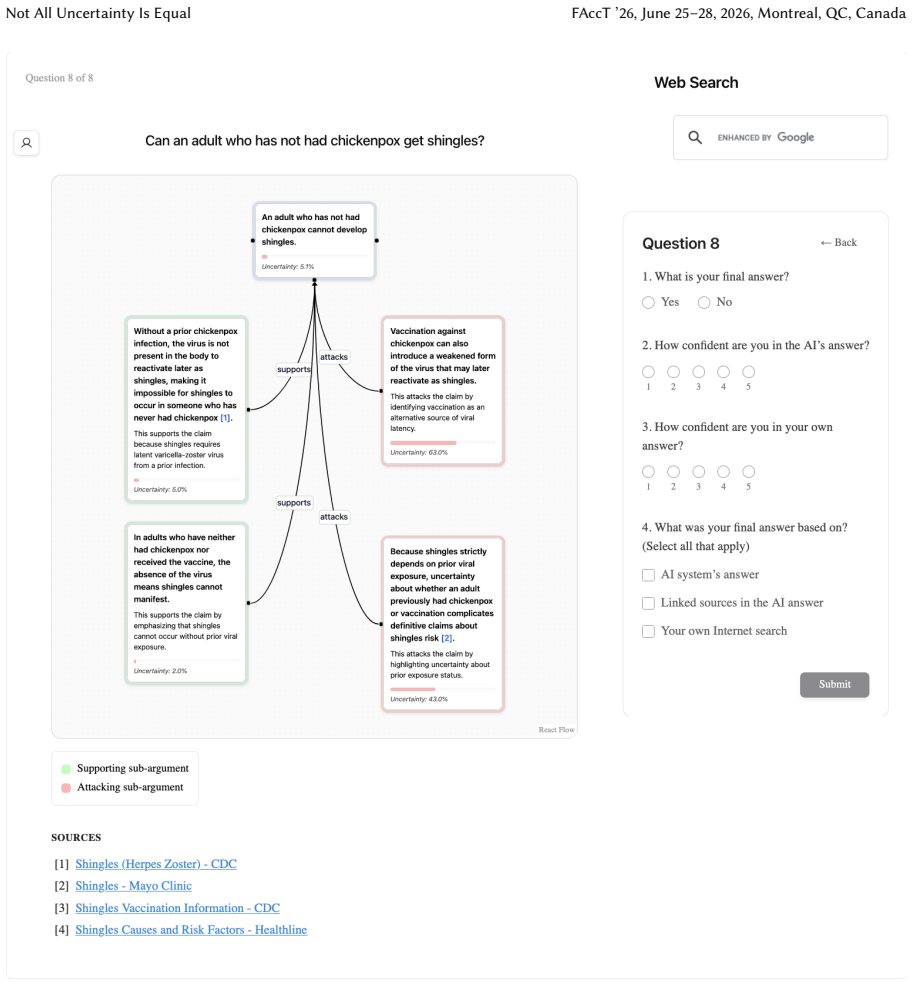
Uncertainty granularity, the extent to which uncertainty is expressed at different levels (output-level for the entire response, relation-level for individual reasoning steps, token-level for specific words) within an LLM response.
If this is right
- Token-level uncertainty may increase acceptance of LLM answers without additional user scrutiny.
- Relation-level uncertainty may steer users away from independent fact-checking toward reliance on the provided cues.
- Output- and relation-level uncertainty may lower users' confidence in their own judgments without raising agreement with the AI.
- Design choices for uncertainty communication should select granularity levels according to the desired balance between trust calibration and verification behavior.
Where Pith is reading between the lines
- Designers could experiment with hybrid displays that switch granularity based on task risk or user expertise to tune verification rates.
- The findings may extend to non-medical domains if similar between-subjects designs are run on factual or technical questions.
- Future work could test whether combining granularity levels with other trust-calibration cues produces additive or interactive effects on verification.
Load-bearing premise
Differences in user behavior can be attributed to the granularity level rather than to how the underlying LLM outputs were generated, how uncertainty values were computed, or how the displays were presented.
What would settle it
A controlled replication that holds LLM outputs, uncertainty values, and visual displays identical across conditions and still observes no differences in agreement rates, self-confidence, or external verification rates would falsify the claim.
Figures



read the original abstract
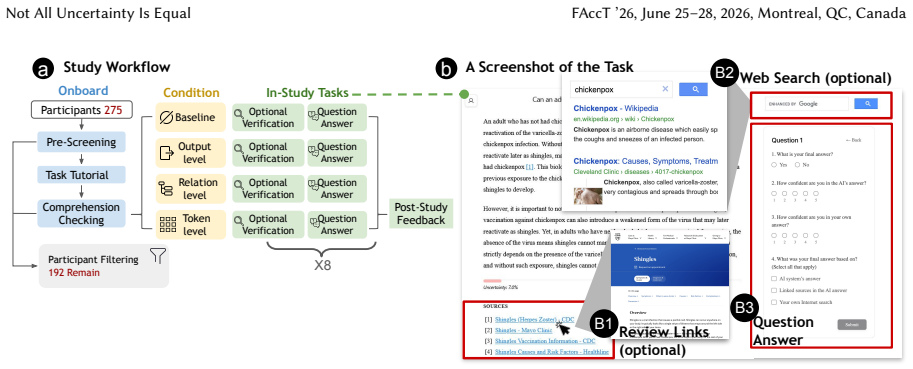
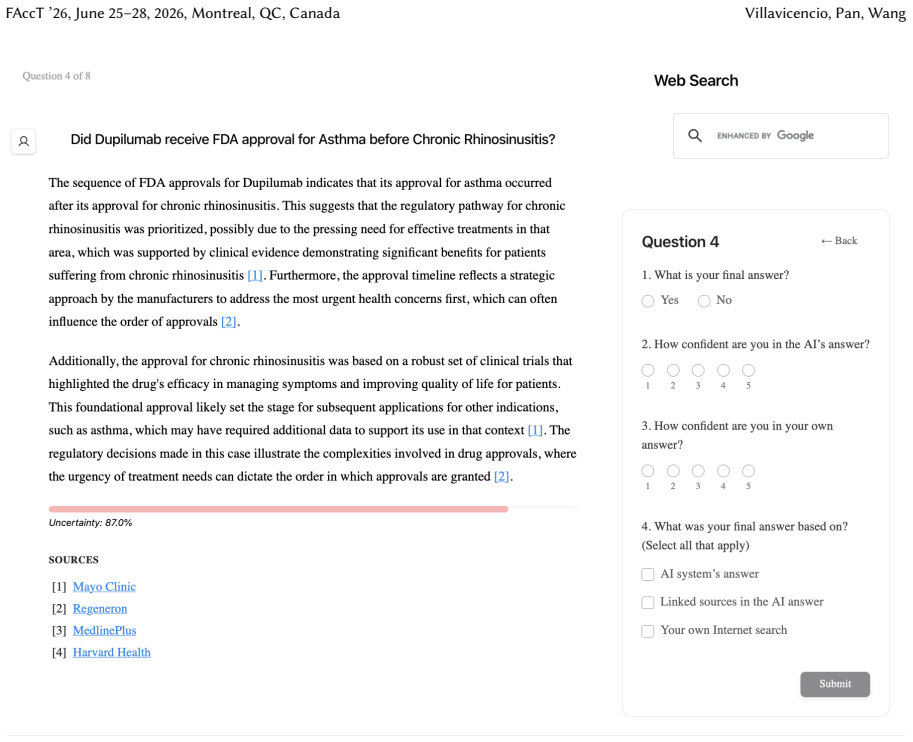
Despite warnings that LLMs can make mistakes, users often develop inappropriate trust and accept incorrect answers without critical evaluation. Uncertainty quantification (UQ), displaying LLMs' confidence, has emerged as a promising approach to calibrate user trust. However, prior empirical studies on uncertainty communication have treated uncertainty as a single numerical score or simple natural language expression. This simplification fails to capture a key property of LLM outputs: a single response often comprises multiple claims and reasoning steps, each with distinct levels of uncertainty. To address this gap, this study investigates uncertainty granularity (i.e., the extent to which uncertainty is expressed at different levels within an LLM response) and examines its impact on LLM-assisted decision-making. We conducted a large-scale, between-subjects study (N=192) in which participants answered medical questions using LLMs that displayed uncertainty at three different granularities: output-level (entire response), relation-level (individual reasoning steps), and token-level (specific words). Our findings reveal distinct behavioral effects as a function of uncertainty granularity. Token-level uncertainty increased users' agreement with the AI, whereas output- and relation-level uncertainty did not increase agreement but instead reduced users' confidence in their own answers. Notably, relation-level uncertainty also reduced external verification (i.e., internet searches, checking provided URLs), steering users away from independent fact-checking and toward reliance on the LLM and its accompanying uncertainty cues. Our findings demonstrate that uncertainty granularity significantly shapes how users interact with and verify LLM outputs, providing concrete design guidance for building responsible LLM applications that encourage appropriate skepticism and verification behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a between-subjects experiment (N=192) on how uncertainty granularity in LLM responses—output-level, relation-level, or token-level—affects user agreement with the LLM, self-confidence, and external verification behaviors during medical question answering. The central claim is that granularity produces distinct behavioral patterns, with token-level increasing agreement and relation-level reducing both self-confidence and external verification.
Significance. If the experimental controls are sound, the work supplies concrete, granularity-specific evidence on trust calibration and verification in LLM-assisted decisions, which is directly relevant to HCI design guidelines for uncertainty communication in high-stakes domains.
major comments (2)
- [Methods] Methods section: the implementation details do not establish that the base LLM responses (specific claims, reasoning steps, and underlying uncertainty values) were identical across the three granularity conditions. Without this control, observed differences in agreement and verification cannot be unambiguously attributed to granularity rather than to systematic differences in content, uncertainty computation, or display properties.
- [Results] Results section: the reported behavioral effects lack accompanying statistical test details, effect sizes, or power analyses in the abstract and main text summary, leaving the strength and reliability of the granularity-dependent patterns difficult to evaluate.
minor comments (1)
- [Abstract] Abstract: no quantitative results, p-values, or effect sizes are supplied, which is standard practice for empirical HCI studies and would improve the summary's informativeness.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on experimental controls and statistical reporting. We address each point below with clarifications from the study design and indicate planned revisions.
read point-by-point responses
-
Referee: [Methods] Methods section: the implementation details do not establish that the base LLM responses (specific claims, reasoning steps, and underlying uncertainty values) were identical across the three granularity conditions. Without this control, observed differences in agreement and verification cannot be unambiguously attributed to granularity rather than to systematic differences in content, uncertainty computation, or display properties.
Authors: The base LLM outputs were generated once per question using a fixed model, prompt, and temperature setting; uncertainty values for claims and tokens were computed from the same logits and then selectively rendered according to the assigned granularity condition. The three conditions therefore differed only in presentation format, not in underlying content or numerical uncertainty estimates. We will revise the Methods section to include explicit confirmation of this shared generation pipeline, along with pseudocode and example outputs demonstrating identical base responses across conditions. revision: yes
-
Referee: [Results] Results section: the reported behavioral effects lack accompanying statistical test details, effect sizes, or power analyses in the abstract and main text summary, leaving the strength and reliability of the granularity-dependent patterns difficult to evaluate.
Authors: The full Results section reports ANOVA and post-hoc tests with exact p-values, Cohen’s d effect sizes, and a pre-registered power analysis (target power 0.80, achieved with N=192). These details appear in the body but were condensed in the abstract and opening summary. We will expand the abstract and main-text summary to include key statistical results and effect sizes while remaining within length limits. revision: yes
Circularity Check
No circularity: purely empirical behavioral study with no derivations or self-referential chains
full rationale
This paper reports a between-subjects experiment (N=192) comparing user behavior across three uncertainty-granularity conditions in an LLM-assisted medical QA task. The abstract and described methods contain no equations, fitted parameters, uniqueness theorems, ansatzes, or self-citations that serve as load-bearing premises. All central claims rest on observed differences in agreement, self-confidence, and verification rates collected from participants; these outcomes are not equivalent to the input conditions by construction. The study is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Between-subjects randomization eliminates carry-over effects and that self-reported agreement, confidence, and verification behaviors are valid proxies for the constructs of interest.
Reference graph
Works this paper leans on
-
[1]
Yavuz Faruk Bakman, Duygu Nur Yaldiz, Baturalp Buyukates, Chenyang Tao, Dimitrios Dimitriadis, and Salman Avestimehr. 2024. Mars: Meaning-aware response scoring for uncertainty estimation in generative llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7752–7767
2024
-
[2]
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. 2024. Linguistic Calibration of Long-Form Generations. InInternational Conference on Machine Learning. PMLR, 2732–2778
2024
-
[3]
Gagan Bansal, Tongshuang Wu, Joyce Zhou, Raymond Fok, Besmira Nushi, Ece Kamar, Marco Tulio Ribeiro, and Daniel Weld. 2021. Does the whole exceed its parts? the effect of ai explanations on complementary team performance. InProceedings of the 2021 CHI conference on human factors in computing systems. 1–16
2021
- [4]
-
[5]
Asma Ben Abacha and Dina Demner-Fushman. 2019. A question-entailment approach to question answering.BMC bioinformatics20, 1 (2019), 511
2019
-
[6]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative Research in Psychology3, 2 (2006), 77–101
2006
-
[7]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z Gajos. 2021. To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making.Proceedings of the ACM on Human-computer Interaction5, CSCW1 (2021), 1–21
2021
-
[8]
Carrie J Cai, Samantha Winter, David Steiner, Lauren Wilcox, and Michael Terry. 2019. Hello AI: uncovering the onboarding needs of medical practitioners for human-AI collaborative decision-making.Proceedings of the ACM on Human-computer Interaction3, CSCW (2019), 1–24
2019
-
[9]
Shiye Cao, Anqi Liu, and Chien-Ming Huang. 2024. Designing for appropriate reliance: The roles of AI uncertainty presentation, initial user decision, and user demographics in AI-assisted decision-making.Proceedings of the ACM on Human-Computer Interaction8, CSCW1 (2024), 1–32
2024
-
[10]
Federico Maria Cau, Hanna Hauptmann, Lucio Davide Spano, and Nava Tintarev. 2023. Effects of AI and logic-style explanations on users’ decisions under different levels of uncertainty.ACM Transactions on Interactive Intelligent Systems13, 4 (2023), 1–42. FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Villavicencio, Pan, Wang
2023
- [11]
-
[12]
Valdemar Danry, Pat Pataranutaporn, Yaoli Mao, and Pattie Maes. 2023. Don’t just tell me, ask me: Ai systems that intelligently frame explanations as questions improve human logical discernment accuracy over causal ai explanations. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–13
2023
-
[13]
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. 2024. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 5050–5063
2024
-
[14]
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, et al. 2024. Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification. InFindings of the Association for Computational Linguistics ACL 2024. 9367–9385
2024
-
[15]
Gabriel Freedman, Adam Dejl, Deniz Gorur, Xiang Yin, Antonio Rago, and Francesca Toni. 2025. Argumentative Large Language Models for Explainable and Contestable Claim Verification. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 14930–14939
2025
-
[16]
Alatrash, Clara Siepmann, and Tannaz Vahidi
Mouadh Guesmi, Mohamed Amine Chatti, Shoeb Joarder, Qurat Ul Ain, R. Alatrash, Clara Siepmann, and Tannaz Vahidi. 2023. Interactive Explanation with Varying Level of Details in an Explainable Scientific Literature Recommender System.International Journal of Human–Computer Interaction40 (2023), 7248 – 7269. https://api.semanticscholar.org/CorpusId:259129445
2023
- [17]
-
[18]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. 2022. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
I’m Not Sure, But
Sunnie SY Kim, Q Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. 2024. " I’m Not Sure, But... ": Examining the Impact of Large Language Models’ Uncertainty Expression on User Reliance and Trust. InProceedings of the 2024 ACM conference on Fairness, Accountability, and Transparency (FAccT). 822–835
2024
-
[20]
René F Kizilcec. 2016. How much information? Effects of transparency on trust in an algorithmic interface. InProceedings of the 2016 CHI conference on human factors in computing systems. 2390–2395
2016
-
[21]
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. 2024. Semantic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [23]
-
[24]
Min Hun Lee and Martyn Zhe Yu Tok. 2025. Towards Uncertainty Aware Task Delegation and Human-AI Collaborative Decision-Making. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. 2274–2289
2025
-
[25]
Zhuoran Lu and Ming Yin. 2021. Human reliance on machine learning models when performance feedback is limited: Heuristics and risks. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–16
2021
- [26]
-
[27]
Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing. 9004–9017
2023
-
[28]
Hannes Matuschek, Reinhold Kliegl, Shravan Vasishth, Harald Baayen, and Douglas Bates. 2017. Balancing Type I error and power in linear mixed models.Journal of Memory and Language94 (2017), 305–315
2017
-
[29]
Luise Metzger, Linda Miller, Martin Baumann, and Johannes Kraus. 2024. Empowering calibrated (dis-) trust in conversational agents: a user study on the persuasive power of limitation disclaimers vs. authoritative style. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–19
2024
- [30]
-
[31]
Snehal Prabhudesai, Leyao Yang, Sumit Asthana, Xun Huan, Q Vera Liao, and Nikola Banovic. 2023. Understanding uncertainty: how lay decision-makers perceive and interpret uncertainty in human-AI decision making. InProceedings of the 28th International Conference on Intelligent User Interfaces (IUI). 379–396
2023
-
[32]
Xin Qiu and Risto Miikkulainen. 2024. Semantic density: Uncertainty quantification for large language models through confidence measurement in semantic space.Advances in neural information processing systems37 (2024), 134507–134533
2024
-
[33]
Olya Rezaeian, Alparslan Emrah Bayrak, and Onur Asan. 2025. Explainability and AI confidence in clinical decision support systems: Effects on trust, diagnostic performance, and cognitive load in breast cancer care.International Journal of Human–Computer Interaction Not All Uncertainty Is Equal FAccT ’26, June 25–28, 2026, Montreal, QC, Canada (2025), 1–21
2025
-
[34]
Sara Salimzadeh, Gaole He, and Ujwal Gadiraju. 2024. Dealing with Uncertainty: Understanding the Impact of Prognostic Versus Diagnostic Tasks on Trust and Reliance in Human-AI Decision-Making. InProceedings of the CHI Conference on Human Factors in Computing Systems. ACM, 1–17
2024
-
[35]
Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z Ren, and Anirudha Majumdar. 2025. A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions.Comput. Surveys(2025)
2025
-
[36]
Mark Steyvers, Heliodoro Tejeda, Aakriti Kumar, Catarina Belem, Sheer Karny, Xinyue Hu, Lukas W Mayer, and Padhraic Smyth. 2025. What large language models know and what people think they know.Nature Machine Intelligence7, 2 (2025), 221–231
2025
-
[37]
Sree Harsha Tanneru, Chirag Agarwal, and Himabindu Lakkaraju. 2024. Quantifying uncertainty in natural language explanations of large language models. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 1072–1080
2024
- [38]
-
[39]
Helena Vasconcelos, Gagan Bansal, Adam Fourney, Q Vera Liao, and Jennifer Wortman Vaughan. 2025. Generation probabilities are not enough: Uncertainty highlighting in ai code completions.ACM Transactions on Computer-Human Interaction32, 1 (2025), 1–30
2025
-
[40]
Qianwen Wang, Kexin Huang, Payal Chandak, Marinka Zitnik, and Nils Gehlenborg. 2022. Extending the nested model for user-centric xai: A design study on gnn-based drug repurposing.IEEE Transactions on Visualization and Computer Graphics29, 1 (2022), 1266–1276
2022
-
[41]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2023. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Zhengtao Xu, Tianqi Song, and Yi-Chieh Lee. 2025. Confronting verbalized uncertainty: Understanding how LLM’s verbalized uncertainty influences users in AI-assisted decision-making.International Journal of Human-Computer Studies197 (2025), 103455
2025
-
[43]
Fumeng Yang, Zhuanyi Huang, Jean Scholtz, and Dustin L Arendt. 2020. How do visual explanations foster end users’ appropriate trust in machine learning?. InProceedings of the 25th International Conference on Intelligent User Interfaces (IUI). 189–201
2020
-
[44]
Zhangyue Yin, Qiushi Sun, Qipeng Guo, Zhiyuan Zeng, Xiaonan Li, Junqi Dai, Qinyuan Cheng, Xuan-Jing Huang, and Xipeng Qiu. 2024. Reasoning in flux: Enhancing large language models reasoning through uncertainty-aware adaptive guidance. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2401–2416
2024
- [45]
-
[46]
Yunfeng Zhang, Q Vera Liao, and Rachel KE Bellamy. 2020. Effect of confidence and explanation on accuracy and trust calibration in AI-assisted decision making. InProceedings of the 2020 conference on Fairness, Accountability, and Transparency (FAccT). 295–305
2020
-
[47]
Jieqiong Zhao, Yixuan Wang, Michelle V Mancenido, Erin K Chiou, and Ross Maciejewski. 2023. Evaluating the impact of uncertainty visualization on model reliance.IEEE Transactions on Visualization and Computer Graphics30, 7 (2023), 4093–4107. APPENDIX The appendix is structured in the following way. •Appendix A: Participant Demographics and Background •App...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.