Efficient Pre-Training of LLMs through Truncated SVD Layers
Pith reviewed 2026-06-29 13:37 UTC · model grok-4.3
The pith
TSVD maintains low-rank orthonormal weights during LLM pretraining to match full-parameter performance at reduced compute cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TSVD maintains low rank and strict orthonormality throughout the training process. It utilizes a spectral energy-based heuristic for adaptive rank selection, and a caching mechanisms to maintain orthonormality. Theoretical analysis justifies the advantage of the approach in pretraining dynamics and experiments across various model scales demonstrate that it is effective empirically. TSVD matches or exceeds the performance of full-parameter baselines while significantly reducing compute requirements.
What carries the argument
TSVD framework that maintains low rank and strict orthonormality throughout training via spectral energy-based adaptive rank selection and caching.
If this is right
- Pretraining can proceed with fewer parameters stored and updated at each step.
- Adaptive rank selection based on spectral energy allows the model to grow effective capacity only where needed.
- Orthonormality preservation reduces the cost of repeated matrix operations during forward and backward passes.
- The method scales across model sizes while preserving the claimed performance parity.
Where Pith is reading between the lines
- The same constraints might stabilize gradient flow in very deep stacks, though this is not tested in the paper.
- TSVD could be combined with existing quantization or pruning pipelines to compound efficiency gains.
- If the heuristic generalizes, similar low-rank orthonormal layers might apply to vision or multimodal pretraining.
Load-bearing premise
Enforcing strict low-rank and orthonormality constraints throughout training does not prevent the model from reaching equivalent or better performance than unconstrained full-rank training.
What would settle it
A controlled experiment in which TSVD-trained models achieve measurably lower validation loss or downstream accuracy than matched full-rank baselines at the same scale and training budget would falsify the central claim.
Figures
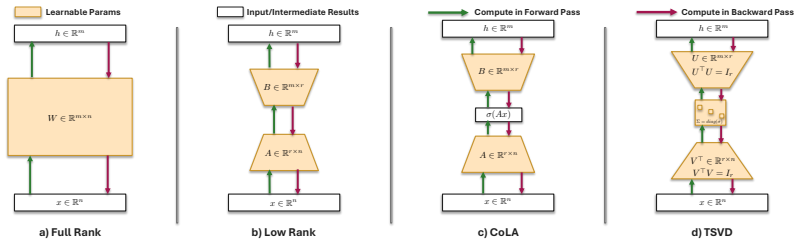
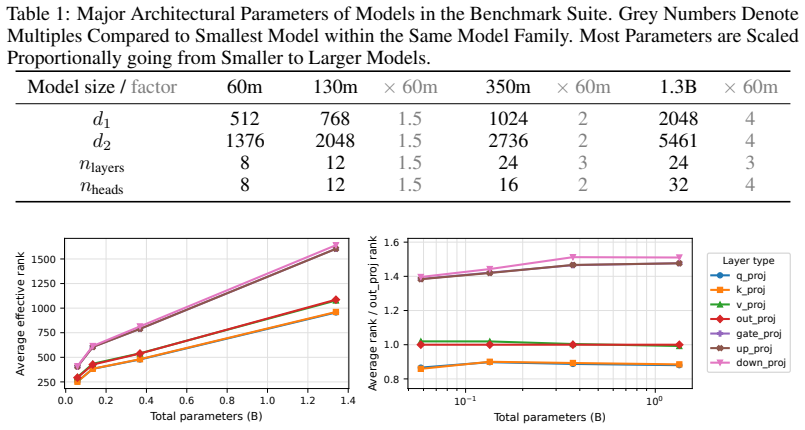
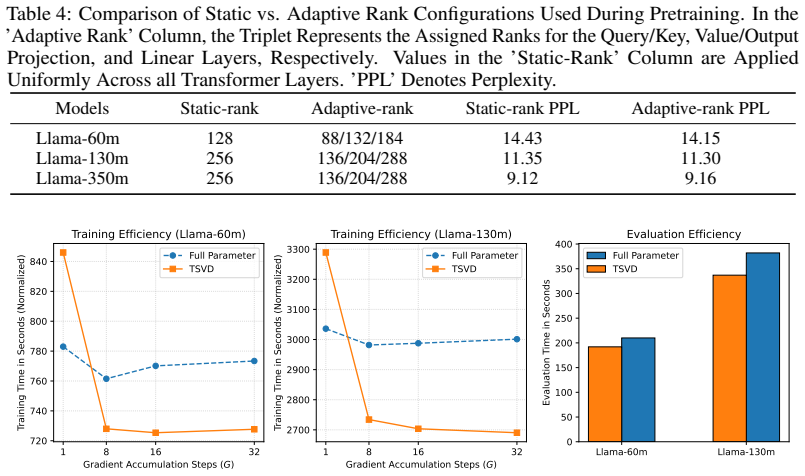
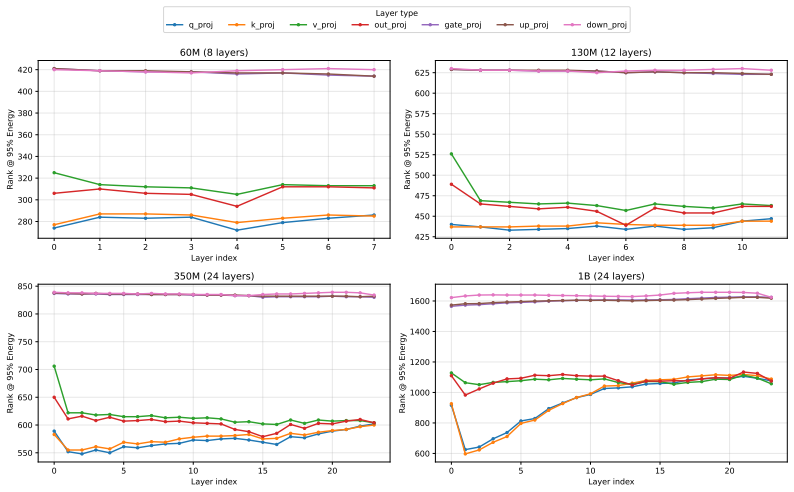
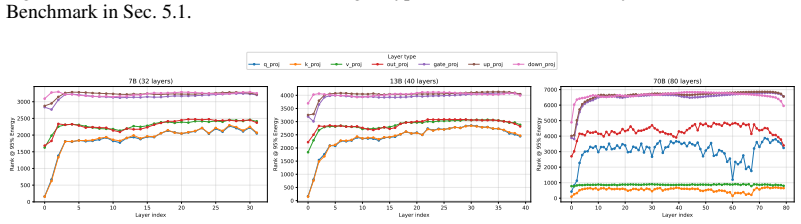
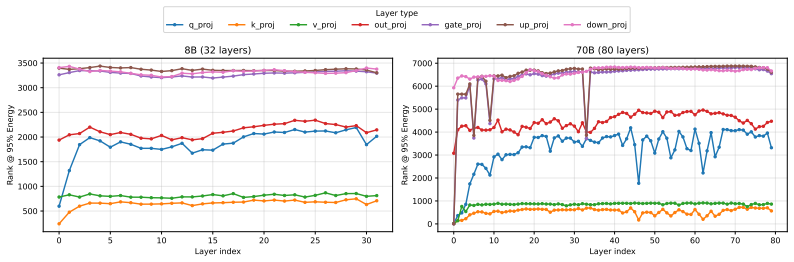
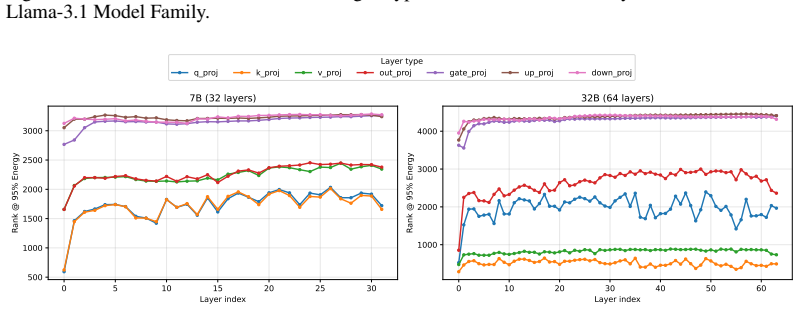
read the original abstract
The massive scaling of Large Language Models (LLMs) has made pretraining increasingly cost-prohibitive. While low-rank representation and orthonormal weight matrices could in principle reduce parameter counts and computational overhead, most existing methods rely on static rank selection and do not enforce weight orthonormality due to high computational cost. This paper introduces TSVD, a framework that maintains low rank and strict orthonormality throughout the training process. It utilizes a spectral energy-based heuristic for adaptive rank selection, and a caching mechanisms to maintain orthonormality. Theoretical analysis justifies the advantage of the approach in pretraining dynamics and experiments across various model scales demonstrate that it is effective empirically. TSVD matches or exceeds the performance of full-parameter baselines while significantly reducing compute requirements. The approach thus offers a well-founded, practical, and scalable path toward efficient high-performance LLM pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TSVD, a framework that enforces low-rank structure and strict orthonormality on weight matrices throughout LLM pretraining via truncated SVD, an adaptive spectral-energy heuristic for rank selection, and caching to maintain orthonormality. It supplies theoretical analysis of pretraining dynamics and claims that experiments across model scales show TSVD matches or exceeds full-parameter baselines while reducing compute.
Significance. If the empirical results and theoretical justification hold, the method could meaningfully lower the resource barrier for LLM pretraining by dynamically imposing low-rank and orthonormal constraints without sacrificing performance. This would be a practical contribution to efficient scaling, provided the constraints do not introduce hidden optimization difficulties at larger scales.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): the central claim that TSVD 'matches or exceeds' full-parameter baselines is stated without any reported metrics, baselines, model sizes, training steps, or error bars. The soundness of the empirical result cannot be assessed from the supplied text.
- [§3] §3 (Theoretical analysis): the justification that the TSVD mechanism and heuristic preserve pretraining dynamics is asserted but the derivation steps, assumptions on the loss landscape, or comparison to unconstrained SGD are not detailed enough to verify whether the low-rank/orthonormality constraints are load-bearing or merely reparameterizations.
minor comments (1)
- [§2] Notation for the spectral energy heuristic and the caching mechanism should be defined with explicit equations rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. We address each major point below and commit to revisions that strengthen the presentation and theoretical exposition without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the central claim that TSVD 'matches or exceeds' full-parameter baselines is stated without any reported metrics, baselines, model sizes, training steps, or error bars. The soundness of the empirical result cannot be assessed from the supplied text.
Authors: We agree that the abstract and §4 do not report the specific quantitative details needed to evaluate the empirical claims. This is a presentation shortcoming in the current draft. In the revised manuscript we will add the missing metrics, baselines, model sizes, training steps, and error bars from the experiments across scales to allow direct assessment of whether TSVD matches or exceeds full-parameter performance. revision: yes
-
Referee: [§3] §3 (Theoretical analysis): the justification that the TSVD mechanism and heuristic preserve pretraining dynamics is asserted but the derivation steps, assumptions on the loss landscape, or comparison to unconstrained SGD are not detailed enough to verify whether the low-rank/orthonormality constraints are load-bearing or merely reparameterizations.
Authors: We acknowledge that §3 presents the justification at a high level and that the derivation steps, loss-landscape assumptions, and explicit comparison to unconstrained SGD are not expanded sufficiently. In the revision we will provide the missing derivation details, state the assumptions clearly, and include a direct comparison showing how the constraints affect the dynamics relative to standard SGD. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on a theoretical analysis of pretraining dynamics plus empirical scaling experiments that compare TSVD against full-parameter baselines. No load-bearing step reduces by construction to a fitted input, self-definition, or self-citation chain; the performance equivalence is presented as an observed outcome rather than a definitional necessity. The adaptive heuristic and caching mechanisms are described as implementation choices whose validity is tested externally, leaving the manuscript self-contained against benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Princeton University Press, 2008
P-A Absil, Robert Mahony, and Rodolphe Sepulchre.Optimization algorithms on matrix manifolds. Princeton University Press, 2008
2008
-
[2]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901. Association for Computational Linguistics, 2023
2023
-
[3]
Unitary evolution recurrent neural networks, 2016
Martin Arjovsky, Amar Shah, and Yoshua Bengio. Unitary evolution recurrent neural networks, 2016
2016
-
[4]
Can we gain more from orthogonality regularizations in training deep cnns?, 2018
Nitin Bansal, Xiaohan Chen, and Zhangyang Wang. Can we gain more from orthogonality regularizations in training deep cnns?, 2018
2018
-
[5]
Cambridge University Press, 2023
Nicolas Boumal.An introduction to optimization on smooth manifolds. Cambridge University Press, 2023
2023
-
[6]
F. E. Burstall.Basic Riemannian geometry, page 1–29. London Mathematical Society Lecture Note Series. Cambridge University Press, 1999
1999
-
[7]
Tony F. Chan. Rank revealing qr factorizations.Linear Algebra and its Applications, 88-89:67– 82, 1987
1987
-
[8]
Reducing overfitting in deep networks by decorrelating representations, 2016
Michael Cogswell, Faruk Ahmed, Ross Girshick, Larry Zitnick, and Dhruv Batra. Reducing overfitting in deep networks by decorrelating representations, 2016
2016
-
[9]
IOS Press, October 2024
Daniel Coquelin, Katharina Flügel, Marie Weiel, Nicholas Kiefer, Charlotte Debus, Achim Streit, and Markus Götz.Harnessing Orthogonality to Train Low-Rank Neural Networks. IOS Press, October 2024
2024
-
[10]
Documenting large webtext corpora: A case study on the colossal clean crawled corpus, 2021
Jesse Dodge, Maarten Sap, Ana Marasovi´c, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. Documenting large webtext corpora: A case study on the colossal clean crawled corpus, 2021
2021
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, and Aurelien Rodriguez et al. The llama 3 herd of models.arXiv, 2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
The approximation of one matrix by another of lower rank
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank. Psychometrika, 1(3):211–218, Sep 1936
1936
-
[13]
Arias, and Steven T
Alan Edelman, Tomás A. Arias, and Steven T. Smith. The geometry of algorithms with orthogonality constraints.SIAM Journal on Matrix Analysis and Applications, 20(2):303–353, 1998
1998
-
[14]
Full-rank no more: Low-rank weight training for modern speech recognition models, 2024
Adriana Fernandez-Lopez, Shiwei Liu, Lu Yin, Stavros Petridis, and Maja Pantic. Full-rank no more: Low-rank weight training for modern speech recognition models, 2024
2024
-
[15]
Deep feedforward networks.Deep learning, 1:161–217, 2016
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep feedforward networks.Deep learning, 1:161–217, 2016
2016
-
[16]
From gpt to llama: Tracing the growth of large language models.Theoretical and Natural Science, 142:144–155, 11 2025
Jiarui Gu. From gpt to llama: Tracing the growth of large language models.Theoretical and Natural Science, 142:144–155, 11 2025
2025
-
[17]
Sltrain: a sparse plus low-rank approach for parameter and memory efficient pretraining, 2024
Andi Han, Jiaxiang Li, Wei Huang, Mingyi Hong, Akiko Takeda, Pratik Jawanpuria, and Bamdev Mishra. Sltrain: a sparse plus low-rank approach for parameter and memory efficient pretraining, 2024. 11
2024
-
[18]
Rae, Oriol Vinyals, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
2022
-
[19]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021
2021
-
[20]
Siddhartha Rao Kamalakara, Acyr Locatelli, Bharat Venkitesh, Jimmy Ba, Yarin Gal, and Aidan N. Gomez. Exploring low rank training of deep neural networks, 2022
2022
-
[21]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020
2020
-
[22]
Initialization and regular- ization of factorized neural layers
Mikhail Khodak, Neil Tenenholtz, Lester Mackey, and Nicolo Fusi. Initialization and regular- ization of factorized neural layers. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[23]
Initialization and regular- ization of factorized neural layers, 2022
Mikhail Khodak, Neil Tenenholtz, Lester Mackey, and Nicolò Fusi. Initialization and regular- ization of factorized neural layers, 2022
2022
-
[24]
Lost: Low-rank and sparse pre-training for large language models, 2025
Jiaxi Li, Lu Yin, Li Shen, Jinjin Xu, Liwu Xu, Tianjin Huang, Wenwu Wang, Shiwei Liu, and Xilu Wang. Lost: Low-rank and sparse pre-training for large language models, 2025
2025
-
[25]
Relora: High- rank training through low-rank updates, 2023
Vladislav Lialin, Namrata Shivagunde, Sherin Muckatira, and Anna Rumshisky. Relora: High- rank training through low-rank updates, 2023
2023
-
[26]
Cola: Compute-efficient pre-training of llms via low-rank activation, 2025
Ziyue Liu, Ruijie Zhang, Zhengyang Wang, Mingsong Yan, Zi Yang, Paul Hovland, Bogdan Nicolae, Franck Cappello, Sui Tang, and Zheng Zhang. Cola: Compute-efficient pre-training of llms via low-rank activation, 2025
2025
-
[27]
Large language models: A survey, 2025
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey, 2025
2025
-
[28]
Parameter and memory efficient pretraining via low-rank riemannian optimization
Zhanfeng Mo, Long-Kai Huang, and Sinno Jialin Pan. Parameter and memory efficient pretraining via low-rank riemannian optimization. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[29]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heine- man, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.CoRR, abs/1910.10683, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[31]
Robust low-rank training via approximate orthonormal constraints, 2023
Dayana Savostianova, Emanuele Zangrando, Gianluca Ceruti, and Francesco Tudisco. Robust low-rank training via approximate orthonormal constraints, 2023
2023
-
[32]
Low-rank lottery tickets: finding efficient low-rank neural networks via matrix differential equations, 2022
Steffen Schotthöfer, Emanuele Zangrando, Jonas Kusch, Gianluca Ceruti, and Francesco Tudisco. Low-rank lottery tickets: finding efficient low-rank neural networks via matrix differential equations, 2022. 12
2022
-
[33]
Compact: Compressed activations for memory-efficient llm training, 2025
Yara Shamshoum, Nitzan Hodos, Yuval Sieradzki, and Assaf Schuster. Compact: Compressed activations for memory-efficient llm training, 2025
2025
-
[34]
Cuttlefish: Low-rank model training without all the tuning.arXiv preprint arXiv:2305.02538, 2023
Yifan Shen et al. Cuttlefish: Low-rank model training without all the tuning.arXiv preprint arXiv:2305.02538, 2023
-
[35]
Hyuntak Shin, Aecheon Jung, Sunwoo Lee, and Sungeun Hong. Dynamic rank adjustment for accurate and efficient neural network training.arXiv preprint arXiv:2508.08625, 2025
-
[36]
Elrt: Efficient low-rank training for compact convolutional neural networks, 2024
Yang Sui, Miao Yin, Yu Gong, Jinqi Xiao, Huy Phan, and Bo Yuan. Elrt: Efficient low-rank training for compact convolutional neural networks, 2024
2024
-
[37]
Llama: Open and efficient foundation language models, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023
2023
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
BOOST: BOttleneck-Optimized Scalable Training Framework for Low-Rank Large Language Models
Zhengyang Wang, Ziyue Liu, Ruijie Zhang, Avinash Maurya, Paul Hovland, Bogdan Nicolae, Franck Cappello, and Zheng Zhang. Boost: Bottleneck-optimized scalable training framework for low-rank large language models.arXiv preprint arXiv:2512.12131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Investigating low-rank training in transformer language models: Efficiency and scaling analysis, 2024
Xiuying Wei, Skander Moalla, Razvan Pascanu, and Caglar Gulcehre. Investigating low-rank training in transformer language models: Efficiency and scaling analysis, 2024
2024
-
[41]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art na...
2020
-
[42]
Learning low-rank deep neural networks via singular vector orthogonality regularization and singular value sparsification, 2020
Huanrui Yang, Minxue Tang, Wei Wen, Feng Yan, Daniel Hu, Ang Li, Hai Li, and Yiran Chen. Learning low-rank deep neural networks via singular vector orthogonality regularization and singular value sparsification, 2020
2020
-
[43]
Inrank: Incremental low-rank learning.arXiv preprint arXiv:2306.11250, 2023
Jiawei Zhao, Yifei Zhang, Beidi Chen, Florian Schäfer, and Anima Anandkumar. Inrank: Incremental low-rank learning.arXiv preprint arXiv:2306.11250, 2023
-
[44]
Galore: Memory-efficient llm training by gradient low-rank projection, 2024
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. Galore: Memory-efficient llm training by gradient low-rank projection, 2024
2024
-
[45]
A survey of large language models, 2026
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2026. 13 A Broader Impact This work aims ...
2026
-
[46]
Hence the forward operator norm is controlled exactly byσ max
For every input vectorx∈R n, ∥W x∥2 ≤ σmax√r ∥x∥2. Hence the forward operator norm is controlled exactly byσ max
-
[47]
Hence the backward operator norm is controlled by the same quantity
For every backpropagated signalδ∈R m, ∥W ⊤δ∥2 ≤ σmax√r ∥δ∥2. Hence the backward operator norm is controlled by the same quantity
-
[48]
Likewise, ifδlies in the represented output subspacespan(U), then σmin√r ∥δ∥2 ≤ ∥W ⊤δ∥2 ≤ σmax√r ∥δ∥2
Ifxlies in the represented input subspacespan(V), then σmin√r ∥x∥2 ≤ ∥W x∥2 ≤ σmax√r ∥x∥2. Likewise, ifδlies in the represented output subspacespan(U), then σmin√r ∥δ∥2 ≤ ∥W ⊤δ∥2 ≤ σmax√r ∥δ∥2. Thus, within the learned low-rank subspaces, neither forward signals nor backward signals can explode beyondσ max/√r, and neither can they vanish beyondσ min/√r
-
[49]
If ui and vi denote the i-th columns of UandV, then W= 1√r rX i=1 σiuiv⊤ i , ∂L ∂σi = 1√r u⊤ i Gvi
LetL(W)be the loss and let G=∇ W L(W) be its gradient with respect to the full weight matrix. If ui and vi denote the i-th columns of UandV, then W= 1√r rX i=1 σiuiv⊤ i , ∂L ∂σi = 1√r u⊤ i Gvi. Therefore each scalar σi controls one orthogonal rank-one mode uiv⊤ i , and the mode strengths are learned without ambiguity from the norms of the basis vectors. P...
-
[50]
No hidden explosion in signal propagation.Forward activations and backward signals can only grow in proportion toσ max/√r
-
[51]
No hidden vanishing inside the represented subspace.As long as σmin is not too small, the layer cannot collapse the represented input and output subspaces by more than the factor σmin/√r
-
[52]
Orthonormality does not remove this fundamental low-rank bottleneck, but it does prevent additional instability caused by badly scaled basis factors
The only unavoidable information loss is the intended rank constraint.Components orthog- onal to span(V) are discarded by any rank-r model. Orthonormality does not remove this fundamental low-rank bottleneck, but it does prevent additional instability caused by badly scaled basis factors. 17 Consider an unconstrained low-rank parameterization W=AB ⊤, A∈R ...
-
[53]
the represented subspaces and spectral magnitudes are cleanly separated
-
[54]
signal amplification and attenuation are explicit and easy to control
-
[55]
parameter gradients are not corrupted by arbitrary factor rescalings; and
-
[56]
orthonormality is maintained throughout training without introducing additional loss terms. These properties are especially appealing in low-rank pretraining, where optimization is already harder than full-rank training and unnecessary conditioning problems can have a disproportionate effect on final performance. In summary, TSVD is best viewed as a by-co...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.