Deformable Gaussian Occupancy: Decoupling Rigid and Nonrigid Motion with Factorized Distillation
Pith reviewed 2026-06-29 13:27 UTC · model grok-4.3
The pith
Deformable Gaussian occupancy decouples rigid and nonrigid motion with factorized 4D distillation to better model dynamic scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
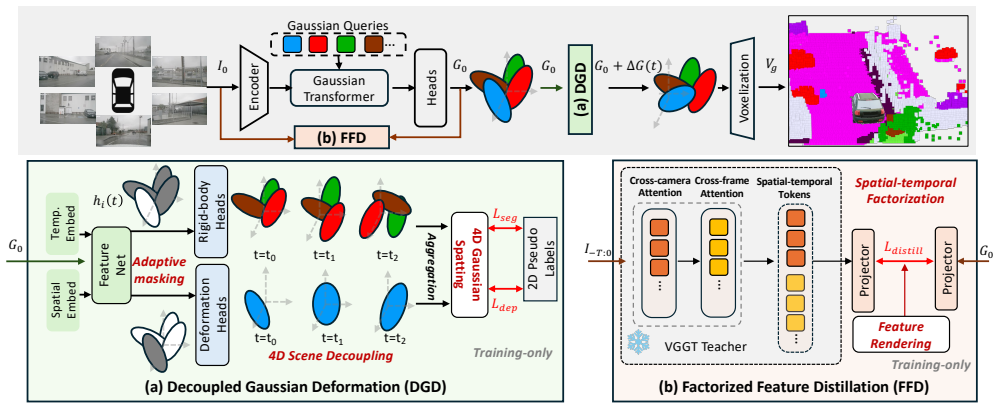
DeGO disentangles rigid and nonrigid motion by allowing each Gaussian primitive to evolve through deformation and offset-based updates, while a factorized 4D distillation strategy transfers cross-camera and cross-frame knowledge from the VGGT foundation model, producing foundation-aligned features that enhance temporal consistency in occupancy modeling.
What carries the argument
Deformable Gaussian primitives that evolve through both deformation and offset-based updates, combined with factorized 4D distillation from a foundation model.
If this is right
- Gaussian primitives can separately handle rigid offsets and nonrigid deformations for finer motion modeling.
- Factorized distillation produces foundation-aligned features that improve temporal coherence across frames and views.
- The combined framework reaches state-of-the-art occupancy prediction under weak supervision on the Occ3D-NuScenes benchmark.
- Performance gains are largest on human-centric instances where nonrigid motion dominates.
Where Pith is reading between the lines
- The same decoupling might apply to other foundation models beyond VGGT for further consistency gains.
- Decoupled motion modeling could support downstream tasks such as trajectory forecasting that require separate rigid and deformable components.
- The method may extend to non-driving domains like robotics where deformable objects interact with rigid ones.
Load-bearing premise
The VGGT foundation model supplies transferable cross-camera and cross-frame knowledge that can be effectively factorized and distilled to enhance temporal consistency.
What would settle it
Remove either the decoupled deformation or the factorized 4D distillation from the model and measure whether the 13.5% gain on human-centric instances and 10.9% overall improvement on Occ3D-NuScenes disappear.
Figures



read the original abstract
Understanding dynamic 3D environments is essential for safe autonomous driving, particularly when reasoning about human-centric, nonrigid agents. However, existing weakly supervised occupancy prediction frameworks predominantly assume rigid-body motion and rely on simple frame-to-frame offsets, limiting their ability to capture fine-grained deformations and maintain temporal coherence. To address this issue, we propose DeGO, a deformable Gaussian occupancy framework that unifies decoupled Gaussian deformation with factorized 4D foundation-model distillation. DeGO disentangles rigid and nonrigid motion, enabling each Gaussian primitive to evolve through both deformation and offset-based updates. In parallel, a factorized 4D distillation strategy transfers cross-camera and cross-frame knowledge from the VGGT foundation model, producing foundation-aligned features that enhance temporal consistency. Experiments on the Occ3D-NuScenes benchmark demonstrate that our method achieves state-of-the-art performance under weak supervision, delivering 13.5% gains on human-centric instances and 10.9% overall improvements. These results highlight the effectiveness of deformation-aware and foundation-guided occupancy modeling for dynamic scene understanding. The code is publicly available: https://github.com/vita-epfl/DeGO
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DeGO, a deformable Gaussian occupancy framework for dynamic 3D scene understanding in autonomous driving. It decouples rigid and nonrigid motion by allowing each Gaussian primitive to evolve via both deformation fields and offset-based updates, while employing a factorized 4D distillation strategy to transfer cross-camera and cross-frame knowledge from the VGGT foundation model for improved temporal consistency. Experiments on the Occ3D-NuScenes benchmark are reported to achieve state-of-the-art performance under weak supervision, with 13.5% gains on human-centric instances and 10.9% overall improvements.
Significance. If the quantitative results hold under proper validation, the work would advance weakly supervised occupancy prediction by explicitly modeling nonrigid deformations, which existing rigid-motion assumptions fail to capture. The public code release supports reproducibility and is a positive contribution.
major comments (1)
- [Abstract and §4] Abstract and §4 (Experiments): The central claims of 13.5% gains on human-centric instances and 10.9% overall improvements on Occ3D-NuScenes are presented without any description of baselines, metrics, error bars, ablation studies, or validation procedures. This absence is load-bearing for the claim of state-of-the-art performance under weak supervision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript to strengthen the presentation of the experimental claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claims of 13.5% gains on human-centric instances and 10.9% overall improvements on Occ3D-NuScenes are presented without any description of baselines, metrics, error bars, ablation studies, or validation procedures. This absence is load-bearing for the claim of state-of-the-art performance under weak supervision.
Authors: We agree that the experimental section would benefit from more explicit and structured descriptions to fully support the reported gains. In the revised manuscript, we will expand §4 to include: (i) a clear enumeration of all baselines with their supervision settings and key implementation details; (ii) the precise evaluation metrics used on Occ3D-NuScenes (e.g., mIoU breakdowns); (iii) any error bars or multi-run statistics; (iv) comprehensive ablation studies on the deformation and distillation components; and (v) a dedicated subsection on the validation protocol, including data splits and weak-supervision assumptions. The abstract will remain a concise summary per convention but will reference the expanded experimental details. These additions will directly address the load-bearing nature of the SOTA claims under weak supervision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and provided context contain no equations, parameter fits, self-citations, or derivation steps that reduce any claimed prediction or result to its inputs by construction. Central performance claims (13.5% and 10.9% gains) are presented as outcomes of experiments on the external Occ3D-NuScenes benchmark under weak supervision, which are independently falsifiable. No load-bearing self-definitional, fitted-input, or uniqueness-imported steps are present or identifiable from the given text. The method description relies on standard modeling choices (Gaussian primitives, distillation from VGGT) without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Simon Boeder, Fabian Gigengack, and Benjamin Risse. Lan- gocc: Self-supervised open vocabulary occupancy estima- tion via volume rendering.arXiv preprint arXiv:2407.17310,
-
[2]
Simon Boeder, Fabian Gigengack, and Benjamin Risse. Gaussianflowocc: Sparse and weakly supervised occupancy estimation using gaussian splatting and temporal flow.arXiv preprint arXiv:2502.17288, 2025. 1, 2, 3, 6
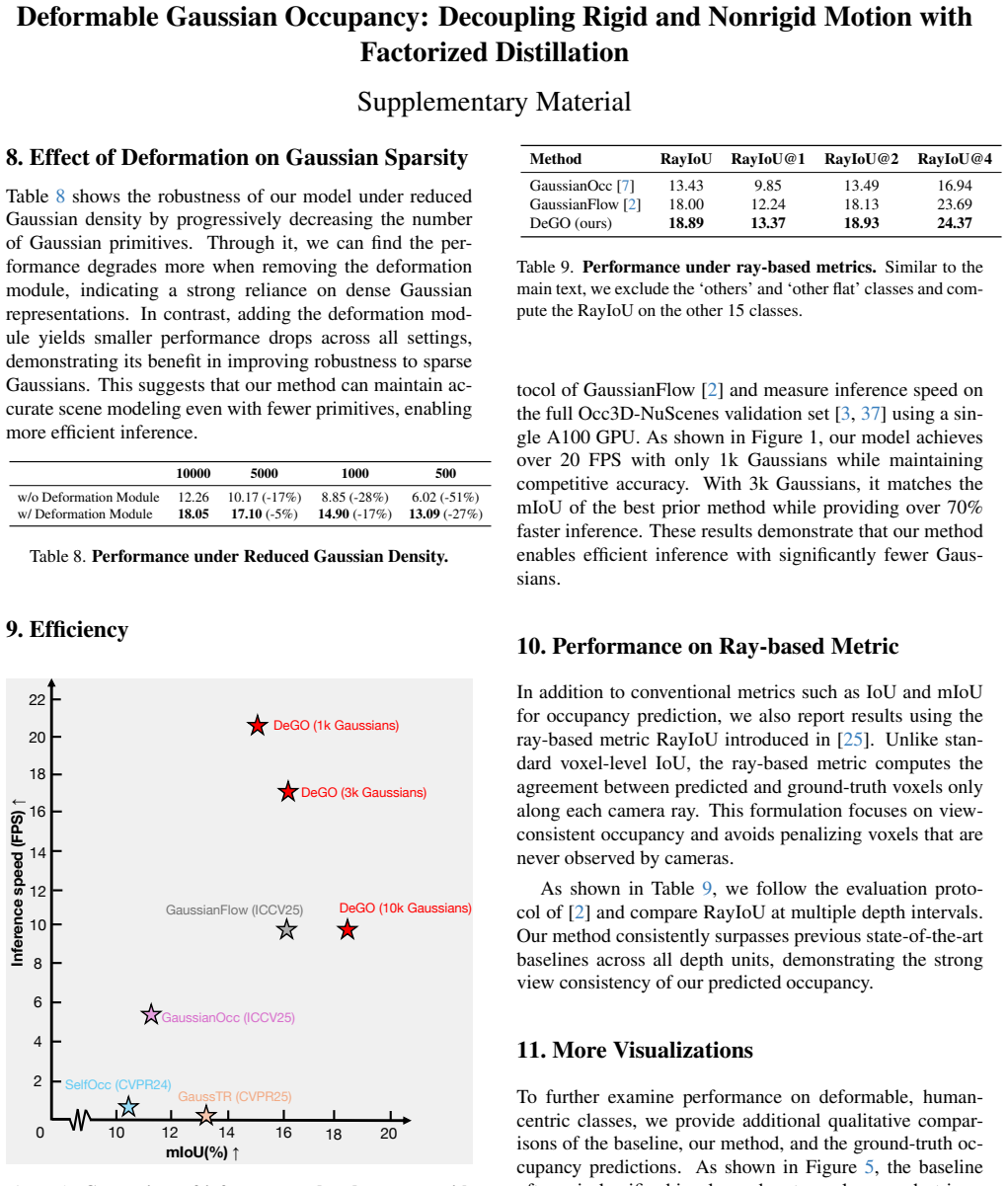
-
[3]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 5, 6, 1
2020
-
[4]
Monoscene: Monoc- ular 3d semantic scene completion
Anh-Quan Cao and Raoul De Charette. Monoscene: Monoc- ular 3d semantic scene completion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3991–4001, 2022. 2
2022
-
[5]
Pasco: Urban 3d panoptic scene completion with uncertainty aware- ness
Anh-Quan Cao, Angela Dai, and Raoul De Charette. Pasco: Urban 3d panoptic scene completion with uncertainty aware- ness. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 14554–14564,
-
[6]
Gaussrender: Learning 3d occupancy with gaussian rendering
Loick Chambon, Eloi Zablocki, Alexandre Boulch, Mick- ael Chen, and Matthieu Cord. Gaussrender: Learning 3d occupancy with gaussian rendering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27010–27020, 2025. 2
2025
-
[7]
Gaussianocc: Fully self-supervised and ef- ficient 3d occupancy estimation with gaussian splatting
Wanshui Gan, Fang Liu, Hongbin Xu, Ningkai Mo, and Naoto Yokoya. Gaussianocc: Fully self-supervised and ef- ficient 3d occupancy estimation with gaussian splatting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 28980–28990, 2025. 1, 2, 6
2025
-
[8]
Multi- transmotion: Pre-trained model for human motion predic- tion
Yang Gao, Po-Chien Luan, and Alexandre Alahi. Multi- transmotion: Pre-trained model for human motion predic- tion. InConference on Robot Learning (CoRL), 2024. 3
2024
-
[9]
Yang Gao, Po-Chien Luan, Kaouther Messaoud, Lan Feng, and Alexandre Alahi. Omnitraj: Pre-training on heteroge- neous data for adaptive and zero-shot human trajectory pre- diction.arXiv preprint arXiv:2507.23657, 2025
-
[10]
Social- pose: Enhancing trajectory prediction with human body pose.IEEE Transactions on Intelligent Transportation Sys- tems, 2025
Yang Gao, Saeed Saadatnejad, and Alexandre Alahi. Social- pose: Enhancing trajectory prediction with human body pose.IEEE Transactions on Intelligent Transportation Sys- tems, 2025. 3
2025
-
[11]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2 https://sportradar.com/
2016
-
[12]
Motionmap: Rep- resenting multimodality in human pose forecasting
Reyhaneh Hosseininejad, Megh Shukla, Saeed Saadatnejad, Mathieu Salzmann, and Alexandre Alahi. Motionmap: Rep- resenting multimodality in human pose forecasting. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 22680–22689, 2025. 1
2025
-
[13]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Junjie Huang, Guan Huang, Zheng Zhu, Yun Ye, and Dalong Du. Bevdet: High-performance multi-camera 3d object de- tection in bird-eye-view.arXiv preprint arXiv:2112.11790,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Tri-perspective view for vision- based 3d semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Tri-perspective view for vision- based 3d semantic occupancy prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9223–9232, 2023. 2
2023
-
[15]
Prob- abilistic gaussian superposition for efficient 3d occupancy prediction.arXiv e-prints, pages arXiv–2412, 2024
Yuanhui Huang, Amonnut Thammatadatrakoon, Wenzhao Zheng, Yunpeng Zhang, Dalong Du, and Jiwen Lu. Prob- abilistic gaussian superposition for efficient 3d occupancy prediction.arXiv e-prints, pages arXiv–2412, 2024. 2
2024
-
[16]
Selfocc: Self-supervised vision-based 3d oc- cupancy prediction
Yuanhui Huang, Wenzhao Zheng, Borui Zhang, Jie Zhou, and Jiwen Lu. Selfocc: Self-supervised vision-based 3d oc- cupancy prediction. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 19946–19956, 2024. 1, 2, 6
2024
-
[17]
Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction. InEuropean Conference on Computer Vision, pages 376–393. Springer,
-
[18]
Sym- phonize 3d semantic scene completion with contextual in- stance queries
Haoyi Jiang, Tianheng Cheng, Naiyu Gao, Haoyang Zhang, Tianwei Lin, Wenyu Liu, and Xinggang Wang. Sym- phonize 3d semantic scene completion with contextual in- stance queries. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20258– 20267, 2024. 2
2024
-
[19]
Gausstr: Foundation model-aligned gaussian transformer for self-supervised 3d spatial understanding
Haoyi Jiang, Liu Liu, Tianheng Cheng, Xinjie Wang, Tian- wei Lin, Zhizhong Su, Wenyu Liu, and Xinggang Wang. Gausstr: Foundation model-aligned gaussian transformer for self-supervised 3d spatial understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11960–11970, 2025. 1, 2, 6
2025
-
[20]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[21]
Wuyang Li, Zhu Yu, and Alexandre Alahi. V oxdet: Rethink- ing 3d semantic occupancy prediction as dense object detec- tion.arXiv preprint arXiv:2506.04623, 2025. 2
-
[22]
V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion
Yiming Li, Zhiding Yu, Christopher Choy, Chaowei Xiao, Jose M Alvarez, Sanja Fidler, Chen Feng, and Anima Anand- kumar. V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9087–9098, 2023. 2
2023
-
[23]
Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2024
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chong- hao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2024. 2
2024
-
[24]
Disen- tangling instance and scene contexts for 3d semantic scene completion
Enyu Liu, En Yu, Sijia Chen, and Wenbing Tao. Disen- tangling instance and scene contexts for 3d semantic scene completion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26999–27009, 2025. 6
2025
-
[25]
Fully sparse 3d occupancy prediction
Haisong Liu, Yang Chen, Haiguang Wang, Zetong Yang, Tianyu Li, Jia Zeng, Li Chen, Hongyang Li, and Limin Wang. Fully sparse 3d occupancy prediction. InEuropean Conference on Computer Vision, pages 54–71. Springer,
-
[26]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Oc- treeocc: Efficient and multi-granularity occupancy predic- tion using octree queries.Advances in Neural Information Processing Systems, 37:79618–79641, 2024
Yuhang Lu, Xinge Zhu, Tai Wang, and Yuexin Ma. Oc- treeocc: Efficient and multi-granularity occupancy predic- tion using octree queries.Advances in Neural Information Processing Systems, 37:79618–79641, 2024. 2
2024
-
[28]
Unified human localization and trajectory pre- diction with monocular vision
Po-Chien Luan, Yang Gao, C ´eline Demonsant, and Alexan- dre Alahi. Unified human localization and trajectory pre- diction with monocular vision. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15037–15044. IEEE, 2025. 1
2025
-
[29]
Camera-based 3d semantic scene completion with sparse guidance network
Jianbiao Mei, Yu Yang, Mengmeng Wang, Junyu Zhu, Jong- won Ra, Yukai Ma, Laijian Li, and Yong Liu. Camera-based 3d semantic scene completion with sparse guidance network. IEEE Transactions on Image Processing, 2024. 2
2024
-
[30]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 1
2021
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Social-transmotion: Promptable human trajectory prediction
Saeed Saadatnejad, Yang Gao, Kaouther Messaoud, and Alexandre Alahi. Social-transmotion: Promptable human trajectory prediction. InInternational Conference on Learn- ing Representations (ICLR), 2024. 3
2024
-
[34]
Occupancy as set of points
Yiang Shi, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Xinggang Wang. Occupancy as set of points. InEuropean Conference on Computer Vision, pages 72–87. Springer,
-
[35]
Semantic scene com- pletion from a single depth image
Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Mano- lis Savva, and Thomas Funkhouser. Semantic scene com- pletion from a single depth image. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 1746–1754, 2017. 2
2017
-
[36]
Sparseocc: Re- thinking sparse latent representation for vision-based seman- tic occupancy prediction
Pin Tang, Zhongdao Wang, Guoqing Wang, Jilai Zheng, Xi- angxuan Ren, Bailan Feng, and Chao Ma. Sparseocc: Re- thinking sparse latent representation for vision-based seman- tic occupancy prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15035–15044, 2024. 2
2024
-
[37]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving.Advances in Neural Information Processing Systems, 36:64318–64330, 2023
Xiaoyu Tian, Tao Jiang, Longfei Yun, Yucheng Mao, Huitong Yang, Yue Wang, Yilun Wang, and Hang Zhao. Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving.Advances in Neural Information Processing Systems, 36:64318–64330, 2023. 5, 6, 1
2023
-
[38]
Mmcm: Multimodality-aware metric using clustering-based modes for probabilistic human motion prediction
Kyotaro Tokoro, Hiromu Taketsugu, and Norimichi Ukita. Mmcm: Multimodality-aware metric using clustering-based modes for probabilistic human motion prediction. InPro- ceedings of the IEEE/CVF Winter Conference on Applica- tions of Computer Vision, pages 2637–2647, 2026. 1
2026
-
[39]
Scene as occupancy
Wenwen Tong, Chonghao Sima, Tai Wang, Li Chen, Silei Wu, Hanming Deng, Yi Gu, Lewei Lu, Ping Luo, Dahua Lin, et al. Scene as occupancy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8406– 8415, 2023. 2
2023
-
[40]
Opus: occupancy prediction using a sparse set
Jiabao Wang, Zhaojiang Liu, Qiang Meng, Liujiang Yan, Ke Wang, Jie Yang, Wei Liu, Qibin Hou, and Ming-Ming Cheng. Opus: occupancy prediction using a sparse set. Advances in Neural Information Processing Systems, 37: 119861–119885, 2024. 2
2024
-
[41]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 6, 7
2025
-
[42]
Letian Wang, Seung Wook Kim, Jiawei Yang, Cunjun Yu, Boris Ivanovic, Steven Waslander, Yue Wang, Sanja Fidler, Marco Pavone, and Peter Karkus. Distillnerf: Perceiving 3d scenes from single-glance images by distilling neural fields and foundation model features.Advances in Neural Infor- mation Processing Systems, 37:62334–62361, 2024. 2, 6
2024
-
[43]
4d gaussian splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 20310–20320, 2024. 2
2024
-
[44]
Zeyu Yang, Hongye Yang, Zijie Pan, and Li Zhang. Real-time photorealistic dynamic scene representation and rendering with 4d gaussian splatting.arXiv preprint arXiv:2310.10642, 2023. 2
-
[45]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaixuan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. InProceedings of the IEEE/CVF international conference on computer vision, pages 9043–9053, 2023. 3
2023
-
[46]
Zichen Yu, Changyong Shu, Jiajun Deng, Kangjie Lu, Zong- dai Liu, Jiangyong Yu, Dawei Yang, Hui Li, and Yan Chen. Flashocc: Fast and memory-efficient occupancy prediction via channel-to-height plugin.arXiv preprint arXiv:2311.12058, 2023. 2
-
[47]
Occnerf: Advancing 3d occupancy prediction in lidar-free environments.IEEE Transactions on Image Processing, 2025
Chubin Zhang, Juncheng Yan, Yi Wei, Jiaxin Li, Li Liu, Yan- song Tang, Yueqi Duan, and Jiwen Lu. Occnerf: Advancing 3d occupancy prediction in lidar-free environments.IEEE Transactions on Image Processing, 2025. 2, 6
2025
-
[48]
Occformer: Dual-path transformer for vision-based 3d semantic occu- pancy prediction
Yunpeng Zhang, Zheng Zhu, and Dalong Du. Occformer: Dual-path transformer for vision-based 3d semantic occu- pancy prediction. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 9433–9443,
-
[49]
Veon: V ocabulary- enhanced occupancy prediction
Jilai Zheng, Pin Tang, Zhongdao Wang, Guoqing Wang, Xi- angxuan Ren, Bailan Feng, and Chao Ma. Veon: V ocabulary- enhanced occupancy prediction. InEuropean Conference on Computer Vision, pages 92–108. Springer, 2024. 2, 6
2024
-
[50]
V oxelsplat: Dynamic gaussian splatting as an effective loss for occupancy and flow predic- tion
Ziyue Zhu, Shenlong Wang, Jin Xie, Jiang-jiang Liu, Jing- dong Wang, and Jian Yang. V oxelsplat: Dynamic gaussian splatting as an effective loss for occupancy and flow predic- tion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6761–6771, 2025. 2 Deformable Gaussian Occupancy: Decoupling Rigid and Nonrigid Motion with Fact...
2025
-
[51]
Through it, we can find the per- formance degrades more when removing the deformation module, indicating a strong reliance on dense Gaussian representations
Effect of Deformation on Gaussian Sparsity Table 8 shows the robustness of our model under reduced Gaussian density by progressively decreasing the number of Gaussian primitives. Through it, we can find the per- formance degrades more when removing the deformation module, indicating a strong reliance on dense Gaussian representations. In contrast, adding ...
-
[52]
Efficiency mIoU(%) ↑1012141618 246810Inference speed (FPS) ↑ SelfOcc (CVPR24) GaussianOcc (ICCV25) GaussTR (CVPR25) GaussianFlow (ICCV25)DeGO (10k Gaussians) 0 20 1214161820 DeGO (3k Gaussians) 22 DeGO (1k Gaussians) Figure 4.Comparison of inference speed and accuracy with state-of-the-art methods on Occ3D-NuScenes validation set. To assess model efficien...
-
[53]
Unlike stan- dard voxel-level IoU, the ray-based metric computes the agreement between predicted and ground-truth voxels only along each camera ray
Performance on Ray-based Metric In addition to conventional metrics such as IoU and mIoU for occupancy prediction, we also report results using the ray-based metric RayIoU introduced in [25]. Unlike stan- dard voxel-level IoU, the ray-based metric computes the agreement between predicted and ground-truth voxels only along each camera ray. This formulation...
-
[54]
As shown in Figure 5, the baseline often misclassifies bicycles and motorcycles as pedestrians
More Visualizations To further examine performance on deformable, human- centric classes, we provide additional qualitative compar- isons of the baseline, our method, and the ground-truth oc- cupancy predictions. As shown in Figure 5, the baseline often misclassifies bicycles and motorcycles as pedestrians. Although these categories can appear visually si...
-
[55]
The deformation module is configured with 32 temporal channels, a positional encoding level of 6, and a time-encoding level of 4
Implementation Details We use a ResNet-50 [11] image encoder and a Gaussian Transformer consisting of three blocks with a hidden di- mension of 256. The deformation module is configured with 32 temporal channels, a positional encoding level of 6, and a time-encoding level of 4. The feature network is a 6- layer MLP, and the 4D Gaussian prediction heads ar...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.