Satisfiability Solving with LLMs: A Matched-Pair Evaluation of Reasoning Capability
Pith reviewed 2026-06-29 11:47 UTC · model grok-4.3
The pith
Paired SAT instances with Accurate Differentiation Rate distinguish genuine LLM reasoning from heuristic shortcuts missed by standard metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
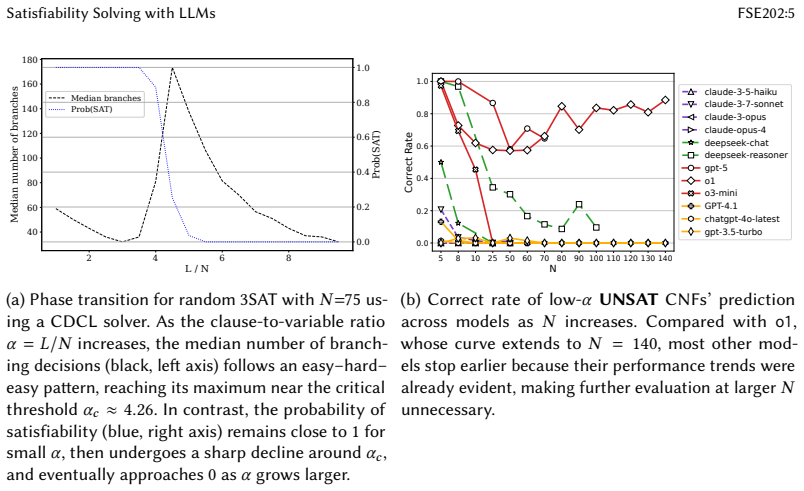
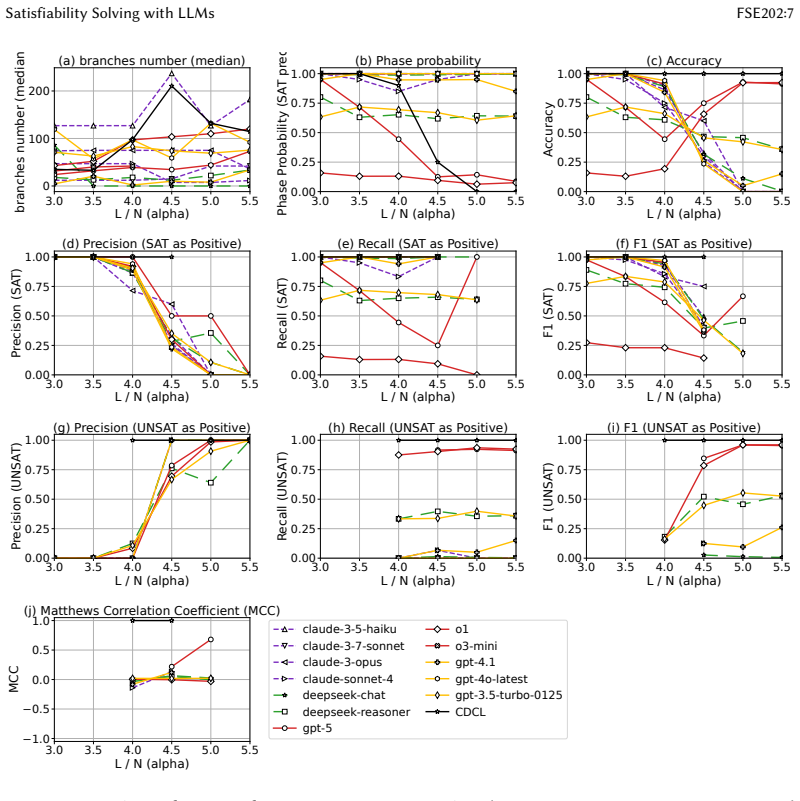
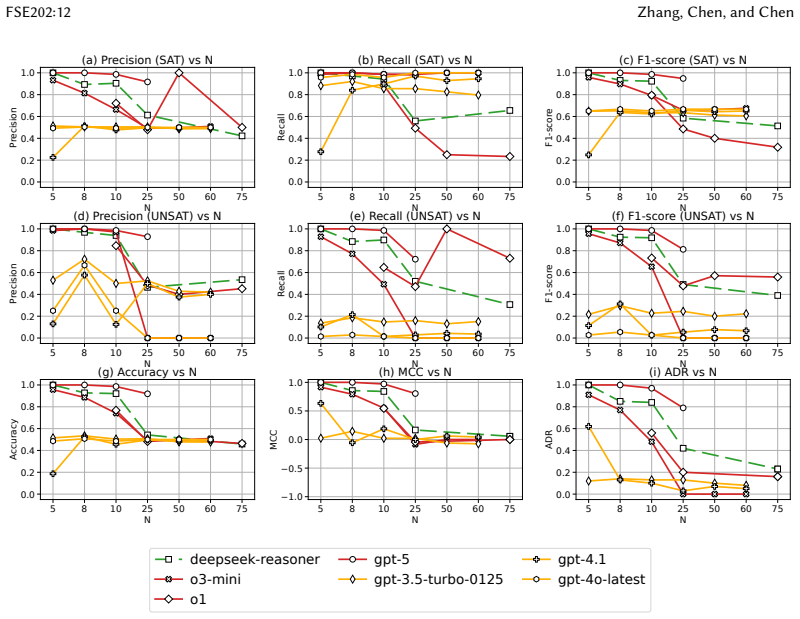
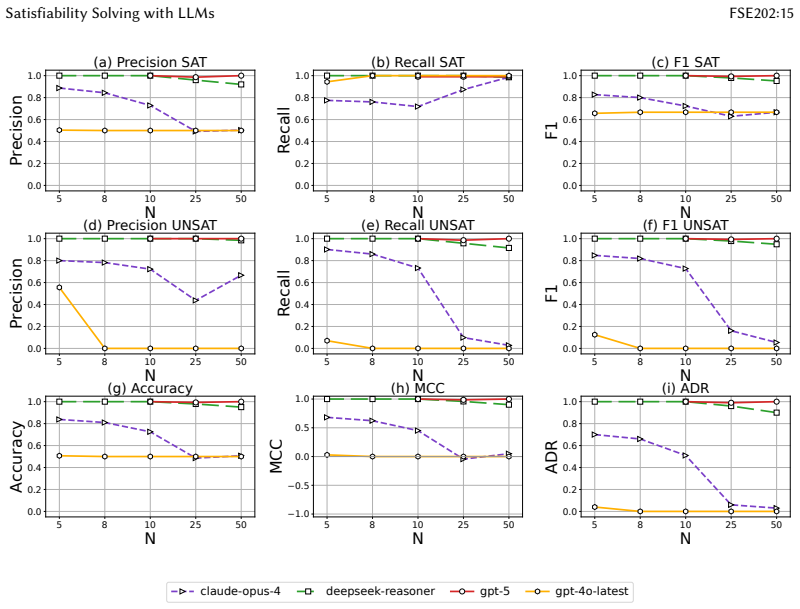
Conventional metrics can be misleading because models obtain high scores by over-predicting satisfiable formulas, fail to reproduce the easy-hard-easy signature around the 3-SAT threshold, and degrade as the number of variables grows. A paired-formula protocol using minimally different satisfiable and unsatisfiable instances together with Accurate Differentiation Rate requires both members of each pair to be classified correctly; this measure separates reasoning-oriented models from heuristic ones, correlates with witness validity, and reveals that model decisions on CNF and converted Vertex Cover or 3D packing instances agree for most models on more than 80 percent of cases.
What carries the argument
Accurate Differentiation Rate (ADR) on minimally different satisfiable-unsatisfiable pairs, which scores a model only when both formulas receive the correct label.
If this is right
- ADR identifies models whose decisions remain stable when the same logical problem is presented in CNF, graph, or packing form.
- Models achieving high ADR also produce valid witnesses more frequently than models that fail the paired test.
- Standard accuracy metrics allow inflated scores from biased predictions that the paired protocol detects and penalizes.
- Performance on SAT instances declines with growing variable count and does not exhibit the classical phase-transition pattern.
- SAT problems serve as a conservative probe that exposes limitations conventional benchmarks overlook.
Where Pith is reading between the lines
- The same paired-construction method could be applied to other constraint problems to test whether decision rules transfer across encodings.
- If ADR continues to correlate with witness validity on larger instances, the metric may predict reliability on industrial scheduling or verification tasks.
- Models that maintain high cross-representation agreement may be learning logical invariants rather than surface statistics of any single encoding.
Load-bearing premise
Correct classification of both members of each minimally different satisfiable-unsatisfiable pair indicates genuine reasoning rather than exploitation of superficial cues from pair construction.
What would settle it
A new collection of paired instances built with a different minimal-difference method in which models that scored high on ADR produce invalid witnesses or drop below 80 percent cross-representation agreement.
Figures
read the original abstract
Large language models (LLMs) are increasingly used for tasks that implicitly reduce to Boolean satisfiability (SAT), yet their reasoning ability on SAT remains unclear. We present a systematic study of LLMs on 2-SAT and 3-SAT, together with two canonical reductions, Vertex Cover and discrete 3D packing, to probe representation-invariant reasoning. We first evaluate models using conventional metrics, including accuracy, precision, recall, and F1, as well as the SAT phase-transition setting. We find that these metrics can be misleading: many models obtain high scores by over-predicting satisfiable formulas, fail to reproduce the classical easy-hard-easy signature around the 3-SAT threshold, and degrade sharply as the number of variables grows. To address this problem, we introduce a paired-formula protocol based on minimally different satisfiable and unsatisfiable instances, together with Accurate Differentiation Rate (ADR), which requires both members of each pair to be classified correctly. ADR separates reasoning-oriented models from heuristic ones and correlates with witness validity. Beyond CNF, we test cross-representation consistency by converting CNF to Vertex Cover and 3-SAT to discrete 3D packing. Model decisions on CNF and on the corresponding graph or packing instances agree for most models on more than 80 percent of instances, suggesting stable decision rules across representations. Overall, our results show that SAT is a conservative probe for LLM reasoning, and that paired evaluation with ADR provides a more faithful and representation-robust assessment than conventional metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates LLMs on 2-SAT and 3-SAT instances plus reductions to Vertex Cover and discrete 3D packing. It argues that standard metrics (accuracy, F1, phase-transition behavior) are misleading because models over-predict satisfiability and fail to reproduce the easy-hard-easy pattern. It introduces a paired-formula protocol using minimally different satisfiable/unsatisfiable pairs and the Accurate Differentiation Rate (ADR) metric, which requires correct classification of both pair members, claiming this better isolates reasoning, separates model classes, correlates with witness validity, and yields >80% decision agreement when CNF instances are converted to the other representations.
Significance. If the paired protocol is free of construction artifacts, the work supplies a more faithful empirical probe of LLM reasoning on SAT than conventional metrics, together with evidence of representation-stable decisions. The study uses fresh paired data with no equations fitted from the test set and reports a concrete cross-representation agreement figure, both of which strengthen the assessment.
major comments (2)
- [Abstract / paired-formula protocol] Abstract and paired-protocol description: the central claim that ADR measures genuine reasoning (rather than detection of pair-construction artifacts) is load-bearing, yet the manuscript supplies no explicit definition of the modification operator that produces 'minimally different' pairs (clause addition/removal, literal flip, variable-count change, etc.) nor any statistical verification that the resulting pairs lack detectable regularities such as clause-length histograms or polarity bias.
- [Abstract] Abstract: the reported >80% cross-representation agreement is presented without sample sizes, confidence intervals, model identifiers, or the exact pair-construction algorithm, preventing independent verification of either the ADR results or the consistency claim.
minor comments (1)
- [Abstract] The acronym ADR is introduced without expansion on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve explicitness and verifiability.
read point-by-point responses
-
Referee: [Abstract / paired-formula protocol] Abstract and paired-protocol description: the central claim that ADR measures genuine reasoning (rather than detection of pair-construction artifacts) is load-bearing, yet the manuscript supplies no explicit definition of the modification operator that produces 'minimally different' pairs (clause addition/removal, literal flip, variable-count change, etc.) nor any statistical verification that the resulting pairs lack detectable regularities such as clause-length histograms or polarity bias.
Authors: We agree that the manuscript must supply an explicit definition of the modification operator and statistical checks for artifacts to support the claim that ADR isolates reasoning. The current text describes pairs only as 'minimally different' without detailing the operator or providing bias verification. In revision we will add a precise description of the operator (specifying operations such as single-clause addition or literal negation) together with statistical comparisons of clause-length distributions, polarity counts, and variable counts between pair members. These additions will be placed in both the abstract and the paired-protocol section. revision: yes
-
Referee: [Abstract] Abstract: the reported >80% cross-representation agreement is presented without sample sizes, confidence intervals, model identifiers, or the exact pair-construction algorithm, preventing independent verification of either the ADR results or the consistency claim.
Authors: We accept that the abstract must include or clearly reference these details for independent verification. The main text already reports per-model sample sizes, agreement percentages, and the underlying instance counts, but the abstract does not. We will revise the abstract to state the total number of pairs evaluated, the models tested, the reported agreement with its confidence interval, and a pointer to the now-expanded pair-construction description. This change will make the consistency claim verifiable from the abstract alone. revision: yes
Circularity Check
Empirical study defines new paired metric on fresh data with no reduction of outcomes to fitted inputs
full rationale
The paper is a standard empirical evaluation that generates paired SAT instances, applies conventional and new ADR metrics, and reports observed accuracies and cross-representation agreement rates. No equations, parameter fits, or derivations are present that would make reported results equivalent to inputs by construction. The ADR definition is a straightforward requirement that both pair members be classified correctly; it does not smuggle in any self-referential prediction or rely on self-citations for its justification. Claims about separating reasoning models rest on the experimental outcomes rather than on any definitional equivalence. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Correct classification of both members of a minimally different satisfiable-unsatisfiable pair indicates reasoning rather than heuristic pattern matching.
- domain assumption Agreement between decisions on CNF and converted Vertex Cover or 3D packing instances measures representation-invariant reasoning.
Reference graph
Works this paper leans on
-
[1]
Aho, Monica S
Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman. 2007.Compilers: Principles, Techniques, and Tools. Pearson. Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE202. Publication date: July 2026. Satisfiability Solving with LLMs FSE202:21
2007
-
[2]
Bengt Aspvall, Michael F Plass, and Robert Endre Tarjan. 1979. A linear-time algorithm for testing the truth of certain quantified boolean formulas.Information processing letters8, 3 (1979), 121–123
1979
- [3]
-
[4]
Ryan Beckett, Aarti Gupta, Ratul Mahajan, and David Walker. 2017. A general approach to network configuration verification. InProceedings of the Conference of the ACM Special Interest Group on Data Communication. 155–168. doi:10.1145/3098822.3098834
-
[5]
Al Bessey, Ken Block, Ben Chelf, Andy Chou, Bryan Fulton, Seth Hallem, Charles Henri-Gros, Asya Kamsky, Scott McPeak, and Dawson Engler. 2010. A few billion lines of code later: using static analysis to find bugs in the real world. Commun. ACM53, 2 (2010), 66–75. doi:10.1145/1646353.1646374
-
[6]
Armin Biere, Alessandro Cimatti, Edmund M Clarke, Ofer Strichman, and Yunshan Zhu. 2009. Bounded model checking. Vol. 185. 457–481
2009
-
[7]
Cristiano Calcagno, Dino Distefano, Jérémy Dubreil, Dominik Gabi, Pieter Hooimeijer, Martino Luca, Peter O’Hearn, Irene Papakonstantinou, Jim Purbrick, and Dulma Rodriguez. 2015. Moving fast with software verification. InNASA Formal Methods Symposium. Springer, 3–11
2015
-
[8]
Saikat Chakraborty, Shuvendu Lahiri, Sarah Fakhoury, Akash Lal, Madanlal Musuvathi, Aseem Rastogi, Aditya Senthilnathan, Rahul Sharma, and Nikhil Swamy. 2023. Ranking llm-generated loop invariants for program verification. (2023), 9164–9175
2023
-
[9]
Xiao Cheng, Haoyu Wang, Jiayi Hua, Guoai Xu, and Yulei Sui. 2021. Deepwukong: Statically detecting software vulnerabilities using deep graph neural network.ACM Transactions on Software Engineering and Methodology (TOSEM) 30, 3 (2021), 1–33. doi:10.1145/3436877
-
[10]
Davide Chicco and Giuseppe Jurman. 2020. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation.BMC genomics21, 1 (2020), 6
2020
-
[11]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D Manning. 2019. What does BERT look at? an analysis of BERT’s attention. (2019), 276–286
2019
-
[12]
Stephen A Cook. 2023. The complexity of theorem-proving procedures. InLogic, automata, and computational complexity: The works of Stephen A. Cook. 143–152
2023
-
[13]
Joseph Culberson and Ian Gent. 2001. Frozen development in graph coloring.Theoretical computer science265, 1-2 (2001), 227–264
2001
-
[14]
Martin Davis, George Logemann, and Donald Loveland. 1962. A machine program for theorem-proving.Commun. ACM5, 7 (1962), 394–397. doi:10.1145/368273.368557
- [15]
-
[16]
Niklas Eén and Niklas Sörensson. 2003. An extensible SAT-solver. InInternational conference on theory and applications of satisfiability testing. Springer, 502–518
2003
- [17]
-
[18]
Shimon Even, Alon Itai, and Adi Shamir. 1975. On the complexity of time table and multi-commodity flow problems. (1975), 184–193
1975
-
[19]
Sándor P Fekete and Jörg Schepers. 2004. A combinatorial characterization of higher-dimensional orthogonal packing. Mathematics of Operations Research29, 2 (2004), 353–368
2004
-
[20]
Thomas A Henzinger, Ranjit Jhala, Rupak Majumdar, and Gregoire Sutre. 2002. Lazy abstraction. InProceedings of the 29th ACM SIGPLAN-SIGACT symposium on Principles of programming languages. 58–70
2002
-
[21]
Holger H Hoos and Thomas Stützle. 2000. SATLIB: An online resource for research on SAT.Sat2000 (2000), 283–292
2000
-
[22]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79. doi:10.1145/3695988
-
[23]
Christian Janßen, Cedric Richter, and Heike Wehrheim. 2024. Can ChatGPT support software verification?. In International Conference on Fundamental Approaches to Software Engineering. Springer, 266–279
2024
-
[24]
Richard M Karp. 2009. Reducibility among combinatorial problems. In50 Years of Integer Programming 1958-2008: from the Early Years to the State-of-the-Art. Springer, 219–241
2009
-
[25]
Henry Kautz and Bart Selman. 1996. Pushing the envelope: Planning, propositional logic, and stochastic search. In Proceedings of the national conference on artificial intelligence. 1194–1201. Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE202. Publication date: July 2026. FSE202:22 Zhang, Chen, and Chen
1996
-
[26]
Scott Kirkpatrick and Bart Selman. 1994. Critical behavior in the satisfiability of random boolean expressions.Science 264, 5163 (1994), 1297–1301
1994
-
[27]
Zhen Li, Deqing Zou, Shouhuai Xu, Xinyu Ou, Hai Jin, Sujuan Wang, Zhijun Deng, and Yuyi Zhong. 2018. VulDeePecker: A deep learning-based system for vulnerability detection.arXiv preprint arXiv:1801.01681
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. Starcoder 2 and the stack v2: The next generation
2024
-
[29]
2008.Introduction to information retrieval
Christopher D Manning. 2008.Introduction to information retrieval. Syngress Publishing
2008
-
[30]
Joao P Marques-Silva and Karem A Sakallah. 2002. GRASP: A search algorithm for propositional satisfiability.IEEE Transactions on computers48, 5 (2002), 506–521. doi:10.1109/12.769433
-
[31]
Brian W Matthews. 1975. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochimica et Biophysica Acta (BBA)-Protein Structure405, 2 (1975), 442–451
1975
-
[32]
David Mitchell, Bart Selman, Hector Levesque, et al. 1992. Hard and easy distributions of SAT problems. InAAAI, Vol. 92. 459–465
1992
-
[33]
Matthew W Moskewicz, Conor F Madigan, Ying Zhao, Lintao Zhang, and Sharad Malik. 2001. Chaff: Engineering an efficient SAT solver. InProceedings of the 38th annual Design Automation Conference. 530–535
2001
-
[34]
Kexin Pei, David Bieber, Kensen Shi, Charles Sutton, and Pengcheng Yin. 2023. Can large language models reason about program invariants?. InInternational Conference on Machine Learning. PMLR, 27496–27520
2023
-
[35]
Muhammad AA Pirzada, Giles Reger, Ahmed Bhayat, and Lucas C Cordeiro. 2024. Llm-generated invariants for bounded model checking without loop unrolling. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1395–1407. doi:10.1145/3691620.3695512
- [36]
-
[37]
Ganesan Ramalingam. 1994. The undecidability of aliasing.ACM Transactions on Programming Languages and Systems (TOPLAS)16, 5 (1994), 1467–1471. doi:10.1145/186025.186041
-
[38]
Mubashar Raza, Zarmina Jahangir, Muhammad Bilal Riaz, Muhammad Jasim Saeed, and Muhammad Awais Sattar
-
[39]
Industrial applications of large language models.Scientific Reports15, 1 (2025), 13755
2025
- [40]
-
[41]
Umesh Shankar, Kunal Talwar, Jeffrey S Foster, and David Wagner. 2001. Detecting format string vulnerabilities with type qualifiers. In10th USENIX Security Symposium (USENIX Security 01)
2001
-
[42]
Robert Tarjan. 1972. Depth-first search and linear graph algorithms.SIAM journal on computing1, 2 (1972), 146–160
1972
-
[43]
Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. 2022. Efficient transformers: A survey.Comput. Surveys 55, 6 (2022), 1–28
2022
-
[44]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
- [45]
-
[46]
Mark N Wegman and F Kenneth Zadeck. 1991. Constant propagation with conditional branches.ACM Transactions on Programming Languages and Systems (TOPLAS)13, 2 (1991), 181–210. doi:10.1145/103135.103136
-
[47]
Cheng Wen, Jialun Cao, Jie Su, Zhiwu Xu, Shengchao Qin, Mengda He, Haokun Li, Shing-Chi Cheung, and Cong Tian. 2024. Enchanting program specification synthesis by large language models using static analysis and program verification. InInternational Conference on Computer Aided Verification. Springer, 302–328. doi:10.1007/978-3-031- 65630-9_16
- [48]
-
[49]
Yichen Xie and Alex Aiken. 2005. Scalable error detection using boolean satisfiability. InProceedings of the 32nd ACM SIGPLAN-SIGACT symposium on Principles of programming languages. 351–363. doi:10.1145/1040305.1040334
-
[50]
Takayuki Yato and Takahiro Seta. 2003. Complexity and completeness of finding another solution and its application to puzzles.IEICE transactions on fundamentals of electronics, communications and computer sciences86, 5 (2003), 1052–1060
2003
-
[51]
Leizhen Zhang, Shuhan Chen, and Sheng Chen. 2026. Evaluating Satisfiability Solving with LLMs. doi:10.5281/zenodo. 19524484
-
[52]
Da Zheng, Lun Du, Junwei Su, Yuchen Tian, Yuqi Zhu, Jintian Zhang, Lanning Wei, Ningyu Zhang, and Huajun Chen
-
[53]
Knowledge augmented complex problem solving with large language models: A survey
-
[54]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks.Advances in neural information processing Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE202. Publication date: July 2026. Satisfiability Solving with LLMs FSE202...
2019
-
[55]
Deqing Zou, Sujuan Wang, Shouhuai Xu, Zhen Li, and Hai Jin. 2019. 𝜇VulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection.IEEE Transactions on Dependable and Secure Computing18, 5 (2019), 2224–2236. doi:10.1109/TDSC.2019.2942930 Received 2025-09-04; accepted 2026-03-24 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE202. Publ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.