Online Irregular Multivariate Time Series Forecasting via Uncertainty-Driven Dual-Expert Calibration
Pith reviewed 2026-06-29 14:22 UTC · model grok-4.3
The pith
Uncertainty estimates route samples between dual experts to adapt a frozen forecasting model for online irregular multivariate time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
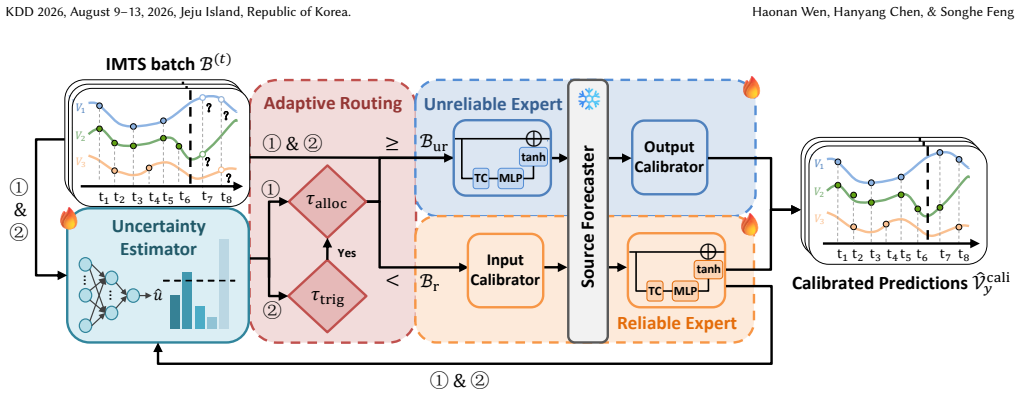
Under-Cali is an uncertainty-driven dual-expert calibration framework for online IMTS forecasting. An uncertainty estimator acts as the central control signal that first evaluates each batch. The adaptive routing module then sends high-uncertainty samples to the unreliable expert for calibration and low-uncertainty samples to the reliable expert. The system subsequently updates the reliable expert and the uncertainty estimator using well-calibrated samples while updating the unreliable expert with difficult samples, all while the source forecasting model remains frozen. This produces stable, efficient online adaptation through a model-agnostic lightweight module.
What carries the argument
The uncertainty estimator that jointly controls inference and adaptation by routing batches to a reliable expert or an unreliable expert for selective updates.
If this is right
- The source forecasting model can remain frozen while adaptation occurs only in the lightweight dual-expert module.
- High-uncertainty samples receive calibration from the unreliable expert while low-uncertainty samples reinforce the reliable expert.
- Updates to the reliable expert and uncertainty estimator use only well-calibrated samples, preserving stability.
- The framework remains model-agnostic and adds only modest computational overhead during online operation.
- Consistent accuracy gains appear across standard IMTS benchmark datasets.
Where Pith is reading between the lines
- The same uncertainty-routing pattern could apply to online adaptation in other irregularly sampled domains such as event streams or sensor networks.
- If uncertainty estimates become more accurate, the separation between reliable and unreliable experts might sharpen further without extra design changes.
- The dual-expert split offers a template for lightweight online calibration in non-time-series tasks that also face distribution drift.
Load-bearing premise
Uncertainty estimates from the estimator can reliably decide routing and produce stable expert updates without any changes to the base forecasting model.
What would settle it
Run the IMTS benchmarks with the uncertainty estimator replaced by random routing decisions and check whether the reported performance gains disappear or reverse.
Figures
read the original abstract
Irregular multivariate time series forecasting is critical in many real-world applications, where time series are irregularly sampled and exhibit dynamically evolving missingness patterns. Although existing methods perform well in offline settings, they often suffer from significant performance degradation when deployed online due to dynamic shifts in data distribution. Maintaining forecasting capability in such dynamic scenarios typically necessitates online adaptation techniques. Since irregular sampling fundamentally undermines temporal continuity and periodicity, we cannot leverage these widely studied characteristics from regular MTS for online learning. To this end, we study the problem of online IMTS forecasting and propose Under-Cali, an uncertainty-driven dual-expert calibration framework consisting of three core components: an uncertainty estimator, a dual-expert calibration module, and an adaptive routing module. We design an uncertainty estimator that serves as the core control signal to jointly manage inference and adaptation processes. In our framework, the uncertainty estimator first assesses uncertainty for each incoming batch. The adaptive routing module then directs samples with high uncertainty to the unreliable expert for calibration, while low uncertainty samples remain with the reliable expert. Subsequently, the system updates the reliable expert and the uncertainty estimator using well-calibrated reliable samples, and updates the unreliable expert with challenging samples, enabling stable and efficient online learning. Under-Cali keeps the source forecasting model frozen and performs adaptation only through a lightweight, model-agnostic calibration module, enabling efficient adaptation. Extensive experiments on IMTS benchmarks demonstrate consistent improvements with low computational cost. Our code is available at https://github.com/HaonanWen/Under-Cali.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Under-Cali, an uncertainty-driven dual-expert calibration framework for online irregular multivariate time series (IMTS) forecasting. It keeps the source forecasting model frozen and performs adaptation via a lightweight, model-agnostic module with three components: an uncertainty estimator that assesses incoming batches, an adaptive routing module that directs high-uncertainty samples to an unreliable expert and low-uncertainty samples to a reliable expert, and dual-expert updates where reliable samples update the reliable expert plus the estimator while challenging samples update the unreliable expert. The approach claims to enable stable, efficient online learning under dynamic missingness patterns, with experiments on IMTS benchmarks showing consistent improvements at low computational cost.
Significance. If the uncertainty-driven routing and selective updates prove stable without degrading the frozen base model, the framework could provide a practical, model-agnostic solution for online IMTS adaptation in domains with evolving distributions, where standard online learning fails due to irregular sampling. The emphasis on keeping the source model frozen and using only lightweight calibration is a potential strength for deployment efficiency if empirically validated.
major comments (2)
- [Framework description (§3)] Framework description (abstract and §3): The central mechanism requires the uncertainty estimator to produce reliable routing signals from the initial batches onward to avoid corrupting the dual experts, yet no initialization, pre-training step, or regularization is described that would secure accurate uncertainty estimates before any updates occur under evolving missingness. This bootstrap issue is load-bearing for the stability claim.
- [Experimental section (§4)] Experimental validation (abstract and §4): The claims of 'consistent improvements' and 'low computational cost' on IMTS benchmarks are stated without any reported metrics, baselines, error bars, ablation results, or statistical tests in the provided text, preventing assessment of whether the dual-expert calibration actually outperforms alternatives.
minor comments (1)
- [Abstract] The GitHub link for code is provided, which supports reproducibility; ensure the released code includes the exact initialization procedure for the uncertainty estimator once added.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below and will revise the manuscript to incorporate clarifications and additional details where needed.
read point-by-point responses
-
Referee: [Framework description (§3)] Framework description (abstract and §3): The central mechanism requires the uncertainty estimator to produce reliable routing signals from the initial batches onward to avoid corrupting the dual experts, yet no initialization, pre-training step, or regularization is described that would secure accurate uncertainty estimates before any updates occur under evolving missingness. This bootstrap issue is load-bearing for the stability claim.
Authors: We agree that the bootstrap issue for the uncertainty estimator is important for ensuring reliable routing signals from the outset. The submitted manuscript does not describe an explicit initialization, pre-training, or regularization procedure for the uncertainty estimator. In the revised version, we will add a dedicated subsection in §3 detailing the initialization strategy (e.g., a short warm-up phase on initial batches or pre-training the estimator on source-domain data) to secure accurate estimates before online updates begin under dynamic missingness. revision: yes
-
Referee: [Experimental section (§4)] Experimental validation (abstract and §4): The claims of 'consistent improvements' and 'low computational cost' on IMTS benchmarks are stated without any reported metrics, baselines, error bars, ablation results, or statistical tests in the provided text, preventing assessment of whether the dual-expert calibration actually outperforms alternatives.
Authors: We acknowledge that the provided text does not include the specific quantitative metrics, baselines, error bars, ablation results, or statistical tests needed to fully evaluate the claims. Although the manuscript references extensive experiments, we will revise §4 to explicitly report all required details (including tables with metrics, comparisons to baselines, error bars, ablations, and statistical significance tests) so that the performance improvements and computational efficiency can be properly assessed. revision: yes
Circularity Check
No circularity in framework proposal
full rationale
The paper proposes Under-Cali as a new conceptual framework with an uncertainty estimator, dual-expert calibration module, and adaptive routing module. No equations, parameter-fitting procedures, or self-citations are described that would reduce the claimed online adaptation or performance improvements to quantities defined by their own inputs. The central claim of lightweight, model-agnostic calibration with the base model frozen is presented as an independent design choice rather than a self-referential derivation, rendering the method self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Oren Anava, Elad Hazan, Shie Mannor, and Ohad Shamir. 2013. Online learning for time series prediction. InConference on learning theory. PMLR, 172–184
2013
-
[2]
Marin Biloš, Johanna Sommer, Syama Sundar Rangapuram, Tim Januschowski, and Stephan Günnemann. 2021. Neural flows: Efficient alternative to neural ODEs.Advances in neural information processing systems34 (2021), 21325–21337
2021
-
[3]
Zhengping Che, Sanjay Purushotham, Kyunghyun Cho, David Sontag, and Yan Liu. 2018. Recurrent neural networks for multivariate time series with missing values.Scientific reports8, 1 (2018), 6085
2018
-
[4]
Ranak Roy Chowdhury, Jiacheng Li, Xiyuan Zhang, Dezhi Hong, Rajesh K Gupta, and Jingbo Shang. 2023. Primenet: Pre-training for irregular multivariate time series. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 7184–7192
2023
-
[5]
Edward De Brouwer, Jaak Simm, Adam Arany, and Yves Moreau. 2019. GRU- ODE-Bayes: Continuous modeling of sporadically-observed time series.Advances in neural information processing systems32 (2019)
2019
-
[6]
Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. Ininternational conference on machine learning. PMLR, 1050–1059
2016
-
[7]
Jindong Han, Weijia Zhang, Hao Liu, Tao Tao, Naiqiang Tan, and Hui Xiong
-
[8]
Bigst: Linear complexity spatio-temporal graph neural network for traffic forecasting on large-scale road networks.Proceedings of the VLDB Endowment 17, 5 (2024), 1081–1090
2024
-
[9]
Max Horn, Michael Moor, Christian Bock, Bastian Rieck, and Karsten Borg- wardt. 2020. Set functions for time series. InInternational Conference on Machine Learning. PMLR, 4353–4363
2020
-
[10]
AE Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Moham- mad Ghassemi, Benjamin Moody, Peter Szolovits, L Anthony Celi, and Roger G Mark. 2016. MIMIC-III, a freely accessible critical care database, Sci.Data3, 1 (2016), 1–9
2016
-
[11]
HyunGi Kim, Siwon Kim, Jisoo Mok, and Sungroh Yoon. 2025. Battling the non- stationarity in time series forecasting via test-time adaptation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 17868–17876
2025
-
[12]
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. 2020. Reformer: The efficient transformer.arXiv preprint arXiv:2001.04451(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
Ying-yee Ava Lau, Zhiwen Shao, and Dit-Yan Yeung. 2025. Fast and Slow Streams for Online Time Series Forecasting Without Information Leakage. InThe Thir- teenth International Conference on Learning Representations
2025
-
[14]
Boyuan Li, Zhen Liu, Yicheng Luo, and Qianli Ma. 2026. Learning Recursive Multi-Scale Representations for Irregular Multivariate Time Series Forecasting. InInternational Conference on Learning Representations
2026
-
[15]
Boyuan Li, Yicheng Luo, Zhen Liu, Junhao Zheng, Jianming Lv, and Qianli Ma
- [16]
-
[17]
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. 2023. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [18]
-
[19]
Yicheng Luo, Zhen Liu, Linghao Wang, Binquan Wu, Junhao Zheng, and Qianli Ma. 2024. Knowledge-empowered dynamic graph network for irregularly sam- pled medical time series.Advances in Neural Information Processing Systems37 (2024), 67172–67199
2024
-
[20]
Yicheng Luo, Bowen Zhang, Zhen Liu, and Qianli Ma. [n. d.]. Hi-Patch: Hi- erarchical Patch GNN for Irregular Multivariate Time Series. InForty-second International Conference on Machine Learning
-
[21]
Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, Nov (2008), 2579–2605
2008
-
[22]
2016.Long-term daily and monthly climate records from stations across the contiguous United States (US Historical Climatology Network)
MJ Menne, CN Williams Jr, and RS Vose. 2016.Long-term daily and monthly climate records from stations across the contiguous United States (US Historical Climatology Network). Technical Report. Environmental System Science Data Infrastructure for a Virtual Ecosystem
2016
-
[23]
Giangiacomo Mercatali, Andre Freitas, and Jie Chen. 2024. Graph neural flows for unveiling systemic interactions among irregularly sampled time series.Advances in Neural Information Processing Systems37 (2024), 57183–57206
2024
-
[24]
Y Nie. 2022. A Time Series is Worth 64Words: Long-term Forecasting with Transformers.arXiv preprint arXiv:2211.14730(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [25]
-
[26]
Yulia Rubanova, Ricky TQ Chen, and David K Duvenaud. 2019. Latent ordinary differential equations for irregularly-sampled time series.Advances in neural information processing systems32 (2019)
2019
-
[27]
Mona Schirmer, Mazin Eltayeb, Stefan Lessmann, and Maja Rudolph. 2022. Mod- eling irregular time series with continuous recurrent units. InInternational con- ference on machine learning. PMLR, 19388–19405
2022
-
[28]
Zongjiang Shang, Ling Chen, Binqing Wu, and Dongliang Cui. 2024. Ada- MSHyper: adaptive multi-scale hypergraph transformer for time series forecast- ing.Advances in Neural Information Processing Systems37 (2024), 33310–33337
2024
- [29]
- [30]
-
[31]
Ikaro Silva, George Moody, Daniel J Scott, Leo A Celi, and Roger G Mark. 2012. Predicting in-hospital mortality of icu patients: The physionet/computing in cardiology challenge 2012. In2012 computing in cardiology. IEEE, 245–248
2012
-
[32]
Roberto Vio, María Diaz-Trigo, and Paola Andreani. 2013. Irregular time series in astronomy and the use of the Lomb–Scargle periodogram.Astronomy and Computing1 (2013), 5–16
2013
-
[33]
Qingsong Wen, Weiqi Chen, Liang Sun, Zhang Zhang, Liang Wang, Rong Jin, Tieniu Tan, et al. 2023. Onenet: Enhancing time series forecasting models under concept drift by online ensembling.Advances in Neural Information Processing Systems36 (2023), 69949–69980
2023
-
[34]
Vijaya Krishna Yalavarthi, Kiran Madhusudhanan, Randolf Scholz, Nourhan Ahmed, Johannes Burchert, Shayan Jawed, Stefan Born, and Lars Schmidt-Thieme
-
[35]
InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol
Grafiti: Graphs for forecasting irregularly sampled time series. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 38. 16255–16263
-
[36]
Zhen-Jie Yao, Jie Bi, and Yi-Xin Chen. 2018. Applying deep learning to individual and community health monitoring data: A survey.International Journal of Automation and Computing15, 6 (2018), 643–655
2018
-
[37]
Kun Yi, Qi Zhang, Wei Fan, Shoujin Wang, Pengyang Wang, Hui He, Ning An, Defu Lian, Longbing Cao, and Zhendong Niu. 2023. Frequency-domain MLPs are more effective learners in time series forecasting.Advances in Neural Information Processing Systems36 (2023), 76656–76679
2023
-
[38]
Jiawen Zhang, Shun Zheng, Wei Cao, Jiang Bian, and Jia Li. 2023. Warpformer: A multi-scale modeling approach for irregular clinical time series. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3273–3285
2023
-
[39]
Kexin Zhang, Qingsong Wen, Chaoli Zhang, Rongyao Cai, Ming Jin, Yong Liu, James Y Zhang, Yuxuan Liang, Guansong Pang, Dongjin Song, et al. 2024. Self- supervised learning for time series analysis: Taxonomy, progress, and prospects. IEEE transactions on pattern analysis and machine intelligence46, 10 (2024), 6775– 6794
2024
-
[40]
Weijia Zhang, Chenlong Yin, Hao Liu, Xiaofang Zhou, and Hui Xiong. 2024. Irregular multivariate time series forecasting: A transformable patching graph neural networks approach. InForty-first International Conference on Machine Learning
2024
- [41]
- [42]
-
[43]
Yunhao Zhang and Junchi Yan. 2023. Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting. InThe eleventh international conference on learning representations
2023
-
[44]
Lifan Zhao and Yanyan Shen. 2025. Proactive model adaptation against concept drift for online time series forecasting. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 2020–2031
2025
-
[45]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond efficient transformer for long se- quence time-series forecasting. InProceedings of the AAAI conference on artificial intelligence, Vol. 35. 11106–11115
2021
-
[46]
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. 2022. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. InInternational conference on machine learning. PMLR, 27268–27286. A Additional Experiments A.1 Additional Main Results We report additional forecasting results measured by the MAE metric in Ta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.