Mining Multi-Modality Spatio-Temporal Cues for Video Important Person Identification
Pith reviewed 2026-06-29 13:23 UTC · model grok-4.3
The pith
VIP-Net identifies the most important person in videos by fusing multi-modal spatio-temporal cues and correcting for importance shifts over time, reaching 67.3% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
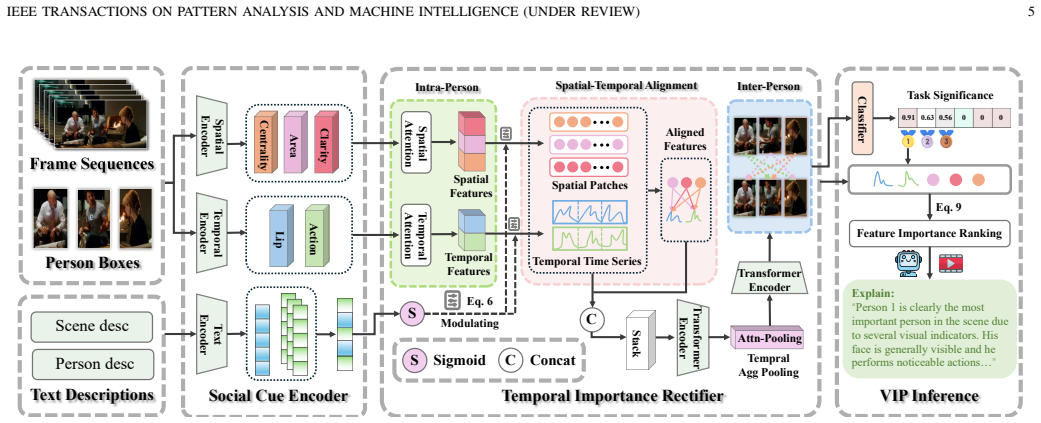
The central claim is that the VIP-Net framework, built from a Social Cue Encoder to extract multi-modal spatio-temporal cues, a Temporal Importance Rectifier for hierarchical cue fusion and cross-modal alignment, and a VIP Inference module for ranking, successfully mitigates Temporal Importance Shift and identifies the most influential person in videos while producing textual rationales that match ground-truth annotations at a mean similarity of 0.63 on the new Temporal-VIP dataset.
What carries the argument
The VIP-Net framework, which combines a Social Cue Encoder and Temporal Importance Rectifier to mine and align multi-modality spatio-temporal cues before ranking individuals.
If this is right
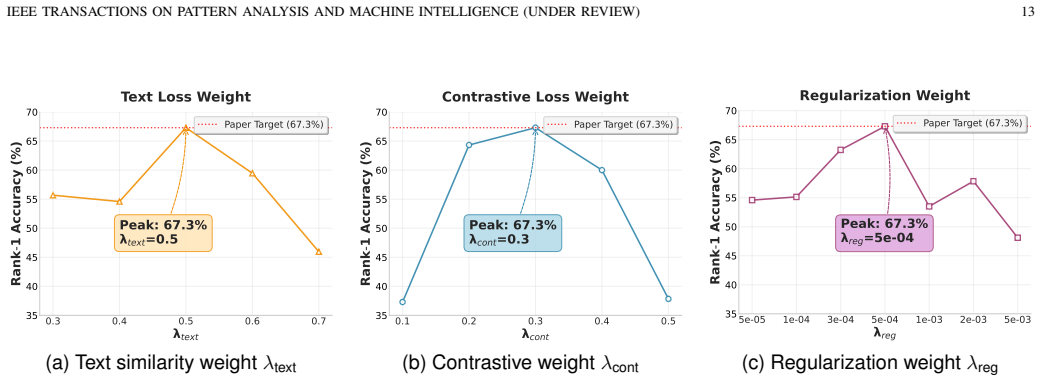
- VIP-Net reaches 67.3% accuracy on the VIP task, exceeding prior state-of-the-art ranges of 37.5-53.9%.
- The model produces rationales whose mean similarity to ground truth reaches 0.63 after feature-guided LLM refinement.
- The method operates on full temporal context across 11 video categories instead of static frames.
- The released Temporal-VIP dataset supplies 9,249 segments with aligned importance rationales for training and testing.
Where Pith is reading between the lines
- Similar temporal rectification steps could be tested on other video tasks that require consistent selection across an entire clip, such as keyframe extraction.
- The combination of visual cue encoding and LLM-based rationale generation may support richer human-AI collaboration in video analysis pipelines.
- Deployment in surveillance could shift from per-frame detection to sequence-level importance ranking without retraining the core encoder.
- The dataset annotations provide a ready benchmark for measuring how well other multimodal models align with human notions of influence.
Load-bearing premise
That Temporal Importance Shift is a widespread limitation of earlier methods and that the rationale annotations in Temporal-VIP reliably capture human judgments of importance.
What would settle it
Evaluating the model on a fresh collection of videos where a person's importance does not shift across frames, or on annotations produced by a different group of human raters, and checking whether accuracy remains substantially above the 37.5-53.9% range of prior models.
Figures




read the original abstract
Identifying key individuals in video scenes is essential for applications such as automated video editing and intelligent surveillance. Current methods primarily focus on static images and immediate visual cues, overlooking the rich spatio-temporal information in videos. This leads to the phenomenon of Temporal Importance Shift (TIS), wherein individuals deemed significant in early frames may be demoted as the entire temporal context is considered. To address this, we introduce the Video Important Person (VIP) identification task, aimed at automatically identifying the most influential individuals in videos while providing textual rationales. We present Temporal-VIP, a large-scale rationale-annotated dataset consisting of 9,249 video segments across 11 categories with aligned importance rationales. To mitigate TIS, we develop the VIP-Net framework, which includes a Social Cue Encoder (SCE) for extracting multi-modal spatio-temporal cues, a Temporal Importance Rectifier (TIR) for hierarchical cue fusion and cross-modal alignment, and VIP Inference for ranking individuals. Experimental results show that VIP-Net achieves 67.3% accuracy, significantly outperforming state-of-the-art models (37.5%-53.9%) and yielding a mean rationale similarity of 0.63 to ground truth through feature-guided LLM refinement. The dataset and code are available at https://huggingface.co/datasets/yml2002/Temporal-VIP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Video Important Person (VIP) identification task to identify the most influential individuals in videos while providing textual rationales, motivated by the Temporal Importance Shift (TIS) phenomenon in prior methods. It releases the Temporal-VIP dataset (9,249 video segments across 11 categories with aligned rationales) and proposes the VIP-Net framework consisting of a Social Cue Encoder (SCE) for multi-modal spatio-temporal cues, a Temporal Importance Rectifier (TIR) for hierarchical fusion and cross-modal alignment, and a VIP Inference module for ranking. Experiments report VIP-Net achieving 67.3% accuracy (outperforming SOTA baselines at 37.5%-53.9%) and a mean rationale similarity of 0.63 to ground truth via feature-guided LLM refinement, with dataset and code released publicly.
Significance. If the empirical claims hold after proper validation, the work could advance video person identification beyond static-image methods by incorporating spatio-temporal cues and interpretability via rationales, with applications in editing and surveillance. The public release of the Temporal-VIP dataset and code is a clear strength that supports reproducibility and future research.
major comments (4)
- [Abstract / Experimental Results] Abstract and Experimental Results section: the central performance claims (67.3% accuracy, outperformance over 37.5%-53.9%, 0.63 rationale similarity) are stated without any description of baseline implementations, number of runs, error bars, statistical tests, or validation procedures (e.g., train/test splits on Temporal-VIP), making it impossible to determine whether the data support the accuracy claims.
- [Introduction] Introduction / Motivation section: the claim that TIS is a prevalent and addressable limitation in prior video person identification methods is not supported by any explicit measurement or quantitative demonstration that the cited SOTA models (37.5%-53.9%) actually exhibit TIS on the new task; this assumption is load-bearing for the motivation of SCE and TIR.
- [Dataset] Dataset section: no inter-annotator agreement statistics are reported for the rationale annotations across the 11 categories in Temporal-VIP, which directly undermines the reliability of the ground-truth rationales used to compute the 0.63 similarity score and to train/evaluate the framework.
- [Method] Method / Ablation section: there is no ablation study isolating the contribution of the TIR module (or SCE) to mitigating TIS versus other factors such as task redefinition or additional modalities; without this, the source of the reported gains cannot be attributed to the proposed components.
minor comments (1)
- [Abstract] Abstract: the phrase 'feature-guided LLM refinement' is used without specifying which LLM, how features guide it, or any implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results section: the central performance claims (67.3% accuracy, outperformance over 37.5%-53.9%, 0.63 rationale similarity) are stated without any description of baseline implementations, number of runs, error bars, statistical tests, or validation procedures (e.g., train/test splits on Temporal-VIP), making it impossible to determine whether the data support the accuracy claims.
Authors: We agree that the current presentation lacks sufficient experimental details to fully substantiate the claims. In the revised manuscript, the Experimental Results section will be expanded to describe baseline re-implementations, the train/test split protocol on Temporal-VIP, results averaged over multiple runs with standard deviations (error bars), and statistical significance tests supporting the reported improvements. revision: yes
-
Referee: [Introduction] Introduction / Motivation section: the claim that TIS is a prevalent and addressable limitation in prior video person identification methods is not supported by any explicit measurement or quantitative demonstration that the cited SOTA models (37.5%-53.9%) actually exhibit TIS on the new task; this assumption is load-bearing for the motivation of SCE and TIR.
Authors: The TIS motivation is derived from the conceptual gap between static-image methods and full-video context. To provide the requested quantitative support, we will add an analysis (new subsection or figure) that measures importance ranking shifts in the cited baselines when evaluated on early frames versus complete temporal sequences on Temporal-VIP. revision: yes
-
Referee: [Dataset] Dataset section: no inter-annotator agreement statistics are reported for the rationale annotations across the 11 categories in Temporal-VIP, which directly undermines the reliability of the ground-truth rationales used to compute the 0.63 similarity score and to train/evaluate the framework.
Authors: We recognize that inter-annotator agreement metrics are essential for validating rationale quality. The dataset annotations involved multiple annotators; in the revision we will compute and report agreement statistics (e.g., Fleiss' kappa) broken down by the 11 categories. revision: yes
-
Referee: [Method] Method / Ablation section: there is no ablation study isolating the contribution of the TIR module (or SCE) to mitigating TIS versus other factors such as task redefinition or additional modalities; without this, the source of the reported gains cannot be attributed to the proposed components.
Authors: Current ablations demonstrate the effect of removing SCE and TIR on final accuracy and rationale similarity. To isolate the TIS-mitigation contribution, we will add a targeted ablation that measures temporal ranking consistency (e.g., importance shift metrics) with and without TIR, directly comparing against baselines to attribute gains to the proposed components. revision: yes
Circularity Check
No significant circularity; empirical results on new task and dataset.
full rationale
The paper introduces the VIP identification task, Temporal-VIP dataset, and VIP-Net framework (with SCE, TIR modules) as novel contributions, then reports direct experimental outcomes (67.3% accuracy, 0.63 rationale similarity) on that dataset. No derivation chain, equations, or fitted-parameter reductions are described that collapse to inputs by construction. Performance claims rest on standard ML evaluation against external benchmarks rather than self-referential definitions or self-citation load-bearing premises. This is the common case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Temporal sentence ground- ing in videos: A survey and future directions,
H. Zhang, A. Sun, W. Jing, and J. T. Zhou, “Temporal sentence ground- ing in videos: A survey and future directions,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 10 443– 10 465, 2023
2023
-
[2]
Bridgenet: Comprehensive and effective feature interactions via bridge feature for multi-task dense predictions,
J. Zhang, J. Fan, P. Ye, B. Zhang, H. Ye, B. Li, Y . Cai, and T. Chen, “Bridgenet: Comprehensive and effective feature interactions via bridge feature for multi-task dense predictions,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 5, pp. 3657–3672, 2025
2025
-
[3]
Learning efficient and effective trajectories for differential equation-based image restoration,
Z. Zhu, J. Hou, H. Liu, H. Zeng, and J. Hou, “Learning efficient and effective trajectories for differential equation-based image restoration,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[4]
Evolved hierarchical masking for self- supervised learning,
Z. Feng and S. Zhang, “Evolved hierarchical masking for self- supervised learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 2, pp. 1013–1027, 2024
2024
-
[5]
Higcin: Hierarchical graph-based cross inference network for group activity recognition,
R. Yan, L. Xie, J. Tang, X. Shu, and Q. Tian, “Higcin: Hierarchical graph-based cross inference network for group activity recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 6, pp. 6955–6968, 2020
2020
-
[6]
Ve-bench: subjective- aligned benchmark suite for text-driven video editing quality assess- ment,
S. Sun, X. Liang, S. Fan, W. Gao, and W. Gao, “Ve-bench: subjective- aligned benchmark suite for text-driven video editing quality assess- ment,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 7105–7113
2025
-
[7]
Multitec: a data- driven multimodal short video detection framework for healthcare misinformation on tiktok,
L. Shang, Y . Zhang, Y . Deng, and D. Wang, “Multitec: a data- driven multimodal short video detection framework for healthcare misinformation on tiktok,”IEEE Transactions on Big Data, vol. 11, no. 5, pp. 2471–2488, 2025
2025
-
[8]
Value co-creation in sports live streaming platforms: A microfoundations perspective,
H. Liu, K. H. Tan, A. Kumar, S. K. Singh, and L. Chung, “Value co-creation in sports live streaming platforms: A microfoundations perspective,”IEEE Transactions on Engineering Management, vol. 71, pp. 12 674–12 685, 2022
2022
-
[9]
Efficient high- order spatial interactions for visual perception,
Z. Liu, Y . Rao, W. Zhao, J. Zhou, and J. Lu, “Efficient high- order spatial interactions for visual perception,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[10]
Deep learning for person re-identification: A survey and outlook,
M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, and S. C. Hoi, “Deep learning for person re-identification: A survey and outlook,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 6, pp. 2872–2893, 2021
2021
-
[11]
Offsetnet: Towards efficient multiple object tracking, detection, and segmentation,
W. Zhang, J. Li, M. Xia, X. Gao, X. Tan, Y . Shi, Z. Huang, and G. Li, “Offsetnet: Towards efficient multiple object tracking, detection, and segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 2, pp. 949–960, 2024
2024
-
[12]
Infogcn++: Learning representation by predicting the future for online skeleton-based action recognition,
S. Chi, H.-G. Chi, Q. Huang, and K. Ramani, “Infogcn++: Learning representation by predicting the future for online skeleton-based action recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 1, pp. 514–528, 2024
2024
-
[13]
Personrank: Detecting important people in images,
W.-H. Li, B. Li, and W.-S. Zheng, “Personrank: Detecting important people in images,” in2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). IEEE, 2018, pp. 234–241
2018
-
[14]
Very important person localization in unconstrained conditions: A new benchmark,
X. Wang, Z. Wang, T. Yamasaki, and W. Zeng, “Very important person localization in unconstrained conditions: A new benchmark,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 4, 2021, pp. 2809–2816
2021
-
[15]
Mip-gaf: A mllm-annotated benchmark for most important person localization and group context understanding,
S. Madan, S. Ghosh, L. R. Sookha, M. Ganaie, R. Subramanian, A. Dhall, and T. Gedeon, “Mip-gaf: A mllm-annotated benchmark for most important person localization and group context understanding,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2025, pp. 1467–1476
2025
-
[16]
The Kinetics Human Action Video Dataset
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsevet al., “The kinetics human action video dataset,”arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Ava: A video dataset of spatio-temporally localized atomic visual actions,
C. Gu, C. Sun, D. A. Ross, C. V ondrick, C. Pantofaru, Y . Li, S. Vijayanarasimhan, G. Toderici, S. Ricco, R. Sukthankaret al., “Ava: A video dataset of spatio-temporally localized atomic visual actions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6047–6056
2018
-
[18]
Sportsmot: A large multi-object tracking dataset in multiple sports scenes,
Y . Cui, C. Zeng, X. Zhao, Y . Yang, G. Wu, and L. Wang, “Sportsmot: A large multi-object tracking dataset in multiple sports scenes,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 9921–9931
2023
-
[19]
Towards local visual modeling for image captioning,
Y . Ma, J. Ji, X. Sun, Y . Zhou, and R. Ji, “Towards local visual modeling for image captioning,”Pattern Recognition, vol. 138, p. 109420, 2023
2023
-
[20]
Background activation suppression for weakly supervised object localization and semantic segmentation,
W. Zhai, P. Wu, K. Zhu, Y . Cao, F. Wu, and Z.-J. Zha, “Background activation suppression for weakly supervised object localization and semantic segmentation,”International Journal of Computer Vision, vol. 132, no. 3, pp. 750–775, 2024
2024
-
[21]
Bytetrack: Multi-object tracking by associating every detection box,
Y . Zhang, P. Sun, Y . Jiang, D. Yu, F. Weng, Z. Yuan, P. Luo, W. Liu, and X. Wang, “Bytetrack: Multi-object tracking by associating every detection box,” inEuropean conference on computer vision. Springer, 2022, pp. 1–21
2022
-
[22]
Track to detect and segment: An online multi-object tracker,
J. Wu, J. Cao, L. Song, Y . Wang, M. Yang, and J. Yuan, “Track to detect and segment: An online multi-object tracker,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 352–12 361
2021
-
[23]
Samba: A unified mamba-based framework for general salient object detection,
J. He, K. Fu, X. Liu, and Q. Zhao, “Samba: A unified mamba-based framework for general salient object detection,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 25 314–25 324
2025
-
[24]
Mgfn: Magnitude-contrastive glance-and-focus network for weakly- supervised video anomaly detection,
Y . Chen, Z. Liu, B. Zhang, W. Fok, X. Qi, and Y .-C. Wu, “Mgfn: Magnitude-contrastive glance-and-focus network for weakly- supervised video anomaly detection,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 1, 2023, pp. 387–395
2023
-
[25]
Mutuality attribute makes better video anomaly detection,
X. Han, X. Wang, K. Jiang, W. Liu, R. Hu, X. Pan, and X. Xu, “Mutuality attribute makes better video anomaly detection,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 2670–2674
2024
-
[26]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[27]
Tinyllava: A framework of small-scale large multimodal models,
B. Zhou, Y . Hu, X. Weng, J. Jia, J. Luo, X. Liu, J. Wu, and L. Huang, “Tinyllava: A framework of small-scale large multimodal models,” arXiv preprint arXiv:2402.14289, 2024
-
[28]
Jrdb- act: A large-scale dataset for spatio-temporal action, social group and activity detection,
M. Ehsanpour, F. Saleh, S. Savarese, I. Reid, and H. Rezatofighi, “Jrdb- act: A large-scale dataset for spatio-temporal action, social group and activity detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 983–20 992
2022
-
[29]
Msr-vtt: A large video description dataset for bridging video and language,
J. Xu, T. Mei, T. Yao, and Y . Rui, “Msr-vtt: A large video description dataset for bridging video and language,” inProceedings of the IEEE IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE (UNDER REVIEW) 15 conference on computer vision and pattern recognition, 2016, pp. 5288–5296
2016
-
[30]
Role of group level affect to find the most influential person in images,
S. Ghosh and A. Dhall, “Role of group level affect to find the most influential person in images,” inProceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018, pp. 518– 533
2018
-
[31]
Learning to learn relation for important people detection in still images,
W.-H. Li, F.-T. Hong, and W. Zheng, “Learning to learn relation for important people detection in still images,”2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4998–5006, 2019
2019
-
[32]
Learning to detect important people in unlabelled images for semi-supervised important people detection,
F.-T. Hong, W.-H. Li, and W.-S. Zheng, “Learning to detect important people in unlabelled images for semi-supervised important people detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 4146–4154
2020
-
[33]
Towards causality inference for very important person localization,
X. Wang, Z. Wang, W. Liu, X. Xu, Q. Zhao, and S. Satoh, “Towards causality inference for very important person localization,” inProceed- ings of the 30th ACM International Conference on Multimedia, 2022, pp. 6618–6626
2022
-
[34]
Impact: Interpretable most important person analysis and classification using transformer- based models,
A. Rampuria, K. P. Nayak, K. V . Thakare, T. Joshi, A. D. Singh, H. Park, H. Choi, D. P. Dogra, and I.-J. Kim, “Impact: Interpretable most important person analysis and classification using transformer- based models,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2026, pp. 8179–8187
2026
-
[35]
A survey on evaluation of large language models,
Y . Chang, X. Wang, J. Wang, Y . Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y . Wanget al., “A survey on evaluation of large language models,”ACM transactions on intelligent systems and technology, vol. 15, no. 3, pp. 1–45, 2024
2024
-
[36]
Mask r-cnn,
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969
2017
-
[37]
Space: Finding key-speaker in complex multi-person scenes,
H. Zhao, W. Min, J. Xu, Q. Han, W. Li, Q. Wang, Z. Yang, and L. Zhou, “Space: Finding key-speaker in complex multi-person scenes,”IEEE Transactions on Emerging Topics in Computing, vol. 10, no. 3, pp. 1645–1656, 2021
2021
-
[38]
Simple online and realtime tracking with a deep association metric,
N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in2017 IEEE international conference on image processing (ICIP). IEEE, 2017, pp. 3645–3649
2017
-
[39]
Track- former: Multi-object tracking with transformers,
T. Meinhardt, A. Kirillov, L. Leal-Taixe, and C. Feichtenhofer, “Track- former: Multi-object tracking with transformers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8844–8854
2022
-
[40]
Observation- centric sort: Rethinking sort for robust multi-object tracking,
J. Cao, J. Pang, X. Weng, R. Khirodkar, and K. Kitani, “Observation- centric sort: Rethinking sort for robust multi-object tracking,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 9686–9696
2023
-
[41]
Motchallenge: A benchmark for single- camera multiple target tracking: P. dendorfer et al
P. Dendorfer, A. Osep, A. Milan, K. Schindler, D. Cremers, I. Reid, S. Roth, and L. Leal-Taix ´e, “Motchallenge: A benchmark for single- camera multiple target tracking: P. dendorfer et al.”International Journal of Computer Vision, vol. 129, no. 4, pp. 845–881, 2021
2021
-
[42]
Slowfast networks for video recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6202–6211
2019
-
[43]
Quo vadis, action recognition? a new model and the kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308
2017
-
[44]
Vivit: A video vision transformer,
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid, “Vivit: A video vision transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 6836–6846
2021
-
[45]
Is space-time attention all you need for video understanding?
G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” inIcml, vol. 2, no. 3, 2021, p. 4
2021
-
[46]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre- training,
Z. Tong, Y . Song, J. Wang, and L. Wang, “Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre- training,”Advances in neural information processing systems, vol. 35, pp. 10 078–10 093, 2022
2022
-
[47]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[48]
The” something something
R. Goyal, S. Ebrahimi Kahou, V . Michalski, J. Materzynska, S. West- phal, H. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag et al., “The” something something” video database for learning and evaluating visual common sense,” inProceedings of the IEEE interna- tional conference on computer vision, 2017, pp. 5842–5850
2017
-
[49]
Motionllm: Understanding human behaviors from human motions and videos,
L.-H. Chen, S. Lu, A. Zeng, H. Zhang, B. Wang, R. Zhang, and L. Zhang, “Motionllm: Understanding human behaviors from human motions and videos,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[50]
Actionart: Advancing multimodal large models for fine-grained human-centric video understanding,
Y .-X. Peng, Q. Yang, Y .-M. Tang, S. Fu, K.-Y . Lin, X. Wei, and W.-S. Zheng, “Actionart: Advancing multimodal large models for fine-grained human-centric video understanding,”arXiv preprint arXiv:2504.18152, 2025
-
[51]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[53]
Referring image segmentation using text supervision,
F. Liu, Y . Liu, Y . Kong, K. Xu, L. Zhang, B. Yin, G. Hancke, and R. Lau, “Referring image segmentation using text supervision,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 22 124–22 134
2023
-
[54]
Video action transformer network,
R. Girdhar, J. Carreira, C. Doersch, and A. Zisserman, “Video action transformer network,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 244–253
2019
-
[55]
Social scene understanding: End-to-end multi-person action localization and collective activity recognition,
T. Bagautdinov, A. Alahi, F. Fleuret, P. Fua, and S. Savarese, “Social scene understanding: End-to-end multi-person action localization and collective activity recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4315–4324
2017
-
[56]
Learning actor relation graphs for group activity recognition,
J. Wu, L. Wang, L. Wang, J. Guo, and G. Wu, “Learning actor relation graphs for group activity recognition,” inProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2019, pp. 9964–9974
2019
-
[57]
Con- gnn: Context-consistent cross-graph neural network for group emotion recognition in the wild,
Y . Wang, S. Zhou, Y . Liu, K. Wang, F. Fang, and H. Qian, “Con- gnn: Context-consistent cross-graph neural network for group emotion recognition in the wild,”Information Sciences, vol. 610, pp. 707–724, 2022
2022
-
[58]
So- cial relation recognition from videos via multi-scale spatial-temporal reasoning,
X. Liu, W. Liu, M. Zhang, J. Chen, L. Gao, C. Yan, and T. Mei, “So- cial relation recognition from videos via multi-scale spatial-temporal reasoning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3566–3574
2019
-
[59]
A domain based approach to social relation recognition,
Q. Sun, B. Schiele, and M. Fritz, “A domain based approach to social relation recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3481–3490
2017
-
[60]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[61]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
2022
-
[62]
Instructblip: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,”Advances in neural information processing systems, vol. 36, pp. 49 250–49 267, 2023
2023
-
[63]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 26 296–26 306
2024
-
[64]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Q.-V . Zhou, “A versatile vision-language model for un- derstanding, localization, text reading, and beyond,”arXiv preprint arXiv:2308.12966, vol. 6, p. 3, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Chat-univi: Unified visual representation empowers large language models with image and video understanding,
P. Jin, R. Takanobu, W. Zhang, X. Cao, and L. Yuan, “Chat-univi: Unified visual representation empowers large language models with image and video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 700–13 710
2024
-
[66]
Llava- cot: Let vision language models reason step-by-step,
G. Xu, P. Jin, Z. Wu, H. Li, Y . Song, L. Sun, and L. Yuan, “Llava- cot: Let vision language models reason step-by-step,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2087–2098
2025
-
[67]
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips,
A. Miech, D. Zhukov, J.-B. Alayrac, M. Tapaswi, I. Laptev, and J. Sivic, “Howto100m: Learning a text-video embedding by watching hundred million narrated video clips,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 2630–2640
2019
-
[68]
Actbert: Learning global-local video-text repre- sentations,
L. Zhu and Y . Yang, “Actbert: Learning global-local video-text repre- sentations,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8746–8755
2020
-
[69]
Frozen in time: A joint video and image encoder for end-to-end retrieval,
M. Bain, A. Nagrani, G. Varol, and A. Zisserman, “Frozen in time: A joint video and image encoder for end-to-end retrieval,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 1728–1738. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE (UNDER REVIEW) 16
2021
-
[70]
Videoclip: Contrastive pre- training for zero-shot video-text understanding,
H. Xu, G. Ghosh, P.-Y . Huang, D. Okhonko, A. Aghajanyan, F. Metze, L. Zettlemoyer, and C. Feichtenhofer, “Videoclip: Contrastive pre- training for zero-shot video-text understanding,” inProceedings of the 2021 conference on empirical methods in natural language processing, 2021, pp. 6787–6800
2021
-
[71]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
B. Zhang, K. Li, Z. Cheng, Z. Hu, Y . Yuan, G. Chen, S. Leng, Y . Jiang, H. Zhang, X. Liet al., “Videollama 3: Frontier multimodal foundation models for image and video understanding,”arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
X. Li, Y . Wang, J. Yu, X. Zeng, Y . Zhu, H. Huang, J. Gao, K. Li, Y . He, C. Wanget al., “Videochat-flash: Hierarchical compression for long-context video modeling,”arXiv preprint arXiv:2501.00574, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Timechat: A time-sensitive multimodal large language model for long video understanding,
S. Ren, L. Yao, S. Li, X. Sun, and L. Hou, “Timechat: A time-sensitive multimodal large language model for long video understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 313–14 323
2024
-
[74]
Video- llava: Learning united visual representation by alignment before pro- jection,
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video- llava: Learning united visual representation by alignment before pro- jection,” inProceedings of the 2024 conference on empirical methods in natural language processing, 2024, pp. 5971–5984
2024
-
[75]
Llava-st: A multimodal large language model for fine-grained spatial- temporal understanding,
H. Li, J. Chen, Z. Wei, S. Huang, T. Hui, J. Gao, X. Wei, and S. Liu, “Llava-st: A multimodal large language model for fine-grained spatial- temporal understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 8592–8603
2025
-
[76]
Video-chatgpt: Towards detailed video understanding via large vision and language models,
M. Maaz, H. Rasheed, S. Khan, and F. Khan, “Video-chatgpt: Towards detailed video understanding via large vision and language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 12 585– 12 602
2024
-
[77]
Internvideo2: Scaling foundation models for multimodal video understanding,
Y . Wang, K. Li, X. Li, J. Yu, Y . He, G. Chen, B. Pei, R. Zheng, Z. Wang, Y . Shiet al., “Internvideo2: Scaling foundation models for multimodal video understanding,” inEuropean conference on computer vision. Springer, 2024, pp. 396–416
2024
-
[78]
Sharegpt4video: Improving video understanding and generation with better captions,
L. Chen, X. Wei, J. Li, X. Dong, P. Zhang, Y . Zang, Z. Chen, H. Duan, B. Lin, Z. Tanget al., “Sharegpt4video: Improving video understanding and generation with better captions,”Advances in Neural Information Processing Systems, vol. 37, pp. 19 472–19 495, 2024
2024
-
[79]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis,
C. Fu, Y . Dai, Y . Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y . Shen, M. Zhanget al., “Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2025, pp. 24 108–24 118
2025
-
[80]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models,
H. Duan, J. Yang, Y . Qiao, X. Fang, L. Chen, Y . Liu, X. Dong, Y . Zang, P. Zhang, J. Wanget al., “Vlmevalkit: An open-source toolkit for evaluating large multi-modality models,” inProceedings of the 32nd ACM international conference on multimedia, 2024, pp. 11 198–11 201
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.