Measuring Form and Function in Language Models
Pith reviewed 2026-06-29 12:47 UTC · model grok-4.3
The pith
No current language model trained on data comparable to children's input meets both the formal syntactic and functional discourse benchmarks for English determiners that children achieve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
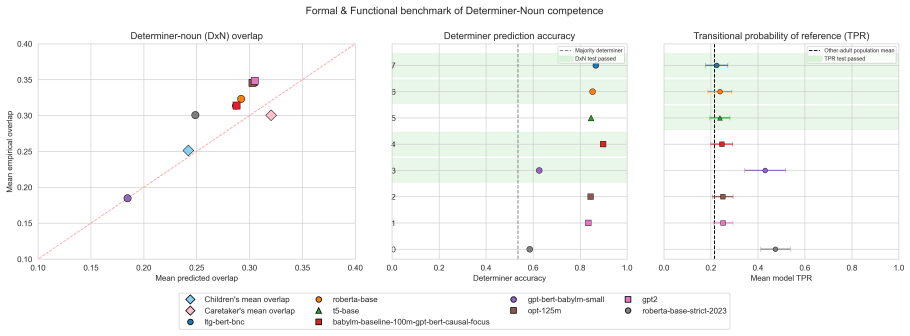
The paper establishes that while some very large language models can satisfy both formal syntactic and functional discourse properties of English determiners to the level of young children, no model trained on a comparable amount of data does so simultaneously. The Contextual Alternative Choice method enables this evaluation by testing targeted knowledge in context.
What carries the argument
The Contextual Alternative Choice (CAC) prompting method, which supplies contextual alternatives to test both syntactic rules and discourse knowledge of determiners in direct comparison to child acquisition data.
If this is right
- Models trained on data volumes typical of child input will fail to meet at least one of the two benchmarks.
- Scaling model size allows achievement of both formal and functional knowledge.
- The CAC method supports direct numerical comparison between model performance and child language statistics.
- Determiners serve as an early-acquired linguistic item suitable for such evaluations.
Where Pith is reading between the lines
- Applying similar metrics to other early-acquired linguistic items could reveal broader patterns in model vs child acquisition.
- Training regimes might need to incorporate more discourse-level signals to close the gap without extreme scaling.
- The results imply that formal syntax and discourse function may require different amounts of data or different learning mechanisms in models.
Load-bearing premise
The Contextual Alternative Choice method accurately isolates and measures syntactic and discourse knowledge of determiners in a manner comparable to the statistical benchmarks from child language acquisition research.
What would settle it
A model trained on a data volume similar to children's input that passes both the formal and functional CAC tests at child-like levels, or empirical evidence that CAC scores do not align with child performance patterns.
Figures

read the original abstract
We introduce quantitative metrics for child language acquisition to evaluate language models. Our focus is on the formal syntactic and functional discourse properties of determiners in English, which young children acquire early and accurately. We propose Contextual Alternative Choice (CAC), a new prompting method which provides targeted tests for both syntactic and discourse knowledge of language. The method enables direct comparison of language models against children, and more importantly, against statistical benchmarks independently established in empirical research. No current model trained on a comparable amount of data simultaneously meet both formal and functional benchmarks like human children, but some very large models do. We present our results as methodological and technical contributions, with specific emphasis on cognitive status of language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces quantitative metrics drawn from child language acquisition research to evaluate language models, focusing on the formal syntactic and functional discourse properties of English determiners. It proposes Contextual Alternative Choice (CAC), a new prompting technique designed to test both syntactic and discourse knowledge, enabling direct numerical comparison of LMs to independently established statistical benchmarks from child studies. The central empirical claim is that no current model trained on a comparable amount of data simultaneously meets both formal and functional benchmarks like human children, although some very large models do.
Significance. If the CAC method is validated as equivalent to child elicitation tasks, the work would supply a concrete, falsifiable protocol for measuring whether LMs exhibit human-like form-function dissociation in determiner use, strengthening the intersection of computational linguistics and developmental psycholinguistics.
major comments (2)
- [Abstract] Abstract: The headline claim that CAC 'enables direct comparison' to child benchmarks and that 'no current model ... simultaneously meet both' is load-bearing, yet the abstract supplies no information on test construction, item counts, statistical controls, or any back-testing of CAC against the original child corpora or elicitation procedures used to derive the reference benchmarks. Without such validation, numerical equivalence cannot be assumed.
- [Method] Method description (CAC): The assumption that CAC isolates syntactic versus discourse determiner knowledge in a manner directly comparable to child acquisition statistics is not shown to have been verified; mismatches in cue availability, response format, or task demands would render the cross-population comparison invalid and thereby undermine the reported model-versus-child result.
minor comments (1)
- [Abstract] Abstract: The sentence 'No current model trained on a comparable amount of data simultaneously meet both formal and functional benchmarks like human children' contains a subject-verb agreement error ('meet' should be 'meets').
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We agree that the abstract and method sections would benefit from additional detail on validation and comparability to strengthen the claims. We address each point below and will make revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that CAC 'enables direct comparison' to child benchmarks and that 'no current model ... simultaneously meet both' is load-bearing, yet the abstract supplies no information on test construction, item counts, statistical controls, or any back-testing of CAC against the original child corpora or elicitation procedures used to derive the reference benchmarks. Without such validation, numerical equivalence cannot be assumed.
Authors: We agree the abstract is too concise on these points. The full manuscript (Section 3) details CAC construction, item counts drawn from child corpora, and direct numerical comparison to the cited acquisition benchmarks. However, explicit back-testing of the prompting format against original child elicitation procedures is not reported. We will revise the abstract to include a sentence summarizing test parameters, item counts, and the alignment procedure used. revision: yes
-
Referee: [Method] Method description (CAC): The assumption that CAC isolates syntactic versus discourse determiner knowledge in a manner directly comparable to child acquisition statistics is not shown to have been verified; mismatches in cue availability, response format, or task demands would render the cross-population comparison invalid and thereby undermine the reported model-versus-child result.
Authors: This concern is well-taken. The method section motivates CAC by mapping its syntactic and discourse conditions onto the properties measured in the child studies, but we do not present a dedicated verification experiment or quantitative comparison of cue availability and response formats. We will add a new subsection (or expand the existing method discussion) that explicitly addresses potential mismatches, reports any available controls, and notes limitations in direct equivalence. revision: yes
Circularity Check
No significant circularity; claims rest on independent external benchmarks
full rationale
The paper's core comparison uses CAC prompting to test LMs against statistical benchmarks from child language acquisition that are described as independently established in prior empirical research. The abstract and setup emphasize direct comparison to these external benchmarks rather than any internal fitting, self-definition, or self-citation chain that would force the result by construction. No equations, predictions, or uniqueness claims reduce to the paper's own inputs; the derivation chain remains self-contained against the cited child-language data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Alhama, Ruthe Foushee, Dan Byrne, Allyson Ettinger, Afra Alishahi, and Susan Goldin-Meadow
Raquel G. Alhama, Ruthe Foushee, Dan Byrne, Allyson Ettinger, Afra Alishahi, and Susan Goldin-Meadow. 2024. https://doi.org/10.1073/pnas.2316527121 Using computational modeling to validate the onset of productive determiner–noun combinations in English -learning children . Proceedings of the National Academy of Sciences, 121(50):e2316527121
-
[4]
Alhama, Ruthe Foushee, Daniel Byrne, Allyson Ettinger, Susan Goldin-Meadow, and Afra Alishahi
Raquel G. Alhama, Ruthe Foushee, Daniel Byrne, Allyson Ettinger, Susan Goldin-Meadow, and Afra Alishahi. 2023. https://doi.org/10.18653/v1/2023.ijcnlp-main.21 Linguistic Productivity : the Case of Determiners in English . In Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia - Pacific C...
-
[5]
Jean Berko. 1958. The child's learning of English morphology. Word, 14(2--3):150--177
1958
-
[6]
Lois Bloom. 1970. Language development: Form and function in emerging grammar. MIT Press, Cambridge, MA
1970
-
[7]
Melissa Bowerman. 1982. Reorganizational process in lexical and syntactic development. In Eric Wanner and Lila R. Gleitman, editors, Language acquisition: The state of the art, pages 319--346. Cambridge University Press, New York
1982
-
[8]
Roger Brown. 1973. First Language : The Early Stages . Harvard University Press, Cambridge
1973
-
[9]
Tetsuro Chihara, John Oller, Kelley Weaver, and Mary Anne Chavez-Oller. 1977. Are cloze items sensitive to constraints across sentences? 1. Language learning, 27(1):63--70
1977
-
[10]
Carol Chomsky. 1969. The acquisition of syntax in children from 5 to 10. MIT Press, Cambridge, MA
1969
-
[11]
Noam Chomsky. 1955. The logical structure of linguistic theory. Manuscript, Harvard University
1955
-
[12]
Noam Chomsky. 1957. Syntactic structures. Mouton, The Hague
1957
-
[13]
Leshem Choshen, Ryan Cotterell, Mustafa Omer Gul, Jaap Jumelet, Tal Linzen, Aaron Mueller, Suchir Salhan, Raj Sanjay Shah, Alex Warstadt, and Ethan Gotlieb Wilcox. 2026. https://doi.org/10.48550/arXiv.2602.20092 BabyLM Turns 4 and Goes Multilingual : Call for Papers for the 2026 BabyLM Workshop . arXiv preprint. ArXiv:2602.20092 [cs]
-
[14]
McCarthy, Katharina Kann, Sabrina J
Ryan Cotterell, Christo Kirov, John Sylak-Glassman, G \'e raldine Walther, Ekaterina Vylomova, Arya D. McCarthy, Katharina Kann, Sabrina J. Mielke, Garrett Nicolai, Miikka Silfverberg, David Yarowsky, Jason Eisner, and Mans Hulden. 2018. https://doi.org/10.18653/v1/K18-3001 The C o NLL -- SIGMORPHON 2018 shared task: Universal morphological reinflection ....
-
[15]
Mark Davies. 2008. Corpus of Contemporary American English (COCA): 410+ million words, 1990-present. Available at http://www.americancorpus.org/
2008
-
[16]
Jill G De Villiers and Peter A De Villiers. 1974. Competence and performance in child language: Are children really competent to judge? Journal of Child Language, 1(1):11--22
1974
-
[17]
Susan M. Ervin. 1964. Imitation and structural change in children's language. In Eric H. Lenneberg, editor, New directions in the study of child language, pages 163--189. MIT Press, Cambridge
1964
-
[18]
Larry Fenson, Philip S Dale, J Steven Reznick, Elizabeth Bates, Donna J Thal, Stephen J Pethick, Michael Tomasello, Carolyn B Mervis, and Joan Stiles. 1994. Variability in early communicative development. Monographs of the Society for Research in Child Development, pages i--185
1994
-
[19]
Olivia La Fiandra, Nathalie Fernandez Echeverri, Patrick Shafto, and Naomi H. Feldman. 2025. https://doi.org/10.18653/v1/2025.babylm-main.8 Large Language Models and Children Have Different Learning Trajectories in Determiner Acquisition . In Proceedings of the First BabyLM Workshop , pages 100--108, Suzhou, China. Association for Computational Linguistics
-
[20]
Jill Gilkerson, Jeffrey A Richards, Steven F Warren, Judith K Montgomery, Charles R Greenwood, D Kimbrough Oller, John HL Hansen, and Terrance D Paul. 2017. Mapping the early language environment using all-day recordings and automated analysis. American journal of speech-language pathology, 26(2):248--265
2017
-
[21]
Talmy Giv \'o n. 1983. Topic continuity in discourse. John Benjamins Publishing Company
1983
-
[22]
Lila Gleitman and Charles Yang. 2022. Two-year-olds' referential determiners in discourse . In Boston Unversity Conference on Language Development
2022
-
[24]
Susan Goldin-Meadow and Charles Yang. 2017 b . https://doi.org/10.1016/j.neubiorev.2016.12.016 Statistical evidence that a child can create a combinatorial linguistic system without external linguistic input: Implications for language evolution . Neuroscience & Biobehavioral Reviews, 81:150--157
-
[25]
Zellig S. Harris. 1951. Methods in structural linguistics. University of Chicago Press, Chicago
1951
-
[26]
Matthew Honnibal and Mark Johnson. 2015. https://doi.org/10.18653/v1/D15-1162 An improved non-monotonic transition system for dependency parsing . In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1373--1378, Lisbon, Portugal. Association for Computational Linguistics
-
[27]
Jennifer Hu and Roger Levy. 2023. Prompting is not a substitute for probability measurements in large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5040--5060
2023
-
[28]
Jacobs, Loïc Grobol, and Alvin Tsang
Cassandra L. Jacobs, Loïc Grobol, and Alvin Tsang. 2024. https://doi.org/10.48550/ARXIV.2410.12057 Large-scale cloze evaluation reveals that token prediction tasks are neither lexically nor semantically aligned . arXiv preprint. Version Number: 2
-
[29]
Carina Kauf, Emmanuele Chersoni, Alessandro Lenci, Evelina Fedorenko, and Anna A Ivanova. 2024. https://doi.org/10.18653/v1/2024.blackboxnlp-1.18 Log probabilities are a reliable estimate of semantic plausibility in base and instruction-tuned language models . In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for N...
-
[30]
Erwin Komen, Rosanne Hebing, Ans Van Kemenade, and Bettelou Los. 2014. Quantifying information structure change in english. In Information structure and syntactic change in Germanic and Romance languages , pages 81--110. John Benjamins Publishing Company, Amsterdam
2014
-
[31]
Nelson Francis
Henry Kučera and W. Nelson Francis. 1967. Computational analysis of present-day American English . Brown University Press, Providence
1967
-
[32]
Legate and Charles Yang
Julie A. Legate and Charles Yang. 2007. Morphosyntactic learning and the development of tense. Language Acquisition, 14(3):315--344
2007
-
[33]
Roger Levy. 2008. https://doi.org/10.1016/j.cognition.2007.05.006 Expectation-based syntactic comprehension . Cognition, 106(3):1126--1177
-
[34]
Christopher Lyons. 1999. Definiteness. Cambridge University Press, Cambridge
1999
-
[35]
Brian MacWhinney. 2000. The CHILDES project: Tools for analyzing talk , 3rd edition. Lawrence Erlbaum, Mahwah, NJ
2000
-
[36]
Michael Maratsos. 1976. The use of definite and indefinite reference in young children. Cambridge University Press, London
1976
-
[37]
Arya D. McCarthy, Ekaterina Vylomova, Shijie Wu, Chaitanya Malaviya, Lawrence Wolf-Sonkin, Garrett Nicolai, Christo Kirov, Miikka Silfverberg, Sabrina J. Mielke, Jeffrey Heinz, Ryan Cotterell, and Mans Hulden. 2019. https://doi.org/10.18653/v1/W19-4226 The SIGMORPHON 2019 shared task: Morphological analysis in context and cross-lingual transfer for inflec...
-
[38]
Thomas McCoy, Paul Smolensky, Tal Linzen, Jianfeng Gao, and Asli Celikyilmaz
R. Thomas McCoy, Paul Smolensky, Tal Linzen, Jianfeng Gao, and Asli Celikyilmaz. 2023. https://doi.org/10.1162/tacl_a_00567 How Much Do Language Models Copy From Their Training Data ? Evaluating Linguistic Novelty in Text Generation Using RAVEN . Transactions of the Association for Computational Linguistics, 11:652--670. Place: Cambridge, MA
-
[39]
William Merrill, Noah A. Smith, and Yanai Elazar. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.800 Evaluating n- Gram Novelty of Language Models Using Rusty - DAWG . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 14459--14473, Miami, Florida, USA. Association for Computational Linguistics
-
[40]
Stephan C. Meylan, Michael C. Frank, Brandon C. Roy, and Roger Levy. 2017. https://doi.org/10.1177/0956797616677753 The Emergence of an Abstract Grammatical Category in Children ’s Early Speech . Psychological Science, 28(2):181--192
-
[41]
Denis Paperno, Germ \'a n Kruszewski, Angeliki Lazaridou, Ngoc-Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fern \'a ndez. 2016. The lambada dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long paper...
2016
-
[42]
Julian M Pine, Daniel Freudenthal, Grzegorz Krajewski, and Fernand Gobet. 2013. Do young children have adult-like syntactic categories? Zipf's law and the case of the determiner . Cognition, 127(3):345--360
2013
-
[43]
Julian M Pine and Helen Martindale. 1996. Syntactic categories in the speech of young children: The case of the determiner. Journal of child language, 23(2):369--395
1996
-
[44]
Margot Isabella Rozendaal and Anne Edith Baker. 2008. A cross-linguistic investigation of the acquisition of the pragmatics of indefinite and definite reference in two-year-olds. Journal of Child Language , 35(4):773--807
2008
-
[45]
Rushen Shi. 2023. Functional categories, determiners, prosody and early child grammar. In D. Armoskaite, S. Armoskaite, and M Wiltschko, editors, Oxford handbook of determiners. Oxford University Press
2023
-
[46]
Dan Slobin. 1985. The crosslinguistic study of language acquisition. Lawrence Erlbaum, Mahwah, NJ
1985
-
[47]
Jon Sprouse, Beracah Yankama, Sagar Indurkhya, Sandiway Fong, and Robert C Berwick. 2018. Colorless green ideas do sleep furiously: gradient acceptability and the nature of the grammar. The Linguistic Review, 35(3):575--599
2018
-
[48]
Wilson L Taylor. 1953. ``cloze procedure'': A new tool for measuring readability. Journalism quarterly, 30(4):415--433
1953
-
[49]
Herbert S Terrace, Laura-Ann Petitto, Richard J Sanders, and Thomas G Bever. 1979. Can an ape create a sentence? Science, 206(4421):891--902
1979
-
[50]
Anna Theakston, Elena Lieven, Julian Pine, and Caroline Rowland. 2001. https://doi.org/10.1017/S0305000900004608 The role of performance limitations in the acquisition of verb-argument structure: An alternative account . Journal of child language, 28:127--52
-
[51]
Rosalind Thornton. 2021. Judgments of acceptability, truth, and felicity in child language. The Cambridge handbook of experimental syntax (Cambridge handbooks in language and linguistics), pages 394--420
2021
-
[52]
Michael Tomasello. 2000. Do young children have adult syntactic competence? Cognition, 74(3):209--253
2000
-
[53]
Virginia Valian. 1986. Syntactic categories in the speech of young children. Developmental Psychology, 22(4):562
1986
-
[54]
Virginia Valian. 1991. Syntactic subjects in the early speech of American and Italian children. Cognition, 40(1):21--81
1991
-
[55]
Virginia Valian, Stephanie Solt, and John Stewart. 2009. Abstract categories or limited-scope formulae? The case of children's determiners . Journal of Child Language, 36(4):743--778
2009
-
[56]
Héctor Vázquez Martínez, Annika Lea Heuser, Charles Yang, and Jordan Kodner. 2023. https://doi.org/10.18653/v1/2023.genbench-1.4 Evaluating Neural Language Models as Cognitive Models of Language Acquisition . In Proceedings of the 1st GenBench Workshop on ( Benchmarking ) Generalisation in NLP , pages 48--64, Singapore. Association for Computational Linguistics
-
[57]
Qi Wang, Diane Lillo-Martin, Catherine T Best, and Andrea Levitt. 1992. Null subject versus null object: Some evidence from the acquisition of Chinese and English . Language Acquisition, 2(3):221--254
1992
-
[58]
Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R Bowman. 2020. Blimp: The benchmark of linguistic minimal pairs for english. Transactions of the Association for Computational Linguistics, 8:377--392
2020
-
[59]
Wilcox, Tiago Pimentel, Clara Meister, Ryan Cotterell, and Roger P
Ethan G. Wilcox, Tiago Pimentel, Clara Meister, Ryan Cotterell, and Roger P. Levy. 2023. https://doi.org/10.1162/tacl_a_00612 Testing the predictions of surprisal theory in 11 languages . Transactions of the Association for Computational Linguistics, 11:1451--1470
-
[60]
Charles Yang. 2013. https://doi.org/10.1073/pnas.1216803110 Ontogeny and phylogeny of language . Proceedings of the National Academy of Sciences, 110(16):6324--6327
-
[61]
Charles Yang. 2016. https://doi.org/10.7551/mitpress/9780262035323.001.0001 The Price of Linguistic Productivity : How Children Learn to Break the Rules of Language . The MIT Press
- [62]
-
[63]
Shuxian Zou, Shaonan Wang, Jiajun Zhang, and Chengqing Zong. 2022. https://doi.org/10.18653/v1/2022.findings-acl.54 Cross-modal cloze task: A new task to brain-to-word decoding . In Findings of the Association for Computational Linguistics: ACL 2022, pages 648--657, Dublin, Ireland. Association for Computational Linguistics
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.