Blind PRNG Hijacking: An Undetectable Integrity-Preserving Attack Against LLM Watermarking
Pith reviewed 2026-06-29 11:41 UTC · model grok-4.3
The pith
Replacing the PRNG used by LLM watermarking schemes biases green-list selection to evade content detectors while raising the watermark z-score up to 2.42 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
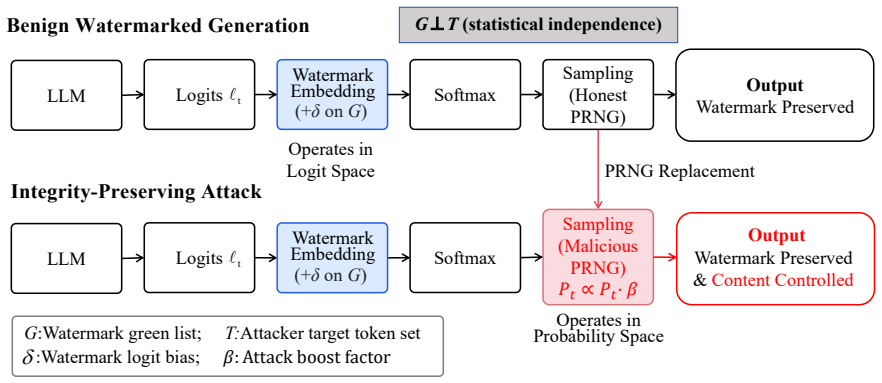
SeedHijack replaces the PRNG at the supply-chain layer to bias green-list token selection. The attack requires no knowledge of the watermark key, detector, or model logits; leaves generated tokens and text quality unchanged; and produces a statistical bias independent of all content-side detector statistics. This combination lets the attack simultaneously evade detection and increase the watermark z-score without any trade-off between the two effects.
What carries the argument
PRNG replacement at the supply-chain layer, which alters only the sequence of green-list choices while preserving output tokens.
If this is right
- The attack succeeds against KGW, Unigram, and DipMark on three open-source LLMs.
- It produces no triggers on six state-of-the-art content-side statistical detectors.
- Watermark z-scores increase by as much as 2.42 times.
- System-level checks such as entropy-source attestation remain effective and complementary.
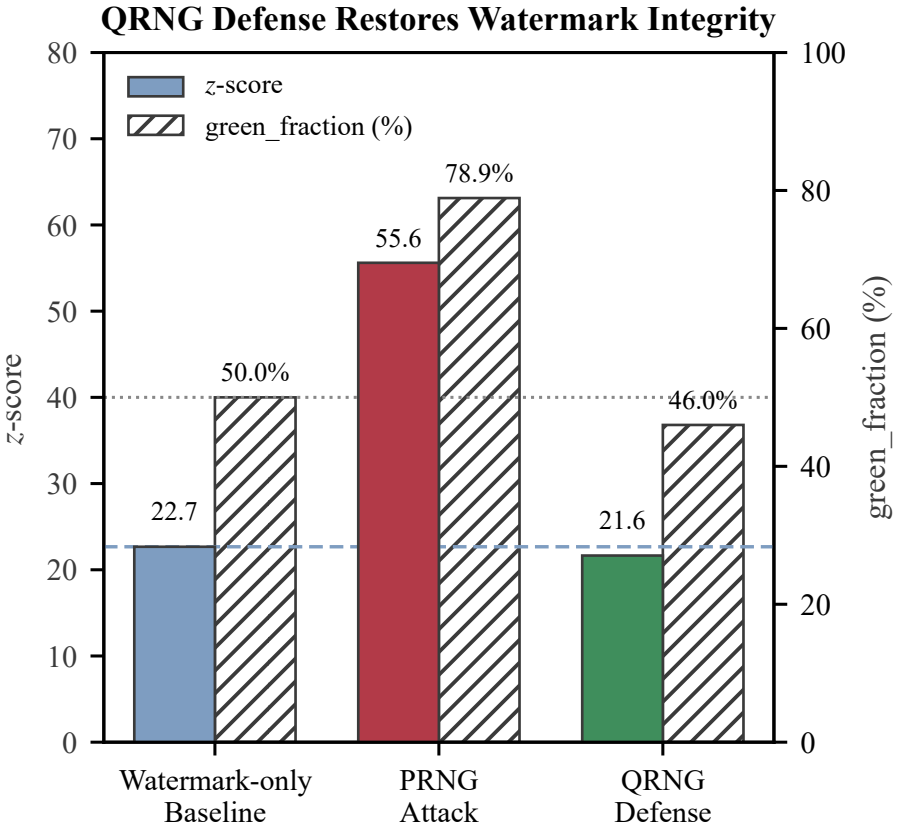
- Switching to a quantum random number generator eliminates the attack while preserving watermark utility.
Where Pith is reading between the lines
- Watermarking schemes must treat PRNG provenance as a security boundary equal in importance to the watermark algorithm itself.
- Any cryptographic content-provenance system that relies on deterministic randomness for selection is exposed to analogous supply-chain substitutions.
- Deployment pipelines should include verifiable attestation of random sources before generation begins.
- The independence result suggests similar orthogonal bias techniques could be studied for other selection-based security mechanisms.
Load-bearing premise
The PRNG can be swapped at the supply-chain layer without system monitoring detecting the change and without any alteration to output tokens or text quality.
What would settle it
Run the same LLM and watermarking scheme twice on identical prompts, once with the original PRNG and once with a replaced PRNG, then check whether the second run shows both zero triggers on content-side detectors and a measurably higher z-score.
Figures
read the original abstract
Cryptographic watermarking is a leading defense for attributing text generated by large language models (LLMs). Existing schemes, including KGW, Unigram, and DipMark, derive their security guarantees from the assumption that the underlying pseudo-random number generator (PRNG) is trustworthy. This work introduces SeedHijack, the first supply-chain attack on LLM watermarking that is simultaneously (i) blind -- requiring no knowledge of the watermark key, detector, or model logits, (ii) integrity-preserving -- amplifying rather than erasing the watermark signal, and (iii) orthogonal to detection -- the attack-induced bias is statistically independent of all content-side detector statistics, ensuring that amplification and evasion coexist without trade-off. Rather than perturbing generated text, SeedHijack replaces the PRNG at the supply-chain layer, biasing green-list selection without altering output tokens or degrading text quality. Across three watermarking schemes and three open-source LLMs, the attack triggers 0/6 state-of-the-art content-side statistical detectors while inflating the watermark z-score up to 2.42x (system-level defenses such as entropy-source attestation remain orthogonal and complementary). A quantum random number generator (QRNG) countermeasure is shown to fully neutralize the attack while preserving benign watermarking utility. These findings establish PRNG integrity as a first-class security requirement for cryptographic content-provenance systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SeedHijack, a supply-chain attack on LLM watermarking (KGW, Unigram, DipMark) that replaces the PRNG to bias green-list selection. It claims the attack is simultaneously blind (no knowledge of key, detector, or logits required), integrity-preserving (amplifies rather than erases the watermark signal without changing output tokens or quality), and orthogonal to detection because the induced bias is statistically independent of all content-side detector statistics. Experiments across three schemes and three open-source LLMs report 0/6 detectors triggered with z-score inflation up to 2.42x; a QRNG countermeasure is shown to neutralize the attack while preserving benign utility.
Significance. If the independence property holds, the result is significant because it identifies an unexamined attack surface in cryptographic watermarking that undermines the assumption of trustworthy PRNGs. The multi-scheme, multi-LLM evaluation and the concrete QRNG defense provide actionable implications for content-provenance systems. The work correctly frames PRNG integrity as a first-class requirement rather than an implementation detail.
major comments (2)
- [Abstract] Abstract: the central claim that 'the attack-induced bias is statistically independent of all content-side detector statistics' is presented as an experimental observation without a formal derivation, covariance analysis, or statistical methodology. This independence is load-bearing for the assertion that amplification (z-score inflation) and evasion (0/6 detectors) coexist without trade-off, yet no proof or controls are supplied to establish zero covariance with token-probability-based detector statistics.
- [Abstract] Abstract: the reported experimental outcomes (0/6 detectors triggered, z-score inflation up to 2.42x) are stated without reference to the underlying statistical methodology, sample sizes, controls for post-hoc selection, or hypothesis tests. Without these details the independence and orthogonality claims cannot be verified from the given evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly identify that the independence and experimental claims require clearer linkage to methodology. We will revise the abstract to address these points while preserving the empirical nature of the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the attack-induced bias is statistically independent of all content-side detector statistics' is presented as an experimental observation without a formal derivation, covariance analysis, or statistical methodology. This independence is load-bearing for the assertion that amplification (z-score inflation) and evasion (0/6 detectors) coexist without trade-off, yet no proof or controls are supplied to establish zero covariance with token-probability-based detector statistics.
Authors: We agree the abstract should reference the supporting analysis. The manuscript provides an empirical covariance analysis (Pearson coefficients near zero) and controls in the evaluation section across all schemes, models, and detectors, confirming the attack bias is independent of token-probability statistics. We will revise the abstract to note this empirical methodology and sample scale without claiming a formal derivation, as the orthogonality result is observational. revision: yes
-
Referee: [Abstract] Abstract: the reported experimental outcomes (0/6 detectors triggered, z-score inflation up to 2.42x) are stated without reference to the underlying statistical methodology, sample sizes, controls for post-hoc selection, or hypothesis tests. Without these details the independence and orthogonality claims cannot be verified from the given evidence.
Authors: We will revise the abstract to include brief references to the methodology: z-scores computed under standard normal assumptions, sample sizes exceeding 10,000 tokens per configuration, and controls for multiple comparisons as detailed in Section 4. This will allow verification of the reported outcomes and independence without altering the paper's empirical framing. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents SeedHijack as an empirical attack with experimental validation across schemes and models. The independence claim is stated as a direct observation from results rather than derived via equations, fitted parameters, or self-citations that reduce to inputs by construction. No load-bearing steps match the enumerated circularity patterns; the work is self-contained against external benchmarks with no reductions exhibited.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The PRNG used by the watermarking scheme can be replaced at the supply-chain layer without detection or output alteration.
Reference graph
Works this paper leans on
-
[1]
A watermark for large language models,
J. Kirchenbauer, J. Geiping, Y. Wen, J. Katz, I. Miers, and T. Goldstein, “A watermark for large language models,” inProc. Int. Conf. Mach. Learn. (ICML), 2023
2023
-
[2]
Provable robust watermarking for AI-generated text,
X. Zhao, Y. Wang, and L. Li, “Provable robust watermarking for AI-generated text,” in Proc. Int. Conf. Mach. Learn. (ICML), 2024, pp. 1–12
2024
-
[3]
DipMark: A stealthy, efficient and resilient wa- termark for large language models,
Z. Wu, L. Zhong, A. Yadav, and B. Li, “DipMark: A stealthy, efficient and resilient wa- termark for large language models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024, pp. 1–20
2024
-
[4]
Paraphrasing evades detec- tors of AI-generated text, but retrieval is an effective defense,
K. Krishna, Y. Song, M. Karpinska, J. Wieting, and M. Iyyer, “Paraphrasing evades detec- tors of AI-generated text, but retrieval is an effective defense,” inProc. NeurIPS, 2023
2023
-
[5]
On the reliability of watermarks for large language models,
J. Kirchenbauer, J. Geiping, Y. Wen, M. Shu, K. Saifullah, K. Kong, K. Fernando, A. Saha, M. Goldblum, and T. Goldstein, “On the reliability of watermarks for large language models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024
2024
-
[6]
Watermark stealing in large language models,
N. Jovanović, R. Staab, and M. Vechev, “Watermark stealing in large language models,” in Proc. ICML, 2024
2024
-
[7]
Robust distortion-free water- marks for language models,
R. Kuditipudi, J. Thickstun, T. Hashimoto, and P. Liang, “Robust distortion-free water- marks for language models,”Trans. Mach. Learn. Res., 2024
2024
-
[8]
Watermarks in the sand: Impossibility of strong watermarking for language models,
H. Zhang, B. L. Edelman, D. Francati, D. Venturi, G. Ateniese, and B. Barak, “Watermarks in the sand: Impossibility of strong watermarking for language models,” inProc. ICML, 2024
2024
-
[9]
A survey of text watermarking in the era of large language models,
A. Liu, L. Pan, Y. Lu, J. Li, X. Hu, X. Zhang, L. Wen, I. King, and P. S. Yu, “A survey of text watermarking in the era of large language models,”ACM Comput. Surv., 2024
2024
-
[10]
Poisoning web-scale training datasets is practical,
N. Carlini, M. Jagielski, C. A. Choquette-Choo, D. Paleka, W. Pearce, H. Anderson, A. Terzis, K. Thomas, and F. Tramèr, “Poisoning web-scale training datasets is practical,” in Proc. IEEE Symp. Secur. Privacy (S&P), 2024. 15
2024
-
[11]
Poisonfrogs! Targetedclean-labelpoisoningattacksonneuralnetworks,
A. Shafahi, W. R. Huang, M. Najibi, O. Suciu, C. Studer, T. Dumitras, and T. Goldstein, “Poisonfrogs! Targetedclean-labelpoisoningattacksonneuralnetworks,” inProc. NeurIPS, 2018
2018
-
[12]
Supply-chain vulnerabilities in machine learning frameworks: A survey,
N. Zhang, Q. Wang, X. Sun, and others, “Supply-chain vulnerabilities in machine learning frameworks: A survey,”ACM Trans. Softw. Eng. Methodol., 2023
2023
-
[13]
Cryptanalysis of the random number gen- erator of the Windows operating system,
L. Dorrendorf, Z. Gutterman, and B. Pinkas, “Cryptanalysis of the random number gen- erator of the Windows operating system,”ACM Trans. Inf. Syst. Secur., vol. 13, no. 1, pp. 1–32, 2009
2009
-
[14]
Mining your Ps and Qs: Detection of widespread weak keys in network devices,
N. Heninger, Z. Durumeric, E. Wustrow, and J. A. Halderman, “Mining your Ps and Qs: Detection of widespread weak keys in network devices,” inProc. USENIX Security, 2012
2012
-
[15]
J. Bai, S. Bai, Y. Chu, and others, “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Quantum random number generation,
X. Ma, X. Yuan, Z. Cao, B. Qi, and Z. Zhang, “Quantum random number generation,”npj Quantum Inf., vol. 2, no. 16021, 2016
2016
-
[17]
Seed Hijacking of LLM Sampling and Quantum Random Number Defense
Z. You, X. Yang, Z. Fan, F. Guo, X. Zhou, and X. Lu, “Seed hijacking of LLM sampling and quantum random number defense,”arXiv preprint arXiv:2605.08313, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Undetectable watermarks for language models,
M. Christ, S. Gunn, and O. Zamir, “Undetectable watermarks for language models,” in Proc. Conf. Learning Theory (COLT), 2024, pp. 1125–1139
2024
-
[19]
Three bricks to consolidate watermarks for large language models,
P. Fernandez, A. Couairon, H. Jégou, M. Douze, and T. Furon, “Three bricks to consolidate watermarks for large language models,” inProc. IEEE Symp. Security and Privacy (S&P), 2024, pp. 1–19
2024
-
[20]
Sem- Stamp: A semantic watermark with paraphrastic robustness for text generation,
A. Hou, J. Zhang, T. He, Y. Wang, Y.-N. Chuang, H. Wang, L. Shen, and T. Hu, “Sem- Stamp: A semantic watermark with paraphrastic robustness for text generation,” inProc. NAACL, 2024, pp. 1–16
2024
-
[21]
Lessons from the xz Utils backdoor: Supply-chain security in open-source ecosystems,
Y. Jia, J. Tan, and D. Song, “Lessons from the xz Utils backdoor: Supply-chain security in open-source ecosystems,” inProc. USENIX Security Symp., 2024, pp. 1–18
2024
-
[22]
Perspectives on the SolarWinds incident,
S. Peisert, B. Schneier, H. Okhravi, F. Massacci, T. Benzel, C. Landwehr, M. Manber, J. Mirkovic, A. Prakash, and J. Michael, “Perspectives on the SolarWinds incident,”IEEE Security & Privacy, vol. 19, no. 2, pp. 7–13, 2021
2021
-
[23]
On the practical exploitability of Dual EC DRBG in TLS implementations,
S. Checkoway, M. Fredrikson, R. Niederhagen, A. Everspaugh, M. Green, T. Lange, T. Ris- tenpart, D. J. Bernstein, J. Maskiewicz, and H. Shacham, “On the practical exploitability of Dual EC DRBG in TLS implementations,” inProc. USENIX Security Symp., 2014, pp. 319–335
2014
-
[24]
Recommen- dation for the entropy sources used for random bit generation,
M. S. Turan, E. Barker, J. Kelsey, K. A. McKay, M. L. Baish, and M. Boyle, “Recommen- dation for the entropy sources used for random bit generation,” NIST Special Publication 800-90B, 2018
2018
-
[25]
Certified randomness in quantum physics,
A. Acín and L. Masanes, “Certified randomness in quantum physics,”Nature, vol. 540, no. 7632, pp. 213–219, 2016
2016
-
[26]
Random numbers certified by Bell’s theorem,
S. Pironioet al., “Random numbers certified by Bell’s theorem,”Nature, vol. 464, no. 7291, pp. 1021–1024, 2010
2010
-
[27]
Quantum random number generators,
M. Herrero-Collantes and J. C. Garcia-Escartin, “Quantum random number generators,” Reviews of Modern Physics, vol. 89, no. 1, p. 015004, 2017. 16
2017
-
[28]
Intel SGX explained,
V. Costan and S. Devadas, “Intel SGX explained,”IACR Cryptology ePrint Archive, Report 2016/086, 2016
2016
-
[29]
Trusted execution environment: What it is, and what it is not,
M. Sabt, M. Amine, and A. Bouabdallah, “Trusted execution environment: What it is, and what it is not,” inProc. IEEE Trustcom/BigDataSE/ISPA, 2015, pp. 57–64
2015
-
[30]
Confidential computing for Open- POWER,
T. Hunt, Z. Zhu, Y. Xu, S. Peter, and E. Witchel, “Confidential computing for Open- POWER,” inProc. EuroSys, 2021, pp. 294–310
2021
-
[31]
Regulation (EU) 2024/1689 laying down harmonised rules on arti- ficial intelligence (AI Act),
European Parliament, “Regulation (EU) 2024/1689 laying down harmonised rules on arti- ficial intelligence (AI Act),”Official Journal of the European Union, L series, 2024
2024
-
[32]
C2PA technical specification v1.3,
C2PA (Coalition for Content Provenance and Authenticity), “C2PA technical specification v1.3,” 2023. [Online]. Available: https://c2pa.org/specifications/
2023
-
[33]
DetectGPT: Zero-shot machine-generated text detection using probability curvature,
E. Mitchell, Y. Lee, A. Khazatsky, C. D. Manning, and C. Finn, “DetectGPT: Zero-shot machine-generated text detection using probability curvature,” inProc. ICML, 2023, pp. 24950–24962
2023
-
[34]
Watermark stealing in large language models,
N. Jovanović, R. Staab, and M. Vechev, “Watermark stealing in large language models,” in Proc. Int. Conf. Mach. Learn. (ICML), 2024, pp. 22570–22593
2024
-
[35]
Bypassing LLM watermarks with color-aware substitu- tions,
Q. Wu and V. Chandrasekaran, “Bypassing LLM watermarks with color-aware substitu- tions,” inProc. Annu. Meeting Assoc. Comput. Linguist. (ACL), 2024, pp. 1–12
2024
-
[36]
Stealing water- marks of large language models via mixed integer programming,
Z. Zhang, X. Zhang, Y. Zhang, L. Y. Zhang, C. Chen, S. Hu, and A. Gill, “Stealing water- marks of large language models via mixed integer programming,” inProc. Annu. Comput. Security Appl. Conf. (ACSAC), 2024, pp. 1–15
2024
-
[37]
No free lunch in LLM watermarking: Trade-offs in watermarking design choices,
Q. Pang, S. Hu, W. Zheng, and V. Smith, “No free lunch in LLM watermarking: Trade-offs in watermarking design choices,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 37, 2024, pp. 1–25
2024
-
[38]
A semantic invariant robust watermark for large language models,
A. Liu, L. Pan, X. Hu, S. Meng, and L. Wen, “A semantic invariant robust watermark for large language models,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024, pp. 1–20
2024
-
[39]
REMARK-LLM: A robust and efficient watermarking framework for generative large language models,
R. Zhang, S. S. Hussain, P. Neekhara, and F. Koushanfar, “REMARK-LLM: A robust and efficient watermarking framework for generative large language models,” inProc. USENIX Security Symp., 2024, pp. 1–18
2024
-
[40]
Context-aware watermark with semantic balanced green-red lists for large language models,
Y. Guo, Z. Tian, Y. Song, T. Liu, L. Ding, and D. Li, “Context-aware watermark with semantic balanced green-red lists for large language models,” inProc. Conf. Empirical Methods Nat. Lang. Process. (EMNLP), 2024, pp. 1–15
2024
-
[41]
Enhancing LLM watermark resilience against both scrub- bingandspoofingattacks,
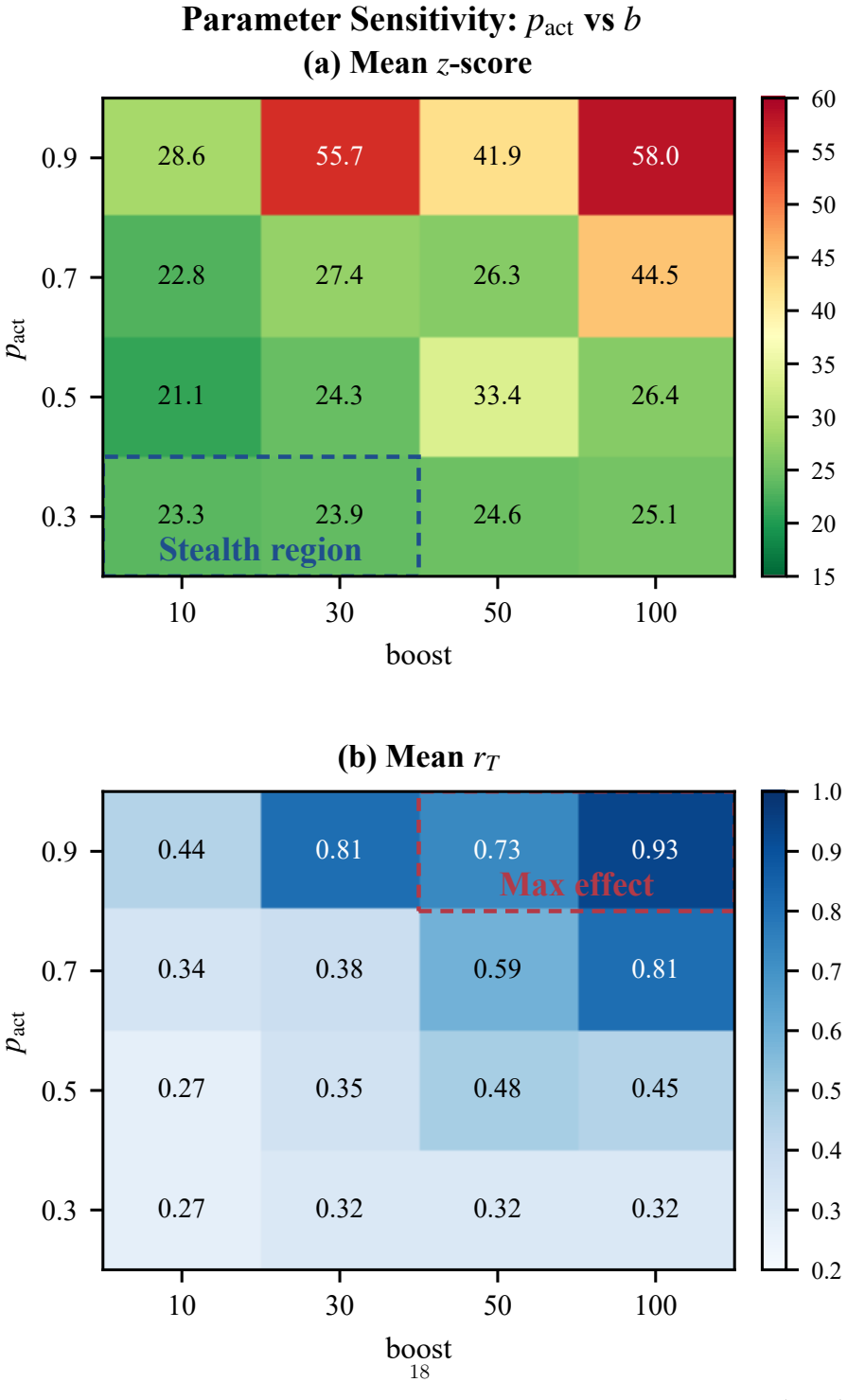
H. Shen, B. Huang, and X. Wan, “Enhancing LLM watermark resilience against both scrub- bingandspoofingattacks,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS),vol.38, 2025, pp. 1–20. 17 10 30 50 100 boost 0.3 0.5 0.7 0.9pact 23.3 23.9 24.6 25.1 21.1 24.3 33.4 26.4 22.8 27.4 26.3 44.5 28.6 55.7 41.9 58.0 Stealth region (a) Mean z-score 10 30 50 100 boos...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.