PrimitiveVLA: Learning Reusable Motion Primitives for Efficient and Generalizable Robotic Manipulation
Pith reviewed 2026-06-29 11:44 UTC · model grok-4.3
The pith
PrimitiveVLA replaces direct instruction-to-control mapping in VLA models with disassembly into reusable motion primitives and reassembly at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
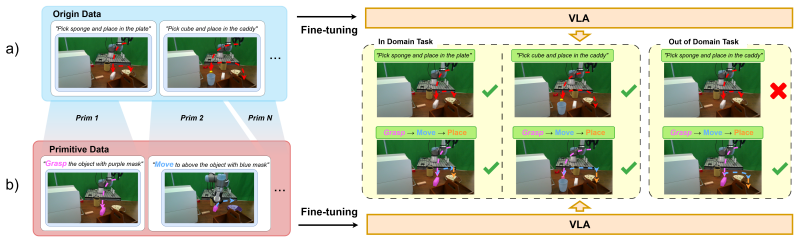
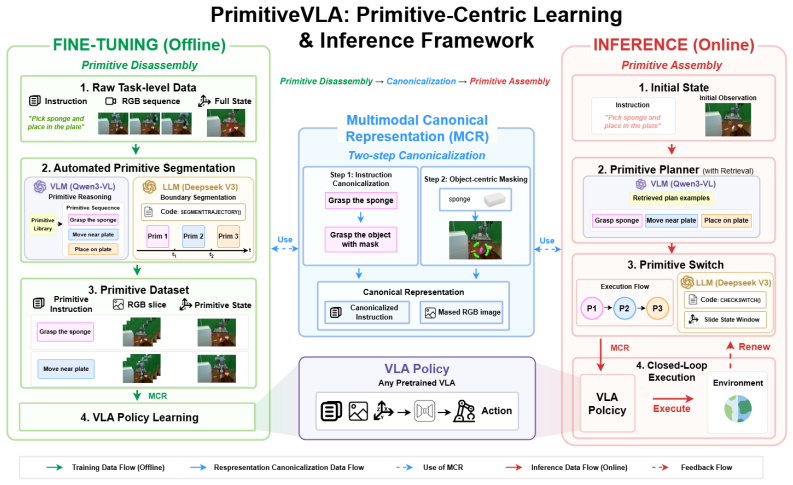
By moving from Direct Instruction-to-Control Mapping to a Primitive-Centric Disassemble & Assemble paradigm supported by a shared Multimodal Canonical Representation, PrimitiveVLA lets VLA models learn invariant motion patterns rather than monolithic trajectories; the automated disassembly stage extracts reusable primitives from demonstrations during fine-tuning, while a VLM-based planner and LLM-generated switch module handle closed-loop composition at inference, producing measurable gains in data efficiency and zero-shot success on unseen and long-horizon manipulation tasks.
What carries the argument
The Multimodal Canonical Representation (MCR) that stores and unifies the extracted motion primitives so they can be disassembled from demonstrations and later assembled by the planner and switch module.
If this is right
- VLA models trained under the new paradigm require fewer demonstration trajectories to reach a given performance level.
- The same model can execute novel task combinations without additional fine-tuning because primitives are recombined rather than relearned.
- Long-horizon tasks become feasible by sequencing existing primitives instead of training on full-length demonstrations.
- The approach separates motion-pattern learning from high-level planning, allowing each component to be updated independently.
Where Pith is reading between the lines
- If the primitives prove stable across robot morphologies, the same library could be transferred between different hardware platforms with minimal re-training.
- The disassembly pipeline could be applied retroactively to existing large-scale VLA datasets to create reusable primitive corpora for community use.
- Failure modes in the switch module would surface first on tasks that require precise timing between primitives rather than on object-recognition errors.
Load-bearing premise
An automated pipeline can reliably break arbitrary demonstrations into a fixed set of reusable primitives that stay task-invariant and remain composable when the model is later asked to solve new tasks.
What would settle it
Running the same VLA backbone with and without the disassembly-assembly pipeline on a held-out suite of manipulation tasks and finding no statistically significant difference in zero-shot success rate or sample efficiency.
Figures




read the original abstract
Vision-Language-Action (VLA) models offer a promising paradigm for generalist robotic policies, yet their adaptation is hindered by data inefficiency and poor generalization. We argue that these bottlenecks stem from the prevailing Direct Instruction-to-Control Mapping, which forces models to memorize monolithic trajectories rather than reusable motion patterns, i.e., primitives. We propose PrimitiveVLA, a framework that shifts this paradigm toward a Primitive-Centric Disassemble & Assemble paradigm. Supported by a shared Multimodal Canonical Representation (MCR), PrimitiveVLA unifies two phases: (1) Fine-tuning-phase Disassembly, which uses an automated pipeline to disassemble demonstrations into reusable primitives; and (2) Inference-phase Assembly, which employs a VLM-based planner and an LLM-generated switch module for robust closed-loop execution. By disassembling tasks into reusable primitives, PrimitiveVLA enables VLA models to learn invariant motion patterns instead of task-specific trajectories. Extensive experiments show that our framework improves data efficiency and achieves superior zero-shot generalization across unseen and long-horizon tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Vision-Language-Action (VLA) models suffer from data inefficiency and poor generalization due to the Direct Instruction-to-Control Mapping, which causes memorization of monolithic trajectories. It proposes PrimitiveVLA, a framework shifting to a Primitive-Centric Disassemble & Assemble paradigm supported by a shared Multimodal Canonical Representation (MCR). This unifies (1) a fine-tuning-phase automated pipeline that disassembles demonstrations into reusable primitives and (2) an inference-phase assembly using a VLM-based planner and LLM-generated switch module for closed-loop execution. The authors state that this enables learning of invariant motion patterns, with extensive experiments showing improved data efficiency and superior zero-shot generalization on unseen and long-horizon tasks.
Significance. If the automated disassembly pipeline reliably extracts task-invariant, composable primitives faithfully captured by the MCR, the framework could meaningfully advance VLA-based robotic manipulation by addressing core data-efficiency bottlenecks through reuse of motion patterns rather than task-specific trajectories. The approach is conceptually aligned with longstanding ideas in robotics about primitives and compositionality, and the dual-phase design (disassembly + assembly) offers a concrete mechanism for operationalizing them in modern VLA models.
major comments (1)
- [Abstract] Abstract (Fine-tuning-phase Disassembly description): The central claim that PrimitiveVLA improves data efficiency and zero-shot generalization rests on the automated pipeline producing reusable, task-invariant primitives that are captured by the MCR and remain composable at inference. No mechanism, segmentation criterion, invariance metric, or failure modes are supplied for this pipeline, making it impossible to evaluate whether the three required properties (task-invariance, faithful MCR capture, reliable recomposability) hold for arbitrary demonstrations or long-horizon tasks.
minor comments (1)
- The abstract refers to 'Extensive experiments' demonstrating the claimed gains, yet supplies no baselines, quantitative metrics, or task descriptions; this presentation gap prevents assessment of effect sizes even if the pipeline details are added.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and indicate where revisions will be made to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract (Fine-tuning-phase Disassembly description): The central claim that PrimitiveVLA improves data efficiency and zero-shot generalization rests on the automated pipeline producing reusable, task-invariant primitives that are captured by the MCR and remain composable at inference. No mechanism, segmentation criterion, invariance metric, or failure modes are supplied for this pipeline, making it impossible to evaluate whether the three required properties (task-invariance, faithful MCR capture, reliable recomposability) hold for arbitrary demonstrations or long-horizon tasks.
Authors: We agree that the abstract, as currently written, is too high-level and does not supply the requested details on the automated disassembly pipeline. The main manuscript (Section 3.2) describes the pipeline, but the abstract itself provides no mechanism, segmentation criterion, invariance metric, or failure modes. To address this, we will revise the abstract to include a concise summary of these elements (drawing directly from the methods section) so that the central claims can be evaluated from the abstract alone. This is a presentation issue rather than a change to the underlying method. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces PrimitiveVLA as a new framework shifting from Direct Instruction-to-Control Mapping to a Primitive-Centric Disassemble & Assemble paradigm using Multimodal Canonical Representation (MCR). The abstract and description outline two phases (fine-tuning disassembly via automated pipeline and inference assembly via VLM/LLM) without equations, fitted parameters, predictions derived from inputs, self-definitional constructs, or load-bearing self-citations. Claims of improved data efficiency and zero-shot generalization are presented as outcomes of the paradigm shift and supported by experiments, with no reduction of any core result to its own inputs by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Demonstrations can be automatically disassembled into reusable, task-invariant motion primitives
invented entities (1)
-
Multimodal Canonical Representation (MCR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
Openvla: An open-source vision-language- action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language- action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[3]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
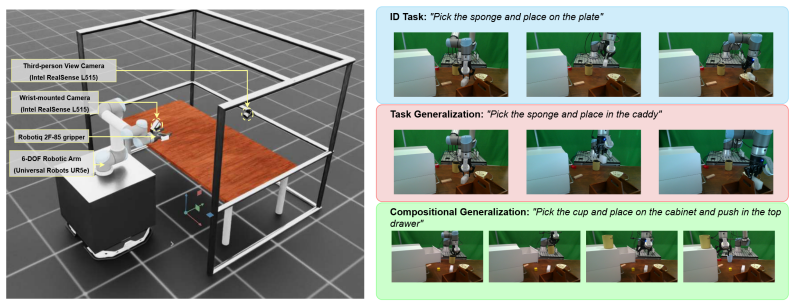
[4]
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Yecheng Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Arhan Jain, Abraham Lee, You...
2024
-
[5]
Jiaming Zhou, Ke Ye, Jiayi Liu, Teli Ma, Zifan Wang, Ronghe Qiu, Kun-Yu Lin, Zhilin Zhao, and Junwei Liang. Exploring the limits of vision-language-action manipulations in cross-task generalization.arXiv preprint arXiv:2505.15660, 2025
-
[6]
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, Vedant Choudhary, Foster Collins, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Maitrayee Dhaka, Jared DiCarlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Vima: General robot manipulation with multimodal prompts,
Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. Vima: General robot manipulation with multimodal prompts.arXiv preprint arXiv:2210.03094, 2(3):6, 2022
-
[9]
Octo: An open-source generalist robot policy
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open-source generalist robot policy. InRobotics: Science and Systems, 2024
2024
-
[10]
Vision-Language Foundation Models as Effective Robot Imitators
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, and Tao Kong. Vision-language foundation models as effective robot imitators.arXiv preprint arXiv:2311.01378, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[12]
Rdt-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[13]
Videovla: Video generators can be generalizable robot manipulators, 2025
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, and Baining Guo. Videovla: Video generators can be generalizable robot manipulators, 2025. URL https: //arxiv.org/abs/2512.06963
-
[14]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Tsung-Yi Lin, Gordon Wetzstein, Ming-Yu Liu, and Donglai Xiang. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni...
2025
-
[15]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
pi_0.5: a vision-language- action model with open-world generalization
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al. pi_0.5: a vision-language- action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[18]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2):181–211, 1999
Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2):181–211, 1999
1999
-
[19]
Dynamical movement primitives: learning attractor models for motor behaviors.Neural computation, 25(2):328–373, 2013
Auke Jan Ijspeert, Jun Nakanishi, Heiko Hoffmann, Peter Pastor, and Stefan Schaal. Dynamical movement primitives: learning attractor models for motor behaviors.Neural computation, 25(2):328–373, 2013
2013
-
[20]
Accelerating reinforcement learning with learned skill priors
Karl Pertsch, Youngwoon Lee, and Joseph Lim. Accelerating reinforcement learning with learned skill priors. InConference on robot learning, pages 188–204. PMLR, 2021
2021
-
[21]
Opal: Offline primitive discovery for accelerating offline reinforcement learning
Anurag Ajay, Aviral Kumar, Pulkit Agrawal, Sergey Levine, and Ofir Nachum. Opal: Offline primitive discovery for accelerating offline reinforcement learning. InInternational Conference on Learning Representations, 2021
2021
-
[22]
Behavior transform- ers: Cloning k modes with one stone
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya (Arty) Altanzaya, and Lerrel Pinto. Behavior transform- ers: Cloning k modes with one stone. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 22955–22968. Cur- ran Associates, Inc., 2022. URL https://proceedings.n...
2022
-
[23]
Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H. Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions. InForty-first International Conference on Machine Learning (ICML), 2024
2024
-
[24]
Universal actions for enhanced embodied foundation models
Jinliang Zheng, Jianxiong Li, Dongxiu Liu, Yinan Zheng, Zhihao Wang, Zhonghong Ou, Yu Liu, Jingjing Liu, Ya-Qin Zhang, and Xianyuan Zhan. Universal actions for enhanced embodied foundation models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22508–22519, June 2025
2025
-
[25]
Joshi, Kyle Jeffrey, Rosario Jauregui Ruano, Jasmine Hsu, Keerthana Gopalakrishnan, Byron David, Andy Zeng, and Chuyuan Kelly Fu
Brian Ichter, Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, Dmitry Kalashnikov, Sergey Levine, Yao Lu, Carolina Parada, Kanishka Rao, Pierre Sermanet, Alexander T Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Mengyuan Yan, Noah Brown, Michael Ahn, Omar ...
-
[26]
URLhttps://proceedings.mlr.press/v205/ichter23a.html
PMLR, 14–18 Dec 2023. URLhttps://proceedings.mlr.press/v205/ichter23a.html. 12
2023
-
[27]
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. InarXiv preprint arXiv:2209.07753, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Pivot-r: Primitive-driven waypoint-aware world model for robotic manipulation.Advances in Neural Information Processing Systems, 37:54105–54136, 2024
Kaidong Zhang, Pengzhen Ren, Bingqian Lin, Junfan Lin, Shikui Ma, Hang Xu, and Xiaodan Liang. Pivot-r: Primitive-driven waypoint-aware world model for robotic manipulation.Advances in Neural Information Processing Systems, 37:54105–54136, 2024
2024
-
[29]
Manipulate-anything: Automating real-world robots using vision-language models
Jiafei Duan, Wentao Yuan, Wilbert Pumacay, Yi Ru Wang, Kiana Ehsani, Dieter Fox, and Ranjay Krishna. Manipulate-anything: Automating real-world robots using vision-language models. InConference on Robot Learning, pages 5326–5350. PMLR, 2025
2025
-
[30]
Feng Xu, Guangyao Zhai, Xin Kong, Tingzhong Fu, Daniel FN Gordon, Xueli An, and Benjamin Busam. Stare-vla: Progressive stage-aware reinforcement for fine-tuning vision-language-action models.arXiv preprint arXiv:2512.05107, 2025
-
[31]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Putting the object back into video object segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Joon-Young Lee, and Alexander Schwing. Putting the object back into video object segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3151–3161, 2024
2024
-
[33]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[34]
Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[35]
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[36]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model. arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Qwen Team. Qwen3-vl technical report, 2025. URLhttps://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
DeepSeek-AI. Deepseek-v3 technical report, 2024. URLhttps://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Qwen2.5-vl technical report, 2025
Qwen Team. Qwen2.5-vl technical report, 2025. URLhttps://arxiv.org/abs/2501.17139
-
[40]
Universal visual decomposer: Long-horizon manipulation made easy
Zichen Zhang, Yunshuang Li, Osbert Bastani, Abhishek Gupta, Dinesh Jayaraman, Yecheng Jason Ma, and Luca Weihs. Universal visual decomposer: Long-horizon manipulation made easy. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6973–6980. IEEE, 2024
2024
-
[41]
Rotate" or
Alibaba Cloud Qwen Team. Qwen3.5-omni: Multimodal understanding and generation model, 2026. URL https://qwen.ai/blog?id=qwen3.5-omni. 13 Appendix A More Details about Method A.1 Fine-tuning: Primitive Reasoning To ensure structural coherence during the disassembly process, we employ a VLM-based semantic decomposer as the primary step to establish a high-l...
2026
-
[42]
grasp: Move toward an object, seize it, and lift slightly
-
[43]
lift: Move upward significantly (z-axis) with closed gripper to reach a height, possibly with minorxyadjustment
-
[44]
move: Large-scale movement in thexy-plane while the gripper is closed
-
[45]
place: Descend to release an object at target location and lift away
-
[46]
push: Apply force to slide an object to a target position
-
[47]
press: Apply downward force on an object or a surface
-
[48]
twist: Rotate the gripper around its central axis (e.g., turning a knob)
-
[49]
tilt: Rotate around a joint beyond the wrist (adduction/abduction of the arm)
-
[50]
rotate: Rotate along a fixed axis of an object (e.g., opening a laptop)
-
[51]
pull: Pull an object toward a target position. 14
-
[52]
black-box
insert: Insert an object or the gripper into a gap/slot. [Merging Rules] •Object-Independent Pre-movement: Motions without object interaction (e.g., approaching a mug) should be merged into the subsequent primitive (e.g., usegraspinstead ofmove + grasp). •State Maintenance: If the arm maintains a grip, label asmoveunless it aligns withliftorpush. Do not f...
-
[53]
grasp: Gripper state remains constant (closed) for current and future frames; action is "close" (1); terminates when future frames show significant movement inxyorz. 15
-
[54]
lift: Significantz-axis increase over past frames; terminates when upward motion stops, begins descending, orxymotion ceases
-
[55]
move: Largexydisplacement over past frames; terminates whenxymotion stops orzbegins a sharp descent
-
[56]
place: Gripper state is "open" (0) for current and past frames; terminates when az-axis lift (departure) is detected
-
[57]
Pick up cup
push: Significantxydisplacement over past frames whilezremains stable; terminates whenxymotion ceases. (Optional) [In-Context Exemplar] // Example: Segmentation att= 40 Task: "Pick up cup" | Primitive: "grasp" | Split Index (t): 40 Index Pos x y z grip Window Logic 35 t−5 0.120 0.450 0.020 0.98 Window Start: Gripper stable ... ... ... ... ... ... ... 40 t...
-
[58]
future" frames; gripper action remains in the
grasp: Constant gripper state across the frames near the current frame and the "future" frames; gripper action remains in the "closed" state; significant horizontal orz-axis movement begins in the "future" frames
-
[59]
lift: Significantz-axis increase over several "past" frames in the buffer; the current/recent frames show a stop in rising, a continuous descending trend, or a cessation of movement in bothxydirections
-
[60]
move: Significantxorymovement over several "past" frames; movement inxydirections tends to stop in recent frames, or the z-axis begins a sharp descent
-
[61]
open" across recent and
place: Gripper state is "open" across recent and "past" frames, accompanied by a lift in thezdirection
-
[62]
[Reference Code] (Full Offline Code provided in context) [Function Logic] →If current_primitive is the last in seq: return current_primitive
push: Significantxorymovement over several "past" frames;xy movement tends to stop in recent frames, with minimal change in thez direction throughout. [Reference Code] (Full Offline Code provided in context) [Function Logic] →If current_primitive is the last in seq: return current_primitive. →If check_[primitive]_condition returnsTrue: return next_primiti...
-
[63]
This results in significant variations among instructions for the same primitive type across different tasks
Motivation for MCR 18 Without MCR, primitive instructions must retain task-specific contextual information, such as specific actions, objects, and spatial relationships. This results in significant variations among instructions for the same primitive type across different tasks. Especially in scenarios involving multiple tasks within the same scene, the m...
-
[64]
Grasp the masked object with color_1
Instruction Mapping When MCR is active, task-specific instructions are first mapped to standardized canonical ones based on their primitive type. The mapping table is as follows: Table 8:Complete MCR Primitive Instruction Mapping.Note: color_1 and color_2 are custom color indices representing the semantic masks of the manipulated object and the target loc...
-
[65]
{obj}". [Input] The image is: [Visual input of the current environment] [Output Format] You must respond strictly in JSON format as follows: {
Visual Grounding and Tracking For each task, we first extract the target objects mentioned in the original instruction. We utilize the Qwen2.5-VL-72B-Instruct[ 38] model to perform zero-shot objectdetection. The model is queried with a specific prompt to provide the spatial coordinates of the objects: System Prompt: Visual Object Detection [System Role] Y...
-
[66]
grasp" and
Imprecise Recognition:The VLM exhibits noticeable flaws inidentifying the temporal boundariesfor disassembly, such as the "grasp" and "pull" transitions in task(a). In task (b), it fails to cover the complete task horizon and prematurely stops, leading to incomplete disassembly
-
[67]
Thislack of interpretabilitymeans we cannot extract deterministic switching rules for subsequent inference
Black-box Logic:The VLM’s criteria for disassembly remain opaque. Thislack of interpretabilitymeans we cannot extract deterministic switching rules for subsequent inference. If the model suffers from hallucinations (as seen in the mid-task termination in (b)), the resultingdisassemblywill lead to execution failure
-
[68]
fine-tune then test
High Computational Cost:Relying on proprietary VLMs to process large-scale datasets for disassembly is prohibitivelyexpensive and difficult to scale. 20 Figure 4:Qualitative comparison of primitive disassembly methods on LIBERO-90.We visualize the disassembly results on two complex tasks: (a)open the top drawer of the cabinet and put the bowl in itand (b)...
-
[69]
pick up the bowl on the right and put it in the tray
We use an action chunk size of 10 for simulation, which is increased to 20 in real- world experiments to enhance the model’s robustness against physical perturbations and environmental noise inherent in live execution. All fine-tuning for OpenVLA and OpenVLA-OFT was conducted on an 8-GPU L40S(48g) server, taking 60 and 100 hours, respectively. Fine-tuning...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.