Bandwidth-Efficient and Privacy-Preserving Edge-Cloud Many-to-Many Speech Translation
Pith reviewed 2026-06-29 11:38 UTC · model grok-4.3
The pith
ESRT splits speech translation between edge device and cloud to cut bandwidth by 10x while blocking voiceprint leakage and supporting 45-language many-to-many S2TT.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
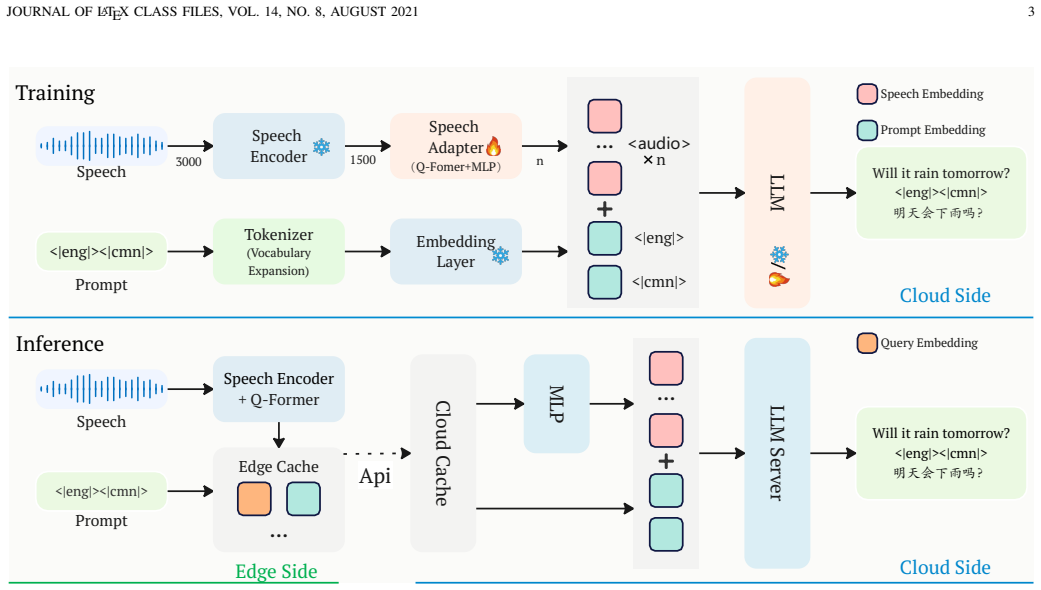
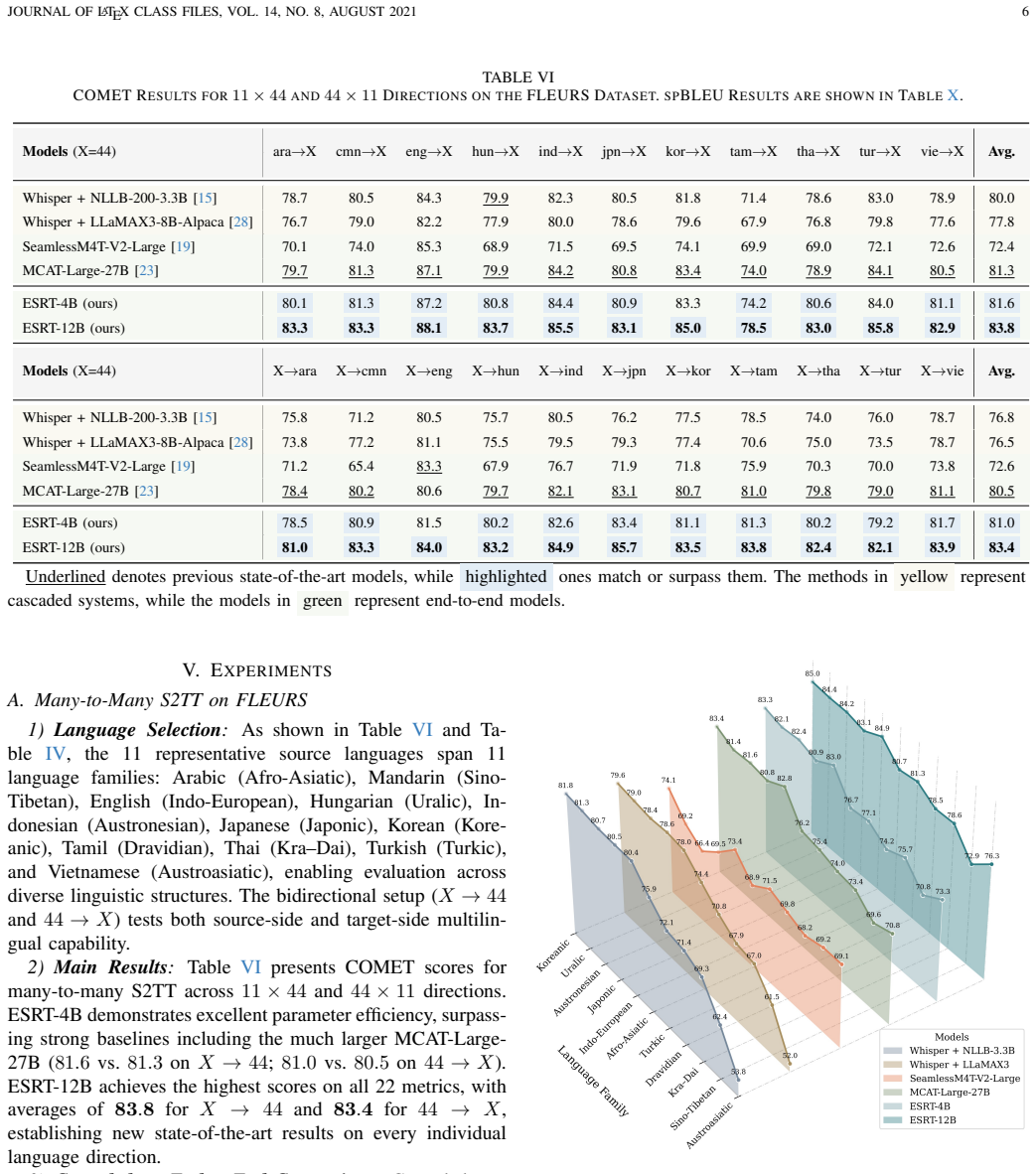
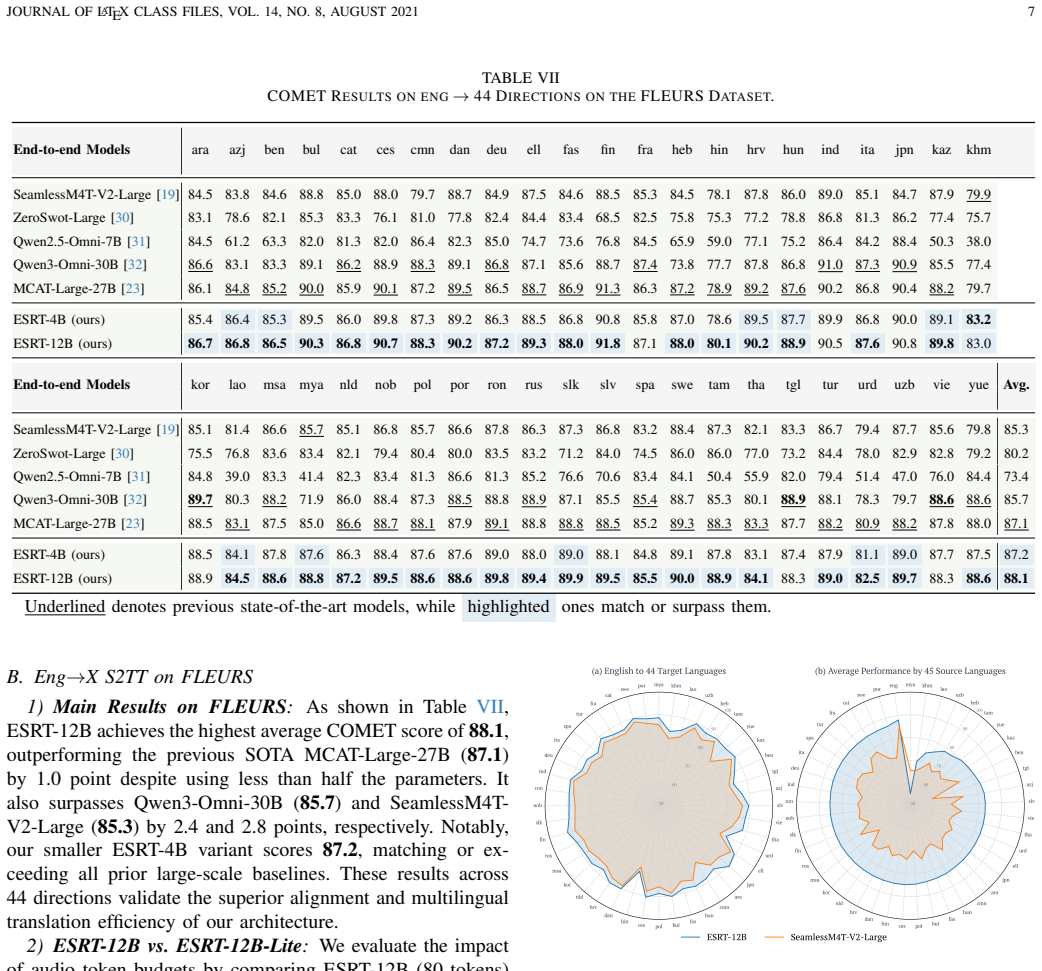
By using an edge-cloud split inference architecture that retains a lightweight speech encoder and adapter on the device, transmitting only highly compressed intermediate features to the cloud, and applying a multi-task weighted curriculum learning strategy with data balancing, the ESRT-4B and ESRT-12B models achieve state-of-the-art many-to-many S2TT performance across 45 languages (45 imes 44 directions) on the FLEURS dataset.
What carries the argument
Edge-cloud split inference architecture that retains a lightweight speech encoder and adapter on the device, transmitting only highly compressed intermediate features to the cloud.
If this is right
- Bandwidth requirements drop by up to 10 times relative to sending raw voice data.
- Raw audio never leaves the device, so voiceprint leakage is blocked at the transmission stage.
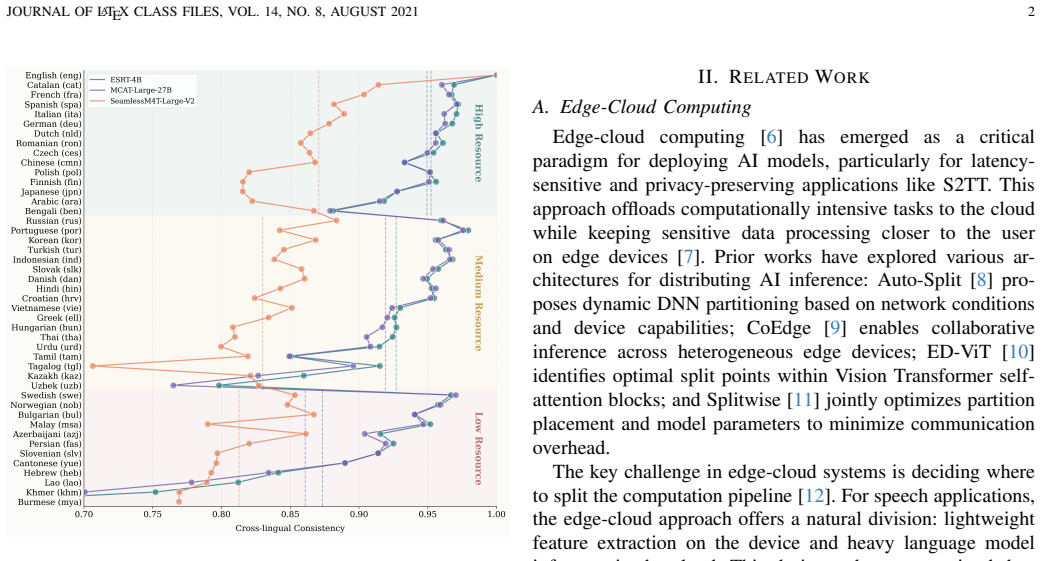
- Cross-lingual consistency holds across 45 languages without needing per-language fine-tuning or post-processing.
- Released code and models allow direct reproduction of the 45-by-44 direction results on FLEURS.
Where Pith is reading between the lines
- The same split could be tested on other edge-cloud audio tasks such as real-time speech recognition where privacy constraints are similar.
- Further reductions in feature size might support deployment over very low-bandwidth mobile links while keeping latency acceptable.
- Community use of the released models could reveal whether the curriculum strategy generalizes to language pairs outside the FLEURS set.
Load-bearing premise
Transmitting only the compressed intermediate features prevents any reconstruction of original voiceprints or raw audio, and the multi-task weighted curriculum learning with data balancing produces unbiased cross-lingual performance without language-specific post-hoc adjustments.
What would settle it
A successful reconstruction of intelligible speech or speaker identity from the transmitted compressed features, or a measurable drop in accuracy on non-English language pairs after removing the balancing step, would falsify the core claims.
Figures



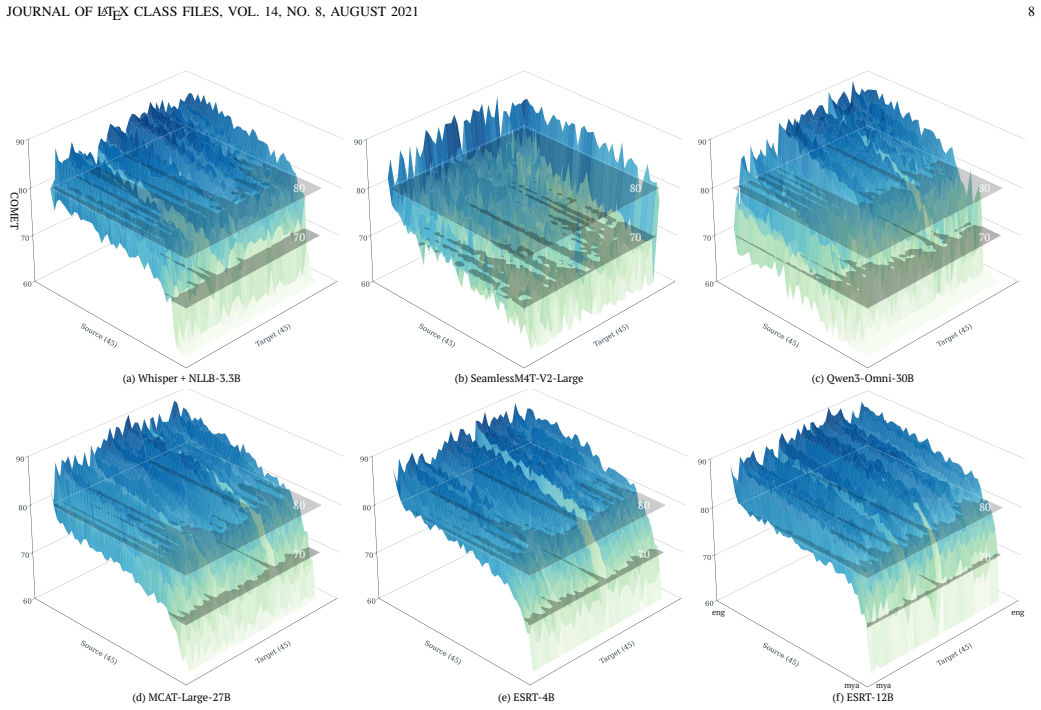

read the original abstract
Multimodal large language models (MLLMs) have demonstrated significant potential for speech-to-text translation (S2TT). However, existing deployment paradigms face critical challenges: pure on-device models suffer from resource constraints, while centralized cloud systems incur severe privacy risks and bandwidth bottlenecks by transmitting raw voice data. Furthermore, most models exhibit English-centric biases, restricting many-to-many translation scaling. In this paper, we propose Edge-cloud Speech Recognition and Translation (ESRT), a privacy-preserving and bandwidth-efficient collaborative edge-cloud MLLM framework. Specifically, we design an edge-cloud split inference architecture that retains a lightweight speech encoder and adapter on the device, transmitting only highly compressed intermediate features to the cloud. This fundamentally prevents voiceprint leakage and reduces bandwidth requirements by up to 10$\times$. To overcome English-centric bottlenecks, we introduce a multi-task weighted curriculum learning strategy with data balancing to ensure robust cross-lingual consistency. Extensive experiments on the FLEURS dataset demonstrate that our models, ESRT-4B and ESRT-12B, achieve state-of-the-art many-to-many S2TT performance across 45 languages ($45 \times 44$ directions). Code and models are released to facilitate reproducible, privacy-aware MLLM S2TT research. The code and models are released at https://github.com/yxduir/esrt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
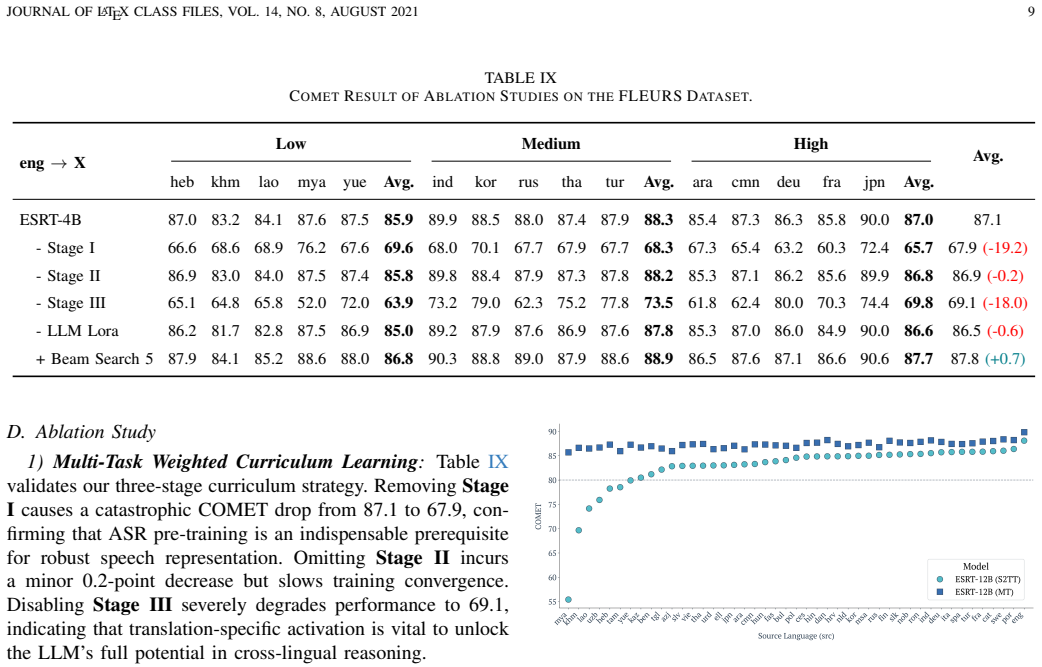
Summary. The paper proposes ESRT, an edge-cloud collaborative framework for many-to-many speech-to-text translation (S2TT) using MLLMs. It introduces a split-inference architecture that keeps a lightweight speech encoder and adapter on-device while transmitting only compressed intermediate features to the cloud, claiming up to 10× bandwidth reduction and prevention of voiceprint leakage. A multi-task weighted curriculum learning strategy with data balancing is used to mitigate English-centric biases and achieve robust cross-lingual performance. On the FLEURS dataset, ESRT-4B and ESRT-12B are reported to achieve SOTA results across 45 languages in 45×44 directions, with code and models released for reproducibility.
Significance. If the empirical claims hold, the work offers a practical path toward privacy-aware and bandwidth-efficient deployment of large speech translation models at the edge, addressing simultaneous constraints on resources, privacy, and language coverage. The public release of code and models strengthens the contribution by enabling direct verification and extension.
major comments (3)
- [Abstract and §3] Abstract and §3: The claim that transmitting compressed intermediate features 'fundamentally prevents voiceprint leakage' is presented without any quantitative privacy evaluation (e.g., speaker identification accuracy on transmitted features, reconstruction attack success rates, or mutual information bounds). This metric is load-bearing for the privacy-preserving contribution.
- [§3 and §4] §3 and §4: The multi-task weighted curriculum learning with data balancing is asserted to produce 'robust cross-lingual consistency' without language-specific post-hoc adjustments, yet no per-direction ablation tables or comparisons against language-specific adapters are provided. If low-resource directions still underperform, the headline SOTA result across all 45×44 pairs would rest primarily on high-resource pairs rather than the claimed balancing effect.
- [§4] §4 (results tables): The reported SOTA numbers and 10× bandwidth claim are given without error bars, standard deviations across seeds, or explicit baseline tables that isolate the contribution of the split architecture versus the curriculum strategy. This makes it impossible to assess whether the central performance claims are statistically reliable.
minor comments (2)
- [Abstract] Abstract: The bandwidth reduction is stated as 'up to 10×' without specifying the exact baseline (raw waveform bitrate, feature dimension, or quantization level) or the measurement protocol.
- [§3] Notation in §3: The weighting scheme for the multi-task curriculum is described at a high level; an explicit equation or pseudocode for how task weights are scheduled and balanced across the 45 languages would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that strengthen the empirical support for our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The claim that transmitting compressed intermediate features 'fundamentally prevents voiceprint leakage' is presented without any quantitative privacy evaluation (e.g., speaker identification accuracy on transmitted features, reconstruction attack success rates, or mutual information bounds). This metric is load-bearing for the privacy-preserving contribution.
Authors: We agree that the privacy claim would be strengthened by quantitative evaluation. The split-inference architecture transmits only compressed intermediate features rather than raw audio, which by design eliminates direct transmission of voice data. In the revised version we will add speaker identification accuracy experiments on the transmitted features (comparing against raw audio baselines) and report reconstruction attack success rates to provide measurable evidence supporting the privacy benefit. revision: yes
-
Referee: [§3 and §4] §3 and §4: The multi-task weighted curriculum learning with data balancing is asserted to produce 'robust cross-lingual consistency' without language-specific post-hoc adjustments, yet no per-direction ablation tables or comparisons against language-specific adapters are provided. If low-resource directions still underperform, the headline SOTA result across all 45×44 pairs would rest primarily on high-resource pairs rather than the claimed balancing effect.
Authors: We acknowledge that aggregate SOTA numbers alone do not fully isolate the contribution of the curriculum strategy. The manuscript currently emphasizes overall performance across 45×44 directions. In revision we will include per-direction performance tables, breakdowns separating high- and low-resource languages, and direct comparisons against language-specific adapter baselines to demonstrate that the balancing effect improves consistency rather than relying solely on high-resource pairs. revision: yes
-
Referee: [§4] §4 (results tables): The reported SOTA numbers and 10× bandwidth claim are given without error bars, standard deviations across seeds, or explicit baseline tables that isolate the contribution of the split architecture versus the curriculum strategy. This makes it impossible to assess whether the central performance claims are statistically reliable.
Authors: The referee correctly notes the absence of statistical reliability measures. We will revise §4 to report standard deviations across multiple random seeds for all main results, add error bars to the tables, and include explicit ablation tables that separately quantify the performance gains from the split-inference architecture and from the multi-task curriculum learning strategy. revision: yes
Circularity Check
No circularity: empirical SOTA claims rest on direct evaluation
full rationale
The paper reports training and evaluation results for ESRT-4B/ESRT-12B on the FLEURS dataset (45×44 directions) using an edge-cloud split architecture and multi-task weighted curriculum learning with data balancing. No equations, fitted parameters, or self-citations are shown that reduce the reported performance numbers back to quantities defined by the same inputs or hyperparameters. The central claims are externally falsifiable via the released code/models and the public FLEURS benchmark, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- task weights in curriculum learning
axioms (1)
- domain assumption The FLEURS dataset constitutes a representative and unbiased testbed for 45-language many-to-many speech translation.
Reference graph
Works this paper leans on
-
[1]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models,”arXiv preprint arXiv:2311.07919,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Speech translation and the end-to-end promise: Taking stock of where we are,
M. Sperber and M. Paulik, “Speech translation and the end-to-end promise: Taking stock of where we are,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 7409–7421. 1, 2
2020
-
[4]
Making llms better many-to-many speech-to-text translators with curriculum learning,
Y . Du, Y . Pan, Z. Ma, B. Yang, Y . Yang, K. Deng, X. Chen, Y . Xiang, M. Liu, and B. Qin, “Making llms better many-to-many speech-to-text translators with curriculum learning,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 12 466–12 478. 1, 2, 3
2025
-
[5]
Fleurs: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, Y . Zhang, V . Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,” in2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 798–805. 2, 3, 5
2023
-
[6]
Edge-cloud polarization and collaboration: A comprehensive survey for ai,
J. Yao, S. Zhang, Y . Yao, F. Wang, J. Ma, J. Zhang, Y . Chu, L. Ji, K. Jia, T. Shen, A. Wu, F. Zhang, Z. Tan, K. Kuang, C. Wu, F. Wu, J. Zhou, and H. Yang, “Edge-cloud polarization and collaboration: A comprehensive survey for ai,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 7, pp. 6866–6886, 2023. 2
2023
-
[7]
Ai on the edge: Characterizing ai-based iot applications using specialized edge architectures,
Q. Liang, P. Shenoy, and D. Irwin, “Ai on the edge: Characterizing ai-based iot applications using specialized edge architectures,” in2020 IEEE International Symposium on Workload Characterization (IISWC), 2020, pp. 145–156. 2
2020
-
[8]
Auto-split: A general framework of collaborative edge-cloud ai,
A. Banitalebi-Dehkordi, N. Vedula, J. Pei, F. Xia, L. Wang, and Y . Zhang, “Auto-split: A general framework of collaborative edge-cloud ai,” inProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, ser. KDD ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 2543–2553. [Online]. Available: https://doi.org/10...
-
[9]
Coedge: Cooperative dnn inference with adaptive workload partitioning over heterogeneous edge devices,
L. Zeng, X. Chen, Z. Zhou, L. Yang, and J. Zhang, “Coedge: Cooperative dnn inference with adaptive workload partitioning over heterogeneous edge devices,”IEEE/ACM Transactions on Networking, vol. 29, no. 2, pp. 595–608, 2021. 2
2021
-
[10]
Efficient partitioning vision transformer on edge devices for distributed inference,
X. Liu, Y . Song, X. Li, Y . Sun, H. Lan, Z. Liu, L. Jiang, and J. Li, “Efficient partitioning vision transformer on edge devices for distributed inference,”2025 IEEE 45th International Conference on Distributed Computing Systems (ICDCS), pp. 286–296, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:273351350 2
2025
-
[11]
Splitwise: Collaborative edge–cloud inference for llms via lyapunov-assisted drl,
A. Younesi, A. Shabrang Maryan, E. Oustad, Z. Najafabadi Samani, M. Ansari, and T. Fahringer, “Splitwise: Collaborative edge–cloud inference for llms via lyapunov-assisted drl,” inProceedings of the 18th IEEE/ACM International Conference on Utility and Cloud Computing, ser. UCC ’25. New York, NY , USA: Association for Computing Machinery, 2026. [Online]. ...
-
[12]
X. Zhang, R. Razavi-Far, H. Isah, A. David, G. Higgins, and M. Zhang, “A survey on deep learning in edge–cloud collaboration: Model partitioning, privacy preservation, and prospects,”Know.- Based Syst., vol. 310, no. C, Feb. 2025. [Online]. Available: https://doi.org/10.1016/j.knosys.2025.112965 2
-
[13]
Covost 2 and massively multilingual speech-to-text translation,
C. Wang, A. Wu, and J. Pino, “Covost 2 and massively multilingual speech-to-text translation,”arXiv preprint arXiv:2007.10310, 2020. 2, 5
-
[14]
Robust speech recognition via large-scale weak super- vision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak super- vision,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 28 492–28 518. 2, 3, 5, 9
2023
-
[15]
Scaling neural machine translation to 200 languages,
“Scaling neural machine translation to 200 languages,”Nature, vol. 630, no. 8018, pp. 841–846, 2024. 2, 5, 6
2024
-
[16]
Attention-passing models for robust and data-efficient end-to-end speech translation,
M. Sperber, G. Neubig, J. Niehues, and A. Waibel, “Attention-passing models for robust and data-efficient end-to-end speech translation,” Transactions of the Association for Computational Linguistics, vol. 7, pp. 313–325, 2019. [Online]. Available: https://aclanthology.org/Q19-1020/ 2
2019
-
[17]
Speech translation with speech foundation models and large language models: What is there and what is missing?
M. Gaido, S. Papi, M. Negri, and L. Bentivogli, “Speech translation with speech foundation models and large language models: What is there and what is missing?” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for ...
2024
-
[18]
C. Wang, J. Pino, and J. Gu, “Improving cross-lingual transfer learn- ing for end-to-end speech recognition with speech translation,”arXiv preprint arXiv:2006.05474, 2020. 2
-
[19]
Joint speech and text machine translation for up to 100 languages,
“Joint speech and text machine translation for up to 100 languages,” Nature, vol. 637, no. 8046, pp. 587–593, 2025. 2, 6, 7
2025
-
[20]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “Salmonn: Towards generic hearing abilities for large language models,”arXiv preprint arXiv:2310.13289, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Speechgpt: Empowering large language models with intrinsic cross- modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross- modal conversational abilities,”arXiv preprint arXiv:2305.11000, 2023. 2
-
[22]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742. 3
2023
-
[23]
Mcat: Scaling many-to-many speech-to-text translation with mllms to 70 languages,
Y . Du, K. Liu, Y . Pan, B. Yang, K. Deng, X. Chen, Y . Xiang, M. Liu, B. Qin, and Y . Wang, “Mcat: Scaling many-to-many speech-to-text translation with mllms to 70 languages,”IEEE Transactions on Audio, Speech and Language Processing, 2026. 3, 5, 6, 7 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
2026
-
[24]
Scaling model and data for multilingual machine translation with open large language models,
Y . Shang, P. Gao, W. Liu, J. Luan, and J. Su, “Scaling model and data for multilingual machine translation with open large language models,”
-
[25]
Available: https://arxiv.org/abs/2602.11961 3, 5
[Online]. Available: https://arxiv.org/abs/2602.11961 3, 5
-
[26]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivièreet al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” inProceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), 2020, pp. 4211–4215. 5
2020
-
[28]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022, pp. 12 513–12 525. [Online]. Available: https://openreview.net/forum?id= nZeVKeeFYf9 5
2022
-
[29]
Llamax: Scaling linguistic horizons of llm by enhancing translation capabilities beyond 100 lan- guages,
Y . Lu, W. Zhu, L. Li, Y . Qiao, and F. Yuan, “Llamax: Scaling linguistic horizons of llm by enhancing translation capabilities beyond 100 lan- guages,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 10 748–10 772. 5, 6
2024
-
[30]
Seamlessm4t-massively multilingual & multimodal machine transla- tion,
L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, P.-A. Duquenne, H. Elsahar, H. Gong, K. Heffernan, J. Hoffmanet al., “Seamlessm4t-massively multilingual & multimodal machine transla- tion,”arXiv preprint arXiv:2308.11596, 2023. 5
-
[31]
Pushing the Limits of Zero-shot End-to-End Speech Translation,
I. Tsiamas, G. Gállego, J. Fonollosa, and M. Costa-jussà, “Pushing the Limits of Zero-shot End-to-End Speech Translation,” inFindings of the Association for Computational Linguistics ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand and virtual meeting: Association for Computational Linguistics, Aug. 2024, pp. 14 245–14 267. [Online...
2024
-
[32]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Comet-22: Unbabel-ist 2022 submission for the metrics shared task,
R. Rei, J. G. De Souza, D. Alves, C. Zerva, A. C. Farinha, T. Glushkova, A. Lavie, L. Coheur, and A. F. Martins, “Comet-22: Unbabel-ist 2022 submission for the metrics shared task,” inProceedings of the Seventh Conference on Machine Translation (WMT), 2022, pp. 578–585. 5
2022
-
[35]
A call for clarity in reporting BLEU scores,
M. Post, “A call for clarity in reporting BLEU scores,” in Proceedings of the Third Conference on Machine Translation: Research Papers. Belgium, Brussels: Association for Computational Linguistics, Oct. 2018, pp. 186–191. [Online]. Available: https: //www.aclweb.org/anthology/W18-6319 5
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.