The Importance of Being Statistically Earnest: A Critical Re-evaluation of GSM-Symbolic
Pith reviewed 2026-06-29 12:14 UTC · model grok-4.3
The pith
Re-evaluation finds only half of LLMs show statistically significant drops on GSM-Symbolic after accounting for larger integers in the data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
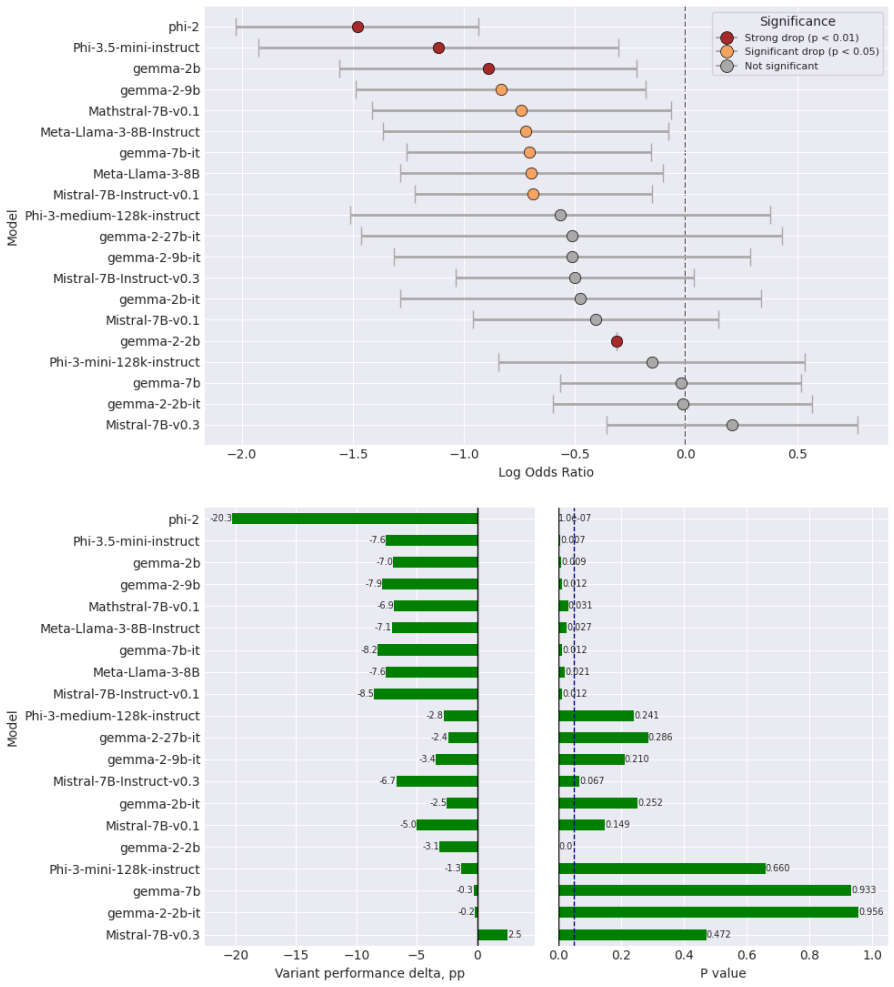
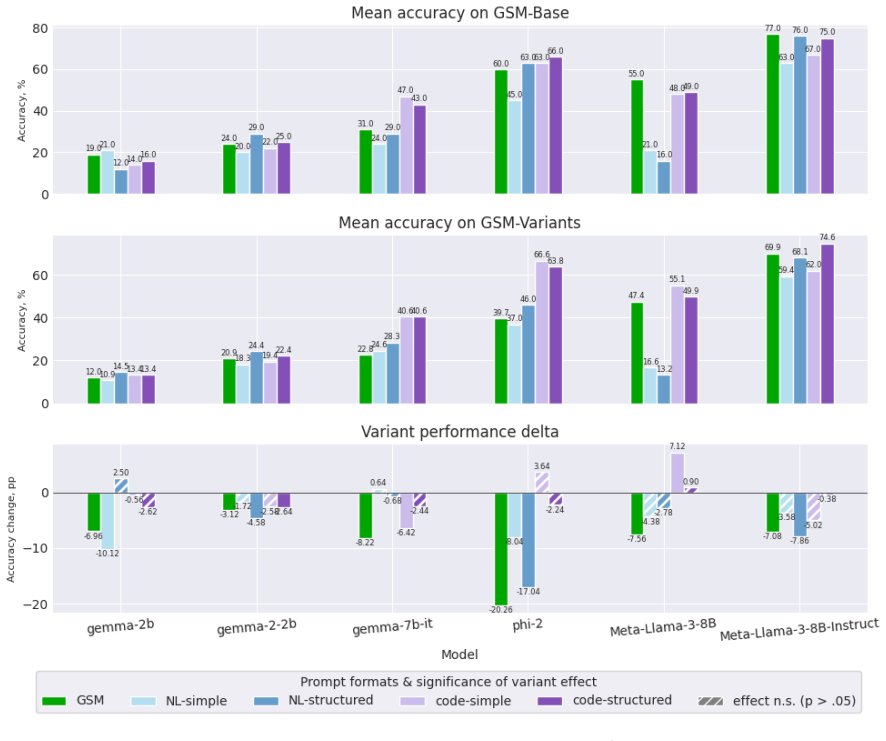
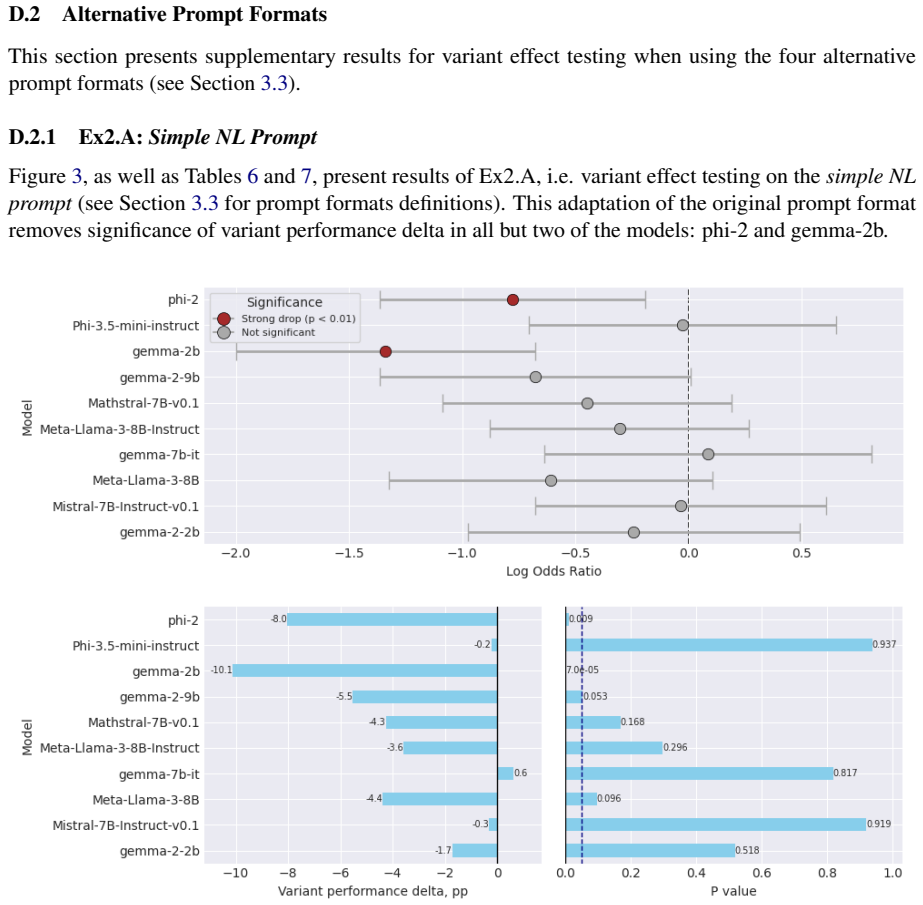
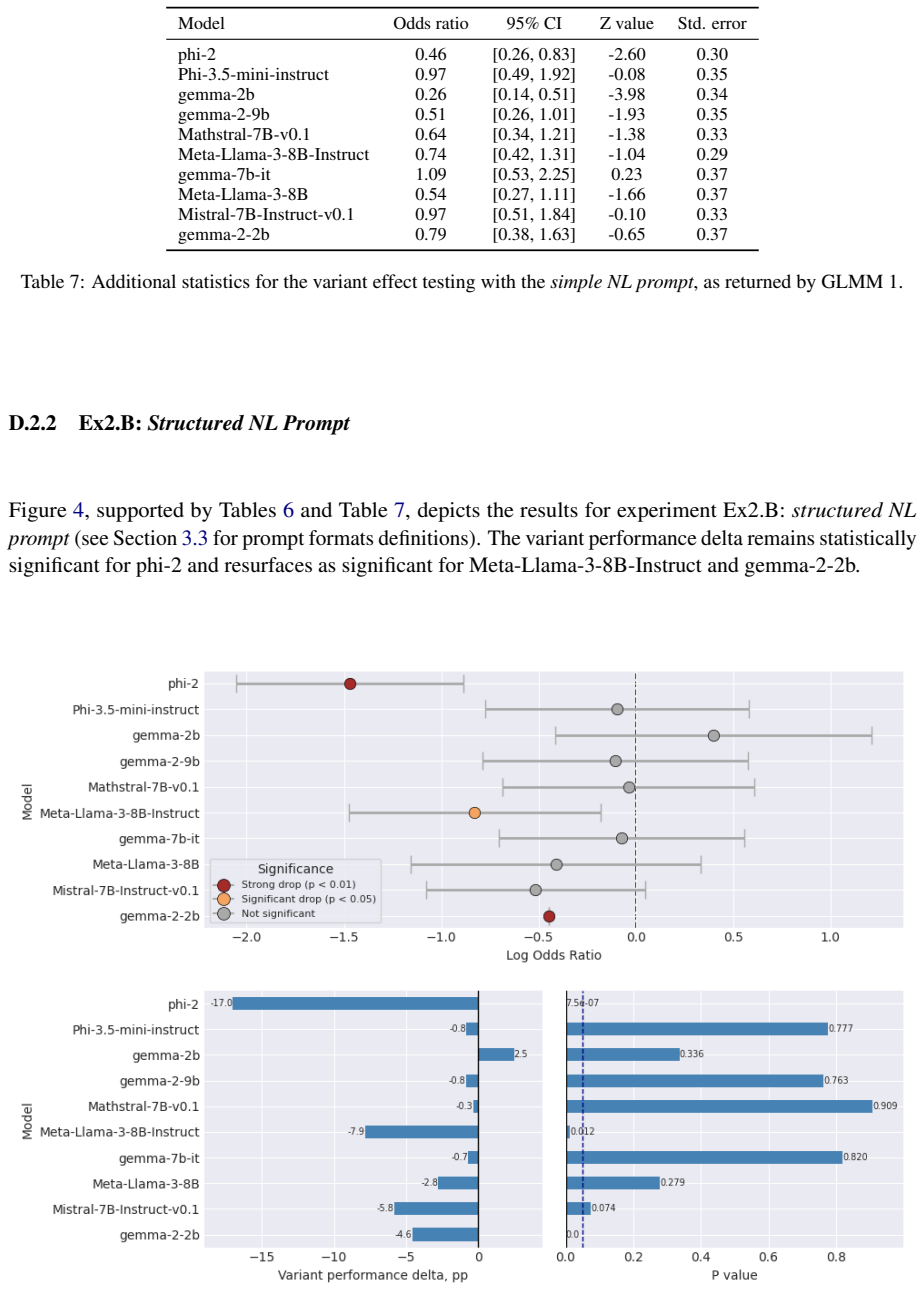
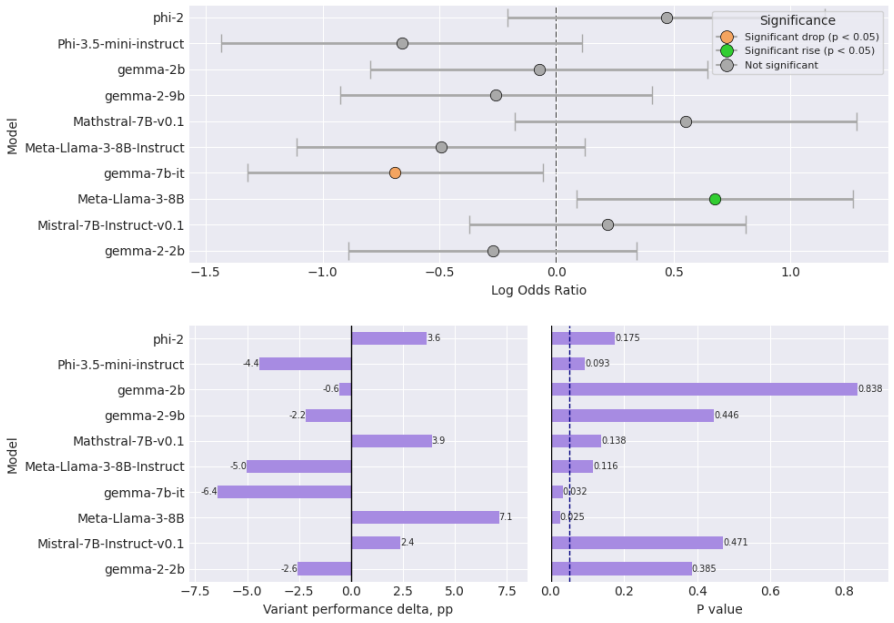
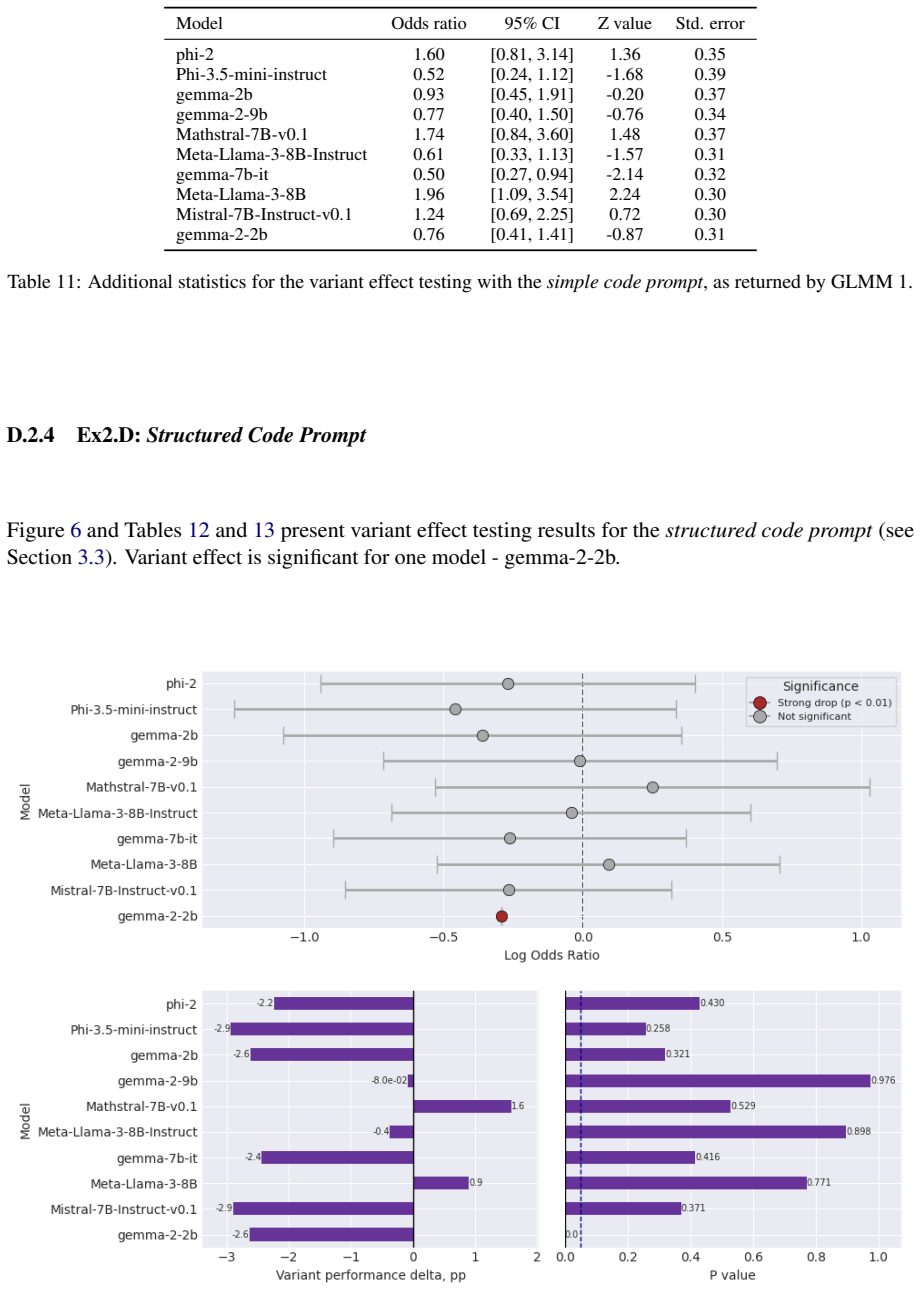
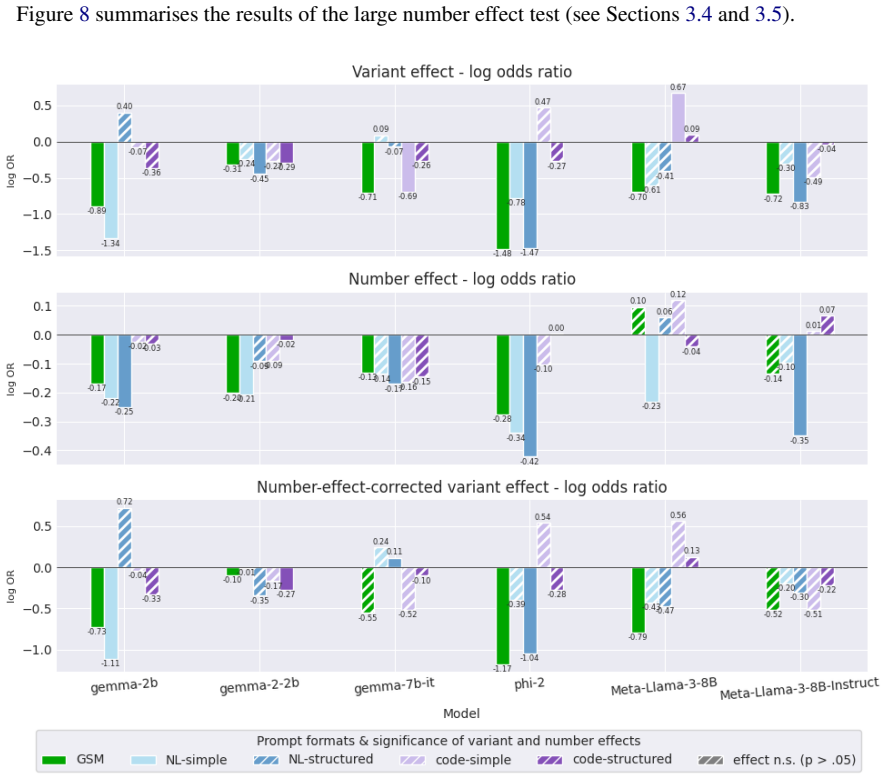
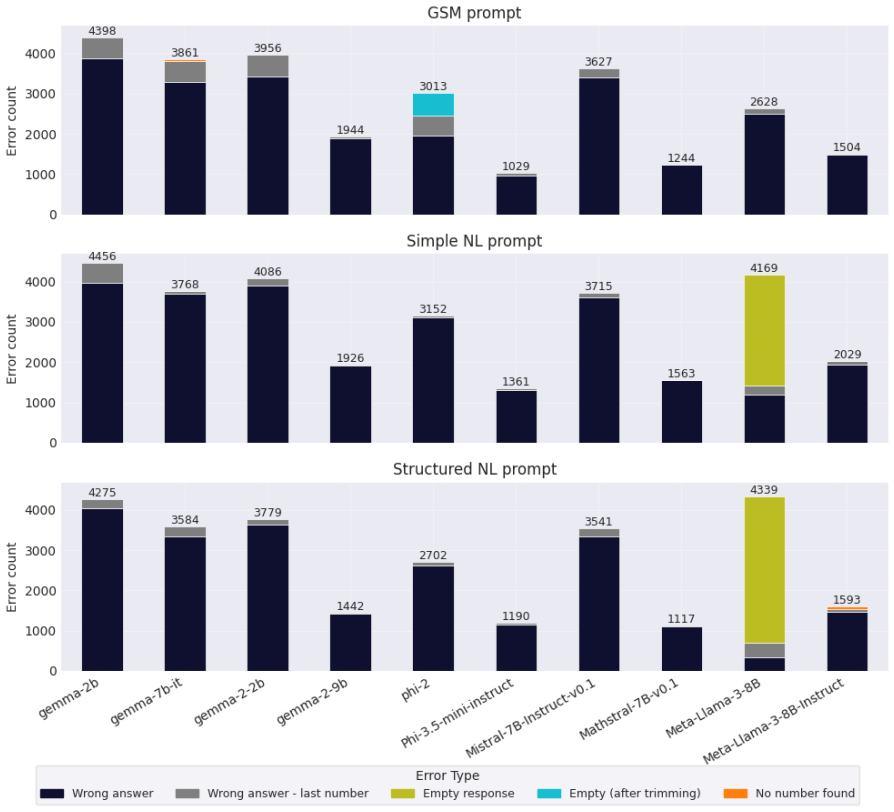
Re-evaluating 20 open-weight models with Generalised Linear Mixed Models that include per-question random effects shows that only half exhibit statistically significant performance changes on the original GSM-Symbolic prompt format. The main dataset contains a shifted distribution of larger integers compared with GSM-Base, contradicting prior claims that the variants were equivalent. Controlling for this integer-size shift accounts for significance in roughly half the remaining cases, and the models that retain significance display distinct failure profiles such as variable-binding fragility, arithmetic limits, and dual-task interference.
What carries the argument
Generalised Linear Mixed Models with per-question random effects, paired with Kolmogorov-Smirnov testing of integer-value distributions between datasets.
If this is right
- Only half the tested models exhibit statistically significant performance changes under the original prompt format.
- The large-integer distribution shift accounts for significance in roughly half the remaining cases after GLMM analysis.
- Models with retained significance display distinct, model-specific failure profiles rather than a uniform reasoning deficit.
- Original GSM-Symbolic claims of consistent reasoning failure rest on incomplete statistical controls.
Where Pith is reading between the lines
- Benchmark creators should match numerical magnitude distributions when generating symbolic variants to avoid confounding size effects with reasoning demands.
- GLMM-style per-item random effects may be required to separate question difficulty from model capability in future LLM evaluations.
- Model-specific failure profiles identified here could guide targeted diagnostic tests rather than relying on aggregate accuracy scores.
Load-bearing premise
That controlling for the observed shift in larger integers fully isolates its causal contribution to performance drops rather than capturing other correlated but unmeasured factors such as problem complexity.
What would settle it
Re-generate the GSM-Symbolic problems with integer sizes matched exactly to the GSM-Base distribution and re-run the same 20 models to test whether the performance deltas lose statistical significance.
Figures
read the original abstract
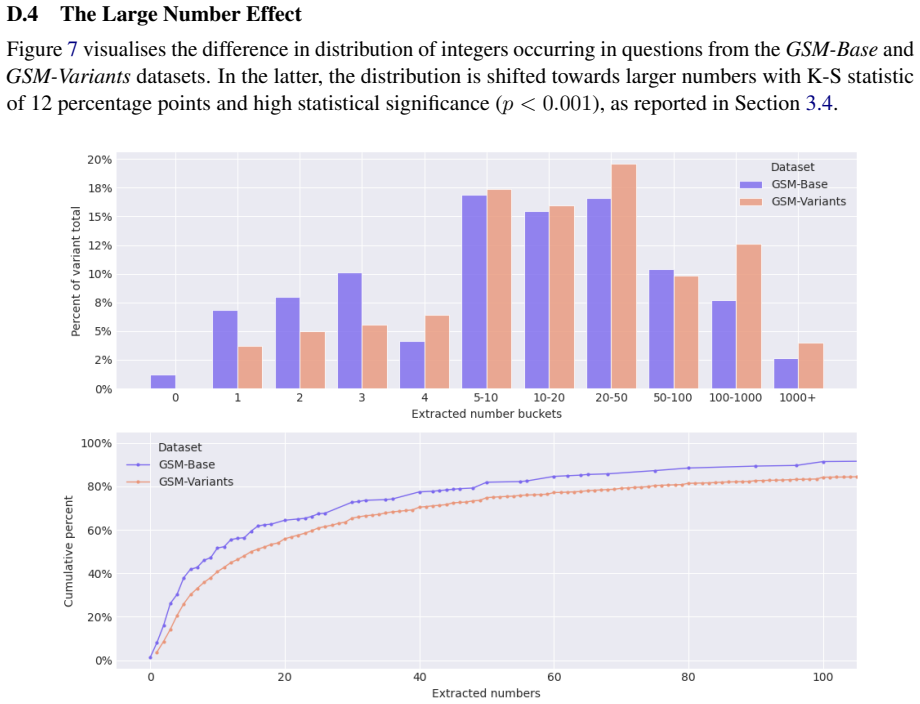
The GSM-Symbolic benchmark (Mirzadeh et al., 2025) reported consistent performance drops across 25 Large Language Models (LLMs) when tested on template-generated variants of GSM8K problems, concluding that the models lack genuine reasoning capabilities. We argue that this conclusion rests on shaky statistical ground. Re-evaluating 20 open-weight models using Generalised Linear Mixed Models with per-question random effects, we find that only half exhibit statistically significant performance changes under the original prompt format. Moreover, we identify a previously unacknowledged factor: the main GSM-Symbolic dataset contains a systematically shifted distribution of larger integers in problem texts relative to GSM-Base (K-S statistic = 0.12, p < 0.001), contradicting the original authors' claims. Controlling for this large number effect accounts for significance in roughly half the remaining cases. Among models with statistically significant performance deltas, we identify distinct, model-specific failure profiles - including fragility of variable binding, arithmetic limitations, and dual-task interference - underscoring that blanket claims about LLM reasoning are both statistically premature and mechanistically misleading.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript re-evaluates the GSM-Symbolic benchmark (Mirzadeh et al., 2025) by applying Generalised Linear Mixed Models (GLMM) with per-question random effects to performance data from 20 open-weight LLMs. It reports that only half of these models exhibit statistically significant performance changes under the original prompt format. The paper further identifies a previously unacknowledged distributional shift toward larger integers in the main GSM-Symbolic dataset relative to GSM-Base (Kolmogorov-Smirnov statistic = 0.12, p < 0.001) and claims that controlling for this shift via the GLMM accounts for statistical significance in roughly half of the remaining cases. It concludes that blanket claims about LLM reasoning deficits are statistically premature and identifies distinct, model-specific failure profiles such as variable-binding fragility and arithmetic limitations.
Significance. If the GLMM specifications and controls prove robust upon detailed reporting, the work would usefully demonstrate the value of mixed-effects modeling and distributional diagnostics in LLM benchmark analysis. It would strengthen the case for moving beyond aggregate accuracy deltas to account for problem-feature shifts and model heterogeneity, thereby supporting more precise, falsifiable claims about reasoning capabilities.
major comments (1)
- [Abstract] Abstract: the central claim that 'controlling for this large number effect accounts for significance in roughly half the remaining cases' is load-bearing for the paper's re-evaluation but rests on an unspecified GLMM. No equation, covariate definition (e.g., max operand, mean log-value, or binned threshold), interaction structure, or sensitivity analysis is provided; the text mentions only per-question random effects. This directly prevents verification of whether the control isolates the integer-size factor or proxies for correlated unmeasured variables such as template complexity, undermining the contradiction with the original authors' claims.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comment. We agree that the GLMM requires fuller specification to support verification of our claims and will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'controlling for this large number effect accounts for significance in roughly half the remaining cases' is load-bearing for the paper's re-evaluation but rests on an unspecified GLMM. No equation, covariate definition (e.g., max operand, mean log-value, or binned threshold), interaction structure, or sensitivity analysis is provided; the text mentions only per-question random effects. This directly prevents verification of whether the control isolates the integer-size factor or proxies for correlated unmeasured variables such as template complexity, undermining the contradiction with the original authors' claims.
Authors: We accept the referee's point that the current manuscript provides insufficient detail on the GLMM. The abstract and main text mention only per-question random effects and do not include the model equation, explicit covariate definitions for the large-number effect, interaction terms, or sensitivity checks. In the revised manuscript we will add the full specification (e.g., performance ~ prompt_format + log(max_operand) + (1|question), with max_operand defined as the largest integer appearing in the problem statement), report the precise covariate construction, test alternative operationalizations (mean log-value, binned thresholds), and include a sensitivity analysis. These additions will allow readers to assess whether the covariate isolates the documented distributional shift rather than serving as a proxy for template complexity or other factors. We view this as a necessary clarification that strengthens rather than alters the paper's conclusions. revision: yes
Circularity Check
No significant circularity; analysis applies external statistical methods to public benchmark data.
full rationale
The paper re-evaluates 20 models on GSM-Symbolic using GLMM with per-question random effects and K-S tests for integer distribution shifts. These are standard, pre-existing statistical tools applied to publicly described datasets. No self-citations are load-bearing, no parameters are fitted to target deltas and then renamed as predictions, and no derivation reduces by construction to its inputs. The claim that the shift accounts for significance in half the cases is an empirical statistical outcome, not a definitional equivalence. The paper is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Generalized linear mixed models with per-question random effects are an appropriate model for binary LLM correctness data across template variants.
- standard math The Kolmogorov-Smirnov test correctly identifies a meaningful distributional difference in integer magnitudes between datasets.
Reference graph
Works this paper leans on
-
[1]
Less Is More: Cognitive Load and the Single-Prompt Ceiling in LLM Mathematical Reasoning
Statistical multicriteria evaluation of LLM- generated text. InProceedings of the 18th Inter- national Natural Language Generation Conference, pages 338–351. R Harald Baayen, Douglas J Davidson, and Douglas M Bates. 2008. Mixed-effects modeling with crossed random effects for subjects and items.Journal of memory and language, 59(4):390–412. Douglas Bates,...
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[2]
Efficient numeracy in language models through single-token number embeddings.Preprint, arXiv:2510.06824. Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Mario Šaško, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Scientific credibility of machine translation re- search: A meta-evaluation of 769 papers. InProceed- ings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7297–7306. Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel T...
-
[4]
InInternational Conference on Learning Representations (ICLR)
GSM-Symbolic: Understanding the limita- tions of mathematical reasoning in large language models. InInternational Conference on Learning Representations (ICLR). Avni Mittal. 2026. Did you forget what i asked? prospective memory failures in large language mod- els.Preprint, arXiv:2603.23530. Kajal Negi, Giovanni Puccetti, and Andrea Esuli. 2026. GSM-Identi...
-
[5]
False-positive psychology: Undisclosed flexi- bility in data collection and analysis allows present- ing anything as significant.Psychological Science, 22(11):1359–1366. Aaditya K Singh and DJ Strouse. 2024. Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs.Preprint, arXiv:2402.14903. Dimitris Spathis and Fahim Kawsar. 2024. T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.